Recognition: unknown
WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
Pith reviewed 2026-05-10 00:14 UTC · model grok-4.3
The pith
Reinforcement learning with cascaded multimodal rewards trains a 7B LLM to generate functional, aesthetic multi-page websites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
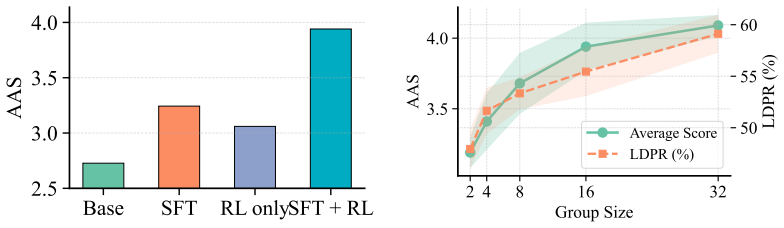
WebGen-R1 applies reinforcement learning to a 7B base model using a scaffold-driven structured generation paradigm that constrains the action space while preserving architectural integrity, paired with a cascaded multimodal reward that combines structural guarantees, execution-grounded functional feedback, and vision-based aesthetic supervision. The trained model produces deployable, aesthetically aligned multi-page websites, outperforming open-source models up to 72B parameters and rivaling the 671B DeepSeek-R1 in functional success while exceeding it in valid rendering and aesthetic alignment.
What carries the argument
The cascaded multimodal reward that couples structural guarantees from scaffolds with execution-based functional verification and vision-model aesthetic scoring to supply training signals for project-level website generation.
Load-bearing premise
The cascaded multimodal reward reliably and unbiasedly evaluates subjective aesthetics and complex cross-page functional interactions without introducing artifacts or overfitting to the reward signals.
What would settle it
Blind human ratings of generated websites showing lower functionality or aesthetic quality than the automated reward scores predict, or head-to-head tests where the 671B model still wins on valid rendering and aesthetics.
Figures






read the original abstract
While Large Language Models (LLMs) excel at function-level code generation, project-level tasks such as generating functional and visually aesthetic multi-page websites remain highly challenging. Existing works are often limited to single-page static websites, while agentic frameworks typically rely on multi-turn execution with proprietary models, leading to substantial token costs, high latency, and brittle integration. Training a small LLM end-to-end with reinforcement learning (RL) is a promising alternative, yet it faces a critical bottleneck in designing reliable and computationally feasible rewards for website generation. Unlike single-file coding tasks that can be verified by unit tests, website generation requires evaluating inherently subjective aesthetics, cross-page interactions, and functional correctness. To this end, we propose WebGen-R1, an end-to-end RL framework tailored for project-level website generation. We first introduce a scaffold-driven structured generation paradigm that constrains the large open-ended action space and preserves architectural integrity. We then design a novel cascaded multimodal reward that seamlessly couples structural guarantees with execution-grounded functional feedback and vision-based aesthetic supervision. Extensive experiments demonstrate that our WebGen-R1 substantially transforms a 7B base model from generating nearly nonfunctional websites into producing deployable, aesthetically aligned multi-page websites. Remarkably, our WebGen-R1 not only consistently outperforms heavily scaled open-source models (up to 72B), but also rivals the state-of-the-art DeepSeek-R1 (671B) in functional success, while substantially exceeding it in valid rendering and aesthetic alignment. These results position WebGen-R1 as a viable path for scaling small open models from function-level code generation to project-level web application generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebGen-R1, an end-to-end RL framework for training LLMs on project-level multi-page website generation. It proposes a scaffold-driven structured generation paradigm to constrain the action space and a cascaded multimodal reward combining structural guarantees, execution-grounded functional feedback, and vision-based aesthetic supervision. Experiments claim that this transforms a 7B base model from nearly nonfunctional outputs to deployable, aesthetically aligned websites, outperforming open-source models up to 72B parameters and rivaling the 671B DeepSeek-R1 in functional success while exceeding it in valid rendering and aesthetic alignment.
Significance. If the cascaded reward proves reliable and non-hackable, the work would be significant for demonstrating scalable RL on complex, multi-component generation tasks beyond single-file code. It offers a potential alternative to high-cost agentic frameworks, with credit due for the end-to-end training setup and explicit handling of cross-page interactions via execution feedback.
major comments (2)
- [Reward design] Reward design section: The cascaded multimodal reward is presented as the solution to the acknowledged bottleneck, yet no ablation studies isolate the contribution of the vision-based aesthetic component versus execution-grounded feedback, nor test for reward hacking on subjective aesthetics or cross-page dynamic interactions. This directly bears on the central claim that the 7B model produces genuinely deployable sites rather than artifacts optimized for the proxy signals.
- [Experiments] Experiments section (results on model comparisons): The reported outperformance over 72B open-source models and rivalry with 671B DeepSeek-R1 in functional success lacks details on evaluation protocol for cross-page functionality (e.g., how dynamic interactions or state consistency are tested) and statistical significance of the gains. Without these, the scaling inversion cannot be confidently attributed to the method rather than evaluation artifacts.
minor comments (2)
- [Abstract/Introduction] The abstract and introduction use 'substantially transforms' and 'remarkably' without quantifying the base model's failure rate or providing concrete examples of pre- vs post-RL outputs in the main text.
- [Method] Notation for the cascaded reward components (structural, execution, vision) should be formalized with equations to clarify weighting and cascading order.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify key aspects of our work. We address each major comment below and will revise the manuscript to incorporate additional details and studies where feasible.
read point-by-point responses
-
Referee: [Reward design] Reward design section: The cascaded multimodal reward is presented as the solution to the acknowledged bottleneck, yet no ablation studies isolate the contribution of the vision-based aesthetic component versus execution-grounded feedback, nor test for reward hacking on subjective aesthetics or cross-page dynamic interactions. This directly bears on the central claim that the 7B model produces genuinely deployable sites rather than artifacts optimized for the proxy signals.
Authors: We agree that dedicated ablation studies would strengthen the evidence for each reward component's contribution. The manuscript presents the cascaded design with structural, execution, and vision elements motivated by the need to address different failure modes, and the overall results show substantial gains over baselines. However, component-wise ablations and explicit reward-hacking analyses (e.g., via human correlation checks or adversarial prompts) were not included in the initial submission. We will add these studies in the revision, including quantitative isolation of the vision-based term and discussion of safeguards against proxy optimization. revision: yes
-
Referee: [Experiments] Experiments section (results on model comparisons): The reported outperformance over 72B open-source models and rivalry with 671B DeepSeek-R1 in functional success lacks details on evaluation protocol for cross-page functionality (e.g., how dynamic interactions or state consistency are tested) and statistical significance of the gains. Without these, the scaling inversion cannot be confidently attributed to the method rather than evaluation artifacts.
Authors: We acknowledge the need for greater transparency in the evaluation protocol. The current manuscript defines functional success via execution-based checks for multi-page navigation and interactions, but we will expand the Experiments section with explicit descriptions of the testing harness (browser-based execution of cross-page flows, state persistence verification, and scripted dynamic interactions). We will also report results with error bars and statistical significance tests across multiple evaluation runs to support attribution of gains to the method rather than artifacts. revision: yes
Circularity Check
No circularity: derivation relies on external execution and vision-model rewards
full rationale
The paper's central claim is that RL training with a cascaded reward (structural + execution-grounded + vision-based) transforms a 7B model into producing functional multi-page sites that outperform larger baselines. No equations or steps reduce the reported gains to a self-definition, fitted input renamed as prediction, or self-citation chain. The reward components are described as external (code execution feedback and separate vision models), not derived from the model's own outputs or prior self-citations. The scaffold-driven generation and reward design are presented as independent engineering choices whose validity is tested via external benchmarks, not assumed by construction. This is the normal non-circular case for an RL paper whose success metric is downstream performance on held-out evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Iterative refinement of project-level code context for precise code generation with compiler feedback
Zhangqian Bi, Yao Wan, Zheng Wang, Hongyu Zhang, Batu Guan, Fangxin Lu, Zili Zhang, Yulei Sui, Hai Jin, and Xuanhua Shi. Iterative refinement of project-level code context for precise code generation with compiler feedback. InFindings of the Association for Computational Linguistics ACL 2024, pages 2336–2353, 2024
2024
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Stepcoder: Improve code generation with reinforcement learning from compiler feedback
Shihan Dou, Yan Liu, Haoxiang Jia, Limao Xiong, Enyu Zhou, Wei Shen, Junjie Shan, Caishuang Huang, Xiao Wang, Xiaoran Fan, et al. Stepcoder: Improve code generation with reinforcement learning from compiler feedback.arXiv preprint arXiv:2402.01391, 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6864–6890, 2024. 13
2024
-
[12]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Hongming Zhang, Tianqing Fang, Zhen- zhong Lan, and Dong Yu. Openwebvoyager: Building multimodal web agents via iterative real-world exploration, feedback and optimization.arXiv preprint arXiv:2410.19609, 2024
-
[13]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework.arXiv preprint arXiv:2308.00352, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
2025
-
[15]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Juyong Jiang, Jiasi Shen, Sunghun Kim, Kang Min Yoo, Jeonghoon Kim, and Sungju Kim. Reflexicoder: Teaching large language models to self-reflect on generated code and self-correct it via reinforcement learning.arXiv preprint arXiv:2603.05863, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
2026
-
[20]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Coderl: Mastering code generation through pretrained models and deep reinforcement learning
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems, 35:21314–21328, 2022
2022
-
[22]
arXiv preprint arXiv:2309.00267 , year=
Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback.arXiv preprint arXiv:2309.00267, 2023
-
[23]
CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models,
Jierui Li, Hung Le, Yingbo Zhou, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Codetree: Agent-guided tree search for code generation with large language models.arXiv preprint arXiv:2411.04329, 2024
-
[24]
Osvbench: Benchmarking llms on specification generation tasks for operating system verification
Shangyu Li, Juyong Jiang, Tiancheng Zhao, and Jiasi Shen. Osvbench: Benchmarking llms on specification generation tasks for operating system verification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31698–31707, 2026
2026
-
[25]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[26]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Webdev arena: Ai battle to build the best website
LMArena. Webdev arena: Ai battle to build the best website. https://web.lmarena.ai/, 2025
2025
-
[28]
Zimu Lu, Yunqiao Yang, Houxing Ren, Haotian Hou, Han Xiao, Ke Wang, Weikang Shi, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Webgen-bench: Evaluating llms on generating interactive and functional websites from scratch.arXiv preprint arXiv:2505.03733, 2025. 14
-
[29]
Deepswe: Training a state-of-the-art coding agent from scratch by scaling rl
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Alpay Ariyak, Colin Cai, Shang Zhu Tarun Venkat, Ben Athiwaratkun, Manan Roongta, Ce Zhang, Li Erran Li, Raluca Ada Popa, Koushik Sen, and Ion Stoica. Deepswe: Training a state-of-the-art coding agent from scratch by scaling rl. https://pretty-radio-b75.notion.site/DeepSWE-T rai...
2025
-
[30]
Deepcoder: A fully open-source 14b coder at o3-mini level
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, Ce Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepcoder: A fully open-source 14b coder at o3-mini level. https://pretty-radio -b75.notion.site/DeepCoder-A-Fully-Open-Source-14B-Coder-at-O3-mini-Lev el-1cf81902c14680b3be...
2025
-
[31]
Youssef Mroueh. Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynam- ics, and success amplification.arXiv preprint arXiv:2503.06639, 2025
-
[32]
Is self-repair a silver bullet for code generation? InThe Twelfth International Conference on Learning Representations, 2023
Theo X Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar- Lezama. Is self-repair a silver bullet for code generation? InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[33]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[34]
Chansung Park, Juyong Jiang, Fan Wang, Sayak Paul, Jiasi Shen, Jing Tang, and Jianguo Li. Tarot: Test-driven and capability-adaptive curriculum reinforcement fine-tuning for code generation with large language models.arXiv preprint arXiv:2602.15449, 2026
-
[35]
Llamaduo: Llmops pipeline for seamless migration from service llms to small-scale local llms
Chansung Park, Juyong Jiang, Fan Wang, Sayak Paul, and Jing Tang. Llamaduo: Llmops pipeline for seamless migration from service llms to small-scale local llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33194–33215, 2025
2025
-
[36]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[37]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
arXiv preprint arXiv:2307.14936 , year =
Bo Shen, Jiaxin Zhang, Taihong Chen, Daoguang Zan, Bing Geng, An Fu, Muhan Zeng, Ailun Yu, Jichuan Ji, Jingyang Zhao, et al. Pangu-coder2: Boosting large language models for code with ranking feedback.arXiv preprint arXiv:2307.14936, 2023
-
[40]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[41]
Execution-based code generation using deep reinforcement learning.Transactions on Machine Learning Research, 2023
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K Reddy. Execution-based code generation using deep reinforcement learning.Transactions on Machine Learning Research, 2023
2023
-
[42]
Repository-level prompt generation for large language models of code
Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-level prompt generation for large language models of code. InInternational Conference on Machine Learning, pages 31693–31715. PMLR, 2023. 15
2023
-
[43]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Mrweb: An exploration of generating multi-page resource-aware web code from ui designs
Yuxuan Wan, Yi Dong, Jingyu Xiao, Yintong Huo, Wenxuan Wang, and Michael R Lyu. Mrweb: An exploration of generating multi-page resource-aware web code from ui designs. arXiv preprint arXiv:2412.15310, 2024
-
[45]
arXiv preprint arXiv:2412.06071 , year=
Fan Wang, Juyong Jiang, Chansung Park, Sunghun Kim, and Jing Tang. Kasa: Knowledge- aware singular-value adaptation of large language models.arXiv preprint arXiv:2412.06071, 2024
-
[46]
Self-instruct: Aligning language models with self-generated in- structions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated in- structions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, 2023
2023
-
[47]
Xumeng Wen, Zihan Liu, Shun Zheng, Zhijian Xu, Shengyu Ye, Zhirong Wu, Xiao Liang, Yang Wang, Junjie Li, Ziming Miao, et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245, 2025
work page internal anchor Pith review arXiv 2025
-
[48]
Interaction2code: How far are we from automatic interactive webpage generation?arXiv e-prints, pages arXiv–2411, 2024
Jingyu Xiao, Yuxuan Wan, Yintong Huo, Zhiyao Xu, and Michael R Lyu. Interaction2code: How far are we from automatic interactive webpage generation?arXiv e-prints, pages arXiv–2411, 2024
2024
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Zhicheng Yang, Zhijiang Guo, Yinya Huang, Yongxin Wang, Dongchun Xie, Yiwei Wang, Xiaodan Liang, and Jing Tang. Depth-breadth synergy in rlvr: Unlocking llm reasoning gains with adaptive exploration.arXiv preprint arXiv:2508.13755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, et al. Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
-
[53]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Chenchen Zhang, Yuhang Li, Can Xu, Jiaheng Liu, Ao Liu, Shihui Hu, Dengpeng Wu, Guanhua Huang, Kejiao Li, Qi Yi, et al. Artifactsbench: Bridging the visual-interactive gap in llm code generation evaluation.arXiv preprint arXiv:2507.04952, 2025
-
[55]
Repocoder: Repository-level code completion through iterative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian- Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2471–2484, 2023
2023
-
[56]
Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13643–13658, 2024
2024
-
[57]
Terry Yue Zhuo, Xiaolong Jin, Hange Liu, Juyong Jiang, Tianyang Liu, Chen Gong, Bhupesh Bishnoi, Vaisakhi Mishra, Marek Suppa, Noah Ziems, et al. Bigcodearena: Unveiling more reliable human preferences in code generation via execution.arXiv preprint arXiv:2510.08697, 2025. 16 Table 5: Statistics of the WebGen-Bench and WebDev Arena benchmarks, including t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.