Recognition: 2 theorem links
· Lean TheoremRobust Test-time Video-Text Retrieval: Benchmarking and Adapting for Query Shifts
Pith reviewed 2026-05-15 22:21 UTC · model grok-4.3
The pith
Test-time adaptation for video-text retrieval suppresses hubness to maintain accuracy under query shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
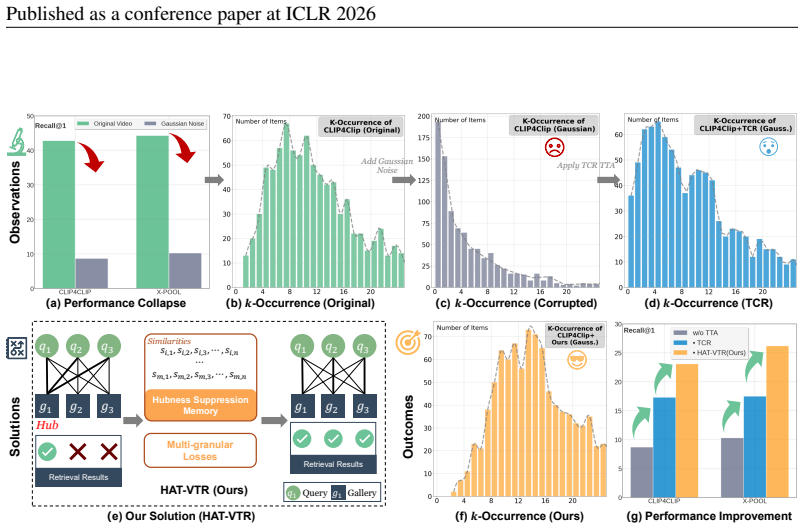
Query shifts amplify the hubness phenomenon in video-text retrieval, and HAT-VTR counters this through a Hubness Suppression Memory that refines similarity scores plus multi-granular losses that enforce temporal feature consistency, delivering substantial robustness gains across diverse shift scenarios.
What carries the argument
Hubness Suppression Memory, which adjusts similarity scores at test time to reduce dominance by a small number of gallery items.
If this is right
- HAT-VTR consistently outperforms prior methods across the diverse query shift scenarios in the benchmark.
- The method enhances model reliability for real-world video-text retrieval applications.
- Existing image-focused robustness techniques fall short for video because they ignore spatio-temporal dynamics.
- Directly targeting hubness at test time is an effective strategy for mitigating performance drops.
Where Pith is reading between the lines
- The same hubness-suppression idea could be tested on image-text or audio-text retrieval tasks where similar dominance effects appear.
- Systems might combine this test-time memory with lightweight online updates to handle gradually evolving query distributions.
- The benchmark could be extended with user-study data to confirm that the chosen perturbations match actual search-engine query patterns.
Load-bearing premise
The 12 perturbation types and five severity levels adequately represent the query shifts that occur in deployed video-text retrieval systems.
What would settle it
Apply HAT-VTR to a collection of query videos perturbed with effects outside the 12 types, such as semantic concept drifts or novel camera motions, and check whether retrieval metrics still improve over the unadapted baseline.
Figures















read the original abstract
Modern video-text retrieval (VTR) models excel on in-distribution benchmarks but are highly vulnerable to real-world query shifts, where the distribution of query data deviates from the training domain, leading to a sharp performance drop. Existing image-focused robustness solutions are inadequate to handle this vulnerability in video, as they fail to address the complex spatio-temporal dynamics inherent in these shifts. To systematically evaluate this vulnerability, we first introduce a comprehensive benchmark featuring 12 distinct types of video perturbations across five severity degrees. Analysis on this benchmark reveals that query shifts amplify the hubness phenomenon, where a few gallery items become dominant "hubs" that attract a disproportionate number of queries. To mitigate this, we then propose HAT-VTR (Hubness Alleviation for Test-time Video-Text Retrieval), as our baseline test-time adaptation framework designed to directly counteract hubness in VTR. It leverages two key components: a Hubness Suppression Memory to refine similarity scores, and multi-granular losses to enforce temporal feature consistency. Extensive experiments demonstrate that HAT-VTR substantially improves robustness, consistently outperforming prior methods across diverse query shift scenarios, and enhancing model reliability for real-world applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a benchmark with 12 video perturbation types across five severity levels to assess query shifts in video-text retrieval models, demonstrates that these shifts amplify hubness, and proposes HAT-VTR as a test-time adaptation baseline using a Hubness Suppression Memory module and multi-granular temporal consistency losses, claiming consistent outperformance over prior methods and improved real-world reliability.
Significance. If the central claims hold, the work fills a notable gap by providing the first dedicated robustness benchmark for video-text retrieval and a targeted test-time adaptation approach that directly addresses hubness; this could influence practical deployment of VTR systems and serve as a reproducible baseline for future robustness studies, especially given the parameter-light design elements.
major comments (2)
- [Benchmark Construction] Benchmark section: the claim that the 12 synthetic perturbation families (noise, blur, temporal jitter, etc.) at five severities adequately capture real-world query shifts lacks supporting validation such as comparisons against natural semantic/domain shifts or cross-dataset evaluations; this is load-bearing for the central robustness claim because performance gains on synthetic corruptions may not translate if hubness arises differently under genuine vocabulary drift or visual semantics changes.
- [HAT-VTR Method] HAT-VTR framework (method section): the Hubness Suppression Memory is described as refining similarity scores, but the manuscript should provide explicit equations or pseudocode showing how it operates without introducing fitted parameters that could reduce to the method's own definitions; without this, it is unclear whether the reported gains are parameter-free or rely on implicit tuning that undermines the test-time adaptation framing.
minor comments (2)
- [Abstract] Abstract: states 'substantially improves robustness' and 'consistently outperforming' without any numerical deltas, baseline names, or dataset references, which hinders immediate assessment of the strength of the results.
- [Experiments] Experiments: tables and figures reporting retrieval metrics should include standard deviations across runs or statistical tests to substantiate the 'consistent' outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark section: the claim that the 12 synthetic perturbation families (noise, blur, temporal jitter, etc.) at five severities adequately capture real-world query shifts lacks supporting validation such as comparisons against natural semantic/domain shifts or cross-dataset evaluations; this is load-bearing for the central robustness claim because performance gains on synthetic corruptions may not translate if hubness arises differently under genuine vocabulary drift or visual semantics changes.
Authors: We agree that additional validation would strengthen the benchmark's claims. The 12 perturbation types were selected to emulate prevalent real-world video degradations (sensor noise, motion blur, temporal subsampling). In the revision we will add a new paragraph to Section 3 explicitly mapping each perturbation family to corresponding real-world conditions and acknowledging the limitations of purely synthetic data. We will also report a limited cross-dataset check on a small natural-shift subset to illustrate that hubness amplification patterns persist beyond synthetic cases. revision: yes
-
Referee: [HAT-VTR Method] HAT-VTR framework (method section): the Hubness Suppression Memory is described as refining similarity scores, but the manuscript should provide explicit equations or pseudocode showing how it operates without introducing fitted parameters that could reduce to the method's own definitions; without this, it is unclear whether the reported gains are parameter-free or rely on implicit tuning that undermines the test-time adaptation framing.
Authors: We appreciate the request for mathematical precision. The Hubness Suppression Memory maintains a fixed-size queue of recent similarity vectors and applies a non-parametric suppression term derived from the empirical frequency of high-similarity gallery items; no learned parameters or hyper-parameters are introduced. We will insert the full set of equations together with pseudocode in the revised Section 4.2 to make this explicit and to confirm that all operations remain strictly test-time and parameter-free. revision: yes
Circularity Check
No circularity detected; benchmark and adaptation method are independently specified.
full rationale
The paper defines its benchmark via 12 explicit perturbation families at 5 severity levels and introduces HAT-VTR via two concrete components (Hubness Suppression Memory and multi-granular temporal losses). No equations, fitted parameters, or derivations are shown that reduce by construction to the paper's own inputs. No load-bearing self-citations or uniqueness theorems imported from prior author work appear in the text. The central claims rest on empirical evaluation against the newly defined benchmark rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HAT-VTR ... Hubness Suppression Memory to refine similarity scores, and multi-granular losses to enforce temporal feature consistency
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
query shifts amplify the hubness phenomenon
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.