Recognition: unknown
A Vision-Language-Action Model for Adaptive Ultrasound-Guided Needle Insertion and Needle Tracking
Pith reviewed 2026-05-10 00:26 UTC · model grok-4.3
The pith
A single Vision-Language-Action model unifies real-time needle tracking and adaptive robotic insertion control under ultrasound guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
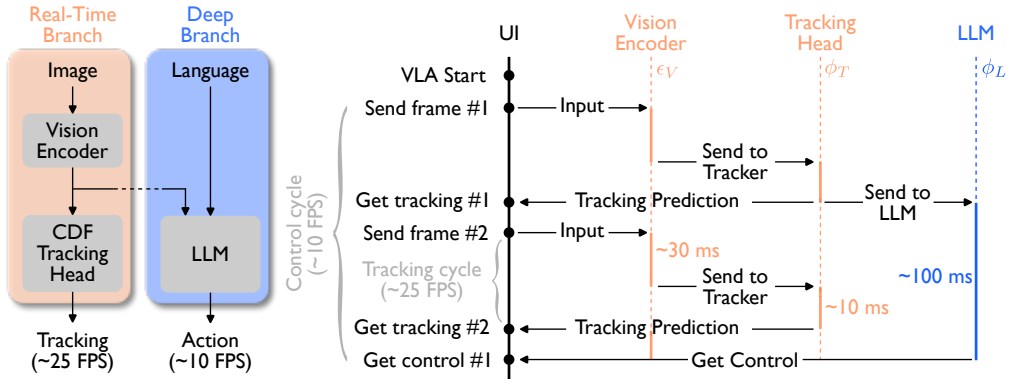
The central claim is that a Vision-Language-Action model, equipped with a Cross-Depth Fusion tracking head for integrating positional and semantic features, a Tracking-Conditioning register for parameter-efficient backbone adaptation, and an uncertainty-aware asynchronous control policy, enables unified, real-time adaptive needle tracking and insertion on robotic ultrasound systems, outperforming state-of-the-art trackers and manual operation in accuracy, success rate, and speed.
What carries the argument
Vision-Language-Action model whose Cross-Depth Fusion tracking head fuses shallow positional and deep semantic features from the vision backbone, paired with a Tracking-Conditioning register for adaptation and an uncertainty-aware policy for insertion decisions.
If this is right
- Real-time needle position and environment awareness can drive continuous adjustment of insertion trajectory without separate controllers.
- Tracking accuracy exceeds that of existing specialized trackers on the same robotic ultrasound platform.
- Insertion success rates rise while total procedure time falls relative to unaided manual operation.
- The asynchronous pipeline supports timely decisions that improve safety margins during dynamic imaging.
Where Pith is reading between the lines
- Pre-trained vision backbones can be repurposed for medical tracking tasks with only lightweight conditioning registers rather than full retraining.
- End-to-end learned policies may eventually replace modular hand-crafted controllers across other image-guided robotic interventions.
- The same VLA structure could be tested on additional needle-based procedures such as biopsies or nerve blocks under different imaging modalities.
Load-bearing premise
The model components will continue to perform reliably when ultrasound images contain the full range of clinical artifacts, varying patient anatomies, and lighting changes not captured in the reported tests.
What would settle it
A controlled clinical study that measures tracking error, insertion success rate, and total time on real patients with diverse anatomies and imaging conditions, directly comparing the model against both state-of-the-art trackers and expert manual performance.
Figures


read the original abstract
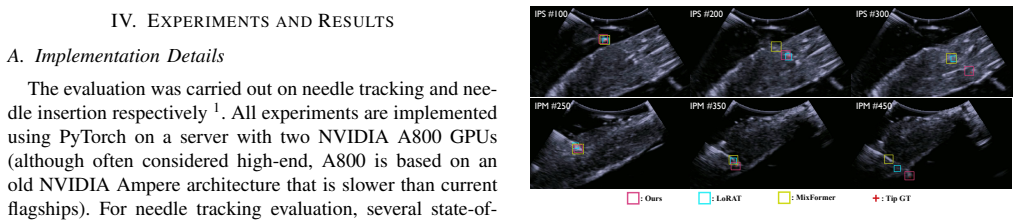
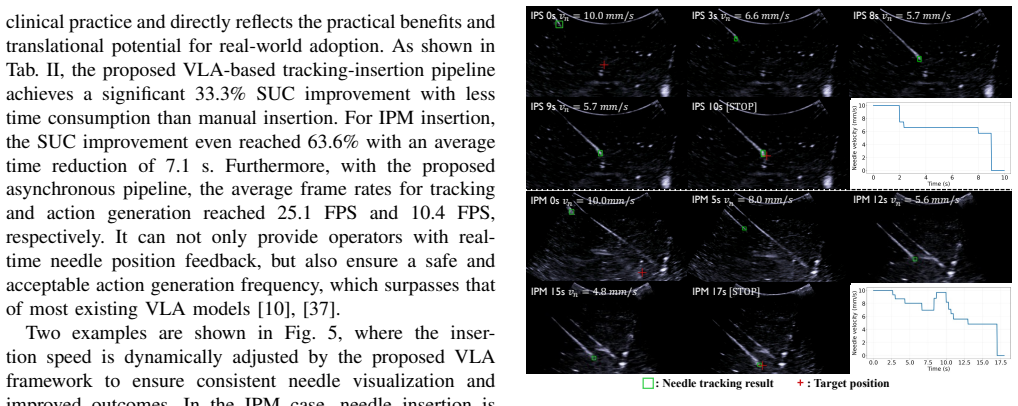
Ultrasound (US)-guided needle insertion is a critical yet challenging procedure due to dynamic imaging conditions and difficulties in needle visualization. Many methods have been proposed for automated needle insertion, but they often rely on hand-crafted pipelines with modular controllers, whose performance degrades in challenging cases. In this paper, a Vision-Language-Action (VLA) model is proposed for adaptive and automated US-guided needle insertion and tracking on a robotic ultrasound (RUS) system. This framework provides a unified approach to needle tracking and needle insertion control, enabling real-time, dynamically adaptive adjustment of insertion based on the obtained needle position and environment awareness. To achieve real-time and end-to-end tracking, a Cross-Depth Fusion (CDF) tracking head is proposed, integrating shallow positional and deep semantic features from the large-scale vision backbone. To adapt the pretrained vision backbone for tracking tasks, a Tracking-Conditioning (TraCon) register is introduced for parameter-efficient feature conditioning. After needle tracking, an uncertainty-aware control policy and an asynchronous VLA pipeline are presented for adaptive needle insertion control, ensuring timely decision-making for improved safety and outcomes. Extensive experiments on both needle tracking and insertion show that our method consistently outperforms state-of-the-art trackers and manual operation, achieving higher tracking accuracy, improved insertion success rates, and reduced procedure time, highlighting promising directions for RUS-based intelligent intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Vision-Language-Action (VLA) model for adaptive and automated ultrasound-guided needle insertion and tracking on a robotic ultrasound (RUS) system. It introduces a Cross-Depth Fusion (CDF) tracking head to integrate shallow positional and deep semantic features from a large-scale vision backbone for real-time end-to-end tracking, a Tracking-Conditioning (TraCon) register for parameter-efficient adaptation of the pretrained backbone, and an uncertainty-aware control policy together with an asynchronous VLA pipeline for adaptive insertion control. The authors claim that extensive experiments on needle tracking and insertion demonstrate consistent outperformance over state-of-the-art trackers and manual operation, with higher tracking accuracy, improved insertion success rates, and reduced procedure time.
Significance. If the experimental claims hold under rigorous validation, this work could advance robotic medical interventions by replacing hand-crafted modular pipelines with a unified, end-to-end VLA framework that adapts insertion in real time based on needle position and scene awareness. The CDF and TraCon components directly target persistent challenges in US needle visualization, and the uncertainty-aware policy addresses safety-critical decision-making. Such an integrated approach has clear potential to improve procedure reliability in dynamic clinical environments.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent outperformance' with 'higher tracking accuracy, improved insertion success rates, and reduced procedure time' is asserted without any quantitative metrics, dataset descriptions, baseline comparisons, statistical tests, or error analysis. This absence makes the empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion of superiority.
- [Abstract] The weakest assumption—that the CDF tracking head, TraCon register, and uncertainty-aware policy will generalize reliably to real clinical settings with varying imaging conditions, patient anatomies, and artifacts—is not addressed by any described validation protocol, cross-site testing, or artifact-specific ablation. This directly undermines the practical significance of the unified VLA approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the abstract and clarify the scope of our validation. We address each point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent outperformance' with 'higher tracking accuracy, improved insertion success rates, and reduced procedure time' is asserted without any quantitative metrics, dataset descriptions, baseline comparisons, statistical tests, or error analysis. This absence makes the empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion of superiority.
Authors: The abstract is intended as a concise overview, while the full manuscript details the quantitative results in the Experiments section, including specific tracking accuracy metrics (e.g., mean and standard deviation of needle tip localization error in pixels), insertion success rates, procedure time reductions, comparisons against multiple state-of-the-art trackers, dataset descriptions (phantom and simulated dynamic US sequences), and statistical significance testing. We agree that embedding a few representative quantitative highlights would make the abstract more self-contained. We will revise the abstract to include key performance figures and brief references to the evaluation protocol. revision: yes
-
Referee: [Abstract] The weakest assumption—that the CDF tracking head, TraCon register, and uncertainty-aware policy will generalize reliably to real clinical settings with varying imaging conditions, patient anatomies, and artifacts—is not addressed by any described validation protocol, cross-site testing, or artifact-specific ablation. This directly undermines the practical significance of the unified VLA approach.
Authors: Our experiments focus on a controlled robotic ultrasound setup using tissue-mimicking phantoms and procedurally generated dynamic sequences that incorporate common imaging variations and artifacts. Ablation studies isolate the contributions of the CDF head and TraCon register, and the uncertainty-aware policy is evaluated for decision reliability under simulated noise. We do not claim immediate readiness for arbitrary clinical deployment and have not performed cross-site or in-vivo patient testing. We will add an explicit Limitations and Future Work section that describes the current validation protocol, acknowledges the gap to full clinical generalization, and outlines planned extensions including artifact-specific ablations and multi-center data collection. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an empirical VLA architecture for ultrasound-guided needle procedures, introducing modules such as the CDF tracking head, TraCon register, uncertainty-aware policy, and asynchronous pipeline. No equations, derivations, or parameter-fitting steps are referenced in the provided text. Claims rest on experimental comparisons to baselines rather than any self-referential reduction of outputs to inputs. No self-citation chains, ansatzes smuggled via prior work, or renamed known results appear as load-bearing elements. The work is a straightforward application of existing VLA concepts with added components, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained large-scale vision backbones can be efficiently adapted for real-time needle tracking via a conditioning register
- domain assumption Ultrasound images contain sufficient positional and semantic information for reliable needle localization under dynamic conditions
invented entities (3)
-
Cross-Depth Fusion (CDF) tracking head
no independent evidence
-
Tracking-Conditioning (TraCon) register
no independent evidence
-
Uncertainty-aware control policy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep learning in medical ultrasound analysis: a review,
S. Liuet al., “Deep learning in medical ultrasound analysis: a review,” Engineering, vol. 5, no. 2, pp. 261–275, 2019
2019
-
[2]
Imaging modalities: Advantages and disadvantages,
R. R. Richardson, MD and R. R. Richardson, “Imaging modalities: Advantages and disadvantages,”Atlas of Acquired Cardiovascular Disease Imaging in Children, pp. 1–4, 2017
2017
-
[3]
3d ultrasound-guided robotic steering of a flexible needle via visual servoing,
P. Chatelainet al., “3d ultrasound-guided robotic steering of a flexible needle via visual servoing,” in2015 IEEE international conference on robotics and automation (ICRA), pp. 2250–2255, IEEE, 2015
2015
-
[4]
Advancements in needle visualization enhance- ment and localization methods in ultrasound: a literature review,
A. Kimbowaet al., “Advancements in needle visualization enhance- ment and localization methods in ultrasound: a literature review,” Artificial Intelligence Surgery, vol. 4, no. 3, pp. 149–169, 2024
2024
-
[5]
Towards 3d ultrasound guided needle steering robust to uncertainties, noise, and tissue heterogeneity,
G. Lapougeet al., “Towards 3d ultrasound guided needle steering robust to uncertainties, noise, and tissue heterogeneity,”IEEE Trans- actions on Biomedical Engineering, vol. 68, no. 4, pp. 1166–1177, 2020
2020
-
[6]
Ultrasound-guided model predictive control of needle steering in biological tissue,
M. Khademet al., “Ultrasound-guided model predictive control of needle steering in biological tissue,”Journal of Medical Robotics Research, vol. 1, no. 01, p. 1640007, 2016
2016
-
[7]
J. Achiamet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
S. Baiet al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
A Survey on Vision-Language-Action Models for Embodied AI
Y . Maet al., “A survey on vision-language-action models for embodied ai,”arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Endovla: Dual-phase vision-language-action model for autonomous tracking in endoscopy,
C. K. Nget al., “Endovla: Dual-phase vision-language-action model for autonomous tracking in endoscopy,”arXiv preprint arXiv:2505.15206, 2025
-
[11]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Informa- tion Processing Systems, 2017
2017
-
[12]
A unified framework for microscopy defocus deblur with multi-pyramid transformer and contrastive learning,
Y . Zhanget al., “A unified framework for microscopy defocus deblur with multi-pyramid transformer and contrastive learning,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11125–11136, 2024
2024
-
[13]
Siamrpn++: Evolution of siamese visual tracking with very deep networks,
B. Liet al., “Siamrpn++: Evolution of siamese visual tracking with very deep networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4282–4291, 2019
2019
-
[14]
Motion-guided dual-camera tracker for endoscope tracking and motion analysis in a mechanical gastric simulator,
Y . Zhanget al., “Motion-guided dual-camera tracker for endoscope tracking and motion analysis in a mechanical gastric simulator,” in 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 01–07, IEEE, 2025
2025
-
[15]
Learning needle tip localization from digital subtraction in 2d ultrasound,
C. Mwikirize, J. L. Nosher, and I. Hacihaliloglu, “Learning needle tip localization from digital subtraction in 2d ultrasound,”International journal of computer assisted radiology and surgery, vol. 14, pp. 1017– 1026, 2019
2019
-
[16]
Mambaxctrack: Mamba-based tracker with ssm cross- correlation and motion prompt for ultrasound needle tracking,
Y . Zhanget al., “Mambaxctrack: Mamba-based tracker with ssm cross- correlation and motion prompt for ultrasound needle tracking,”IEEE Robotics and Automation Letters, vol. 10, no. 5, pp. 5130–5137, 2025
2025
-
[17]
Mrtrack: Register mamba for needle tracking with rapid reciprocating motion during ultrasound-guided aspiration biopsy,
Y . Zhanget al., “Mrtrack: Register mamba for needle tracking with rapid reciprocating motion during ultrasound-guided aspiration biopsy,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 407–417, Springer, 2025
2025
-
[18]
A needle in a (medical) haystack: Detecting a biopsy needle in ultrasound images using vision transformers,
A. M. Wijata, B. Pyci ´nski, and J. Nalepa, “A needle in a (medical) haystack: Detecting a biopsy needle in ultrasound images using vision transformers,” in2024 IEEE International Conference on Image Processing (ICIP), pp. 3017–3023, IEEE, 2024
2024
-
[19]
Learning-based needle tip tracking in 2d ultrasound by fusing visual tracking and motion prediction,
W. Yanet al., “Learning-based needle tip tracking in 2d ultrasound by fusing visual tracking and motion prediction,”Medical Image Analysis, vol. 88, p. 102847, 2023
2023
-
[20]
Trackvla: Embodied visual tracking in the wild.arXiv preprint arXiv:2505.23189, 2025a
S. Wanget al., “Trackvla: Embodied visual tracking in the wild,”arXiv preprint arXiv:2505.23189, 2025
-
[21]
Capsdt: Diffusion-transformer for capsule robot manip- ulation,
X. Heet al., “Capsdt: Diffusion-transformer for capsule robot manip- ulation,”arXiv preprint arXiv:2506.16263, 2025
-
[22]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4195–4205, 2023
2023
-
[23]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
Lora: Low-rank adaptation of large language models.,
E. J. Huet al., “Lora: Low-rank adaptation of large language models.,” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[25]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Film: Visual reasoning with a general conditioning layer,
E. Perezet al., “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[27]
Basic techniques and technical tips for ultrasound-guided needle puncture,
Y . Sato, K. Matsueda, and Y . Inaba, “Basic techniques and technical tips for ultrasound-guided needle puncture,”Interventional Radiology, vol. 9, no. 3, pp. 80–85, 2024
2024
-
[28]
Effect of needle insertion speed on tissue injury, stress, and backflow distribution for convection-enhanced delivery in the rat brain,
F. Casanova, P. R. Carney, and M. Sarntinoranont, “Effect of needle insertion speed on tissue injury, stress, and backflow distribution for convection-enhanced delivery in the rat brain,”PLoS One, vol. 9, no. 4, p. e94919, 2014
2014
-
[29]
Siamcar: Siamese fully convolutional classification and regression for visual tracking,
D. Guoet al., “Siamcar: Siamese fully convolutional classification and regression for visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6269– 6277, 2020
2020
-
[30]
Siamban: Target-aware tracking with siamese box adaptive network,
Z. Chenet al., “Siamban: Target-aware tracking with siamese box adaptive network,”IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, vol. 45, no. 4, pp. 5158–5173, 2022
2022
-
[31]
Swintrack: A simple and strong baseline for trans- former tracking,
L. Linet al., “Swintrack: A simple and strong baseline for trans- former tracking,”Advances in Neural Information Processing Systems, vol. 35, pp. 16743–16754, 2022
2022
-
[32]
Mixformer: End-to-end tracking with iterative mixed attention,
Y . Cuiet al., “Mixformer: End-to-end tracking with iterative mixed attention,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13608–13618, 2022
2022
-
[33]
Stmtrack: Template-free visual tracking with space-time memory networks,
Z. Fuet al., “Stmtrack: Template-free visual tracking with space-time memory networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13774–13783, 2021
2021
-
[34]
Tracking meets lora: Faster training, larger model, stronger performance,
L. Linet al., “Tracking meets lora: Faster training, larger model, stronger performance,” inEuropean Conference on Computer Vision, pp. 300–318, Springer, 2024
2024
-
[35]
Online object tracking: A bench- mark,
Y . Wu, J. Lim, and M.-H. Yang, “Online object tracking: A bench- mark,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2411–2418, 2013
2013
-
[36]
Trackingnet: A large-scale dataset and benchmark for object tracking in the wild,
M. Mulleret al., “Trackingnet: A large-scale dataset and benchmark for object tracking in the wild,” inProceedings of the European conference on computer vision (ECCV), pp. 300–317, 2018
2018
-
[37]
Robonurse-vla: Robotic scrub nurse system based on vision-language-action model,
S. Liet al., “Robonurse-vla: Robotic scrub nurse system based on vision-language-action model,”arXiv preprint arXiv:2409.19590, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.