Recognition: unknown
AttentionBender: Manipulating Cross-Attention in Video Diffusion Transformers as a Creative Probe
Pith reviewed 2026-05-09 22:41 UTC · model grok-4.3
The pith
AttentionBender applies 2D transforms to cross-attention maps in video diffusion transformers, producing distributed distortions and glitch aesthetics that reveal entangled attention mechanisms while serving as both an XAI probe and creative tool.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results suggest that cross-attention is highly entangled: targeted manipulations often resist clean, localized control, producing distributed distortions and glitch aesthetics over linear edits.
Load-bearing premise
That applying 2D geometric transforms to attention maps isolates the effect of cross-attention on generation without introducing unrelated artifacts from the manipulation process itself.
Figures




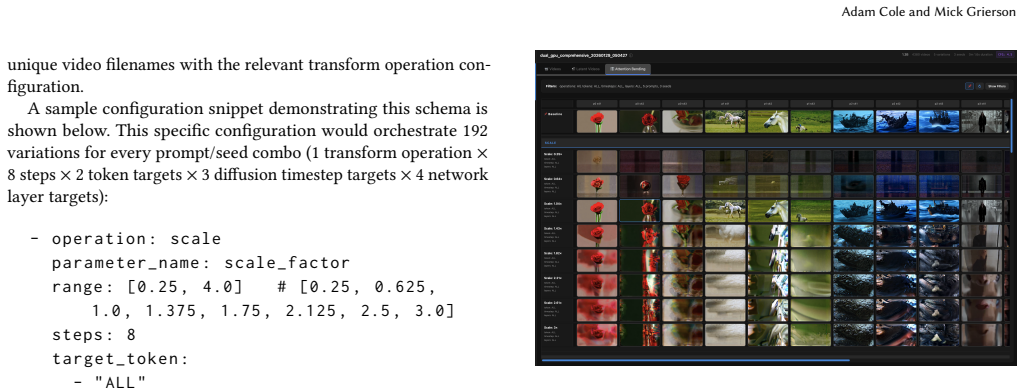
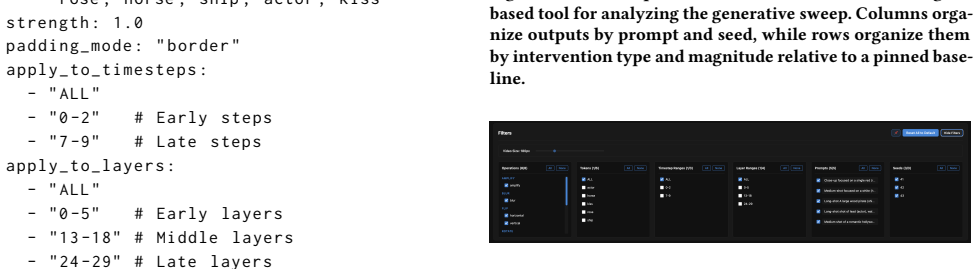











read the original abstract
We present AttentionBender, a tool that manipulates cross-attention in Video Diffusion Transformers to help artists probe the internal mechanics of black-box video generation. While generative outputs are increasingly realistic, prompt-only control limits artists' ability to build intuition for the model's material process or to work beyond its default tendencies. Using an autobiographical research-through-design approach, we built on Network Bending to design AttentionBender, which applies 2D transforms (rotation, scaling, translation, etc.) to cross-attention maps to modulate generation. We assess AttentionBender by visualizing 4,500+ video generations across prompts, operations, and layer targets. Our results suggest that cross-attention is highly entangled: targeted manipulations often resist clean, localized control, producing distributed distortions and glitch aesthetics over linear edits. AttentionBender contributes a tool that functions both as an Explainable AI style probe of transformer attention mechanisms, and as a creative technique for producing novel aesthetics beyond the model's learned representational space.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: empirical observations from tool application are independent of inputs
full rationale
The paper's derivation chain consists of designing AttentionBender by applying 2D geometric transforms to cross-attention maps, then reporting observations from 4,500+ generated videos. No equations, fitted parameters, or predictions appear; the claim of entanglement follows directly from visualized distributed distortions rather than reducing to self-definition, self-citation chains, or renamed known results. The approach is self-contained as research-through-design with no load-bearing steps that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abuzuraiq and Philippe Pasquier
Ahmed M. Abuzuraiq and Philippe Pasquier. 2025. Explainability-in-Action: Enabling Expressive Manipulation and Tacit Understanding by Bending Diffusion Models in ComfyUI. arXiv:2508.07183 [cs] doi:10.48550/arXiv.2508.07183
-
[2]
Philip E. Agre. 1997. Toward a Critical Technical Practice: Lessons Learned in Trying to Reform AI. InSocial Science, Technical Systems, and Cooperative Work. Psychology Press
1997
-
[3]
Giacomo Aldegheri, Alina Rogalska, Ahmed Youssef, and Eugenia Iofinova
-
[4]
arXiv:2310.04816 [cs] doi:10.48550/arXiv.2310.04816
Hacking Generative Models with Differentiable Network Bending. arXiv:2310.04816 [cs] doi:10.48550/arXiv.2310.04816
-
[5]
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. 2021. ViViT: A Video Vision Transformer. arXiv:2103.15691 [cs] doi:10.48550/arXiv.2103.15691
-
[6]
Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Ben- netot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, Raja Chatila, and Francisco Herrera. 2019. Ex- plainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. arXiv:1910...
work page internal anchor Pith review doi:10.48550/arxiv 2019
-
[7]
Jordan Belson. 1967. Samadhi
1967
-
[8]
Stan Brakhage. 1963. Mothlight
1963
-
[9]
Terrance Broad. 2024. Using Generative AI as an Artistic Material: A Hacker’s Guide.Proceedings of Explainable AI for the Arts Workshop 2024 (XAIxArts 2024) 1, 1 (2024)
2024
-
[10]
Terence Broad, Frederic Fol Leymarie, and Mick Grierson. 2021. Network Bending: Expressive Manipulation of Deep Generative Models. InArtificial Intelligence in Music, Sound, Art and Design: 10th International Conference, EvoMUSART 2021, Held as Part of EvoStar 2021, Virtual Event, April 7–9, 2021, Proceedings. Springer- Verlag, Berlin, Heidelberg, 20–36. ...
-
[11]
Nick Bryan-Kinns, Berker Banar, Corey Ford, Courtney N. Reed, Yixiao Zhang, Simon Colton, and Jack Armitage. 2023. Exploring XAI for the Arts: Explaining Latent Space in Generative Music. arXiv:2308.05496 [cs] doi:10.48550/arXiv.2308. 05496
-
[12]
Nick Bryan-Kinns, Corey Ford, Alan Chamberlain, Steven David Benford, Helen Kennedy, Zijin Li, Wu Qiong, Gus G. Xia, and Jeba Rezwana. 2023. Explainable AI for the Arts: XAIxArts. InProceedings of the 15th Conference on Creativity and Cognition (C&C ’23). Association for Computing Machinery, New York, NY, USA, 1–7. doi:10.1145/3591196.3593517
-
[13]
Nick Bryan-Kinns, Shuoyang Jasper Zheng, Francisco Castro, Makayla Lewis, Jia-Rey Chang, Gabriel Vigliensoni, Terence Broad, Michael Clemens, and Elizabeth Wilson. 2025. XAIxArts Manifesto: Explainable AI for the Arts. arXiv:2502.21220 [cs] doi:10.1145/3706599.3716227
-
[14]
Jenna Burrell. 2016. How the Machine ‘Thinks’: Understanding Opacity in Machine Learning Algorithms.Big Data & Society3(1) (2016). doi:10.1177/ 2053951715622512
2016
-
[15]
Antoine Caillon and Philippe Esling. 2022. RAVE: A Variational Autoencoder for Fast and High-Quality Neural Audio Synthesis. InInternational Conference on Learning Representations, Vol. 10
2022
-
[16]
David Casacuberta and Ariel Guersenzvaig. 2025. Disembodied Creativity in Generative AI: Prima Facie Challenges and Limitations of Prompting in Creative Practice.Frontiers in Artificial Intelligence8 (Aug. 2025). doi:10.3389/frai.2025. 1651354
-
[17]
Eva Cetinic and James She. 2022. Understanding and Creating Art with AI: Review and Outlook.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)(2022)
2022
-
[18]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. 2023. Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffu- sion Models. arXiv:2301.13826 [cs] doi:10.48550/arXiv.2301.13826
-
[19]
Hila Chefer, Shir Gur, and Lior Wolf. 2021. Transformer Interpretability Beyond Attention Visualization. arXiv:2012.09838 [cs] doi:10.48550/arXiv.2012.09838
-
[20]
2006.Handmade Electronic Music: The Art of Hardware Hacking
Nicolas Collins. 2006.Handmade Electronic Music: The Art of Hardware Hacking. Taylor & Francis
2006
-
[21]
Comfy-Org. 2023. ComfyUI: The Most Powerful and Modular Stable Diffusion GUI and Backend. https://github.com/comfy-org/comfyui
2023
-
[22]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion Models Beat GANs on Image Synthesis. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., 8780–8794
2021
-
[23]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations
2020
-
[24]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
2020
-
[25]
Luke Dzwonczyk, Carmine Emanuele Cella, and David Ban. 2024. Network Bending of Diffusion Models for Audio-Visual Generation. arXiv:2406.19589 [cs] doi:10.48550/arXiv.2406.19589
-
[26]
Luke Dzwonczyk, Carmine-Emanuele Cella, and David Ban. 2025. Generating Music Reactive Videos by Applying Network Bending to Stable Diffusion.Journal of the Audio Engineering Society73, 6 (2025), 388–398. doi:10.17743/jaes.2022.0210
-
[27]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. InProceedings of the 41st International Conference on Machine Learning...
2024
-
[28]
2025.AI in the Screen Sector: Perspectives and Paths Forward
Angus Finney, Brian Tarran, and Rishi Coupland. 2025.AI in the Screen Sector: Perspectives and Paths Forward. Technical Report. CoSTAR Foresight Lab. doi:10. 5281/zenodo.15601301
2025
-
[29]
2005.Circuit-Bending: Build Your Own Alien Instruments
Reed Ghazala. 2005.Circuit-Bending: Build Your Own Alien Instruments. Wiley
2005
-
[30]
Drew Hemment, Dave Murray-Rust, Vaishak Belle, Ruth Aylett, Matjaz Vidmar, and Frank Broz. 2024. Experiential AI: Between Arts and Explainable AI.Leonardo 57, 3 (June 2024), 298–306. doi:10.1162/leon_a_02524
-
[31]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-Prompt Image Editing with Cross Attention Control. arXiv:2208.01626 [cs] doi:10.48550/arXiv.2208.01626
work page internal anchor Pith review doi:10.48550/arxiv.2208.01626 2022
-
[32]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models (DDPM). InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., 6840–6851
2020
-
[33]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. 2022. Video Diffusion Models. arXiv:2204.03458 [cs] doi:10.48550/arXiv.2204.03458
work page internal anchor Pith review doi:10.48550/arxiv.2204.03458 2022
-
[34]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations
2021
-
[35]
Tom Hume. 2025. Meet Flow: AI-powered Filmmaking with Veo 3
2025
-
[36]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A Style-Based Generator Archi- tecture for Generative Adversarial Networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4396–4405. doi:10.1109/CVPR. 2019.00453
-
[37]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and Improving the Image Quality of StyleGAN. arXiv:1912.04958 [cs, eess, stat] doi:10.48550/arXiv.1912.04958
-
[38]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. 2013. Auto-Encoding Variational Bayes. InInternational Conference on Learning Representations
2013
-
[39]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.03603 2025
-
[40]
Vivian Liu and Lydia B Chilton. 2022. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, 1–23. doi:10.1145/3491102.3501825
-
[41]
Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. 2023. VDT: General-purpose Video Diffusion Transformers via Mask Modeling. arXiv:2305.13311 [cs] doi:10.48550/arXiv.2305.13311
-
[42]
Yao Lyu, He Zhang, Shuo Niu, and Jie Cai. 2024. A Preliminary Exploration of YouTubers’ Use of Generative-AI in Content Creation. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’24). Association for Computing Machinery, New York, NY, USA, 1–7. doi:10.1145/3613905.3651057
-
[43]
Daniel Manz and Mick Grierson. 2025. Brave: Designing an Embedded Network- Bending Instrument, Manifesting Output Diversity in Neural Audio Systems. In International Conference on Computational Creativity
2025
-
[44]
Louis McCallum and Matthew Yee-King. 2020. Network Bending Neural Vocoders. In4th Workshop on Machine Learning for Creativity and Design at NeurIPS 2020, Vancouver, Canada.Goldsmiths, University of London
2020
-
[45]
2011.The Glitch Moment(Um)
Rosa Menkman. 2011.The Glitch Moment(Um). Institute of Network Cultures
2011
-
[46]
Melkamu Mersha, Khang Lam, Joseph Wood, Ali AlShami, and Jugal Kalita
-
[47]
Explainable Artificial Intelligence: A Survey of Needs, Techniques, Ap- plications, and Future Direction.Neurocomputing599 (Sept. 2024), 128111. arXiv:2409.00265 [cs] doi:10.1016/j.neucom.2024.128111
-
[48]
Carman Neustaedter and Phoebe Sengers. 2012. Autobiographical Design in HCI Research: Designing and Learning through Use-It-Yourself. InProceedings of the Designing Interactive Systems Conference (DIS ’12). Association for Computing Machinery, New York, NY, USA, 514–523. doi:10.1145/2317956.2318034
-
[49]
OpenAI. [n. d.]. Video Generation Models as World Simulators | OpenAI
-
[50]
OpenAI. 2024. Sora (Blogpost). https://openai.com/index/sora/
2024
-
[51]
OpenAI. 2025. Sora 2 Is Here
2025
-
[52]
Jonas Oppenlaender, Rhema Linder, and Johanna Silvennoinen. 2025. Prompting AI Art: An Investigation into the Creative Skill of Prompt Engineering.Interna- tional Journal of Human–Computer Interaction41, 16 (Aug. 2025), 10207–10229. doi:10.1080/10447318.2024.2431761
-
[53]
Nam June Paik. 1965. Magnet TV
1965
-
[54]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Paris, France, 4172–4182. doi:10.1109/ICCV51070.2023.00387
-
[55]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers (Preprint). InProceedings of the IEEE/CVF International Conference on Computer Vision. 4195–4205
2023
-
[56]
Xiangyu Peng, Zangwei Zheng, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, Wenjun Li, Yuhui Wang, Anbang Ye, Gang Ren, Qianran Ma, Wanying Liang, Xiang Lian, Xiwen Wu, Yuting Zhong, Zhuangyan Li, Chaoyu Gong, Guojun Lei, Leijun Cheng, Limin Zhang, Minghao Li, Ruijie Zhang, Silan Hu, Shijie Huang, Xiaokang Wang, Yu...
-
[57]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision (CLIP). InProceedings of the 38th Interna- tional Conference on Machine Learning. PMLR, 8748–8763
2021
-
[58]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683 doi:10.48550/arXiv.1910.10683
work page internal anchor Pith review doi:10.48550/arxiv.1910.10683 2023
-
[59]
Nina Rajcic, Maria Teresa Llano Rodriguez, and Jon McCormack. 2024. Towards a Diffractive Analysis of Prompt-Based Generative AI. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3613904.3641971
- [60]
-
[61]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models (Stable Diffusion). InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695
2022
-
[62]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Nassir Navab, Joachim Horneg- ger, William M. Wells, and Alejandro F. Frangi (Eds.). Springer International Publishing, Cham, 234–241. doi:10.1007/978-3-319-2...
-
[63]
Runway. 2025. Runway Research | Introducing Runway Gen-4.5
2025
-
[64]
Johannes Schneider. 2024. Explainable Generative AI (GenXAI): A Survey, Con- ceptualization, and Research Agenda.Artificial Intelligence Review57, 11 (Sept. 2024), 289. doi:10.1007/s10462-024-10916-x
-
[65]
Renee Shelby, Shalaleh Rismani, and Negar Rostamzadeh. 2024. Generative AI in Creative Practice: ML-Artist Folk Theories of T2I Use, Harm, and Harm- Reduction. InProceedings of the 2024 CHI Conference on Human Factors in Com- puting Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–17. doi:10.1145/3613904.3642461
-
[66]
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. 2022. Make-A-Video: Text-to-Video Generation without Text- Video Data. InThe Eleventh International Conference on Learning Representations
2022
-
[67]
Adams Sitney
P. Adams Sitney. 2002.Visionary Film: The American A vant-garde, 1943-2000. Oxford University Press
2002
- [68]
-
[69]
Maddalena Torricelli, Mauro Martino, Andrea Baronchelli, and Luca Maria Aiello. 2024. The Role of Interface Design on Prompt-mediated Creativity in Generative AI. InProceedings of the 16th ACM Web Science Conference (WEB- SCI ’24). Association for Computing Machinery, New York, NY, USA, 235–240. doi:10.1145/3614419.3644000
-
[70]
Luke Tredinnick and Claire Laybats. 2023. Black-Box Creativity and Generative Artifical Intelligence.Business Information Review40, 3 (Sept. 2023), 98–102. doi:10.1177/02663821231195131
-
[71]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc
2017
-
[72]
WanTeam, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Ti...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20314 2025
-
[73]
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. 2024. Diffusion Models: A Comprehensive Survey of Methods and Applications. arXiv:2209.00796 [cs] doi:10.48550/arXiv.2209.00796
-
[74]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Xiaotao Gu, Yuxuan Zhang, Weihan Wang, Yean Cheng, Ting Liu, Bin Xu, Yuxiao Dong, and Jie Tang. 2024. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. arXiv:2408.06072 [cs] doi:10.48550/arXiv.2408.06072
work page internal anchor Pith review doi:10.48550/arxiv.2408.06072 2024
-
[75]
Shamim Yazdani, Akansha Singh, Nripsuta Saxena, Zichong Wang, Avash Pa- likhe, Deng Pan, Umapada Pal, Jie Yang, and Wenbin Zhang. 2025. Generative AI in Depth: A Survey of Recent Advances, Model Variants, and Real-World Applications. arXiv:2510.21887 [cs] doi:10.48550/arXiv.2510.21887
-
[76]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. arXiv:2308.06721 [cs] doi:10.48550/arXiv.2308.06721
work page internal anchor Pith review doi:10.48550/arxiv.2308.06721 2023
-
[77]
1970.Expanded Cinema
Gene Youngblood. 1970.Expanded Cinema. Dutton
1970
-
[78]
Zamfirescu-Pereira, Richmond Y
J.D. Zamfirescu-Pereira, Richmond Y. Wong, Bjoern Hartmann, and Qian Yang
-
[79]
InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23)
Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–21. doi:10.1145/3544548.3581388
-
[80]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding Conditional Control to Text-to-Image Diffusion Models. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 3836–3847
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.