Recognition: unknown
V-tableR1: Process-Supervised Multimodal Table Reasoning with Critic-Guided Policy Optimization
Pith reviewed 2026-05-09 23:45 UTC · model grok-4.3
The pith
Process-supervised reinforcement learning makes small multimodal models reason step-by-step over tables instead of guessing patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
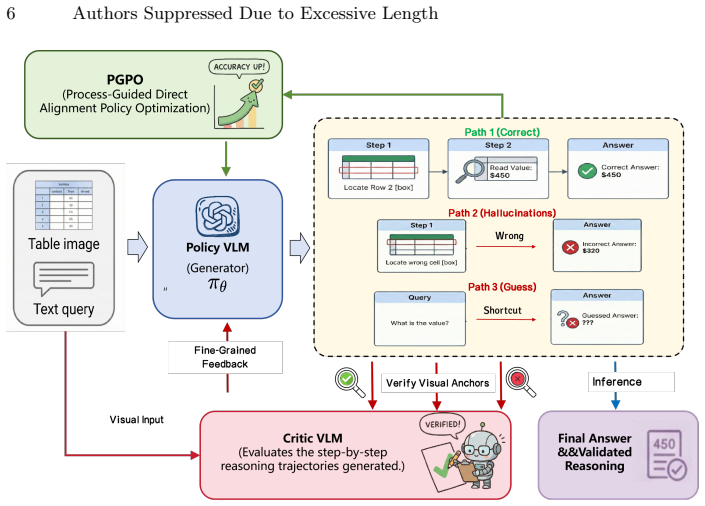
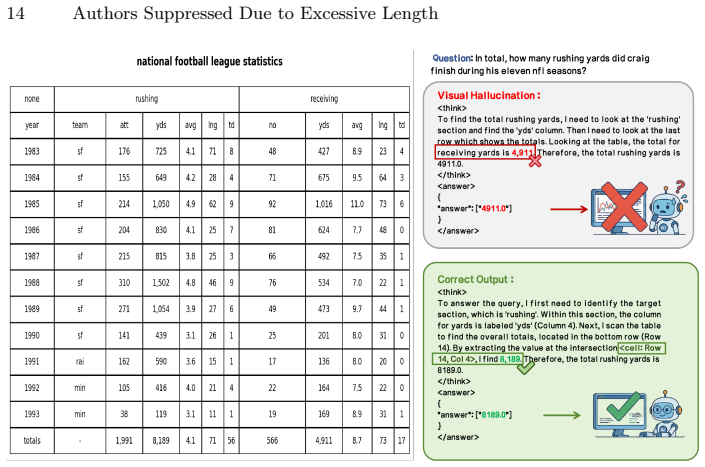
V-tableR1 pairs a policy VLM that produces explicit visual chain-of-thought with a specialized critic VLM that supplies dense step-level process rewards, then optimizes the system with the Process-Guided Direct Alignment Policy Optimization algorithm that combines those rewards, decoupled policy constraints, and length-aware dynamic sampling. The resulting 4B model reaches state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforms models up to 18 times larger, and improves over its supervised fine-tuning baseline by explicitly penalizing visual hallucinations and shortcut guessing.
What carries the argument
Process-Guided Direct Alignment Policy Optimization (PGPO), an RL algorithm that integrates critic-provided process rewards with decoupled constraints and dynamic sampling to enforce verifiable multi-step visual reasoning trajectories.
If this is right
- The model explicitly penalizes visual hallucinations and shortcut guessing through step-level process rewards.
- Multimodal inference shifts from black-box pattern matching to verifiable logical derivation.
- The 4B model establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks.
- Performance exceeds that of models up to 18 times larger.
- Accuracy improves over the supervised fine-tuning baseline.
Where Pith is reading between the lines
- The same critic-guided process supervision could be tested on other structured visual domains such as charts or diagrams where step-level grounding remains feasible.
- Replacing final-answer rewards with dense process feedback may improve reasoning robustness in general multimodal tasks that are not limited to tables.
- Smaller models trained with this method could reduce the compute required to reach high accuracy on table-reasoning applications.
Load-bearing premise
The fixed grid structure of tables removes ambiguity when grounding logical steps into pixel space, so that a critic VLM can reliably judge the correctness of each step in the policy model's visual chain-of-thought.
What would settle it
Run the 4B model on the same tabular benchmarks after disabling the critic feedback or after replacing tables with less structured visuals such as natural images; if accuracy falls back to the supervised baseline level and hallucinations increase, the central claim is false.
Figures


read the original abstract
We introduce V-tableR1, a process-supervised reinforcement learning framework that elicits rigorous, verifiable reasoning from multimodal large language models (MLLMs). Current MLLMs trained solely on final outcomes often treat visual reasoning as a black box, relying on superficial pattern matching rather than performing rigorous multi-step inference. While Reinforcement Learning with Verifiable Rewards could enforce transparent reasoning trajectories, extending it to visual domains remains severely hindered by the ambiguity of grounding abstract logic into continuous pixel space. We solve this by leveraging the deterministic grid structure of tables as an ideal visual testbed. V-tableR1 employs a specialized critic VLM to provide dense, step-level feedback on the explicit visual chain-of-thought generated by a policy VLM. To optimize this system, we propose Process-Guided Direct Alignment Policy Optimization (PGPO), a novel RL algorithm integrating process rewards, decoupled policy constraints, and length-aware dynamic sampling. Extensive evaluations demonstrate that V-tableR1 explicitly penalizes visual hallucinations and shortcut guessing. By fundamentally shifting multimodal inference from black-box pattern matching to verifiable logical derivation, V-tableR1 4B establishes state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x its size and improving over its SFT baseline
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces V-tableR1, a process-supervised reinforcement learning framework for multimodal large language models (MLLMs) on table reasoning tasks. It employs a policy VLM to generate explicit visual chain-of-thought and a specialized critic VLM to supply dense step-level process rewards, optimized via the proposed Process-Guided Direct Alignment Policy Optimization (PGPO) algorithm that combines process rewards, decoupled policy constraints, and length-aware dynamic sampling. By exploiting the deterministic grid structure of tables as a low-ambiguity visual testbed, the method aims to penalize visual hallucinations and shortcut guessing, shifting from black-box pattern matching to verifiable logical derivation. The central claim is that the resulting 4B model achieves state-of-the-art accuracy among open-source models on complex tabular benchmarks, outperforming models up to 18x larger and improving over its SFT baseline.
Significance. If the empirical results and ablations hold, the work would be significant for extending RL-with-verifiable-rewards techniques to multimodal visual domains. Tables provide a controlled setting for grounding reasoning, and the critic-guided process supervision offers a concrete mechanism to reduce hallucinations. The PGPO algorithm represents a targeted adaptation of alignment methods, potentially serving as a template for other grounded reasoning tasks in document understanding and visual question answering.
major comments (2)
- [Abstract] Abstract: The manuscript asserts 'extensive evaluations' demonstrating SOTA accuracy, explicit penalization of hallucinations, and outperformance of models up to 18x larger, yet supplies no quantitative metrics, benchmark names, scores, error bars, ablation tables, or description of how hallucinations or shortcut guessing are measured. This omission is load-bearing because the central performance claim cannot be assessed without these details.
- [Method] Method section (PGPO description): The integration of process rewards with 'decoupled policy constraints' and 'length-aware dynamic sampling' is presented as novel, but the provided text contains no equations, pseudocode, or formal definition of the objective or sampling procedure. Without these, it is impossible to verify whether the algorithm correctly implements the claimed process supervision or avoids circularity in reward assignment.
minor comments (1)
- [Abstract] The final sentence of the abstract is truncated ('improving over its SFT baseline').
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below and have revised the manuscript to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts 'extensive evaluations' demonstrating SOTA accuracy, explicit penalization of hallucinations, and outperformance of models up to 18x larger, yet supplies no quantitative metrics, benchmark names, scores, error bars, ablation tables, or description of how hallucinations or shortcut guessing are measured. This omission is load-bearing because the central performance claim cannot be assessed without these details.
Authors: We agree that the abstract should be more self-contained. We have revised the abstract to include key quantitative results (benchmark names, accuracy scores for the 4B model versus baselines and larger models, and a brief statement on the measurement of hallucinations via step-level critic verification and error categorization). The full experimental tables, ablations, and detailed methodology remain in the Experiments section, but the updated abstract now supplies the essential metrics to support the claims. revision: yes
-
Referee: [Method] Method section (PGPO description): The integration of process rewards with 'decoupled policy constraints' and 'length-aware dynamic sampling' is presented as novel, but the provided text contains no equations, pseudocode, or formal definition of the objective or sampling procedure. Without these, it is impossible to verify whether the algorithm correctly implements the claimed process supervision or avoids circularity in reward assignment.
Authors: We accept that a formal specification is required. The revised manuscript now includes the full PGPO objective function with explicit terms for process rewards, the decoupled policy constraint (formulated to separate reward scaling from policy updates and thereby avoid circularity), and the length-aware dynamic sampling procedure together with pseudocode. These additions make the algorithm precisely defined and allow direct verification of its implementation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces V-tableR1 as an empirical extension of existing RL-with-verifiable-rewards methods to multimodal table reasoning. It relies on a critic VLM for step-level process feedback and proposes the PGPO algorithm for optimization, with all central claims (SOTA accuracy, hallucination penalization) grounded in experimental benchmarks rather than any closed-form derivations, self-definitional equations, or fitted parameters renamed as predictions. No load-bearing steps reduce by construction to the paper's own inputs or self-citations; the framework is presented as a practical application on the deterministic structure of tables, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The deterministic grid structure of tables serves as an ideal visual testbed allowing unambiguous grounding of logic into pixel space.
- domain assumption A specialized critic VLM can provide dense, accurate step-level feedback on the policy VLM's visual chain-of-thought.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE international confer- ence on computer vision
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: Proceedings of the IEEE international confer- ence on computer vision. pp. 2425–2433 (2015)
2015
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2510.01459 (2025)
Chen, W., Koenig, S., Dilkina, B.: Lspo: Length-aware dynamic sampling for policy optimization in llm reasoning. arXiv preprint arXiv:2510.01459 (2025)
-
[5]
ArXivabs/1909.02164(2019),https://api.semanticscholar.org/CorpusID: 1989173392
Chen, W., Wang, H., Chen, J., Zhang, Y., Wang, H., Li, S., Zhou, X., Wang, W.Y.: Tabfact: A large-scale dataset for table-based fact verification. arXiv preprint arXiv:1909.02164 (2019)
-
[6]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review arXiv 2024
-
[7]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Zhou, Q., Shen, Y., Hong, Y., Sun, Z., Gutfreund, D., Gan, C.: Visual chain-of-thought prompting for knowledge-based visual reasoning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 1254–1262 (2024)
2024
-
[8]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
Chen, Z., Chen, W., Smiley, C., Shah, S., Borova, I., Langdon, D., Moussa, R., Beane, M., Huang, T.H., Routledge, B.R., et al.: Finqa: A dataset of numerical reasoning over financial data. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 3697–3711 (2021)
2021
-
[9]
Cheng, Z., Dong, H., Wang, Z., Jia, R., Guo, J., Gao, Y., Han, S., Lou, J.G., Zhang, D.: Hitab: A hierarchical table dataset for question answering and natural languagegeneration.In:Proceedingsofthe60thAnnualMeetingoftheAssociation for Computational Linguistics (Volume 1: Long Papers). pp. 1094–1110 (2022)
2022
-
[10]
Process Reinforcement through Implicit Rewards
Cui, G., Yuan, L., Wang, Z., Wang, H., Zhang, Y., Chen, J., Li, W., He, B., Fan, Y., Yu, T., et al.: Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456 (2025)
work page internal anchor Pith review arXiv 2025
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Favero, A., Zancato, L., Trager, M., Choudhary, S., Perera, P., Achille, A., Swami- nathan, A., Soatto, S.: Multi-modal hallucination control by visual information grounding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14303–14312 (2024)
2024
-
[12]
Nature Machine In- telligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine In- telligence2(11), 665–673 (2020)
2020
-
[13]
In: Proceedings of the 58th Annual Meeting of the Associa- tion for Computational Linguistics
Gupta, V., Mehta, M., Nokhiz, P., Srikumar, V.: Infotabs: Inference on tables as semi-structured data. In: Proceedings of the 58th Annual Meeting of the Associa- tion for Computational Linguistics. pp. 2309–2324 (2020) 16 Authors Suppressed Due to Excessive Length
2020
-
[14]
arXiv preprint arXiv:2411.08516 (2024)
Ji, D., Zhu, L., Gao, S., Xu, P., Lu, H., Ye, J., Zhao, F.: Tree-of-table: Unleashing the power of llms for enhanced large-scale table understanding. arXiv preprint arXiv:2411.08516 (2024)
-
[15]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Jiao, F., Qin, C., Liu, Z., Chen, N., Joty, S.: Learning planning-based reasoning by trajectories collection and process reward synthesizing. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 334–350 (2024)
2024
-
[16]
Laurençon, H., Tronchon, L., Cord, M., Sanh, V.: What matters when building vision-language models? Advances in Neural Information Processing Systems37, 87874–87907 (2024)
2024
-
[17]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024)
work page internal anchor Pith review arXiv 2024
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[19]
Advances in neural information processing systems35, 2507– 2521 (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in neural information processing systems35, 2507– 2521 (2022)
2022
-
[20]
Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning
Lu, P., Qiu, L., Chang, K.W., Wu, Y.N., Zhu, S.C., Rajpurohit, T., Clark, P., Kalyan,A.:Dynamicpromptlearningviapolicygradientforsemi-structuredmath- ematical reasoning. arXiv preprint arXiv:2209.14610 (2022)
-
[21]
Mroueh, Y.: Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification. arXiv preprint arXiv:2503.06639 (2025)
-
[22]
Pasupat, P., Liang, P.: Compositional semantic parsing on semi-structured tables. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Pro- cessing (Volume 1: Long Papers). pp. 1470–1480 (2015)
2015
-
[23]
In: Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025)
Rawte, V., Mishra, A., Sheth, A., Das, A.: Defining and quantifying visual hal- lucinations in vision-language models. In: Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025). pp. 501–510 (2025)
2025
-
[24]
Robinson, J., Sun, L., Yu, K., Batmanghelich, K., Jegelka, S., Sra, S.: Can con- trastive learning avoid shortcut solutions? Advances in neural information process- ing systems34, 4974–4986 (2021)
2021
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Su, Y., Yu, D., Song, L., Li, J., Mi, H., Tu, Z., Zhang, M., Yu, D.: Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains. arXiv preprint arXiv:2503.23829 (2025)
-
[27]
arXiv preprint arXiv:2006.06434 (2020)
Sun, N., Yang, X., Liu, Y.: Tableqa: a large-scale chinese text-to-sql dataset for table-aware sql generation. arXiv preprint arXiv:2006.06434 (2020)
-
[28]
github.io/blog/qvq-72b-preview/
Team, Q.: Qvq: To see the world with wisdom (December 2024),https://qwenlm. github.io/blog/qvq-72b-preview/
2024
-
[29]
arXiv preprint arXiv:2505.21771 , year =
Titiya, P.Y., Trivedi, J., Baral, C., Gupta, V.: Mmtbench: A unified benchmark for complex multimodal table reasoning. arXiv preprint arXiv:2505.21771 (2025)
- [30]
-
[31]
Wang, Q., Wang, Z., Su, Y., Tong, H., Song, Y.: Rethinking the bounds of llm reasoning: Are multi-agent discussions the key? In: Proceedings of the 62nd Annual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers). pp. 6106–6131 (2024)
2024
-
[32]
Wang, W., Gao, Z., Chen, L., Chen, Z., Zhu, J., Zhao, X., Liu, Y., Cao, Y., Ye, S., Zhu, X., et al.: Visualprm: An effective process reward model for multimodal reasoning. arXiv preprint arXiv:2503.10291 (2025)
-
[33]
Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
Wang, Y., Wu, S., Zhang, Y., Yan, S., Liu, Z., Luo, J., Fei, H.: Multimodal chain- of-thought reasoning: A comprehensive survey. arXiv preprint arXiv:2503.12605 (2025)
-
[34]
Wang, Z., Zhang, H., Li, C.L., Eisenschlos, J.M., Perot, V., Wang, Z., Miculicich, L., Fujii, Y., Shang, J., Lee, C.Y., et al.: Chain-of-table: Evolving tables in the reasoning chain for table understanding. arXiv preprint arXiv:2401.04398 (2024)
-
[35]
arXiv preprint arXiv:2505.12415 (2025)
Wu, Z., Yang, J., Liu, J., Wu, X., Pan, C., Zhang, J., Zhao, Y., Song, S., Li, Y., Li, Z.: Table-r1: Region-based reinforcement learning for table understanding. arXiv preprint arXiv:2505.12415 (2025)
work page internal anchor Pith review arXiv 2025
-
[36]
In: Proceedings of the 60th Annual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers)
Yang, J., Gupta, A., Upadhyay, S., He, L., Goel, R., Paul, S.: Tableformer: Robust transformer modeling for table-text encoding. In: Proceedings of the 60th Annual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers). pp. 528–537 (2022)
2022
-
[37]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al.: Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yue, Y., Yuan, Y., Yu, Q., Zuo, X., Zhu, R., Xu, W., Chen, J., Wang, C., Fan, T., Du, Z., et al.: Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks. arXiv preprint arXiv:2504.05118 (2025)
work page internal anchor Pith review arXiv 2025
-
[39]
IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024)
Zhang, J., Huang, J., Jin, S., Lu, S.: Vision-language models for vision tasks: A survey. IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024)
2024
-
[40]
Frontiers of Computer Science19(9), 199348 (2025)
Zhang, X., Wang, D., Dou, L., Zhu, Q., Che, W.: A survey of table reasoning with large language models. Frontiers of Computer Science19(9), 199348 (2025)
2025
-
[41]
In: Findings of the Association for Computational Linguistics: ACL 2025
Zhang, Z., Zheng, C., Wu, Y., Zhang, B., Lin, R., Yu, B., Liu, D., Zhou, J., Lin, J.: The lessons of developing process reward models in mathematical reasoning. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 10495– 10516 (2025)
2025
-
[42]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023)
work page internal anchor Pith review arXiv 2023
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, Q., Lu, Y., Kim, M.J., Fu, Z., Zhang, Z., Wu, Y., Li, Z., Ma, Q., Han, S., Finn, C., et al.: Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1702–1713 (2025)
2025
-
[44]
Advances in Neural Information Processing Systems37, 7185–7212 (2024)
Zhao, W., Feng, H., Liu, Q., Tang, J., Wu, B., Liao, L., Wei, S., Ye, Y., Liu, H., Zhou, W., et al.: Tabpedia: Towards comprehensive visual table understanding with concept synergy. Advances in Neural Information Processing Systems37, 7185–7212 (2024)
2024
-
[45]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Zheng, M., Feng, X., Si, Q., She, Q., Lin, Z., Jiang, W., Wang, W.: Multimodal ta- ble understanding. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9102–9124 (2024)
2024
-
[46]
International journal of computer vision130(9), 2337–2348 (2022) 18 Authors Suppressed Due to Excessive Length
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International journal of computer vision130(9), 2337–2348 (2022) 18 Authors Suppressed Due to Excessive Length
2022
-
[47]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
work page internal anchor Pith review arXiv 2023
-
[48]
Zhu, F., Lei, W., Huang, Y., Wang, C., Zhang, S., Lv, J., Feng, F., Chua, T.S.: Tat-qa: A question answering benchmark on a hybrid of tabular and textual con- tent in finance. In: Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: lon...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.