Deep Interest Mining with Cross-Modal Alignment for SemanticID Generation in Generative Recommendation
Pith reviewed 2026-05-15 16:57 UTC · model grok-4.3
The pith
A framework with deep interest mining, cross-modal alignment, and quality-aware reinforcement generates higher-quality Semantic IDs for generative recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating Deep Contextual Interest Mining, Cross-Modal Semantic Alignment, and Quality-Aware Reinforcement Mechanism addresses information degradation, semantic degradation, and modality distortion in Semantic ID generation, resulting in SIDs that preserve more original semantics and lead to superior performance on recommendation benchmarks compared to existing two-stage approaches.
What carries the argument
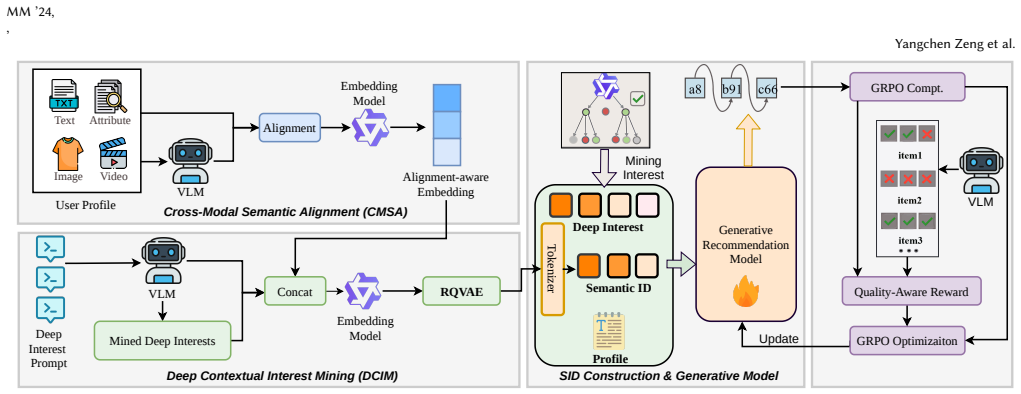
The three-component framework of Deep Contextual Interest Mining (DCIM) for capturing high-level semantics through reconstruction supervision, Cross-Modal Semantic Alignment (CMSA) for unifying modalities via vision-language models, and Quality-Aware Reinforcement Mechanism (QARM) for posterior selection of rich IDs.
If this is right
- Semantic IDs retain more critical contextual information from advertising contexts through reconstruction-based supervision.
- High-quality SIDs are encouraged while low-quality ones are suppressed through quality-aware reinforcement learning rewards.
- Modality distortion is reduced by aligning non-textual features into a unified text-based semantic space.
- Joint optimization of embedding generation and quantization prevents semantic loss from cascaded processes.
- The method achieves superior results on multiple generative recommendation benchmarks.
Where Pith is reading between the lines
- The joint optimization strategy could extend to other compression tasks that convert multimodal data into discrete sequences.
- Making ID generation sensitive to quality signals might allow smaller vocabularies to support equivalent performance on large datasets.
- The reinforcement component could be tested for robustness when swapping different vision-language model backbones.
Load-bearing premise
That the quality-aware rewards in the reinforcement mechanism can be defined to accurately reflect semantic richness without causing training instability or introducing unintended biases.
What would settle it
Running the full method on a standard multimodal recommendation benchmark and observing no improvement in downstream next-token prediction metrics or hit rates over existing SID baselines would falsify the central claim.
Figures

read the original abstract
Generative Recommendation (GR) has demonstrated remarkable performance in next-token prediction paradigms, which relies on Semantic IDs (SIDs) to compress trillion-scale data into learnable vocabulary sequences. However, existing methods suffer from three critical limitations: (1) Information Degradation: the two-stage compression pipeline causes semantic loss and information degradation, with no posterior mechanism to distinguish high-quality from low-quality SIDs; (2) Semantic Degradation: cascaded quantization discards key semantic information from original multimodal features, as the embedding generation and quantization stages are not jointly optimized toward a unified objective; (3) Modality Distortion: quantizers fail to properly align text and image modalities, causing feature misalignment even when upstream networks have aligned them. To address these challenges, we propose a novel framework integrating three key innovations: Deep Contextual Interest Mining (DCIM), Cross-Modal Semantic Alignment (CMSA), and Quality-Aware Reinforcement Mechanism (QARM). First, we leverage Vision-Language Models (VLMs) to align non-textual modalities into a unified text-based semantic space, mitigating modality distortion. Second, we introduce a deep interest mining mechanism that captures high-level semantic information implicitly present in advertising contexts, encouraging SIDs to preserve critical contextual information through reconstruction-based supervision. Third, we employ a reinforcement learning framework with quality-aware rewards to encourage semantically rich SIDs while suppressing low-quality ones in the posterior stage. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art SID generation methods, achieving superior performance on multiple benchmarks. Ablation studies further validate the effectiveness of each proposed component
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-component framework (DCIM, CMSA, QARM) for Semantic ID (SID) generation in generative recommendation to address information degradation in two-stage pipelines, semantic loss from cascaded quantization, and modality misalignment between text and images. It uses VLMs to map modalities into a unified text space, applies deep interest mining with reconstruction supervision to preserve contextual semantics, and employs an RL framework with quality-aware rewards to distinguish high- from low-quality SIDs in the posterior stage. The central claim is consistent outperformance over SOTA SID methods on multiple benchmarks, with ablations confirming each component's contribution.
Significance. If the reported gains and ablation results hold under rigorous controls, the work would provide a practical advance in generative recommendation by producing SIDs that retain more multimodal semantics and contextual quality, potentially improving next-token prediction accuracy and reducing information loss in trillion-scale catalogs.
major comments (2)
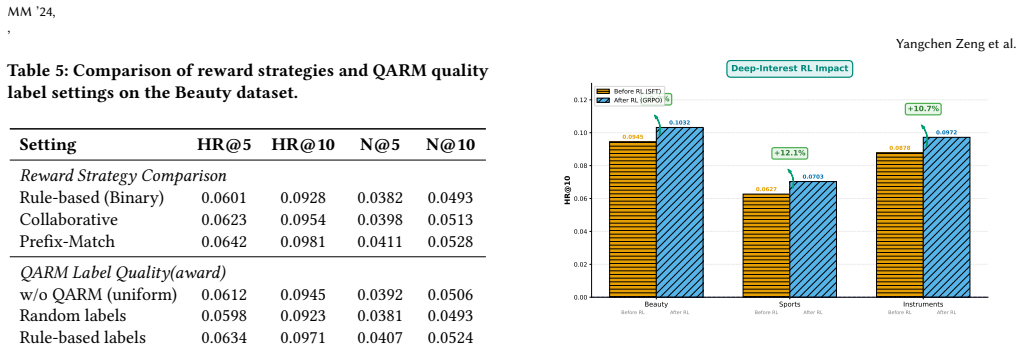
- [§4.2] §4.2 (QARM description): the quality-aware reward is defined using reconstruction loss and semantic similarity scores that are themselves optimized within the joint training objective; this creates a circularity risk where claimed posterior quality improvements may simply reflect better fitting to the same supervision signals rather than independent quality discrimination.
- [Table 2, §5.1] Table 2 and §5.1: the main results table reports consistent outperformance, but the experimental setup section provides no details on the exact number of runs, variance estimates, or statistical significance tests; without these, it is impossible to assess whether the reported margins over baselines are robust or could be explained by hyperparameter sensitivity.
minor comments (2)
- [Throughout] Notation: SID and SemanticID are used interchangeably; standardize to one form throughout.
- [Figure 3] Figure 3 caption: the diagram of the RL policy update does not label the reward scaling hyperparameter, making it hard to reproduce the exact training dynamics.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and will revise the manuscript to improve clarity and experimental reporting.
read point-by-point responses
-
Referee: [§4.2] §4.2 (QARM description): the quality-aware reward is defined using reconstruction loss and semantic similarity scores that are themselves optimized within the joint training objective; this creates a circularity risk where claimed posterior quality improvements may simply reflect better fitting to the same supervision signals rather than independent quality discrimination.
Authors: We appreciate the referee's concern about potential circularity. The reconstruction loss and semantic similarity serve as supervision to train DCIM and CMSA for semantic preservation in SID generation. QARM then employs these as reward signals within the RL policy optimization to favor high-quality SIDs. To eliminate ambiguity, we will revise §4.2 to clarify the staged training process: the supervision signals are pre-computed from the fixed encoder outputs and applied as static rewards during RL, without back-propagation through the same objectives in the posterior stage. We will also add pseudocode illustrating this separation to demonstrate that quality discrimination operates on the learned semantic metrics rather than direct re-optimization. revision: partial
-
Referee: [Table 2, §5.1] Table 2 and §5.1: the main results table reports consistent outperformance, but the experimental setup section provides no details on the exact number of runs, variance estimates, or statistical significance tests; without these, it is impossible to assess whether the reported margins over baselines are robust or could be explained by hyperparameter sensitivity.
Authors: We agree that additional statistical details are necessary to substantiate the robustness of our results. We will revise §5.1 to report that all experiments were conducted over 5 independent runs with different random seeds, include mean performance and standard deviations in Table 2, and add paired t-test p-values to confirm statistical significance of improvements over baselines. These changes will directly address concerns about hyperparameter sensitivity and variance. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces a three-part framework (DCIM for deep interest mining via reconstruction supervision, CMSA for cross-modal alignment using VLMs, and QARM for quality-aware RL rewards) to mitigate information degradation, semantic loss, and modality distortion in Semantic ID generation. No equations or steps in the abstract or described method reduce any prediction or result to its own inputs by construction, nor do they rely on self-citations, imported uniqueness theorems, or ansatzes smuggled from prior author work. The central claims rest on external experimental benchmarks and ablations rather than internal self-definition or fitted-input renaming. The derivation is self-contained against the stated limitations.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward scaling and quality thresholds
axioms (1)
- domain assumption Vision-Language Models can align non-textual modalities into a unified text-based semantic space without introducing significant distortion
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
work page 2025
- [3]
-
[4]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al . 2025. Mtgr: Industrial- scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
work page 2025
-
[6]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learning vector-quantized item representation for transferable sequential recommenders. InProceedings of the ACM Web Conference 2023. 1162–1171
work page 2023
-
[7]
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. 2023. Learning vector-quantized item representation for transferable sequential recommenders. InWWW. 1162–1171
work page 2023
-
[8]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating long semantic ids in parallel for recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 956–966
work page 2025
- [9]
- [10]
-
[11]
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. 2025. A Survey of Generative Recommendation from a Tri-Decoupled Perspective: Tokenization, Architecture, and Optimization. (2025)
work page 2025
- [12]
-
[13]
McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel
Julian J. McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel
-
[14]
Image-Based Recommendations on Styles and Substitutes. InSIGIR
-
[15]
Aleksandr V Petrov and Craig Macdonald. 2024. RecJPQ: training large-catalogue sequential recommenders. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 538–547
work page 2024
-
[16]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[17]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
work page 2023
-
[18]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Recommender Systems with Generative Retrieval. InNeurIPS
work page 2023
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Hao Wang, Wei Guo, Luankang Zhang, Jin Yao Chin, Yufei Ye, Huifeng Guo, Yong Liu, Defu Lian, Ruiming Tang, and Enhong Chen. 2025. Generative large recom- mendation models: Emerging trends in llms for recommendation. InCompanion Proceedings of the ACM on Web Conference 2025. 49–52
work page 2025
- [22]
-
[23]
Jinze Wang, Tiehua Zhang, Lu Zhang, Yang Bai, Xin Li, and Jiong Jin. 2025. HyperMAN: Hypergraph-enhanced Meta-learning Adaptive Network for Next POI Recommendation. In2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
work page 2025
- [24]
-
[25]
Bencheng Yan, Shilei Liu, Zhiyuan Zeng, Zihao Wang, Yizhen Zhang, Yujin Yuan, Langming Liu, Jiaqi Liu, Di Wang, Wenbo Su, et al. 2025. Unlocking Scaling Law in Industrial Recommendation Systems with a Three-step Paradigm based Large User Model.arXiv preprint arXiv:2502.08309(2025)
- [26]
- [27]
-
[28]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Jiayuan He, et al. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. In International Conference on Machine Learning. PMLR, 58484–58509
work page 2024
- [29]
- [30]
-
[31]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, and Ji- Rong Wen. 2024. Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation. InICDE
work page 2024
-
[33]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900(2025)
work page internal anchor Pith review arXiv 2025
-
[34]
Hao Zhou, Chengming Hu, Ye Yuan, Yufei Cui, Yili Jin, Can Chen, Haolun Wu, Dun Yuan, Li Jiang, Di Wu, et al. 2024. Large language model (llm) for telecom- munications: A comprehensive survey on principles, key techniques, and oppor- tunities.IEEE Communications Surveys & Tutorials27, 3 (2024), 1955–2005
work page 2024
-
[35]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. InCIKM
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.