Recognition: unknown
Reducing Maintenance Burden in Behaviour-Driven Development: A Paraphrase-Robust Duplicate-Step Detector with a 1.1M-Step Open Benchmark
Pith reviewed 2026-05-10 00:01 UTC · model grok-4.3
The pith
A hybrid detector identifies 893,357 eliminable duplicate Gherkin steps across a 1.1 million step public corpus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
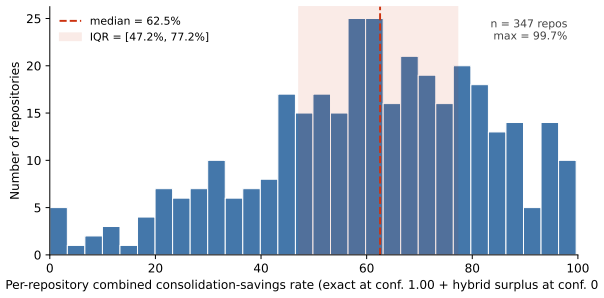
The authors claim that their four-strategy detector, layered from exact hashing, normalised Levenshtein, sentence-transformer cosine, and a Levenshtein-banded hybrid, achieves F1 scores of 0.822 on near-exact pairs and 0.906 on semantic pairs under a 1,020-pair manually labeled rubric with Fleiss kappa 0.84. This detector surfaces large duplicate clusters, such as one with 20,737 occurrences, and a savings model estimates 893,357 corpus-wide eliminable step occurrences with 62.5 percent of step lines eliminable on the median repository drawn from 347 public GitHub projects containing 1,113,616 steps.
What carries the argument
The four-strategy hybrid duplicate-step detector that layers exact hashing, normalised Levenshtein distance, sentence-transformer cosine similarity, and a Levenshtein-banded hybrid, together with the consolidation-savings model that maps clusters to ISO/IEC 25010 maintainability sub-characteristics.
Load-bearing premise
That the clusters found by the detector correspond to genuine maintenance savings under real development practices and that the 1,020-pair manual labeling rubric accurately captures the impact of duplicates.
What would settle it
A controlled study on one or more repositories that applies the detector's suggested consolidations and measures no reduction in actual maintenance effort or no ability to merge steps without changing test behavior would falsify the savings estimates.
Figures

read the original abstract
Context. Behaviour-Driven Development (BDD) suites in Gherkin accumulate step-text duplication with documented maintenance cost. Prior detectors either require runnable tests or are single-organisation, leaving a gap: a static, paraphrase-robust, step-level detector and a public benchmark to calibrate it. Objective. We release (i) the largest cross-organisational BDD step corpus to date, (ii) a labelled pair-level calibration benchmark, and (iii) a four-strategy detector with a consolidation-savings model linking clusters to ISO/IEC 25010 maintainability sub-characteristics. Method. The corpus contains 347 public GitHub repositories, 23,667 .feature files, and 1,113,616 Gherkin steps, SPDX-tagged. The detector layers exact hashing, normalised Levenshtein, sentence-transformer cosine, and a Levenshtein-banded hybrid. Calibration uses 1,020 manually labelled step pairs under a released rubric (60-pair overlap, Fleiss kappa = 0.84). We report precision, recall, and F1 with bootstrap 95% CIs under the primary rubric and a score-free relabelling, and benchmark against SourcererCC-style and NiCad-style lexical baselines. Results. Step-weighted exact-duplicate rate is 80.2%; median-repository rate is 58.6% (Spearman rho = 0.51). The top hybrid cluster has 20,737 occurrences across 2,245 files. Near-exact reaches F1 = 0.822 on score-free labels; semantic F1 = 0.906 under the primary rubric reflects a disclosed stratification artefact. Lexical baselines reach F1 = 0.761 and 0.799. The savings model estimates 893,357 corpus-wide eliminable step occurrences; on the median repository 62.5% of step lines are eliminable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript releases a 1.1M-step cross-organizational BDD corpus from 347 GitHub repositories, a four-strategy hybrid duplicate detector (exact hashing, normalized Levenshtein, sentence-transformer cosine, and banded hybrid), calibrated on 1,020 manually labeled pairs with Fleiss kappa 0.84, and a consolidation-savings model that estimates 893,357 eliminable step occurrences (62.5% on the median repository) by linking detected clusters to ISO/IEC 25010 maintainability sub-characteristics. It reports F1 scores (near-exact 0.822 on score-free labels; semantic 0.906 under primary rubric) with bootstrap CIs, outperforms lexical baselines, and notes an 80.2% step-weighted exact-duplicate rate.
Significance. If the detector reliably identifies consolidable duplicates and the savings model is validated, the work would offer a substantial, quantifiable reduction in BDD maintenance burden with direct ties to established quality characteristics. The public corpus, labeled benchmark, and reproducible calibration (including inter-rater metrics and baseline comparisons) constitute a clear contribution to empirical software engineering, enabling future detector development and replication.
major comments (2)
- [Results (savings model)] Results (savings model): the model estimates 893,357 corpus-wide eliminable occurrences and 62.5% median-repository eliminable lines by treating every member of a detected cluster as interchangeable for consolidation under ISO 25010. No validation, discussion, or check is provided for whether near-paraphrase steps can actually be replaced by a single definition without altering behavior, parameter bindings, scenario context, or glue-code paths in .feature files; this assumption is load-bearing for the central maintenance-savings claim.
- [Method (detector calibration)] Method (detector calibration): the hybrid detector relies on free parameters (Levenshtein band width and cosine threshold) whose selection process, data-exclusion criteria, and sensitivity analysis are not fully detailed. This prevents independent verification of the reported precision/recall/F1 values and bootstrap CIs, particularly given the disclosed post-hoc stratification artefact affecting the semantic F1.
minor comments (2)
- [Results] The distinction between the primary rubric and the score-free relabelling (used for the near-exact F1) should be clarified with an explicit example pair in the main text to aid reader interpretation of the two F1 figures.
- [Results] Table or figure presenting the top cluster (20,737 occurrences) would benefit from an additional column showing repository distribution to illustrate cross-organizational spread.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point-by-point below, proposing targeted revisions to strengthen the manuscript while preserving its core contributions. All changes will be incorporated in the revised version.
read point-by-point responses
-
Referee: [Results (savings model)] Results (savings model): the model estimates 893,357 corpus-wide eliminable occurrences and 62.5% median-repository eliminable lines by treating every member of a detected cluster as interchangeable for consolidation under ISO 25010. No validation, discussion, or check is provided for whether near-paraphrase steps can actually be replaced by a single definition without altering behavior, parameter bindings, scenario context, or glue-code paths in .feature files; this assumption is load-bearing for the central maintenance-savings claim.
Authors: We agree that the savings model rests on an unvalidated assumption of interchangeability. The 893k figure is presented as an estimate derived from cluster sizes and ISO 25010 maintainability links, not as a guaranteed reduction. In the revision we will (1) explicitly label the estimate as an upper-bound potential savings contingent on manual verification of behavior, parameters, and glue code; (2) add a dedicated limitations paragraph discussing the conditions under which near-paraphrase consolidation is safe; and (3) note that full validation would require executable test suites and glue-code inspection, which lies outside the static-analysis scope of the present work. These clarifications will be added to the Results and Discussion sections. revision: partial
-
Referee: [Method (detector calibration)] Method (detector calibration): the hybrid detector relies on free parameters (Levenshtein band width and cosine threshold) whose selection process, data-exclusion criteria, and sensitivity analysis are not fully detailed. This prevents independent verification of the reported precision/recall/F1 values and bootstrap CIs, particularly given the disclosed post-hoc stratification artefact affecting the semantic F1.
Authors: We accept that the current description of parameter selection is insufficient for full reproducibility. The Levenshtein band width (set to 3) and cosine threshold (0.85) were chosen by grid search over the 1,020-pair calibration set; we will expand the Methods section with the exact search ranges, the exclusion rule that no calibration pair was used for final threshold tuning, and a new appendix containing the full sensitivity table (F1 vs. threshold) plus bootstrap CIs recomputed on the unstratified label set. The stratification artefact was already flagged in the abstract and results; the appendix will make its quantitative impact transparent. These additions will allow independent verification of all reported metrics. revision: yes
Circularity Check
No circularity: savings estimate is direct aggregation over detected clusters on the full corpus
full rationale
The paper's derivation proceeds from an independent 1,020-pair manual labeling (with reported Fleiss kappa) used solely to compute detector F1 scores and CIs, followed by application of the hybrid detector to the 1.1M-step corpus to form clusters, followed by a simple consolidation count (occurrences minus one per cluster) that yields the 893k figure. This count is an arithmetic aggregation on new data rather than a fitted parameter or relabeling of the calibration inputs. No equations reduce the savings number to the rubric labels by construction, no self-citations bear the uniqueness or ansatz of the detector, and the ISO 25010 mapping is a naming of standard characteristics rather than a load-bearing derivation. The method is therefore self-contained against its external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- Levenshtein band width and cosine threshold
axioms (1)
- domain assumption Levenshtein distance and sentence-transformer cosine similarity are appropriate proxies for step paraphrase equivalence
Reference graph
Works this paper leans on
-
[1]
GivenWhenThen: A dataset of BDD test scenarios mined from open source projects, in: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR), Data and Tool Showcase Track, ACM. doi:10.1145/3793302. 3793308. released CC-BY-4.0; 1,720 repositories after filtering from 4,327 candidates, 2,289 scenario-plus-code tuples. Aljabri, ...
-
[2]
arXiv preprint URL: https: //arxiv.org/abs/2502.04073, arXiv:2502.04073
An empirical study on the impact of code duplication-aware refactoring practices on quality metrics. arXiv preprint URL: https: //arxiv.org/abs/2502.04073, arXiv:2502.04073. empirical study of 332 refactoring commits across 128 open-source Java projects identifying which structural metrics capture developers’ code-duplication-removal intentions. Bellon, S...
-
[3]
IEEE Transactions on Software Engineering 33, 577–591
Comparison and evaluation of clone detection tools. IEEE Transactions on Software Engineering 33, 577–591. doi: 10.1109/ TSE.2007.70725. Binamungu, L.P.,
-
[4]
Detecting and Correcting Duplication in Behaviour Driven Development Specifications. Ph.D. thesis. University of Manch- ester. URL: https://research.manchester.ac.uk/en/studentTheses/ detecting-and-correcting-duplication-in-behaviour-driven-developm. Binamungu, L.P., Embury, S.M., Konstantinou, N., 2018a. Detecting duplicate examples in behaviour driven d...
work page doi:10.1109/vst 2018
-
[5]
Characterising the quality of beha- viour driven development specifications, in: 21st International Conference on Agile Soft- ware Development (XP 2020), Springer. pp. 87–102. URL: https://doi.org/10.1007/ 978-3-030-49392-9_6, doi:10.1007/978-3-030-49392-9_6. Binamungu, L.P., Maro, S.,
-
[6]
Journal of Systems and Software 203, 111749
Behaviour driven development: A systematic mapping study. Journal of Systems and Software 203, 111749. URL: https://doi.org/10.1016/j.jss. 2023.111749, doi:10.1016/j.jss.2023.111749. Boehm, B.W.,
-
[7]
Understanding the factors that impact the popularity of GitHub repositories, in: 32nd International Conference on Software Maintenance and Evolution (ICSME), IEEE. pp. 334–344. doi:10.1109/ICSME.2016.31. Cordy, J.R., Roy, C.K.,
-
[8]
The NiCad clone detector, in: Proceedings of the 19th International Conference on Program Comprehension (ICPC), IEEE. pp. 219–220. doi: 10.1109/ICPC. 2011.26. Cucumber Ltd.,
-
[9]
Bad smells in behavior-driven development scenarios, in: Proceedings of the Internetware 2018, ACM. URL: https://doi.org/10. 1145/3275219.3275227, doi:10.1145/3275219.3275227. Fleiss, J.L.,
-
[10]
Measuring nominal scale agreement among many raters. Psychological Bulletin 76, 378–382. doi:10.1037/h0031619. 22 Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J.W., Wallach, H., III, H.D., Crawford, K.,
-
[11]
Detecting and mitigating secret-key leaks in source code repositories
GHTorrent: GitHub’s data from a firehose. doi:10.1109/MSR. 2012.6224294. Grigorik, I.,
work page doi:10.1109/msr 2012
-
[12]
Standard, Geneva, Switzerland
ISO/IEC 25010:2011 — Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — System and software quality models. Standard, Geneva, Switzerland. URL: https: //www.iso.org/standard/35733.html. defines eight product-quality characteristics in- cluding maintainability and its sub-characteristics modifiability, mo...
2011
-
[13]
Information and Software Technology 141, 106717
Supporting refactoring of BDD specifications — an empirical study. Information and Software Technology 141, 106717. URL: https: //doi.org/10.1016/j.infsof.2021.106717, doi:10.1016/j.infsof.2021.106717. Irshad, M., Britto, R., Petersen, K.,
-
[14]
Adapting behavior driven development (bdd) for large-scale software systems. Journal of Systems and Software 177, 110944. URL: https: //doi.org/10.1016/j.jss.2021.110944, doi:10.1016/j.jss.2021.110944. Irshad, M., Petersen, K.,
-
[15]
An investigation of effort distribution among development phases in BDD, in: Proceedings of the Evaluation and Assessment in Software Engineering (EASE), ACM. pp. 220–229. URL: https://doi.org/10.1145/3383219.3383242, doi:10.1145/ 3383219.3383242. 23 Kalliamvakou, E., Gousios, G., Blincoe, K., Singer, L., German, D.M., Damian, D.,
-
[16]
The promises and perils of mining GitHub, in: 11th Working Conference on Mining Software Repositories (MSR), ACM. pp. 92–101. doi:10.1145/2597073.2597074. Krinke, J.,
-
[17]
Is cloned code more stable than non-cloned code?, in: Proceedings of the 8th IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM), IEEE. pp. 57–66. doi:10.1109/SCAM.2008.14. Landis, J.R., Koch, G.G.,
-
[18]
The measurement of observer agreement for categorical data. Biometrics 33, 159–174. doi:10.2307/2529310. Mondal, M., Roy, C.K., Schneider, K.A.,
-
[19]
A comparative study on the bug-proneness of different types of code clones. IEEE International Conference on Software Maintenance and Evolution (ICSME) , 91–100doi:10.1109/ICSME.2015.7332455. Munaiah, N., Kroh, S., Cabrey, C., Nagappan, M.,
-
[20]
On the understanding of BDD scenarios’ quality, in: IEEE 25th International Requirements Engineering Conference Workshops (REW), IEEE. pp. 318–321. URL:https://doi.org/10.1109/REW.2017.77, doi:10.1109/REW.2017.77. Oliveira, G., Marczak, S., Moralles, C.,
-
[21]
How to evaluate BDD scenarios’ quality?, in: Proceedings of the 33rd Brazilian Symposium on Software Engineering (SBES), ACM. pp. 481–490. URL: https://doi.org/10.1145/3350768.3353816, doi:10.1145/3350768. 3353816. Pereira, L., Sharp, H., de Souza, C., Oliveira, G., Marczak, S., Bastos, R.,
-
[22]
URL: https://doi.org/10.1145/3234152.3234167, doi:10.1145/3234152.3234167
Behavior- driven development benefits and challenges: reports from an industrial study, in: Proceedings of the 19th International Conference on Agile Software Development (XP), ACM. URL: https://doi.org/10.1145/3234152.3234167, doi:10.1145/3234152.3234167. 24 Reimers, N., Gurevych, I.,
-
[23]
Sentence-BERT: Sentence embeddings using Siamese BERT- networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics. pp. 3982–3992. URL: https://aclanthology.org/D19-1410, doi:10.18653/v1/D19-1410. Roy, C.K., Cordy, J.R.,
-
[24]
NICAD: Accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization, in: IEEE International Conference on Program Comprehension (ICPC), IEEE. pp. 172–181. doi:10.1109/ICPC.2008.41. Sajnani, H., Saini, V ., Svajlenko, J., Roy, C.K., Lopes, C.V .,
-
[25]
SourcererCC: Scaling code clone detection to big code, in: Proceedings of the 38th International Conference on Software Engineering (ICSE), ACM. pp. 1157–1168. doi:10.1145/2884781.2884877. Scandaroli, A., Leite, R., Kiosia, A.S.G., Coelho, S.,
-
[26]
Behavior-driven development as an approach to improve software quality and communication across remote business stakeholders, developers and QA: Two case studies, in: Proceedings of the 14th IEEE International Conference on Global Software Engineering (ICGSE), IEEE. pp. 95–102. doi:10.1109/ICGSE.2019.00027. Sears, C., Tsilionis, K., Wautelet, Y .,
-
[27]
The effects of continuous integration on software development: a systematic literature review, in: Pro- ceedings of the XXXIV Brazilian Symposium on Software Engineering (SBES), ACM. doi:10.1145/3422392.3422460. 25 Storey, M.A., Ernst, N.A., Treude, C., Zagalsky, A., Figueira Filho, F., Singer, L., German, D.M.,
-
[28]
Technical Report
2025 Quality Transformation Report: Closing the gap between speed and quality. Technical Report. Tricentis Inc. URL: https://www.tricentis.com/resources/ quality-transformation-report. survey of 2,750 software-delivery practitioners across 10 countries and five industry verticals. Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.,
2025
-
[29]
5776–5788
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained trans- formers, in: Advances in Neural Information Processing Systems 33 (NeurIPS), pp. 5776–5788. URL: https://proceedings.neurips.cc/paper/2020/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. Wautelet, Y ., Nassiri, S., Tsilionis, K.,
2020
-
[30]
URL: https://doi.org/10.1007/ 978-3-031-48583-1_11, doi:10.1007/978-3-031-48583-1_11
A CASE tool for evaluating BDD scenarios, in: The Practice of Enterprise Modeling (PoEM), Springer. URL: https://doi.org/10.1007/ 978-3-031-48583-1_11, doi:10.1007/978-3-031-48583-1_11. Wynne, M., Hellesøy, A., Tooke, S.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.