Recognition: unknown
AITP: Traffic Accident Responsibility Allocation via Multimodal Large Language Models
Pith reviewed 2026-05-10 16:05 UTC · model grok-4.3
The pith
Multimodal LLMs with chain-of-thought reasoning and legal retrieval can allocate responsibility in traffic accidents at state-of-the-art levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
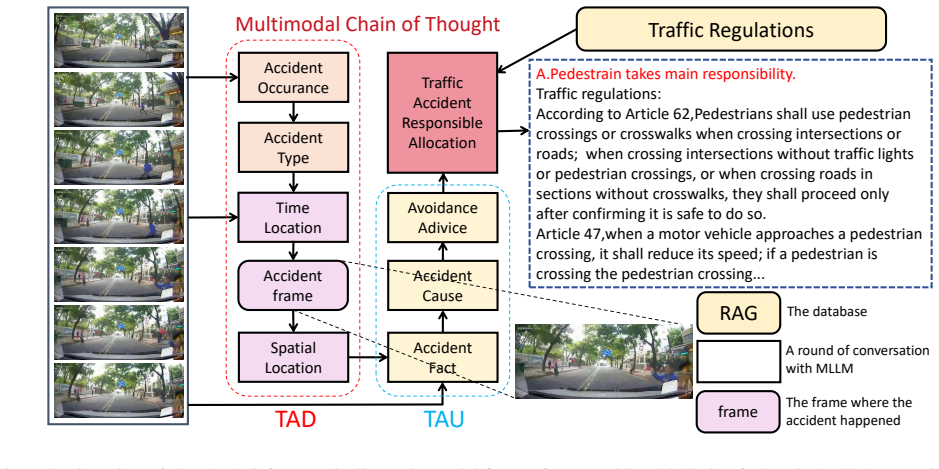
We introduce AITP, a multimodal large language model for responsibility reasoning and allocation in traffic accidents. It enhances reasoning through a Multimodal Chain-of-Thought mechanism and integrates legal knowledge via Retrieval-Augmented Generation. On the DecaTARA benchmark with 67,941 videos and 195,821 question-answer pairs across ten tasks, AITP achieves state-of-the-art performance on responsibility allocation, traffic accident detection, and traffic accident understanding.
What carries the argument
Multimodal Chain-of-Thought (MCoT) for multi-step reasoning over accident videos paired with Retrieval-Augmented Generation (RAG) to pull in relevant traffic regulations.
Load-bearing premise
Augmenting multimodal large language models with chain-of-thought and retrieval mechanisms will produce legally accurate responsibility allocations without hallucinations or errors in applying traffic rules, and that the benchmark scenarios match real-world conditions.
What would settle it
A study in which traffic law experts review allocations made by AITP on previously unseen accident videos and find systematic discrepancies with legal standards or factual causality.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable progress in Traffic Accident Detection (TAD) and Traffic Accident Understanding (TAU). However, existing studies mainly focus on describing and interpreting accident videos, leaving room for deeper causal reasoning and integration of legal knowledge. Traffic Accident Responsibility Allocation (TARA) is a more challenging task that requires multi-step reasoning grounded in traffic regulations. To address this, we introduce AITP (Artificial Intelligence Traffic Police), a multimodal large language model for responsibility reasoning and allocation. AITP enhances reasoning via a Multimodal Chain-of-Thought (MCoT) mechanism and integrates legal knowledge through Retrieval-Augmented Generation (RAG). We further present DecaTARA, a decathlon-style benchmark unifying ten interrelated traffic accident reasoning tasks with 67,941 annotated videos and 195,821 question-answer pairs. Extensive experiments show that AITP achieves state-of-the-art performance across responsibility allocation, TAD, and TAU tasks, establishing a new paradigm for reasoning-driven multimodal traffic analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AITP, a multimodal large language model for Traffic Accident Responsibility Allocation (TARA) that augments MLLMs with Multimodal Chain-of-Thought (MCoT) reasoning and Retrieval-Augmented Generation (RAG) for legal knowledge integration. It also presents the DecaTARA benchmark, a large-scale dataset unifying ten interrelated tasks with 67,941 annotated videos and 195,821 question-answer pairs. The central claim is that AITP achieves state-of-the-art performance on responsibility allocation, Traffic Accident Detection (TAD), and Traffic Accident Understanding (TAU) tasks.
Significance. If the experimental results and legal accuracy claims hold after proper validation, the work could advance multimodal reasoning in safety-critical and regulated domains such as autonomous driving and accident forensics. The scale of DecaTARA represents a potentially useful community resource for benchmarking causal and regulatory reasoning. However, the current lack of supporting details on evaluation protocols substantially reduces the assessed significance.
major comments (2)
- [Abstract] Abstract: The assertion of state-of-the-art performance on TARA, TAD, and TAU is unsupported by any description of baselines, evaluation metrics (especially for legal accuracy of responsibility allocations), statistical significance testing, or error analysis.
- [Abstract] Abstract: The core claim that MCoT+RAG produces accurate and legally compliant responsibility allocations lacks any account of the legal knowledge base, retrieval precision/recall for traffic regulations, or expert adjudication of model outputs against statutes; without this, benchmark scores on DecaTARA cannot distinguish regulatory reasoning from hallucination or pattern matching.
minor comments (1)
- The abstract refers to 'extensive experiments' without even high-level pointers to the experimental section or tables, which hinders immediate assessment.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments point by point below. We agree that the abstract is overly concise and will revise it and the main text to provide the requested details on evaluation protocols and legal knowledge validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art performance on TARA, TAD, and TAU is unsupported by any description of baselines, evaluation metrics (especially for legal accuracy of responsibility allocations), statistical significance testing, or error analysis.
Authors: We agree the abstract does not enumerate these elements. The full manuscript (Section 4 and Appendix) specifies the baselines (Video-LLaMA, LLaVA-1.5, GPT-4V, GPT-4o, and prior TARA-specific models), metrics (accuracy, F1, and a legal-compliance-augmented score for TARA), paired t-test significance results (p < 0.05), and error analysis with categorized failure cases. The DecaTARA ground-truth labels for responsibility allocation were produced by legal experts. We will revise the abstract to include a brief clause on baselines and statistical validation and will ensure the metrics paragraph in Section 4 explicitly highlights the legal-accuracy component. revision: yes
-
Referee: [Abstract] Abstract: The core claim that MCoT+RAG produces accurate and legally compliant responsibility allocations lacks any account of the legal knowledge base, retrieval precision/recall for traffic regulations, or expert adjudication of model outputs against statutes; without this, benchmark scores on DecaTARA cannot distinguish regulatory reasoning from hallucination or pattern matching.
Authors: We acknowledge the need for explicit documentation. The legal knowledge base comprises official traffic statutes and regulations from authoritative national sources, embedded via a vector store; retrieval uses top-k cosine similarity with reported precision@5 and recall@5 on a validation query set (Appendix). DecaTARA annotations were performed by a panel of traffic police officers and legal scholars, with inter-annotator agreement measured. We additionally ran a human evaluation on 500 model outputs scored by the same experts for statutory compliance, showing AITP reduces hallucinated violations relative to baselines. We will add a dedicated subsection (new Section 3.3) describing the knowledge-base construction, retrieval metrics, and expert validation protocol. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks and new dataset
full rationale
The paper introduces AITP (an MLLM augmented with MCoT and RAG) and the DecaTARA benchmark, then reports empirical SOTA results on responsibility allocation, TAD, and TAU tasks. No derivation chain, equations, or fitted parameters are presented that reduce to the inputs by construction. Performance claims rely on comparisons against external baselines on the newly introduced dataset rather than self-referential fitting or self-citation load-bearing arguments. The central claims are therefore self-contained against the provided benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal LLMs augmented with chain-of-thought and retrieval can perform reliable multi-step causal and legal reasoning on video data
- domain assumption The DecaTARA benchmark accurately reflects real-world traffic regulations and accident scenarios
invented entities (2)
-
AITP model
no independent evidence
-
DecaTARA benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Viena: A driving anticipation dataset
Mohammad Sadegh Aliakbarian, Fatemeh Sadat Saleh, Mathieu Salzmann, Basura Fernando, Lars Petersson, and Lars Andersson. Viena: A driving anticipation dataset. InAsian Conference on Computer Vision, pages 449–466. Springer, 2018. 3
2018
-
[2]
Edmond Awad, Sydney Levine, Max Kleiman-Weiner, So- han Dsouza, Joshua B Tenenbaum, Azim Shariff, Jean- Franc ¸ois Bonnefon, and Iyad Rahwan. Blaming humans in autonomous vehicle accidents: Shared responsibility across levels of automation.arXiv preprint arXiv:1803.07170,
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Uncertainty-based traffic accident anticipation with spatio-temporal relational learn- ing
Wentao Bao, Qi Yu, and Yu Kong. Uncertainty-based traffic accident anticipation with spatio-temporal relational learn- ing. InProceedings of the 28th ACM International Confer- ence on Multimedia, pages 2682–2690, 2020. 3
2020
-
[5]
Tads: a novel dataset for road traffic ac- cident detection from a surveillance perspective.Journal of Supercomputing, 80(18), 2024
Yachuang Chai, Jianwu Fang, Haoquan Liang, and Wushouer Silamu. Tads: a novel dataset for road traffic ac- cident detection from a surveillance perspective.Journal of Supercomputing, 80(18), 2024. 3
2024
-
[6]
Dada-2000: Can driving accident be pre- dicted by driver attentionƒ analyzed by a benchmark
Jianwu Fang, Dingxin Yan, Jiahuan Qiao, Jianru Xue, He Wang, and Sen Li. Dada-2000: Can driving accident be pre- dicted by driver attentionƒ analyzed by a benchmark. In2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 4303–4309. IEEE, 2019. 3
2000
-
[7]
Dada: Driver attention prediction in driving accident scenarios.IEEE transactions on intelligent trans- portation systems, 23(6):4959–4971, 2021
Jianwu Fang, Dingxin Yan, Jiahuan Qiao, Jianru Xue, and Hongkai Yu. Dada: Driver attention prediction in driving accident scenarios.IEEE transactions on intelligent trans- portation systems, 23(6):4959–4971, 2021. 3
2021
-
[8]
Traffic accident detection via self-supervised consis- tency learning in driving scenarios.IEEE Transactions on Intelligent Transportation Systems, 23(7):9601–9614, 2022
Jianwu Fang, Jiahuan Qiao, Jie Bai, Hongkai Yu, and Jianru Xue. Traffic accident detection via self-supervised consis- tency learning in driving scenarios.IEEE Transactions on Intelligent Transportation Systems, 23(7):9601–9614, 2022. 1
2022
-
[9]
Abductive ego-view accident video understanding for safe driving per- ception
Jianwu Fang, Lei-lei Li, Junfei Zhou, Junbin Xiao, Hongkai Yu, Chen Lv, Jianru Xue, and Tat-Seng Chua. Abductive ego-view accident video understanding for safe driving per- ception. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22030– 22040, 2024. 1, 3, 4
2024
-
[10]
Vision transformers for road accident detection from dashboard cameras
Feten Hajri and Hajer Fradi. Vision transformers for road accident detection from dashboard cameras. In2022 18th IEEE international conference on advanced video and signal based surveillance (AVSS), pages 1–8. IEEE, 2022. 1
2022
-
[11]
Towards anomaly detection in dashcam videos
Sanjay Haresh, Sateesh Kumar, M Zeeshan Zia, and Quoc- Huy Tran. Towards anomaly detection in dashcam videos. In 2020 IEEE Intelligent Vehicles Symposium (IV), pages 1407–
2020
-
[12]
Adapt: Action-aware driving cap- tion transformer
Bu Jin and Haotian Liu. Adapt: Action-aware driving cap- tion transformer. InCAAI International Conference on Arti- ficial Intelligence, pages 473–477. Springer, 2023. 1
2023
-
[13]
Crash to not crash: Learn to identify dangerous vehicles using a simulator
Hoon Kim, Kangwook Lee, Gyeongjo Hwang, and Changho Suh. Crash to not crash: Learn to identify dangerous vehicles using a simulator. InProceedings of the AAAI Conference on Artificial Intelligence, pages 978–985, 2019. 3
2019
-
[14]
Textual explanations for self-driving ve- hicles.Proceedings of the European Conference on Com- puter Vision (ECCV), 2018
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving ve- hicles.Proceedings of the European Conference on Com- puter Vision (ECCV), 2018. 4
2018
-
[15]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020. 2
2020
-
[16]
Lei-lei Li, Jianwu Fang, Junbin Xiao, Shanmin Pang, Hongkai Yu, Chen Lv, Jianru Xue, and Tat-Seng Chua. Causal-entity reflected egocentric traffic accident video syn- thesis.arXiv preprint arXiv:2506.23263, 2025. 3
-
[17]
Miao Li, Wenhao Ding, Haohong Lin, Yiqi Lyu, Yihang Yao, Yuyou Zhang, and Ding Zhao. Crashagent: Crash sce- nario generation via multi-modal reasoning.arXiv preprint arXiv:2505.18341, 2025. 3
-
[18]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 6
2004
-
[19]
A simulation-based frame- work for urban traffic accident detection
Haohan Luo and Feng Wang. A simulation-based frame- work for urban traffic accident detection. InICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 3
2023
-
[20]
Localizing anomalies from weakly-labeled videos.IEEE transactions on image processing, 30:4505– 4515, 2021
Hui Lv, Chuanwei Zhou, Zhen Cui, Chunyan Xu, Yong Li, and Jian Yang. Localizing anomalies from weakly-labeled videos.IEEE transactions on image processing, 30:4505– 4515, 2021. 3
2021
-
[21]
Dolphins: Multimodal language model for driving
Yingzi Ma, Yulong Cao, Jiachen Sun, Marco Pavone, and Chaowei Xiao. Dolphins: Multimodal language model for driving. InEuropean Conference on Computer Vision, pages 403–420. Springer, 2024. 1
2024
-
[22]
Deep learning based traffic accident detection in smart transportation: a ma- chine vision-based approach
Mark Melegrito, Ryan Reyes, Ryan Tejada, John Edgar Su- alog Anthony, Alvin Sarraga Alon, Ritchelie P Delmo, Meriam A Enaldo, and Abrahem P Anqui. Deep learning based traffic accident detection in smart transportation: a ma- chine vision-based approach. In2024 4th International Con- ference on Applied Artificial Intelligence (ICAPAI), pages 1–
-
[23]
Nexar dashcam collision prediction dataset and challenge
Daniel Moura, Shizhan Zhu, and Orly Zvitia. Nexar dashcam collision prediction dataset and challenge. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2583–2591, 2025. 1
2025
-
[24]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[25]
Roadsocial: A diverse videoqa dataset and benchmark for road event understanding from so- cial video narratives
Chirag Parikh, Deepti Rawat, Tathagata Ghosh, Ravi Ki- ran Sarvadevabhatla, et al. Roadsocial: A diverse videoqa dataset and benchmark for road event understanding from so- cial video narratives. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19002–19011,
-
[26]
A call for clarity in reporting BLEU scores.arXiv preprint arXiv:1804.08771,
Matt Post. A call for clarity in reporting bleu scores.arXiv preprint arXiv:1804.08771, 2018. 6
-
[27]
Detection of collision-prone vehicle be- havior at intersections using siamese interaction lstm.IEEE transactions on intelligent transportation systems, 23(4): 3137–3147, 2020
Debaditya Roy, Tetsuhiro Ishizaka, C Krishna Mohan, and Atsushi Fukuda. Detection of collision-prone vehicle be- havior at intersections using siamese interaction lstm.IEEE transactions on intelligent transportation systems, 23(4): 3137–3147, 2020. 1
2020
-
[28]
Cadp: A novel dataset for cctv traffic camera based accident analysis
Ankit Parag Shah, Jean-Bapstite Lamare, Tuan Nguyen-Anh, and Alexander Hauptmann. Cadp: A novel dataset for cctv traffic camera based accident analysis. In2018 15th IEEE In- ternational Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 1–9. IEEE, 2018. 3
2018
-
[29]
Zihao Sheng, Zilin Huang, Yen-Jung Chen, Yansong Qu, Yuhao Luo, Yue Leng, and Sikai Chen. Safeplug: Empow- ering multimodal llms with pixel-level insight and temporal grounding for traffic accident understanding.arXiv preprint arXiv:2508.06763, 2025. 1, 3
-
[30]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chen- zhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025. 7
work page internal anchor Pith review arXiv 2025
-
[32]
Detection of road ac- cidents using synthetically generated multi-perspective acci- dent videos.IEEE Transactions on Intelligent Transporta- tion Systems, 24(2):1926–1935, 2022
Thakare Kamalakar Vijay, Debi Prosad Dogra, Heeseung Choi, Gipyo Nam, and Ig-Jae Kim. Detection of road ac- cidents using synthetically generated multi-perspective acci- dent videos.IEEE Transactions on Intelligent Transporta- tion Systems, 24(2):1926–1935, 2022. 3
1926
-
[33]
Deepaccident: A motion and accident prediction bench- mark for v2x autonomous driving
Tianqi Wang, Sukmin Kim, Ji Wenxuan, Enze Xie, Chongjian Ge, Junsong Chen, Zhenguo Li, and Ping Luo. Deepaccident: A motion and accident prediction bench- mark for v2x autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, pages 5599– 5606, 2024. 3
2024
-
[34]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 2
2022
-
[36]
Global status report on road safety 2023
World Health Organization. Global status report on road safety 2023. Technical report, World Health Organization, Geneva, Switzerland, 2023. 1
2023
-
[37]
Echotraffic: Enhancing traffic anomaly understanding with audio-visual insights
Zhenghao Xing, Hao Chen, Binzhu Xie, Jiaqi Xu, Ziyu Guo, Xuemiao Xu, Jianye Hao, Chi-Wing Fu, Xiaowei Hu, and Pheng-Ann Heng. Echotraffic: Enhancing traffic anomaly understanding with audio-visual insights. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19098–19108, 2025. 1, 3, 4
2025
-
[38]
Sutd-trafficqa: A question answering benchmark and an efficient network for video rea- soning over traffic events
Li Xu, He Huang, and Jun Liu. Sutd-trafficqa: A question answering benchmark and an efficient network for video rea- soning over traffic events. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9878–9888, 2021. 1, 3
2021
-
[39]
Tad: A large-scale benchmark for traffic accidents detection from video surveillance.IEEE Access, 2024
Yajun Xu, Huan Hu, Chuwen Huang, Yibing Nan, Yuyao Liu, Kai Wang, Zhaoxiang Liu, and Shiguo Lian. Tad: A large-scale benchmark for traffic accidents detection from video surveillance.IEEE Access, 2024. 3
2024
-
[40]
Unsupervised traffic accident detection in first-person videos
Yu Yao, Mingze Xu, Yuchen Wang, David J Crandall, and Ella M Atkins. Unsupervised traffic accident detection in first-person videos. In2019 IEEE/RSJ International confer- ence on intelligent robots and systems (IROS), pages 273–
-
[41]
Dota: Unsupervised de- tection of traffic anomaly in driving videos.IEEE transac- tions on pattern analysis and machine intelligence, 45(1): 444–459, 2022
Yu Yao, Xizi Wang, Mingze Xu, Zelin Pu, Yuchen Wang, Ella Atkins, and David J Crandall. Dota: Unsupervised de- tection of traffic anomaly in driving videos.IEEE transac- tions on pattern analysis and machine intelligence, 45(1): 444–459, 2022. 3
2022
-
[42]
Traffic accident bench- mark for causality recognition
Tackgeun You and Bohyung Han. Traffic accident bench- mark for causality recognition. InEuropean Conference on Computer Vision, pages 540–556. Springer, 2020. 3
2020
-
[43]
arXiv preprint arXiv:2402.10828 (2024)
Jianhao Yuan, Shuyang Sun, Daniel Omeiza, Bo Zhao, Paul Newman, Lars Kunze, and Matthew Gadd. Rag-driver: Gen- eralisable driving explanations with retrieval-augmented in- context learning in multi-modal large language model.arXiv preprint arXiv:2402.10828, 2024. 1
-
[44]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Wein- berger, and Yoav Artzi. Bertscore: Evaluating text genera- tion with bert.arXiv preprint arXiv:1904.09675, 2019. 6
work page internal anchor Pith review arXiv 1904
-
[45]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of- thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[46]
Mover- score: Text generation evaluating with contextualized embeddings and earth mover distance
Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M Meyer, and Steffen Eger. Moverscore: Text generation eval- uating with contextualized embeddings and earth mover dis- tance.arXiv preprint arXiv:1909.02622, 2019. 6
-
[47]
Swift:a scal- able lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yun- lin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scal- able lightweight infrastructure for fine-tuning, 2024. 5
2024
-
[48]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. 6
2023
-
[49]
TAU-106k: A new dataset for comprehen- sive understanding of traffic accident
Yixuan Zhou, Long Bai, Sijia Cai, Bing Deng, Xing Xu, and Heng Tao Shen. TAU-106k: A new dataset for comprehen- sive understanding of traffic accident. InThe Thirteenth In- ternational Conference on Learning Representations, 2025. 1, 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.