Recognition: unknown
Trust, Lies, and Long Memories: Emergent Social Dynamics and Reputation in Multi-Round Avalon with LLM Agents
Pith reviewed 2026-05-09 23:13 UTC · model grok-4.3
The pith
LLM agents form role-dependent reputations from cross-game memory and favor trusted players 46 percent more often in Avalon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When agents retain memory of previous games, including roles and behaviors, two patterns appear across 188 matches. First, agents describe one another in role-conditional ways, calling the same player straightforward after a good performance but subtle after an evil one, and high-reputation agents receive 46 percent more team inclusions. Second, evil agents with higher reasoning effort pass early missions 75 percent of the time versus 36 percent in low-effort games, building false trust before betraying later missions.
What carries the argument
Cross-game memory that lets agents reference specific past roles, actions, and outcomes when making current decisions.
If this is right
- Agents begin to treat prior game outcomes as evidence when choosing future teammates.
- Evil agents shift from immediate sabotage to delayed betrayal once they have more reasoning steps available.
- Reputation labels stay tied to the specific role an agent held in each remembered game.
- Social caution, such as wariness of past over-trusting, appears in agent statements without being directly instructed.
Where Pith is reading between the lines
- Similar memory setups could let LLM agents sustain consistent identities across many different games rather than resetting each time.
- Running the same protocol on negotiation or alliance games might show whether reputation formation is specific to Avalon or general to repeated hidden-role play.
- If the patterns survive changes in model family or prompt style, they offer a practical way to study how trust scales with interaction length in language-model groups.
Load-bearing premise
The reputation and deception patterns come from the agents' own memory and reasoning rather than from how the prompts or game rules were written.
What would settle it
Run the identical 188-game setup but disable cross-game memory or lower the reasoning effort and check whether the 46 percent inclusion gap and the 75-versus-36 percent early-mission rates both vanish.
Figures

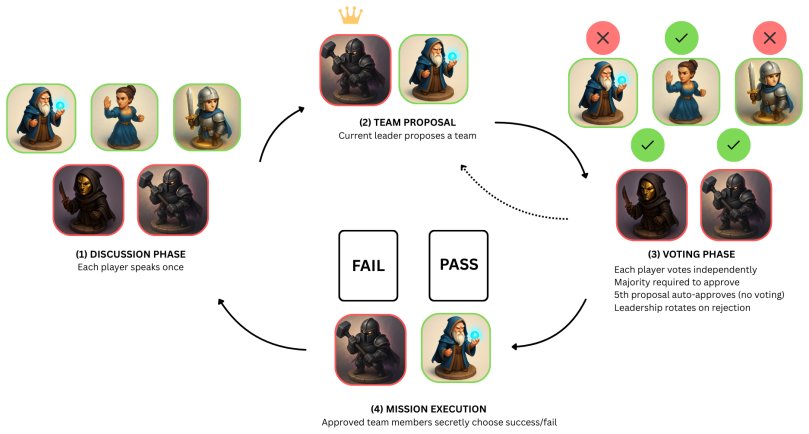
read the original abstract
We study emergent social dynamics in LLM agents playing The Resistance: Avalon, a hidden-role deception game. Unlike prior work on single-game performance, our agents play repeated games while retaining memory of previous interactions, including who played which roles and how they behaved, enabling us to study how social dynamics evolve. Across 188 games, two key phenomena emerge. First, reputation dynamics emerge organically when agents retain cross-game memory: agents reference past behavior in statements like "I am wary of repeating last game's mistake of over-trusting early success." These reputations are role-conditional: the same agent is described as "straightforward" when playing good but "subtle" when playing evil, and high-reputation players receive 46% more team inclusions. Second, higher reasoning effort supports more strategic deception: evil players more often pass early missions to build trust before sabotaging later ones, 75% in high-effort games vs 36% in low-effort games. Together, these findings show that repeated interaction with memory gives rise to measurable reputation and deception dynamics among LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM agents playing repeated rounds of The Resistance: Avalon while retaining cross-game memory exhibit emergent reputation dynamics: agents reference past behaviors, reputations are role-conditional, and high-reputation players receive 46% more team inclusions. It further claims that higher reasoning effort enables more strategic deception, with evil players passing early missions 75% of the time in high-effort games versus 36% in low-effort games, based on observations from 188 games.
Significance. If the patterns are shown to arise specifically from memory and reasoning rather than artifacts, the work would demonstrate measurable emergent social behaviors in LLM multi-agent systems, with implications for understanding reputation and deception in repeated interactions. The scale of 188 games provides a useful observational dataset for identifying such patterns in a complex hidden-role game.
major comments (3)
- Methods section: No details are provided on memory implementation (what prior-game information is stored, how it is summarized or injected into prompts), which is load-bearing for the claim that reputation references and the 46% inclusion differential emerge from cross-game memory retention rather than base prompts or pretraining.
- Results section: The reported 46% more team inclusions for high-reputation players and the 75% vs 36% early-mission pass rates lack any statistical tests, confidence intervals, or controls for prompt variation and LLM model choice, preventing assessment of whether these differentials support the emergence claims.
- Experimental design: No ablation or control condition is described in which agents play repeated games under identical rules and prompts but without cross-game memory access; without this comparison the central attribution of reputation dynamics and strategic deception to memory cannot be established.
minor comments (1)
- Abstract: Numerical claims (46%, 75%, 36%) are presented without reference to variability measures or exact game counts per condition, reducing clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. The comments identify key areas where additional clarity, rigor, and discussion of limitations will strengthen the manuscript. We respond to each major comment below, indicating the revisions we will undertake.
read point-by-point responses
-
Referee: Methods section: No details are provided on memory implementation (what prior-game information is stored, how it is summarized or injected into prompts), which is load-bearing for the claim that reputation references and the 46% inclusion differential emerge from cross-game memory retention rather than base prompts or pretraining.
Authors: We acknowledge that the Methods section would benefit from greater specificity on the memory mechanism. The manuscript describes cross-game memory at a conceptual level but does not fully detail the stored information, summarization steps, or prompt integration. In the revised manuscript we will expand the Methods section with a precise description of the memory store contents, the summarization procedure to fit context limits, and concrete examples of how memory is injected into prompts. This will enable readers to evaluate whether the reported reputation effects are attributable to the memory component. revision: yes
-
Referee: Results section: The reported 46% more team inclusions for high-reputation players and the 75% vs 36% early-mission pass rates lack any statistical tests, confidence intervals, or controls for prompt variation and LLM model choice, preventing assessment of whether these differentials support the emergence claims.
Authors: We agree that statistical support and explicit controls would improve the results. We will add appropriate statistical tests (e.g., proportion tests or chi-squared) together with confidence intervals for the 46% inclusion differential and the 75% vs 36% deception rates. Our experiments used a single model and fixed prompt template across all 188 games; we will state this explicitly and discuss it as a limitation. While we cannot introduce new prompt or model variations retroactively, we will quantify robustness across the observed games and note that broader controls remain an avenue for future work. revision: partial
-
Referee: Experimental design: No ablation or control condition is described in which agents play repeated games under identical rules and prompts but without cross-game memory access; without this comparison the central attribution of reputation dynamics and strategic deception to memory cannot be established.
Authors: This is a substantive limitation of the current design. The study was conducted as an observational analysis within the memory-enabled multi-round setting, with reference to prior single-game literature for contrast. An explicit no-memory ablation was not performed. We will add a dedicated paragraph in the Discussion section acknowledging this gap and its implications for causal claims about memory. We plan to run the suggested control condition in follow-up experiments to provide stronger evidence for the role of cross-game memory. revision: partial
Circularity Check
No circularity: purely observational simulation study
full rationale
The paper reports empirical patterns observed across 188 simulated games of repeated Avalon with LLM agents that retain memory. No mathematical derivation, equations, fitted parameters, or first-principles claims are present that could reduce reported outcomes (reputation references, 46% inclusion differential, deception rates) to definitions or inputs internal to the model. The work is self-contained as a descriptive simulation study; the absence of ablations is a validity concern but does not create circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From text to tactic: Evaluating llms playing the game of avalon
AvalonBench: Evaluating LLMs Playing the Game of Avalon , author=. arXiv preprint arXiv:2310.05036 , year=
-
[2]
Science , volume=
Human-level play in the game of Diplomacy by combining language models with strategic reasoning , author=. Science , volume=
-
[3]
arXiv preprint arXiv:2302.02083 , year=
Theory of Mind May Have Spontaneously Emerged in Large Language Models , author=. arXiv preprint arXiv:2302.02083 , year=
-
[4]
Proceedings of the National Academy of Sciences , volume=
Evaluating large language models in theory of mind tasks , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , doi=
2024
-
[5]
UIST , year=
Generative Agents: Interactive Simulacra of Human Behavior , author=. UIST , year=
-
[6]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. arXiv preprint arXiv:2401.05566 , year=
work page internal anchor Pith review arXiv
-
[7]
EMNLP , year=
Deal or No Deal? End-to-End Learning of Negotiation Dialogues , author=. EMNLP , year=
-
[8]
The Resistance: Avalon , author=
-
[9]
2024 , note=
The Resistance (game) , author=. 2024 , note=
2024
-
[10]
AgentBench: Evaluating LLMs as Agents
AgentBench: Evaluating LLMs as Agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review arXiv
-
[11]
ICLR , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. ICLR , year=
-
[12]
NeurIPS , year=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[13]
NeurIPS , year=
Large Language Models are Zero-Shot Reasoners , author=. NeurIPS , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.