Recognition: unknown
COMPASS: COntinual Multilingual PEFT with Adaptive Semantic Sampling
Pith reviewed 2026-05-10 01:09 UTC · model grok-4.3
The pith
COMPASS adapts LLMs to target languages by sampling auxiliary data from semantic gaps rather than linguistic similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COMPASS is a framework for continual multilingual PEFT that uses a distribution-aware sampling strategy based on multilingual embeddings and clustering to identify semantic gaps between existing training data and a target usage distribution. By prioritizing auxiliary data from under-represented semantic clusters, it trains language-specific adapters to maximize positive cross-lingual transfer while minimizing interference. The framework extends to COMPASS-ECDA, which dynamically updates adapters upon detecting distribution shifts to balance new adaptation with preservation of existing knowledge. Across Phi-4-Mini, Llama-3.1-8B, and Qwen2.5-7B on Global-MMLU, MMLU-ProX, and OneRuler, COMPASS-
What carries the argument
The distribution-aware sampling strategy that clusters multilingual embeddings to prioritize auxiliary data from under-represented semantic clusters during adapter training.
If this is right
- Outperforms linguistic-similarity baselines on Global-MMLU and MMLU-ProX across three model architectures.
- Maintains gains on unseen long-context tasks such as OneRuler.
- Supports continual updates that adapt to new data distributions without erasing prior knowledge.
- Provides an efficient, PEFT-based path to sustainable multilingual model maintenance.
Where Pith is reading between the lines
- Semantic structure captured by embeddings may serve as a stronger guide for cross-lingual transfer than surface linguistic features.
- The sampling approach could extend to continual adaptation in non-language domains where distribution shifts occur.
- Focusing on semantic gaps might reduce the volume of data needed for effective multilingual adaptation.
Load-bearing premise
That selecting auxiliary data from semantic clusters identified via embeddings will maximize positive cross-lingual transfer while minimizing interference.
What would settle it
A head-to-head comparison on Global-MMLU or MMLU-ProX in which COMPASS shows no improvement or worse results than linguistic-similarity baselines would indicate the sampling strategy fails to deliver its claimed benefits.
Figures


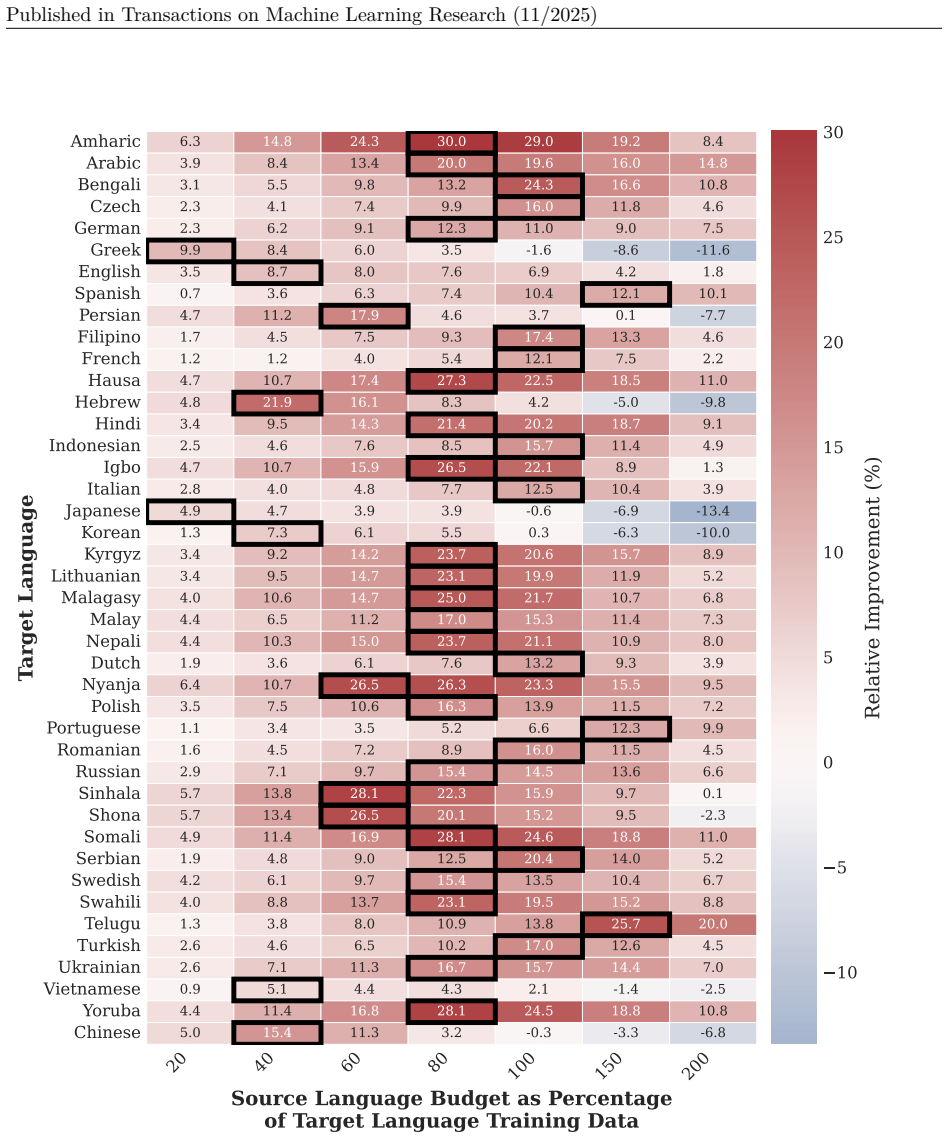
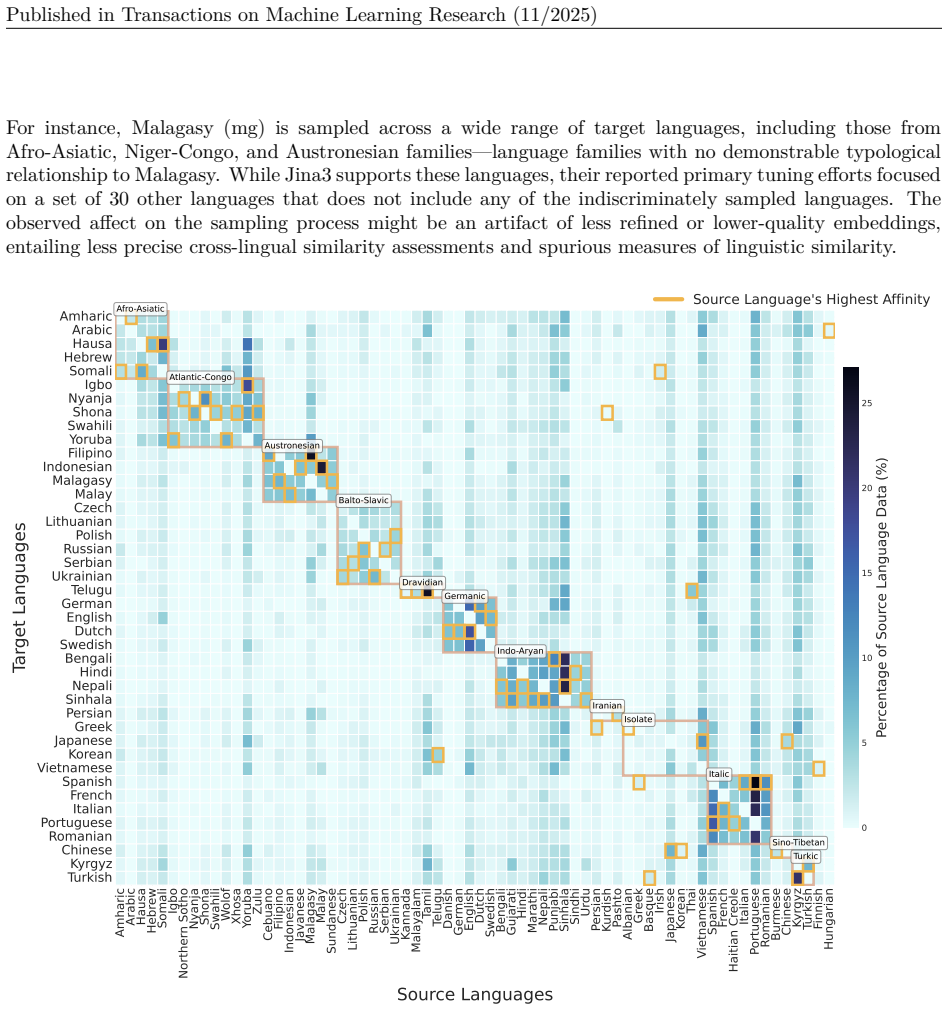








read the original abstract
Large language models (LLMs) often exhibit performance disparities across languages, with naive multilingual fine-tuning frequently degrading performance due to negative cross-lingual interference. To address this, we introduce COMPASS (COntinual Multilingual PEFT with Adaptive Semantic Sampling), a novel data-centric framework for adapting LLMs to target languages. COMPASS leverages parameter-efficient fine-tuning (PEFT) by training lightweight, language-specific adapters on a judiciously selected subset of auxiliary multilingual data. The core of our method is a distribution-aware sampling strategy that uses multilingual embeddings and clustering to identify semantic gaps between existing training data and a target usage distribution. By prioritizing auxiliary data from under-represented semantic clusters, COMPASS maximizes positive cross-lingual transfer while minimizing interference. We extend this into a continual learning framework, COMPASS-ECDA, which monitors for data distribution shifts in production and dynamically updates adapters to prevent model staleness, balancing adaptation to new data with the preservation of existing knowledge. Across three different model architectures (Phi-4-Mini, Llama-3.1-8B, and Qwen2.5-7B) and multiple challenging multilingual benchmarks (Global-MMLU, MMLU-ProX), including unseen long-context tasks (OneRuler), we demonstrate that COMPASS consistently outperforms baseline methods guided by linguistic similarity, providing an effective, efficient, and sustainable solution for developing and maintaining high-performing multilingual models in dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COMPASS, a data-centric continual multilingual PEFT framework. It uses multilingual embeddings and clustering to identify semantic gaps and sample auxiliary data from under-represented clusters for training language-specific adapters, aiming to maximize positive cross-lingual transfer while minimizing interference. An extension, COMPASS-ECDA, adds dynamic monitoring and adapter updates for production distribution shifts. The authors claim consistent outperformance over linguistic-similarity baselines across Phi-4-Mini, Llama-3.1-8B, and Qwen2.5-7B on Global-MMLU, MMLU-ProX, and unseen long-context tasks like OneRuler.
Significance. If the empirical results hold with proper controls, the work could meaningfully advance efficient multilingual adaptation by shifting focus from linguistic to semantic similarity in data selection and incorporating continual learning for deployment. The PEFT-based design supports practicality, and the emphasis on minimizing negative interference addresses a known pain point in multilingual LLMs.
major comments (2)
- [Abstract] Abstract: The central claim that COMPASS 'consistently outperforms baseline methods guided by linguistic similarity' across three models and multiple benchmarks is asserted without any quantitative metrics, tables, error bars, ablation studies, or details on how clusters were formed or sampling thresholds chosen. This prevents assessment of the result and is load-bearing for the paper's contribution.
- [§3 (Method)] Method description: The distribution-aware sampling relies on external multilingual embeddings and clustering to identify semantic gaps, but no equations, pseudocode, or implementation details are supplied for cluster formation, gap identification, or the sampling procedure itself. This is central to the claimed mechanism and reproducibility.
minor comments (2)
- [Abstract] The acronym 'COntinual' uses inconsistent capitalization; standard form is 'Continual'.
- [§3.3] Notation for the continual extension (COMPASS-ECDA) is introduced without a clear expansion or diagram showing how it integrates with the base COMPASS adapters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that COMPASS 'consistently outperforms baseline methods guided by linguistic similarity' across three models and multiple benchmarks is asserted without any quantitative metrics, tables, error bars, ablation studies, or details on how clusters were formed or sampling thresholds chosen. This prevents assessment of the result and is load-bearing for the paper's contribution.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the central claim to allow immediate assessment. In the revised manuscript, we will update the abstract to report key performance metrics from the experimental results (e.g., average gains across Global-MMLU and MMLU-ProX for the three models), reference the presence of error bars and ablation studies in the main text, and briefly note the clustering approach. This change directly addresses the load-bearing nature of the claim while preserving the abstract's conciseness. revision: yes
-
Referee: [§3 (Method)] Method description: The distribution-aware sampling relies on external multilingual embeddings and clustering to identify semantic gaps, but no equations, pseudocode, or implementation details are supplied for cluster formation, gap identification, or the sampling procedure itself. This is central to the claimed mechanism and reproducibility.
Authors: The referee is correct that the current method section relies on narrative description without formal equations or pseudocode. While the textual account covers the use of multilingual embeddings, clustering for gap detection, and adaptive sampling, we acknowledge this limits reproducibility. We will revise Section 3 to include mathematical formulations (e.g., for embedding-based cluster assignment and semantic gap scoring) and add pseudocode for the full sampling procedure, including threshold selection. These additions will be placed in the main text or a dedicated algorithm box. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and method description rely on external multilingual embeddings and clustering for distribution-aware sampling, which are independent of any internal fitted parameters or self-derived equations within the paper. No equations, derivations, or predictions are shown that reduce to inputs by construction. The central claims are empirical performance results on benchmarks, with the continual learning extension presented as a monitoring framework rather than a self-referential loop. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing manner that would create circularity. The derivation chain is self-contained as a data-centric heuristic applied to PEFT adapters.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Estimating example difficulty using variance of gradients, 2022
Chirag Agarwal, Daniel D'souza, and Sara Hooker. Estimating example difficulty using variance of gradients, 2022. URL https://arxiv.org/abs/2008.11600
-
[5]
V. Beaufils and J. Tomin. Stochastic approach to worldwide language classification: the signals and the noise towards long-range exploration. 10 2020. doi:10.31235/osf.io/5swba
-
[6]
Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz et al. Lora learns less and forgets less, 2024. URL https://arxiv.org/abs/2405.09673
-
[8]
Terra Blevins, Tomasz Limisiewicz, Suchin Gururangan et al. Breaking the curse of multilinguality with cross-lingual expert language models, 2024. URL https://arxiv.org/abs/2401.10440
-
[9]
Spanish pre-trained bert model and evaluation data, 2023
José Cañete, Gabriel Chaperon, Rodrigo Fuentes et al. Spanish pre-trained bert model and evaluation data, 2023
2023
-
[10]
German’s next language model
Branden Chan, Stefan Schweter, and Timo M \"o ller. German’s next language model. In International Conference on Computational Linguistics, 2020. URL https://api.semanticscholar.org/CorpusID:224814107
2020
-
[11]
Beyond english: Unveiling multilingual bias in llm copyright compliance, 2025
Yupeng Chen, Xiaoyu Zhang, Yixian Huang et al. Beyond english: Unveiling multilingual bias in llm copyright compliance, 2025. URL https://arxiv.org/abs/2503.05713
-
[13]
Efficient and effective text encoding for chinese llama and alpaca
Yiming Cui, Ziqing Yang, and Xin Yao. Efficient and effective text encoding for chinese llama and alpaca, 2024. URL https://arxiv.org/abs/2304.08177
-
[14]
Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474,
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan et al. Multilingual jailbreak challenges in large language models, 2024. URL https://arxiv.org/abs/2310.06474
-
[15]
Dryer and Martin Haspelmath, editors
Matthew S. Dryer and Martin Haspelmath (eds.). WALS Online (v2020.4). Zenodo, 2013. doi:10.5281/zenodo.13950591. URL https://doi.org/10.5281/zenodo.13950591
-
[16]
Eberhard, Gary F
David M. Eberhard, Gary F. Simons, and Charles D. Fennig (eds.). Ethnologue: Languages of the World. SIL International, Dallas, Texas, 28 edition, 2025. URL http://www.ethnologue.com
2025
-
[17]
Mmteb: Massive multilingual text embedding bench- mark.arXiv preprint arXiv:2502.13595,
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua et al. Mmteb: Massive multilingual text embedding benchmark, 2025. URL https://arxiv.org/abs/2502.13595
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart et al. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review arXiv 2021
-
[23]
Selective experience replay for lifelong learning, 2018
David Isele and Akansel Cosgun. Selective experience replay for lifelong learning, 2018. URL https://arxiv.org/abs/1802.10269
-
[25]
Franken-adapter: Cross-lingual adaptation of llms by embedding surgery, 2025
Fan Jiang, Honglin Yu, Grace Chung et al. Franken-adapter: Cross-lingual adaptation of llms by embedding surgery, 2025. URL https://arxiv.org/abs/2502.08037
-
[27]
Khyati Khandelwal, Manuel Tonneau, Andrew M. Bean et al. Casteist but not racist? quantifying disparities in large language model bias between india and the west. CoRR, abs/2309.08573, 2023. URL https://doi.org/10.48550/arXiv.2309.08573
-
[29]
Second Conference on Language Modeling , url =
Yekyung Kim, Jenna Russell, Marzena Karpinska et al. One ruler to measure them all: Benchmarking multilingual long-context language models, 2025. URL https://arxiv.org/abs/2503.01996
-
[32]
Korealbert: Pretraining a lite bert model for korean language understanding
Hyunjae Lee, Jaewoong Yoon, Bonggyu Hwang et al. Korealbert: Pretraining a lite bert model for korean language understanding. 2020 25th International Conference on Pattern Recognition (ICPR), pp.\ 5551--5557, 2021. URL https://api.semanticscholar.org/CorpusID:231718643
2020
-
[33]
Privacy in large language mod- els: Attacks, defenses, and future directions,
Haoran Li, Yulin Chen, Jinglong Luo et al. Privacy in large language models: Attacks, defenses and future directions, 2024. URL https://arxiv.org/abs/2310.10383
-
[34]
Congrad:conflicting gradient filtering for multilingual preference alignment, 2025
Jiangnan Li, Thuy-Trang Vu, Christian Herold et al. Congrad:conflicting gradient filtering for multilingual preference alignment, 2025. URL https://arxiv.org/abs/2503.23777
-
[36]
Mortensen, Ke Lin et al
Patrick Littell, David R. Mortensen, Ke Lin et al. URIEL and lang2vec: Representing languages as typological, geographical, and phylogenetic vectors. In Mirella Lapata, Phil Blunsom, and Alexander Koller (eds.), Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , pp.\ 8--14...
2017
-
[38]
F., Cheng, K.-T., and Chen, M.-H
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin et al. Dora: Weight-decomposed low-rank adaptation, 2024. URL https://arxiv.org/abs/2402.09353
-
[40]
A large-scale audit of dataset licensing and attribution in AI
Shayne Longpre, Rishi Mahari, Annie Chen et al. A large-scale audit of dataset licensing and attribution in AI . Nature Machine Intelligence, 6: 0 975--987, 2024. doi:10.1038/s42256-024-00878-8
-
[41]
Seacrowd: A multilingual multimodal data hub and benchmark suite for southeast asian languages, 2025
Holy Lovenia, Rahmad Mahendra, Salsabil Maulana Akbar et al. Seacrowd: A multilingual multimodal data hub and benchmark suite for southeast asian languages, 2025. URL https://arxiv.org/abs/2406.10118
-
[43]
Analyzing leakage of personally identifiable information in language models
Nils Lukas, Ahmed Salem, Robert Sim et al. Analyzing leakage of personally identifiable information in language models, 2023. URL https://arxiv.org/abs/2302.00539
-
[44]
Camembert: a tasty french language model
Louis Martin, Benjamin Muller, Pedro Ortiz Suarez et al. Camembert: a tasty french language model. In Annual Meeting of the Association for Computational Linguistics, 2019. URL https://api.semanticscholar.org/CorpusID:207853304
2019
-
[45]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft, :, Abdelrahman Abouelenin et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras, 2025. URL https://arxiv.org/abs/2503.01743
work page internal anchor Pith review arXiv 2025
-
[46]
Mistral saba, 2025
Mistral. Mistral saba, 2025. URL https://mistral.ai/news/mistral-saba
2025
-
[48]
Feder Cooper, Daphne Ippolito, Christopher A
Milad Nasr, Nicholas Carlini, Jonathan Hayase et al. Scalable extraction of training data from (production) language models, 2023. URL https://arxiv.org/abs/2311.17035
-
[49]
Phobert: Pre-trained language models for vietnamese
Dat Quoc Nguyen and Anh Gia-Tuan Nguyen. Phobert: Pre-trained language models for vietnamese. In Findings, 2020. URL https://api.semanticscholar.org/CorpusID:211677475
2020
-
[50]
Lost in translation: Large language models in non-english content analysis, 2023
Gabriel Nicholas and Aliya Bhatia. Lost in translation: Large language models in non-english content analysis, 2023. URL https://arxiv.org/abs/2306.07377
-
[51]
Understanding multimodal llms under distribution shifts: An information-theoretic approach, 2025
Changdae Oh, Zhen Fang, Shawn Im et al. Understanding multimodal llms under distribution shifts: An information-theoretic approach, 2025. URL https://arxiv.org/abs/2502.00577
-
[53]
Sabi\'a: Portuguese large language models, 2023
Ramon Pires, Hugo Abonizio, Thales Sales Almeida et al. Sabi\'a: Portuguese large language models, 2023
2023
-
[54]
Qwen, :, An Yang et al. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL http://arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
-
[57]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz et al. Experience replay for continual learning. In H. Wallach, H. Larochelle, A. Beygelzimer et al. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/fa7cdfad1a5aaf8370ebeda47a1ff1c3-Paper.pdf
2019
-
[58]
It5: Large-scale text-to-text pretraining for italian language understanding and generation
Gabriele Sarti and Malvina Nissim. It5: Large-scale text-to-text pretraining for italian language understanding and generation. ArXiv, abs/2203.03759, 2022. URL https://api.semanticscholar.org/CorpusID:247315276
-
[60]
Longrope2: Near-lossless llm context window scaling, 2025
Ning Shang, Li Lyna Zhang, Siyuan Wang et al. Longrope2: Near-lossless llm context window scaling, 2025. URL https://arxiv.org/abs/2502.20082
-
[61]
arXiv preprint arXiv:2210.03057 , year=
Freda Shi, Mirac Suzgun, Markus Freitag et al. Language models are multilingual chain-of-thought reasoners, 2022. URL https://arxiv.org/abs/2210.03057
-
[62]
Shivalika Singh, Freddie Vargus, Daniel Dsouza et al. Aya dataset: An open-access collection for multilingual instruction tuning, 2024. URL https://arxiv.org/abs/2402.06619
-
[63]
Shivalika Singh, Angelika Romanou, Clémentine Fourrier et al. Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evaluation, 2025. URL https://arxiv.org/abs/2412.03304
-
[64]
Beyond neural scaling laws: beating power law scaling via data pruning, 2023
Ben Sorscher, Robert Geirhos, Shashank Shekhar et al. Beyond neural scaling laws: beating power law scaling via data pruning, 2023
2023
-
[65]
jina- embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173, 2024
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram et al. jina-embeddings-v3: Multilingual embeddings with task lora, 2024. URL https://arxiv.org/abs/2409.10173
-
[68]
arXiv preprint arXiv:2412.13678 , year=
Alex Tamkin, Miles McCain, Kunal Handa et al. Clio: Privacy-preserving insights into real-world ai use, 2024. URL https://arxiv.org/abs/2412.13678
-
[69]
No Language Left Behind: Scaling Human-Centered Machine Translation
NLLB Team, Marta R. Costa-jussà, James Cross et al. No language left behind: Scaling human-centered machine translation, 2022. URL https://arxiv.org/abs/2207.04672
work page internal anchor Pith review arXiv 2022
-
[73]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024. URL https://arxiv.org/abs/2406.01574
work page internal anchor Pith review arXiv 2024
-
[74]
Data efficient continual learning of large language model, 2025
Zhenyi Wang and Heng Huang. Data efficient continual learning of large language model, 2025. URL https://openreview.net/forum?id=aqvf3R48pl
2025
-
[79]
Mmlu-prox: A multilingual benchmark for advanced large language model evaluation, 2025
Weihao Xuan, Rui Yang, Heli Qi et al. Mmlu-prox: A multilingual benchmark for advanced large language model evaluation, 2025. URL https://arxiv.org/abs/2503.10497
-
[80]
Multilingual universal sentence encoder for semantic retrieval, 2019
Yinfei Yang, Daniel Cer, Amin Ahmad et al. Multilingual universal sentence encoder for semantic retrieval, 2019
2019
-
[81]
Exploring Cross-lingual Latent Transplantation: Mutual Opportunities and Open Challenges
Yangfan Ye, Xiaocheng Feng, Xiachong Feng et al. Exploring cross-lingual latent transplantation: Mutual opportunities and open challenges, 2025. URL https://arxiv.org/abs/2412.12686
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [82]
-
[83]
Gradient surgery for multi-task learning,
Tianhe Yu, Saurabh Kumar, Abhishek Gupta et al. Gradient surgery for multi-task learning, 2020. URL https://arxiv.org/abs/2001.06782
-
[85]
The ai index 2022 annual report, 2022
Daniel Zhang, Nestor Maslej, Erik Brynjolfsson et al. The ai index 2022 annual report, 2022. URL https://arxiv.org/abs/2205.03468
-
[87]
arXiv preprint arXiv:2502.17920 , year=
Xin Zhang, Liang Bai, Xian Yang et al. C-lora: Continual low-rank adaptation for pre-trained models, 2025. URL https://arxiv.org/abs/2502.17920
-
[88]
Lens: Rethinking multilingual enhancement for large language models, 2025
Weixiang Zhao, Yulin Hu, Jiahe Guo et al. Lens: Rethinking multilingual enhancement for large language models, 2025. URL https://arxiv.org/abs/2410.04407
-
[89]
Tianyang Zhong, Zhenyuan Yang, Zhengliang Liu et al. Opportunities and challenges of large language models for low-resource languages in humanities research, 2024. URL https://arxiv.org/abs/2412.04497
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[90]
Mix-of-language-experts architecture for multilingual programming, 2025
Yifan Zong, Yuntian Deng, and Pengyu Nie. Mix-of-language-experts architecture for multilingual programming, 2025. URL https://arxiv.org/abs/2506.18923
-
[91]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[92]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[93]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[94]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[95]
Publications Manual , year = "1983", publisher =
1983
-
[96]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[97]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[98]
Dan Gusfield , title =. 1997
1997
-
[99]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[100]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[101]
MAD-X : A n A dapter- B ased F ramework for M ulti- T ask C ross- L ingual T ransfer
Pfeiffer, Jonas and Vuli \'c , Ivan and Gurevych, Iryna and Ruder, Sebastian. MAD-X : A n A dapter- B ased F ramework for M ulti- T ask C ross- L ingual T ransfer. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.617
-
[102]
Wang, Zirui and Lipton, Zachary C. and Tsvetkov, Yulia. On Negative Interference in Multilingual Models: Findings and A Meta-Learning Treatment. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.359
-
[103]
2022 , eprint=
MASSIVE: A 1M-Example Multilingual Natural Language Understanding Dataset with 51 Typologically-Diverse Languages , author=. 2022 , eprint=
2022
-
[104]
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Unsupervised Cross-lingual Representation Learning at Scale , journal =. 2019 , url =. 1911.02116 , timestamp =
-
[105]
Computational Intelligence , volume =
Estabrooks, Andrew and Jo, Taeho and Japkowicz, Nathalie , title =. Computational Intelligence , volume =. doi:https://doi.org/10.1111/j.0824-7935.2004.t01-1-00228.x , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.0824-7935.2004.t01-1-00228.x , abstract =
-
[106]
2022 , url =
Jose Garrido Ramas and Thu Le and Bei Chen and Manoj Kumar and Kay Rottmann , title =. 2022 , url =
2022
-
[107]
2023 , eprint=
Beyond neural scaling laws: beating power law scaling via data pruning , author=. 2023 , eprint=
2023
-
[108]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[109]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[110]
MacQueen, J. B. , biburl =. Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability , editor =
-
[111]
2019 , eprint=
Multilingual Universal Sentence Encoder for Semantic Retrieval , author=. 2019 , eprint=
2019
-
[112]
Emanuele Bastianelli and Andrea Vanzo and Pawel Swietojanski and Verena Rieser , title=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.