Recognition: unknown
GRPO-VPS: Enhancing Group Relative Policy Optimization with Verifiable Process Supervision for Effective Reasoning
Pith reviewed 2026-05-10 00:10 UTC · model grok-4.3
The pith
Segmenting LLM outputs and tracking the model's own probability of the correct answer at each boundary supplies targeted process supervision that refines GRPO updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By segmenting the generation into discrete steps and tracking the conditional probability of the correct answer appended at each segment boundary, we efficiently compute interpretable segment-wise progress measurements to refine GRPO's trajectory-level feedback. This yields more targeted and sample-efficient policy updates while avoiding costly intermediate supervision from rollouts or auxiliary models.
What carries the argument
Segment-wise progress measurements obtained by appending the ground-truth answer at each generation boundary and recording the model's conditional probability of that answer.
If this is right
- Policy updates become more targeted because credit is assigned according to measured progress at each segment rather than the whole trajectory.
- Reasoning length decreases because the model learns to avoid unproductive intermediate steps.
- The method generalizes across mathematical and general-domain benchmarks and across different base models without requiring auxiliary reward models.
- Sample efficiency improves since each trajectory now contributes finer-grained learning signals.
Where Pith is reading between the lines
- The same boundary-probability probe could be applied to other trajectory-level RL methods such as PPO or REINFORCE variants used for LLM reasoning.
- Dynamic rather than fixed segment boundaries might further improve the granularity of the progress signal.
- The approach might help detect and penalize overthinking by flagging segments where the probability of the correct answer stops rising.
Load-bearing premise
The model's conditional probability of the correct answer at arbitrary segment boundaries supplies a reliable, unbiased signal of intermediate reasoning progress without explicit verification of those steps.
What would settle it
An ablation that removes the segment-boundary probability signals and reverts to pure trajectory-level GRPO feedback, then measures whether accuracy and length gains disappear on the same benchmarks.
Figures

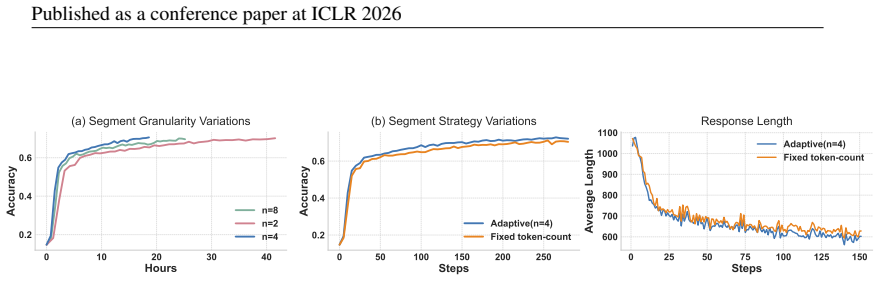






read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capabilities of Large Language Models (LLMs) by leveraging direct outcome verification instead of learned reward models. Building on this paradigm, Group Relative Policy Optimization (GRPO) eliminates the need for critic models but suffers from indiscriminate credit assignment for intermediate steps, which limits its ability to identify effective reasoning strategies and incurs overthinking. In this work, we introduce a model-free and verifiable process supervision via probing the model's belief in the correct answer throughout its reasoning trajectory. By segmenting the generation into discrete steps and tracking the conditional probability of the correct answer appended at each segment boundary, we efficiently compute interpretable segment-wise progress measurements to refine GRPO's trajectory-level feedback. This approach enables more targeted and sample-efficient policy updates, while avoiding the need for intermediate supervision derived from costly Monte Carlo rollouts or auxiliary models. Experiments on mathematical and general-domain benchmarks show consistent gains over GRPO across diverse models: up to 2.6-point accuracy improvements and 13.7% reasoning-length reductions on math tasks, and up to 2.4 points and 4% on general-domain tasks, demonstrating strong generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GRPO-VPS, an extension to Group Relative Policy Optimization (GRPO) that adds verifiable process supervision. It segments LLM reasoning trajectories into discrete steps and derives segment-wise credit signals from the model's conditional probability of the correct final answer appended at each boundary. These signals refine GRPO's trajectory-level feedback to enable more targeted updates, reduce overthinking, and improve sample efficiency without Monte Carlo rollouts or auxiliary models. Experiments report accuracy gains of up to 2.6 points on math benchmarks and 2.4 points on general-domain tasks, together with reasoning-length reductions of 13.7% and 4%, respectively, across multiple models.
Significance. If the conditional-probability signal proves to be a reliable proxy for intermediate progress, the work supplies a computationally lightweight, model-free route to process-level supervision inside RLVR pipelines. This could meaningfully improve credit assignment and efficiency in reasoning fine-tuning while preserving GRPO's avoidance of critic networks, with potential applicability to larger-scale or multi-step reasoning tasks.
major comments (2)
- The central claim that conditional probability of the correct answer at segment boundaries supplies an unbiased, monotonic measure of reasoning progress is load-bearing yet untested in the provided description. The method deliberately avoids explicit step verification or Monte Carlo estimates to remain cheap, but this leaves open whether high probability can arise from flawed prefixes (recoverable errors or lucky guessing) or low probability from correct but uncertain steps; a correlation analysis or ablation against ground-truth step validity is required to substantiate the refinement of GRPO feedback.
- Method description: the segmentation procedure (how boundaries are chosen—token count, sentence, or logical unit) and the exact computation/normalization of the conditional probability are not specified with sufficient precision to allow reproduction or to evaluate whether boundaries align with reasoning units.
minor comments (2)
- Abstract: the specific models, benchmarks, and baseline GRPO configurations used for the reported 2.6-point and 2.4-point gains should be named to contextualize the results.
- The paper should clarify whether the length reductions are measured in tokens or steps and whether any length penalty was applied during training.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: The central claim that conditional probability of the correct answer at segment boundaries supplies an unbiased, monotonic measure of reasoning progress is load-bearing yet untested in the provided description. The method deliberately avoids explicit step verification or Monte Carlo estimates to remain cheap, but this leaves open whether high probability can arise from flawed prefixes (recoverable errors or lucky guessing) or low probability from correct but uncertain steps; a correlation analysis or ablation against ground-truth step validity is required to substantiate the refinement of GRPO feedback.
Authors: We agree that a direct validation of the conditional-probability signal against ground-truth step validity would strengthen the central claim. While the consistent accuracy gains and reasoning-length reductions across benchmarks provide indirect support for the signal's utility, we acknowledge the potential for high probabilities from flawed but recoverable prefixes. In the revised manuscript we will add a new analysis subsection that (i) reports Pearson correlations between segment-wise probabilities and human-annotated step correctness on a held-out sample of 200 trajectories and (ii) includes an ablation replacing our signal with random or uniform scores to quantify the contribution of the verifiable process supervision. revision: yes
-
Referee: Method description: the segmentation procedure (how boundaries are chosen—token count, sentence, or logical unit) and the exact computation/normalization of the conditional probability are not specified with sufficient precision to allow reproduction or to evaluate whether boundaries align with reasoning units.
Authors: We thank the referee for highlighting this reproducibility gap. In the revised version we will expand Section 3.2 with: (1) an explicit statement that segment boundaries are placed at the ends of complete sentences (detected via punctuation and sentence segmentation) to align with logical reasoning units rather than fixed token counts; (2) the precise formula P(correct | prefix up to boundary) obtained by appending the ground-truth answer to the partial trajectory and extracting the model's next-token probability for the first token of the answer; and (3) the min-max normalization applied to the resulting segment scores within each trajectory to produce relative credit signals for GRPO. revision: yes
Circularity Check
No circularity; supervision signal is direct model probability computation, not a fitted or self-referential construct
full rationale
The paper's core proposal segments trajectories and computes P(correct answer | prefix) at boundaries to generate segment-wise signals for GRPO refinement. This is a straightforward forward-pass extraction rather than any derivation that reduces the claimed progress measure to its own inputs by construction. No equations are presented that equate the output to a fitted parameter or prior self-citation; the method is introduced as a model-free alternative to Monte Carlo or auxiliary models and is validated empirically on external benchmarks. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or description to justify the central claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional probability of the correct answer at segment boundaries measures reasoning progress
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.00782 , year=
Alex J Chan, Hao Sun, Samuel Holt, and Mihaela Van Der Schaar. Dense reward for free in reinforcement learning from human feedback.arXiv preprint arXiv:2402.00782,
-
[2]
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset (2023).URL https://arxiv. org/abs/2305.12524. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through imp...
-
[3]
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models. arXiv preprint arXiv:2505.07686,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, and Shuang Qiu. Segment policy optimization: Effective segment- level credit assignment in rl for large language models.arXiv preprint arXiv:2505.23564,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008, 2024a. Jujie He, Tianwen Wei, Rui Yan, Jiacai Liu, Chaojie Wang, Yimeng Ga...
work page internal anchor Pith review arXiv
-
[6]
RAG-RL: Advancing Retrieval-Augmented Generation via RL and Curriculum Learning
Jerry Huang, Siddarth Madala, Risham Sidhu, Cheng Niu, Hao Peng, Julia Hockenmaier, and Tong Zhang. Rag-rl: Advancing retrieval-augmented generation via rl and curriculum learning.arXiv preprint arXiv:2503.12759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Vineppo: Refining credit assignment in rl training of llms, 2025
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in rl training of llms.arXiv preprint arXiv:2410.01679,
-
[8]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
-
[9]
11 Published as a conference paper at ICLR 2026 MAA
URLhttps:// artofproblemsolving.com/wiki/index.php/AMC_12_Problems_and_Solutions. 11 Published as a conference paper at ICLR 2026 MAA. American invitational mathematics examination (aime) - february 2024, 02
2026
-
[10]
Optimizing test-time compute via meta reinforcement fine-tuning
URLhttps://openai.com/index/ learning-to-reason-with-llms/. Yuxiao Qu, Matthew YR Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhut- dinov, and Aviral Kumar. Optimizing test-time compute via meta reinforcement fine-tuning.arXiv preprint arXiv:2503.07572,
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy opti- mization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning.arXiv preprint arXiv:2410.08146,
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review arXiv
-
[15]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji- Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review arXiv
-
[16]
Gemma Team. Gemma. 2024a. doi: 10.34740/KAGGLE/M/3301. URLhttps://www.kaggle.com/ m/3301. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
-
[17]
URLhttps://arxiv.org/abs/2505.09388. Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations.arXiv preprint arXiv:2312.08935,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective rein- forcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review arXiv
-
[19]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
12 Published as a conference paper at ICLR 2026 An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint a...
work page internal anchor Pith review arXiv 2026
-
[20]
arXiv preprint arXiv:2505.12929 , year=
Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, and Yunjian Xu. Do not let low-probability tokens over-dominate in rl for llms.arXiv preprint arXiv:2505.12929,
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025a. Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118,
work page internal anchor Pith review arXiv
-
[23]
Kaiwen Zha, Zhengqi Gao, Maohao Shen, Zhang-Wei Hong, Duane S Boning, and Dina Katabi. Rl tango: Reinforcing generator and verifier together for language reasoning.arXiv preprint arXiv:2505.15034,
-
[24]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review arXiv
-
[25]
A APPENDIX A.1 EXPERIMENTALSETTINGS All hyperparameter settings are listed in Table 4, our experiments are performed on 8 × H100 GPUs. 13 Published as a conference paper at ICLR 2026 Hyperparameter Values learning rate 1.0e-6 temperature 1.0 Number of responses per question 8 batch size 512 α 1.2 εlow 0.2 εhigh 0.27 ppo mini-batch size 128 (top P, top k) ...
2026
-
[26]
14 Published as a conference paper at ICLR 2026 Prompt A.3: Template for Qwen3 models <|im start|>system A conversation between User and Assistant
model. 14 Published as a conference paper at ICLR 2026 Prompt A.3: Template for Qwen3 models <|im start|>system A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are...
2026
-
[27]
Gemma base model exhibits extremely short responses at initializa- tion, due to its instruction-tuned alignment, which explicitly suppresses verbosity and favors concise, direct answers. As training progresses, both methods gradually increase the response length, as longer reasoning 15 Published as a conference paper at ICLR 2026 Table 5: Performance comp...
2026
-
[28]
Let's implement this in Python. ```python import math # Define the numbers ming_pencils = 40 catherine_pencils = 24 # Calculate the GCD gcd = math.gcd(ming_pencils, catherine_pencils) # Output the largest possible number of pencils in a package print(gcd) ``` ```output 8 ``` The largest possible number of pencils in a package is \(\boxed{8}\). noninformat...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.