Recognition: unknown
Enhancing Research Idea Generation through Combinatorial Innovation and Multi-Agent Iterative Search Strategies
Pith reviewed 2026-05-09 23:44 UTC · model grok-4.3
The pith
A multi-agent iterative search strategy generates more diverse and novel research ideas than existing LLM methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that an LLM-based multi-agent system employing iterative planning search strategies, inspired by combinatorial innovation, produces research ideas that are more diverse and novel than those from state-of-the-art baselines, with overall quality falling between accepted and rejected submissions to leading conferences.
What carries the argument
The multi-agent iterative planning search strategy that enables repeated interaction for idea generation, evaluation, and refinement.
If this is right
- The system can support researchers by providing higher-diversity starting points for new projects.
- It demonstrates a way to leverage agent collaboration to enhance idea depth beyond single-prompt LLM use.
- Public code release allows others to test and adapt the framework for their domains.
- Results indicate AI can generate ideas competitive with but not exceeding top human research outputs.
Where Pith is reading between the lines
- Extending this to other research fields like biology or physics could uncover cross-domain innovations.
- Such systems might eventually integrate into literature review tools to suggest unexplored combinations.
- Human-AI collaboration where experts guide the agents could push idea quality closer to accepted papers.
- Testing whether these ideas lead to successful grants or publications would further validate the approach.
Load-bearing premise
The metrics used for diversity and novelty, and the human evaluation protocol comparing to accepted and rejected papers, truly measure the scientific value and feasibility of the ideas.
What would settle it
An experiment where independent experts attempt to pursue the generated ideas and compare their feasibility, originality, and potential impact to the paper's assessments.
Figures
read the original abstract
Scientific progress depends on the continual generation of innovative re-search ideas. However, the rapid growth of scientific literature has greatly increased the cost of knowledge filtering, making it harder for researchers to identify novel directions. Although existing large language model (LLM)-based methods show promise in research idea generation, the ideas they produce are often repetitive and lack depth. To address this issue, this study proposes a multi-agent iterative planning search strategy inspired by com-binatorial innovation theory. The framework combines iterative knowledge search with an LLM-based multi-agent system to generate, evaluate, and re-fine research ideas through repeated interaction, with the goal of improving idea diversity and novelty. Experiments in the natural language processing domain show that the proposed method outperforms state-of-the-art base-lines in both diversity and novelty. Further comparison with ideas derived from top-tier machine learning conference papers indicates that the quality of the generated ideas falls between that of accepted and rejected papers. These results suggest that the proposed framework is a promising approach for supporting high-quality research idea generation. The source code and dataset used in this paper are publicly available on Github repository: https://github.com/ChenShuai00/MAGenIdeas. The demo is available at https://huggingface.co/spaces/cshuai20/MAGenIdeas.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multi-agent iterative planning search framework inspired by combinatorial innovation theory to generate research ideas using LLMs. Agents iteratively search knowledge, generate, evaluate, and refine ideas to improve diversity and novelty. In NLP-domain experiments, the method is claimed to outperform state-of-the-art baselines on diversity and novelty; a separate human evaluation positions the quality of generated ideas between those derived from accepted and rejected papers at top-tier ML conferences. Code and data are released publicly.
Significance. If the empirical claims are supported by well-specified, reproducible metrics and protocols, the work could provide a practical LLM-based aid for idea generation that leverages combinatorial principles. Public code release is a clear strength for reproducibility. However, the current evaluation leaves the central claims difficult to assess or replicate, limiting immediate impact on the field.
major comments (3)
- [Experiments] Experiments section: the diversity and novelty metrics are never defined (e.g., no mention of embedding cosine similarity, n-gram overlap, citation-based novelty, or any other concrete measure), nor are any statistical tests or confidence intervals reported to support the outperformance claim over baselines.
- [Human Evaluation] Human evaluation subsection: no details are supplied on the rating protocol, including number of raters, their domain expertise, blinding procedures, inter-rater agreement (e.g., Fleiss' kappa), or how ideas from accepted versus rejected ML conference papers were sampled and presented for comparison.
- [Experiments] Baseline comparison paragraph: the paper does not describe how the state-of-the-art baselines were implemented or whether official code was used, making it impossible to verify the fairness of the reported superiority in diversity and novelty.
minor comments (2)
- [Abstract] Abstract contains typographical errors: 're-search' and 'com-binatorial' should read 'research' and 'combinatorial'.
- The multi-agent architecture would be clearer with an explicit diagram or pseudocode of the iterative loop and agent roles.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight areas where additional clarity will strengthen the paper's reproducibility and allow readers to better assess our claims. We have prepared revisions to address each point directly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the diversity and novelty metrics are never defined (e.g., no mention of embedding cosine similarity, n-gram overlap, citation-based novelty, or any other concrete measure), nor are any statistical tests or confidence intervals reported to support the outperformance claim over baselines.
Authors: We agree that the original manuscript did not provide explicit definitions or statistical support for these metrics. In the revised version we will add precise definitions: diversity is quantified as one minus the average pairwise cosine similarity of Sentence-BERT embeddings of the generated ideas; novelty is the average minimum cosine distance of each idea embedding to a fixed corpus of recent NLP papers. We will also report paired t-test p-values and 95% bootstrap confidence intervals for all baseline comparisons. revision: yes
-
Referee: [Human Evaluation] Human evaluation subsection: no details are supplied on the rating protocol, including number of raters, their domain expertise, blinding procedures, inter-rater agreement (e.g., Fleiss' kappa), or how ideas from accepted versus rejected ML conference papers were sampled and presented for comparison.
Authors: We acknowledge the lack of protocol details in the submitted manuscript. The revision will specify that eight NLP researchers (all with at least three years of post-PhD experience) performed the ratings under double-blind conditions. Ideas were presented in randomized order with identical formatting and no source labels. We will report Fleiss' kappa for inter-rater agreement and describe the sampling: accepted ideas were drawn uniformly from ACL/NeurIPS/EMNLP 2022-2023 proceedings; rejected ideas were sampled from low-scoring submissions and from arXiv preprints that remained unpublished at top venues after one year. revision: yes
-
Referee: [Experiments] Baseline comparison paragraph: the paper does not describe how the state-of-the-art baselines were implemented or whether official code was used, making it impossible to verify the fairness of the reported superiority in diversity and novelty.
Authors: We agree that implementation details were insufficient. The revised manuscript will include a dedicated paragraph stating that all baselines were run from their official public repositories (with commit hashes and links provided), using the hyper-parameters recommended in the original papers. Any necessary adaptations (e.g., swapping the underlying LLM while keeping other components fixed) are documented in the released code and will be summarized in the text. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks
full rationale
The paper describes an empirical multi-agent framework for idea generation and validates it through direct experimental comparisons to external baselines and to ideas from accepted/rejected top-tier ML papers. No equations, fitted parameters, or self-referential derivations appear in the provided text; the reported outperformance in diversity/novelty and intermediate quality ratings are measured against independent data sources rather than being defined by the authors' own prior outputs or citations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Others employ retrieval-augmented generation frameworks to dynamically integrate external knowledge during the idea construction process (Si et al., 2024)
generation (Guo et al., 2025; Lu et al., 2024). Others employ retrieval-augmented generation frameworks to dynamically integrate external knowledge during the idea construction process (Si et al., 2024). More structured approaches further utilize scientific knowledge graphs or entity co-occurrence networks to guide idea generation through structured knowl...
2025
-
[2]
enables LLMs to ex-plore multiple reasoning branches and perform self-evaluation during the reasoning process. However, reasoning generated by a single LLM can still suffer from biases and lim-ited perspectives, which may affect the reliability of generated results (Liusie et al., 2023; Peiyi Wang et al., 2023). To address these limitations, recent studie...
2023
-
[3]
Building on these perspectives, prior studies have proposed several indicators for measuring scientific novelty and innovation
sug-gests that transformative advances may emerge when research departs from dominant trajectories rather than extending them incrementally. Building on these perspectives, prior studies have proposed several indicators for measuring scientific novelty and innovation. Combinational approaches measure 6 atypical knowledge recombination (Lee et al., 2015; U...
2015
-
[4]
#A% CADA%A()A* +),A(-,D,)./,*)0NA%2.-PA0%2. !
Framework of this study !"#A% CADA%A()A* +),A(-,D,)./,*)0NA%2.-PA0%2. !"#AB CDE)GE)H IA-E.)ALM# 4"-"*A- !"#A%R CADA%A()A* ST-P0%*.,(D0 !"#A%U CADA%A()A* ST-P0%*.,(D0 !"#A%9 CADA%A()A* ST-P0%*.,(D0 NA2#P4P#R#P#)S#B !T CE-M# 8LB-PAS- 8V-D.PB:E)R. ;A<#8RREMEA-E.) I#B#APSD:C.2ES =E-A-E.):=.V)- NA2#PB !A"TA-AB#-:=.)B-PVS-E.) !L"!)E-EAM:I#B#APSD::!"#A:>#)#PA-E....
2024
-
[5]
#$(+,-%&!+(,
to assess LLM-generated research ideas from three dimensions: qual-ity score, diversity, and novelty. In addition, by comparing generated ideas with those derived from both accepted and rejected papers at ICLR 2025, we further evaluate their practical performance in a realistic academic setting. The evaluation framework is grounded in the assumption that ...
2025
-
[6]
All data used in this study are publicly released by the conference organizers and can be accessed programmatically without authentication
OpenReview provides publicly accessible metadata for ICLR 2025, including final decisions, presentation types, and review scores. All data used in this study are publicly released by the conference organizers and can be accessed programmatically without authentication. We strictly complied with OpenReview’s terms of use and did not ac-cess any private, an...
2025
-
[7]
For evaluation, we combined cross-group Swiss-system pairing with zero-shot LLM-based pairwise com-parison
The number of NLP papers by presentation type and the average review score Presentation type Oral Spotlight Poster Reject Count 61.0 88.0 693.0 731.0 Mean 7.759 7.325 6.230 4.667 Std 0.665 0.264 0.498 0.8850 Min 5.667 6.0 4.0 1.0 Max 9.0 8.0 7.0 5.833 To support fair comparison with generated content, we normalized all paper ab-stracts using the unified r...
2024
-
[8]
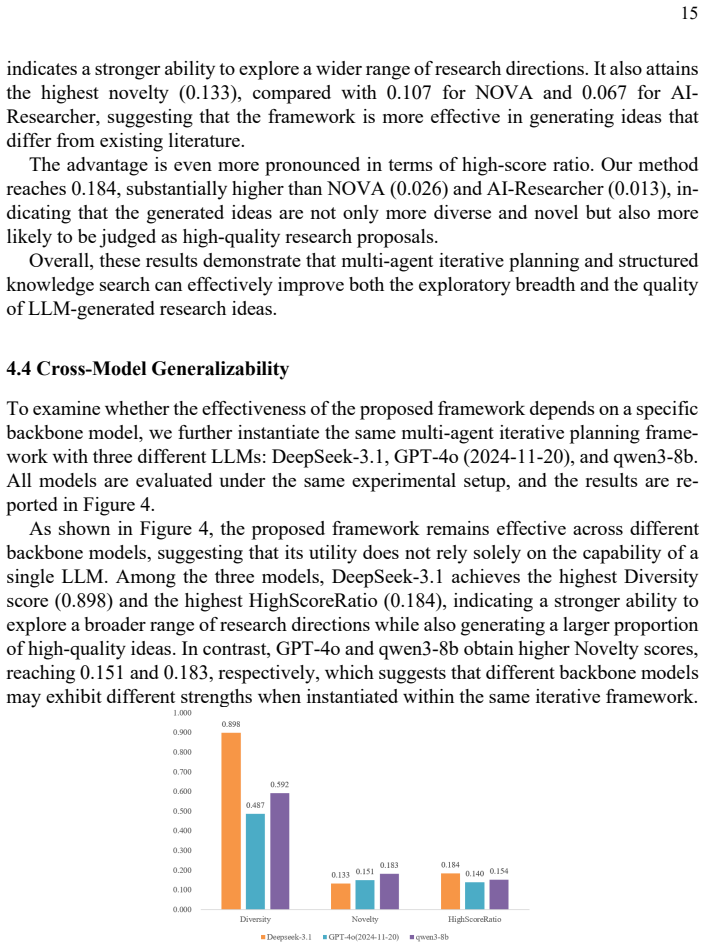
Comparison with Baseline Methods As shown in Figure 3, the proposed multi-agent iterative planning framework out-performs both baseline methods across all three metrics. Our method achieves the high-est diversity (0.898), exceeding NOVA (0.867) and AI-Researcher (0.680), which 15 indicates a stronger ability to explore a wider range of research directions...
2024
-
[9]
The threshold of 3 was adopted for three reasons. First, under the Swiss-system evaluation, ideas with scores of 3 or above have already demonstrated a certain level of competitiveness, and can therefore be regarded as medium- to high-quality outputs. Second, this threshold roughly corresponds to a baseline standard of academic acceptability, making the c...
2025
-
[10]
Comparison of Ideas in Accepted vs. Rejected Papers at ICLR 2025 Group Mean (S.D.) T Significance Ideas for accepted papers 3.256(1.095) 57.27 0.000*** Ideas for rejected papers 1.744(1.148) Note: * indicates significance at the 0.05 level, ** indicates significance at the 0.01 level, *** indicates significance at the 0.001 level. Based on this validation...
2025
-
[11]
Comparison of paper ideas accepted at the 2025 ICLR conference with ideas gener-ated in this study. Group Mean (S.D.) T Significance Ideas for accepted papers 2.776(1.646) 10.390 0.000*** Generated ideas 2.224(0.777) Note: * indicates significance at the 0.05 level, ** indicates significance at the 0.01 level, *** indicates significance at the 0.001 level. Table
2025
-
[12]
Comparison of paper ideas rejected at the 2025 ICLR conference with ideas generated in this study. Group Mean (S.D.) T Significance Generated ideas 2.689(0.818) 7.910 0.000*** Ideas for rejected papers 2.311(1.620) Note: * indicates significance at the 0.05 level, ** indicates significance at the 0.01 level, *** indicates significance at the 0.001 level. ...
2025
-
[13]
The multi-agent iterative planning and search strategy integrates two core modules: knowledge planning and search, and multi-agent genera-tion
Variation in Team Size Corresponding to the Best Metrics per Iteration 4.8 Ablation Study We answer RQ2 in this section. The multi-agent iterative planning and search strategy integrates two core modules: knowledge planning and search, and multi-agent genera-tion. A key objective of this study is to determine which module plays a decisive role in influenc...
2024
-
[14]
We then extract entities from the in-termediate outputs of each iteration, including both the generated ideas and their corre-sponding knowledge bases
on the SciNLP dataset (Duan et al., 2025), which defines five entity types: Method, Task, Metric, Dataset, and Other. We then extract entities from the in-termediate outputs of each iteration, including both the generated ideas and their corre-sponding knowledge bases. Here, the knowledge base consists of the previous-round idea together with the titles a...
2025
-
[15]
#A% &'(')G(+I-.#LM !1')I2'
Demonstration Process Next, the initial research ideas and retrieved knowledge are provided to the virtual sci-entist agents, each of whom is instantiated with the background information of the se-lected paper’s author(s). Based on both prior background knowledge and newly !"#A% &'(')G(+I-.#LM !1')I2'"'G)%L."IP4IRAS%LTU9'"%I!%'G)%L:'I;')GM+I;%G)%'9L'( <L%...
2025
-
[16]
K., Grossman, T., Hope, T., Dalvi Mishra, B., Latzke, M., Bragg, J., Chang, J
Pu, K., Feng, K. K., Grossman, T., Hope, T., Dalvi Mishra, B., Latzke, M., Bragg, J., Chang, J. C., & Siangliulue, P. (2025). Ideasynth: Iterative research idea development through evolving and composing idea facets with literature-grounded feedback. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. Sadler-Smith, E. J. C. r....
2025
-
[17]
Si, C., Yang, D., & Hashimoto, T. (2024). Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore EXPO. Su, H., Chen, R., Tang, S., Yin, Z., Zheng, X., Li, J., Qi, B., Wu, Q., Li, H., Ouyang, W., Torr, P., Zhou, B., & Dong,...
2024
-
[18]
Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., & Le, Q
arXiv preprint arXiv:.03493. Zhou, D., Schärli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., & Le, Q. (2022). Least-to-most prompting enables complex reasoning in large language models. In Proceedings of the eleventh International Conference on Learning Representations. Zhu, K., Wang, J., Zhao, Q., Xu, R., & Xie, X. (...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.