Recognition: unknown
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Pith reviewed 2026-05-10 00:21 UTC · model grok-4.3
The pith
Synthetic videos generated from text can train physics-based dexterous controllers that generalize to unseen objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present DeVI (Dexterous Video Imitation), a novel framework that leverages text-conditioned synthetic videos to enable physically plausible dexterous agent control for interacting with unseen target objects. To overcome the imprecision of generative 2D cues, we introduce a hybrid tracking reward that integrates 3D human tracking with robust 2D object tracking. Unlike methods relying on high-quality 3D kinematic demonstrations, DeVI requires only the generated video, enabling zero-shot generalization across diverse objects and interaction types.
What carries the argument
The hybrid tracking reward that combines 3D human pose tracking from the video with robust 2D object tracking to guide reinforcement learning of physics-based dexterous controllers.
If this is right
- Outperforms existing approaches that imitate 3D human-object interaction demonstrations, particularly in modeling dexterous hand-object interactions.
- Enables zero-shot generalization across diverse objects and interaction types using only the generated video.
- Supports effective control in multi-object scenes.
- Facilitates text-driven action diversity through video-based planning.
Where Pith is reading between the lines
- This method could scale dexterous skill acquisition if paired with improved video generators that better respect physics.
- It suggests video models might eventually replace manual demonstration collection for training robotic manipulation policies.
- Controllers from this approach could be tested for transfer to real robots by measuring success rates on physical objects that match the video categories.
Load-bearing premise
That the hybrid 3D human and 2D object tracking reward can extract sufficient and accurate enough signals from physically imprecise and 2D generative videos to produce stable and generalizable controllers.
What would settle it
Training a controller on synthetic videos of grasping one object category and testing whether it maintains stable contact and manipulation success when the object is replaced by one with different shape or dynamics not matching the video cues.
Figures




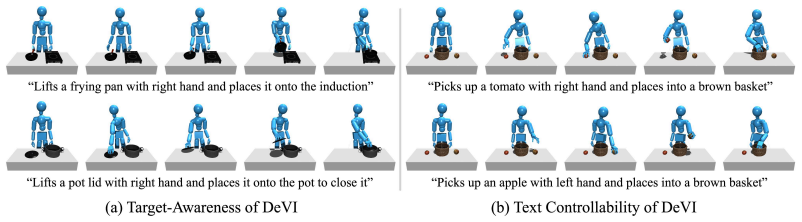







read the original abstract
Recent advances in video generative models enable the synthesis of realistic human-object interaction videos across a wide range of scenarios and object categories, including complex dexterous manipulations that are difficult to capture with motion capture systems. While the rich interaction knowledge embedded in these synthetic videos holds strong potential for motion planning in dexterous robotic manipulation, their limited physical fidelity and purely 2D nature make them difficult to use directly as imitation targets in physics-based character control. We present DeVI (Dexterous Video Imitation), a novel framework that leverages text-conditioned synthetic videos to enable physically plausible dexterous agent control for interacting with unseen target objects. To overcome the imprecision of generative 2D cues, we introduce a hybrid tracking reward that integrates 3D human tracking with robust 2D object tracking. Unlike methods relying on high-quality 3D kinematic demonstrations, DeVI requires only the generated video, enabling zero-shot generalization across diverse objects and interaction types. Extensive experiments demonstrate that DeVI outperforms existing approaches that imitate 3D human-object interaction demonstrations, particularly in modeling dexterous hand-object interactions. We further validate the effectiveness of DeVI in multi-object scenes and text-driven action diversity, showcasing the advantage of using video as an HOI-aware motion planner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeVI, a framework that trains physics-based dexterous controllers for human-object interactions by imitating text-conditioned synthetic videos from generative models. It proposes a hybrid tracking reward that combines 3D human pose tracking with 2D object mask/bbox tracking to compensate for the limited physical fidelity and 2D nature of the videos, enabling zero-shot generalization to unseen objects and outperforming methods that rely on 3D kinematic demonstrations. The work further claims validation on multi-object scenes and text-driven action diversity.
Significance. If the hybrid reward successfully yields stable, generalizable controllers despite video artifacts, the approach could meaningfully advance scalable dexterous manipulation learning by substituting abundant synthetic video data for expensive mocap capture. This would be particularly valuable for complex hand-object interactions that are hard to demonstrate in 3D.
major comments (2)
- [Method] Method section (hybrid tracking reward): the claim that combining 3D human tracking with 2D object tracking overcomes generative-video inconsistencies (jitter, penetration artifacts, missing depth, and lack of 3D object orientation) is load-bearing for the physical-plausibility premise, yet no equations, weighting scheme, or contact-consistency term are provided to show how the reward remains dense and accurate enough for RL to discover non-penetrating, stable policies on unseen objects.
- [Experiments] Experiments section: the abstract asserts outperformance on dexterous tasks and validation on multi-object/text-driven cases, but supplies no quantitative metrics, ablation tables, success rates, or error analysis; without these, the central claim that the hybrid reward produces superior controllers cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experiments demonstrate' is used without any supporting numbers or references to specific tables/figures, which reduces clarity.
Simulated Author's Rebuttal
We sincerely thank the referee for their detailed and insightful review of our work on DeVI. Their comments highlight important areas for improvement in the clarity of our method and experimental validation. We will revise the manuscript to address these points thoroughly.
read point-by-point responses
-
Referee: [Method] Method section (hybrid tracking reward): the claim that combining 3D human tracking with 2D object tracking overcomes generative-video inconsistencies (jitter, penetration artifacts, missing depth, and lack of 3D object orientation) is load-bearing for the physical-plausibility premise, yet no equations, weighting scheme, or contact-consistency term are provided to show how the reward remains dense and accurate enough for RL to discover non-penetrating, stable policies on unseen objects.
Authors: We appreciate the referee's emphasis on the importance of the hybrid tracking reward formulation. Upon review, we recognize that the current manuscript provides a high-level description but lacks the detailed equations and weighting parameters. In the revised version, we will include the complete reward function equations, specifying the weights for the 3D human tracking component (using SMPL pose and joint positions) and the 2D object components (using IoU for masks and L1 for bboxes). Furthermore, we will add a contact consistency term that uses collision detection to penalize penetrations, ensuring the reward guides the policy effectively despite video artifacts. This will better illustrate the robustness for zero-shot generalization to unseen objects. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts outperformance on dexterous tasks and validation on multi-object/text-driven cases, but supplies no quantitative metrics, ablation tables, success rates, or error analysis; without these, the central claim that the hybrid reward produces superior controllers cannot be evaluated.
Authors: We agree that quantitative evidence is essential to support our claims. The current manuscript includes some experimental results, but we acknowledge they are not presented in a sufficiently detailed or tabular format. We will revise the Experiments section to include ablation tables, success rate metrics (e.g., percentage of successful interactions without falling or penetrating), tracking error metrics, and error analysis for multi-object and text-driven scenarios. This will enable a clear evaluation of how the hybrid reward outperforms 3D kinematic demonstration baselines. revision: yes
Circularity Check
No circularity: DeVI pipeline uses external generative models and standard trackers without self-referential reductions
full rationale
The paper's core derivation proceeds from text-conditioned external video generators to a hybrid 3D-human + 2D-object tracking reward that is then used as an RL signal for physics-based control. No equations, fitted parameters, or central claims reduce by construction to quantities defined inside the paper; the hybrid reward is assembled from off-the-shelf components whose outputs are treated as independent inputs. Experiments compare against prior 3D-demonstration baselines rather than deriving performance from the method's own fitted values. This is the normal case of a self-contained engineering pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Monoscene: Monocular 3d semantic scene completion
Anh-Quan Cao and Raoul de Charette. Monoscene: Monocular 3d semantic scene completion. InCVPR, 2022
2022
-
[2]
Large Video Planner Enables Generalizable Robot Control
Boyuan Chen, Tianyuan Zhang, Haoran Geng, Kiwhan Song, Caiyi Zhang, Peihao Li, William T. Freeman, Jitendra Malik, Pieter Abbeel, Russ Tedrake, Vincent Sitzmann, and Yilun Du. Large video planner enables generalizable robot control. InarXiv:2512.15840, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Anyskill: Learning open-vocabulary physical skill for interactive agents
Jieming Cui, Tengyu Liu, Nian Liu, Yaodong Yang, Yixin Zhu, and Siyuan Huang. Anyskill: Learning open-vocabulary physical skill for interactive agents. InCVPR, 2024
2024
-
[4]
Grove: A generalized reward for learning open-vocabulary physical skill
Jieming Cui, Tengyu Liu, Meng Ziyu, Yu Jiale, Ran Song, Wei Zhang, Yixin Zhu, and Siyuan Huang. Grove: A generalized reward for learning open-vocabulary physical skill. InCVPR, 2025
2025
-
[5]
Learning universal policies via text-guided video generation
Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InNeurIPS, 2023
2023
-
[6]
Black, and Dimitrios Tzionas
Sai Kumar Dwivedi, Dimitrije Anti ´c, Shashank Tripathi, Omid Taheri, Cordelia Schmid, Michael J. Black, and Dimitrios Tzionas. Interactvlm: 3d interaction reasoning from 2D foundational models. InCVPR, 2025
2025
-
[7]
Black, and Otmar Hilliges
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J. Black, and Otmar Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. InCVPR, 2023
2023
-
[8]
Yao Feng, Hengkai Tan, Xinyi Mao, Chendong Xiang, Guodong Liu, Shuhe Huang, Hang Su, and Jun Zhu. Vidar: Embodied video diffusion model for generalist manipulation. In arXiv:2507.12898, 2025
-
[9]
Coohoi: Learning cooperative human-object interaction with manipulated object dynamics
Jiawei Gao, Ziqin Wang, Zeqi Xiao, Jingbo Wang, Tai Wang, Jinkun Cao, Xiaolin Hu, Si Liu, Jifeng Dai, and Jiangmiao Pang. Coohoi: Learning cooperative human-object interaction with manipulated object dynamics. InNeurIPS, 2024
2024
-
[10]
Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y
Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H. Huang, Dhruva Tirumala, Jan Humplik, Markus Wulfmeier, Saran Tunyasuvunakool, Noah Y . Siegel, Roland Hafner, Michael Bloesch, Kristian Hartikainen, Arunkumar Byravan, Leonard Hasenclever, Yuval Tassa, Fereshteh Sadeghi, Nathan Batchelor, Federico Casarini, Stefano Saliceti, Charles Game, Neil Sreendra, Kush...
2024
-
[11]
Synthesizing physical character-scene interactions
Mohamed Hassan, Yunrong Guo, Tingwu Wang, Michael Black, Sanja Fidler, and Xue Bin Peng. Synthesizing physical character-scene interactions. InProc. ACM SIGGRAPH, 2023
2023
-
[12]
Available: https://arxiv.org/abs/2502.01143
Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Sobanbabu, Chaoyi Pan, Zeji Yi, Guannan Qu, Kris Kitani, Jessica Hodgins, Linxi "Jim" Fan, Yuke Zhu, Changliu Liu, and Guanya Shi. Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills. InarXiv:2502.01143, 2025
-
[13]
Shin, and Junyong Noh
Seokpyo Hong, Daseong Han, Kyungmin Cho, Joseph S. Shin, and Junyong Noh. Physics-based full-body soccer motion control for dribbling and shooting. InACM TOG, 2019
2019
-
[14]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. InarXiv:2205.15868, 2022
work page internal anchor Pith review arXiv 2022
-
[15]
Black, David W
Angjoo Kanazawa, Michael J. Black, David W. Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InCVPR, 2018
2018
-
[16]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In arXiv:2410.11831, 2024. 10
-
[17]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Questenvsim: Environment-aware simulated motion tracking from sparse sensors
Sunmin Lee, Sebastian Starke, Yuting Ye, Jungdam Won, and Alexander Winkler. Questenvsim: Environment-aware simulated motion tracking from sparse sensors. InProc. ACM SIGGRAPH, 2023
2023
-
[19]
Object motion guided human motion synthesis
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis. In ACM TOG, 2023
2023
-
[20]
Karen Liu
Jiaman Li, Alexander Clegg, Roozbeh Mottaghi, Jiajun Wu, Xavier Puig, and C. Karen Liu. Controllable human-object interaction synthesis. InECCV, 2024
2024
-
[21]
Dreamitate: Real-world visuomotor policy learning via video generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, and Carl V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. InCoRL, 2024
2024
-
[22]
Lightx2v: Light video generation inference framework
LightX2V Contributors. Lightx2v: Light video generation inference framework. https: //github.com/ModelTC/lightx2v, 2025
2025
-
[23]
Yuhang Lin, Yijia Xie, Jiahong Xie, Yuehao Huang, Ruoyu Wang, Jiajun Lv, Yukai Ma, and Xingxing Zuo. Simgenhoi: Physically realistic whole-body humanoid-object interaction via generative modeling and reinforcement learning. InarXiv:2508.14120, 2025
-
[24]
Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning
Libin Liu and Jessica Hodgins. Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning. InACM TOG, 2018
2018
-
[25]
Siqi Liu, Guy Lever, Zhe Wang, Josh Merel, S. M. Ali Eslami, Daniel Hennes, Wojciech M. Czarnecki, Yuval Tassa, Shayegan Omidshafiei, Abbas Abdolmaleki, Noah Y . Siegel, Leonard Hasenclever, Luke Marris, Saran Tunyasuvunakool, H. Francis Song, Markus Wulfmeier, Paul Muller, Tuomas Haarnoja, Brendan Tracey, Karl Tuyls, Thore Graepel, and Nicolas Heess. Fro...
2022
-
[26]
Zero-shot human-object interaction synthesis with multimodal priors
Yuke Lou, Yiming Wang, Zhen Wu, Rui Zhao, Wenjia Wang, Mingyi Shi, and Taku Komura. Zero-shot human-object interaction synthesis with multimodal priors. InarXiv:2503.20118, 2025
-
[27]
Winkler, Kris Kitani, and Weipeng Xu
Zhengyi Luo, Jinkun Cao, Alexander W. Winkler, Kris Kitani, and Weipeng Xu. Perpetual humanoid control for real-time simulated avatars. InICCV, 2023
2023
-
[28]
Kitani, and Weipeng Xu
Zhengyi Luo, Jinkun Cao, Josh Merel, Alexander Winkler, Jing Huang, Kris M. Kitani, and Weipeng Xu. Universal humanoid motion representations for physics-based control. InICLR, 2024
2024
-
[29]
Sm- plolympics: Sports environments for physically simulated humanoids
Zhengyi Luo, Jiashun Wang, Kangni Liu, Haotian Zhang, Chen Tessler, Jingbo Wang, Ye Yuan, Jinkun Cao, Zihui Lin, Fengyi Wang, et al. Smplolympics: Sports environments for physically simulated humanoids. InarXiv:2407.00187, 2024
-
[30]
Isaac gym: High performance gpu-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning. InNeurIPS, 2021
2021
-
[31]
Chatgpt: Optimizing language models for dialogue
OpenAI. Chatgpt: Optimizing language models for dialogue. https://openai.com/blog/ chatgpt/, (accessed Jan 18th, 2026)
2026
-
[32]
Synthesizing physically plausible human motions in 3d scenes
Liang Pan, Jingbo Wang, Buzhen Huang, Junyu Zhang, Haofan Wang, Xu Tang, and Yangang Wang. Synthesizing physically plausible human motions in 3d scenes. In3DV, 2024
2024
-
[33]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. InCVPR, 2019
2019
-
[34]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InCVPR, 2024. 11
2024
-
[35]
Deepmimic: Example- guided deep reinforcement learning of physics-based character skills
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. Deepmimic: Example- guided deep reinforcement learning of physics-based character skills. InACM TOG, 2018
2018
-
[36]
Amp: Adversarial motion priors for stylized physics-based character control
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control. InACM TOG, 2021
2021
-
[37]
Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters. InACM TOG, 2022
2022
-
[38]
Scott D. Roth. Ray casting for modeling solids. InComput. Graph. Image Process., 1982
1982
-
[39]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. InarXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InarXiv:1506.02438, 2018
work page internal anchor Pith review arXiv 2018
-
[41]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. In Proc. ACM SIGGRAPH Asia, 2024
2024
-
[42]
SketchFab.https://sketchfab.com/, (accessed Jul 20th, 2025)
2025
-
[43]
Grab: A dataset of whole-body human grasping of objects
Omid Taheri, Nima Ghorbani, Michael J Black, and Dimitrios Tzionas. Grab: A dataset of whole-body human grasping of objects. InECCV, 2020
2020
-
[44]
SAM 3D: 3Dfy Anything in Images
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images. In arXiv:25...
work page internal anchor Pith review arXiv 2025
-
[45]
Calm: Conditional adversarial latent models for directable virtual characters
Chen Tessler, Yoni Kasten, Yunrong Guo, Shie Mannor, Gal Chechik, and Xue Bin Peng. Calm: Conditional adversarial latent models for directable virtual characters. InProc. ACM SIGGRAPH, 2023
2023
-
[46]
Maskedmimic: Unified physics-based character control through masked motion
Chen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, and Xue Bin Peng. Maskedmimic: Unified physics-based character control through masked motion. InACM TOG, 2024
2024
-
[47]
Closd: Closing the loop between simulation and diffusion for multi-task character control
Guy Tevet, Sigal Raab, Setareh Cohan, Daniele Reda, Zhengyi Luo, Xue Bin Peng, Amit Haim Bermano, and Michiel van de Panne. Closd: Closing the loop between simulation and diffusion for multi-task character control. InICLR, 2025
2025
-
[48]
Shashank Tripathi, Agniv Chatterjee, Jean-Claude Passy, Hongwei Yi, Dimitrios Tzionas, and Michael J. Black. Deco: Dense estimation of 3d human-scene contact in the wild. InICCV, 2023
2023
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Strategy and skill learning for physics-based table tennis animation
Jiashun Wang, Jessica Hodgins, and Jungdam Won. Strategy and skill learning for physics-based table tennis animation. InProc. ACM SIGGRAPH, 2024
2024
-
[51]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024. 12
2024
-
[52]
Yinhuai Wang, Jing Lin, Ailing Zeng, Zhengyi Luo, Jian Zhang, and Lei Zhang. Physhoi: Physics-based imitation of dynamic human-object interaction. InarXiv:2312.04393, 2023
-
[53]
Skillmimic: Learning basketball interaction skills from demonstrations
Yinhuai Wang, Qihan Zhao, Runyi Yu, Hok Wai Tsui, Ailing Zeng, Jing Lin, Zhengyi Luo, Jiwen Yu, Xiu Li, Qifeng Chen, Jian Zhang, Lei Zhang, and Ping Tan. Skillmimic: Learning basketball interaction skills from demonstrations. InCVPR, 2025
2025
-
[54]
Tram: Global trajectory and motion of 3d humans from in-the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos. InarXiv:2403.17346, 2024
-
[55]
Vid- man: Exploiting implicit dynamics from video diffusion model for effective robot manipulation
Youpeng Wen, Junfan Lin, Yi Zhu, Jianhua Han, Hang Xu, Shen Zhao, and Xiaodan Liang. Vid- man: Exploiting implicit dynamics from video diffusion model for effective robot manipulation. InNeurIPS, 2024
2024
-
[56]
Karen Liu
Zhen Wu, Jiaman Li, Pei Xu, and C. Karen Liu. Human-object interaction from human-level instructions. InICCV, 2025
2025
-
[57]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In CVPR, 2025
2025
-
[58]
Unified human-scene interaction via prompted chain-of-contacts
Zeqi Xiao, Tai Wang, Jingbo Wang, Jinkun Cao, Wenwei Zhang, Bo Dai, Dahua Lin, and Jiangmiao Pang. Unified human-scene interaction via prompted chain-of-contacts. InICLR, 2024
2024
-
[59]
Chore: Contact, human and object reconstruction from a single rgb image
Xianghui Xie, Bharat Lal Bhatnagar, and Gerard Pons-Moll. Chore: Contact, human and object reconstruction from a single rgb image. InECCV, 2022
2022
-
[60]
Cari4d: Category agnostic 4d reconstruction of human-object interaction
Xianghui Xie, Bowen Wen, Yan Chang, Hesam Rabeti, Jiefeng Li, Ye Yuan, Gerard Pons-Moll, and Stan Birchfield. Cari4d: Category agnostic 4d reconstruction of human-object interaction. InCVPR, 2026
2026
-
[61]
Learning soccer juggling skills with layer-wise mixture-of-experts
Zhaoming Xie, Sebastian Starke, Hung Yu Ling, and Michiel van de Panne. Learning soccer juggling skills with layer-wise mixture-of-experts. InProc. ACM SIGGRAPH, 2022
2022
-
[62]
Karen Liu
Zhaoming Xie, Jonathan Tseng, Sebastian Starke, Michiel van de Panne, and C. Karen Liu. Hierarchical planning and control for box loco-manipulation. InACM Comput. Graph. Interact. Tech., 2023
2023
-
[63]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models. InarXiv:2404.07191, 2024
work page internal anchor Pith review arXiv 2024
-
[64]
Intermimic: Towards universal whole-body control for physics-based human-object interactions
Sirui Xu, Hung Yu Ling, Yu-Xiong Wang, and Liang-Yan Gui. Intermimic: Towards universal whole-body control for physics-based human-object interactions. InCVPR, 2025
2025
-
[65]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
2024
-
[66]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InarXiv:2408.06072, 2024
work page internal anchor Pith review arXiv 2024
-
[67]
Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors
Tao Yu, Zerong Zheng, Kaiwen Guo, Pengpeng Liu, Qionghai Dai, and Yebin Liu. Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors. InCVPR, 2021
2021
-
[68]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InICCV, 2023
2023
-
[69]
Zhang, Sam Pepose, Hanbyul Joo, Deva Ramanan, Jitendra Malik, and Angjoo Kanazawa
Jason Y . Zhang, Sam Pepose, Hanbyul Joo, Deva Ramanan, Jitendra Malik, and Angjoo Kanazawa. Perceiving 3d human-object spatial arrangements from a single image in the wild. InECCV, 2020. 13
2020
-
[70]
A plug-and-play physical motion restoration approach for in-the-wild high-difficulty motions
Youliang Zhang, Ronghui Li, Yachao Zhang, Liang Pan, Jingbo Wang, Yebin Liu, and Xiu Li. A plug-and-play physical motion restoration approach for in-the-wild high-difficulty motions. InICCV, 2025
2025
-
[71]
Physics- based motion imitation with adversarial differential discriminators
Ziyu Zhang, Sergey Bashkirov, Dun Yang, Yi Shi, Michael Taylor, and Xue Bin Peng. Physics- based motion imitation with adversarial differential discriminators. InProc. ACM SIGGRAPH Asia, 2025. 14 A Implementation Details A.1 Scene Initialization Our scene initialization follows a tabletop scenario. We place an SMPL-X [33] human at the origin on the xy-pla...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.