Recognition: unknown
Thinking Like a Botanist: Challenging Multimodal Language Models with Intent-Driven Chain-of-Inquiry
Pith reviewed 2026-05-10 00:15 UTC · model grok-4.3
The pith
Structured chains of inquiry help multimodal models diagnose plant diseases more accurately and with fewer hallucinations than single-turn answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize a Chain of Inquiry framework modeling diagnostic trajectories as ordered question-answer sequences conditioned on grounded visual cues and explicit epistemic intent. Evaluations on top-tier Multimodal Large Language Models reveal that while they describe visual symptoms adequately, they struggle with safe clinical reasoning and accurate diagnosis. Importantly, structured question-guided inquiry significantly improves diagnostic correctness, reduces hallucination, and increases reasoning efficiency.
What carries the argument
The Chain of Inquiry framework, which turns botanical diagnosis into ordered sequences of questions and answers driven by visual grounding and explicit diagnostic intent.
If this is right
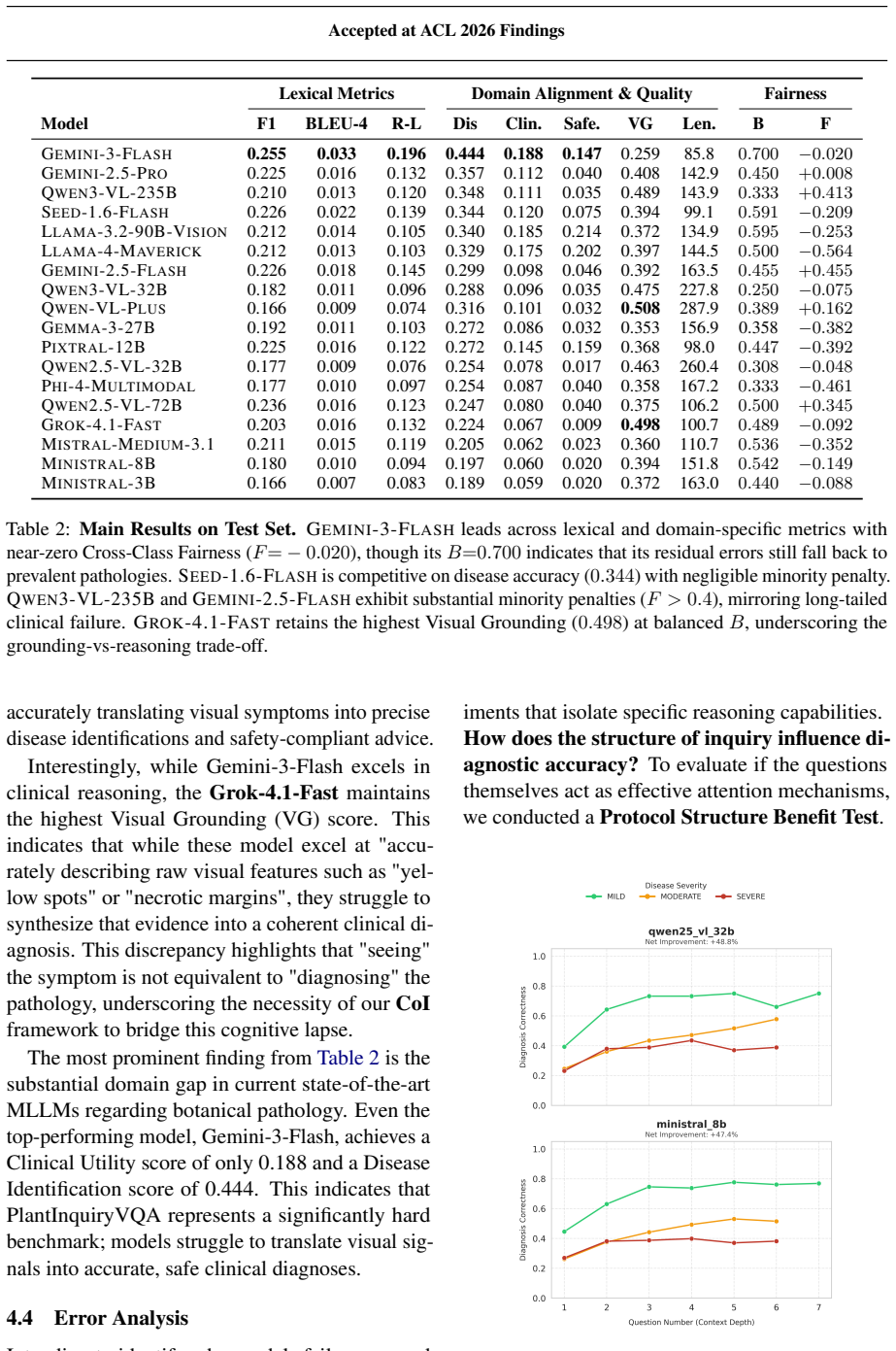
- Multimodal models reach higher diagnostic accuracy when they follow intent-driven question sequences rather than producing direct answers.
- Hallucinations about disease identity, severity, and treatment decline when reasoning is constrained by the Chain of Inquiry.
- Reasoning becomes more efficient, converging on a correct diagnosis in fewer steps under structured inquiry.
- The benchmark supports development of diagnostic agents that reason like expert botanists instead of functioning as static classifiers.
Where Pith is reading between the lines
- The same inquiry-chain structure could be tested in other image-based diagnostic domains such as medical radiology or skin lesion analysis.
- Models might be trained to generate their own inquiry chains from an initial image rather than receiving them from an external template.
- The visual grounding labels in the dataset could be used to create training signals that improve how future models link specific image regions to diagnostic questions.
Load-bearing premise
The expert-curated dataset, visual grounding annotations, and Chain of Inquiry templates accurately capture how real botanists diagnose plant diseases from images.
What would settle it
A direct comparison in which practicing botanists diagnose the same leaf images using their own adaptive questioning process, with results measured against the model's Chain of Inquiry outputs for accuracy and number of steps required.
Figures













read the original abstract
Vision evaluations are typically done through multi-step processes. In most contemporary fields, experts analyze images using structured, evidence-based adaptive questioning. In plant pathology, botanists inspect leaf images, identify visual cues, infer diagnostic intent, and probe further with targeted questions that adapt to species, symptoms, and severity. This structured probing is crucial for accurate disease diagnosis and treatment formulation. Yet current vision-language models are evaluated on single-turn question answering. To address this gap, we introduce PlantInquiryVQA, a benchmark for studying multi-step, intent-driven visual reasoning in botanical diagnosis. We formalize a Chain of Inquiry framework modeling diagnostic trajectories as ordered question-answer sequences conditioned on grounded visual cues and explicit epistemic intent. We release a dataset of 24,950 expert-curated plant images and 138,068 question-answer pairs annotated with visual grounding, severity labels, and domain-specific reasoning templates. Evaluations on top-tier Multimodal Large Language Models reveal that while they describe visual symptoms adequately, they struggle with safe clinical reasoning and accurate diagnosis. Importantly, structured question-guided inquiry significantly improves diagnostic correctness, reduces hallucination, and increases reasoning efficiency. We hope PlantInquiryVQA serves as a foundational benchmark in advancing research to train diagnostic agents to reason like expert botanists rather than static classifiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlantInquiryVQA, a benchmark for multi-step intent-driven visual reasoning in botanical disease diagnosis, comprising 24,950 expert-curated plant images and 138,068 QA pairs annotated with visual grounding, severity labels, and domain-specific reasoning templates. It formalizes a Chain of Inquiry framework that models diagnostic trajectories as ordered QA sequences conditioned on grounded cues and epistemic intent. Evaluations on top-tier MLLMs indicate adequate visual symptom description but struggles with safe clinical reasoning and diagnosis; the key result is that structured question-guided inquiry improves diagnostic correctness, reduces hallucination, and increases reasoning efficiency.
Significance. If the central results hold after addressing validation gaps, the work would be significant for shifting MLLM evaluation from single-turn QA toward adaptive, intent-driven reasoning in specialized domains. The public release of the large-scale dataset with grounding annotations and templates is a clear strength that enables reproducibility and follow-on research in visual diagnostic agents.
major comments (3)
- [§3] §3 (Chain of Inquiry framework): The claim that structured inquiry 'significantly improves diagnostic correctness' and enables models to 'reason like expert botanists' rests on the unvalidated assumption that the expert-curated framework and annotations faithfully capture real botanist diagnostic processes and adaptive probing. No inter-expert agreement metrics, comparison to observed clinical trajectories, or external botanist validation studies are described; without this, the reported gains may reflect an artificial prompting scaffold rather than generalizable intent modeling.
- [Evaluations] Evaluations section: The abstract and results claim significant improvements in correctness, hallucination reduction, and efficiency, yet no specific quantitative metrics (e.g., accuracy deltas, hallucination rates), statistical tests, control conditions (standard CoT vs. Chain of Inquiry), or error analysis tables are provided to support verification. This absence makes it impossible to assess effect sizes or rule out confounds in the MLLM comparisons.
- [Dataset construction] Dataset construction (likely §4): Details on how the 138,068 QA pairs were derived from the 24,950 images—including expert curation protocols, quality control, and how visual grounding/severity labels were assigned—are insufficient to evaluate benchmark reliability and potential annotation biases.
minor comments (2)
- [Abstract] Abstract: Names of the 'top-tier' MLLMs evaluated and key numerical results are omitted, reducing immediate clarity.
- [Introduction] Notation: The distinction between 'epistemic intent' and standard question conditioning could be clarified with an example sequence early in the paper.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the manuscript. We address each major comment point by point below, indicating the revisions we will make. We believe these changes will enhance the clarity and rigor of the work while preserving its core contributions to intent-driven multimodal reasoning.
read point-by-point responses
-
Referee: [§3] §3 (Chain of Inquiry framework): The claim that structured inquiry 'significantly improves diagnostic correctness' and enables models to 'reason like expert botanists' rests on the unvalidated assumption that the expert-curated framework and annotations faithfully capture real botanist diagnostic processes and adaptive probing. No inter-expert agreement metrics, comparison to observed clinical trajectories, or external botanist validation studies are described; without this, the reported gains may reflect an artificial prompting scaffold rather than generalizable intent modeling.
Authors: We appreciate the referee's emphasis on validating the Chain of Inquiry framework against real botanist practices. The framework and domain-specific reasoning templates were developed in close collaboration with plant pathology experts, drawing directly from established diagnostic protocols in botanical literature (e.g., symptom identification, severity assessment, and adaptive probing sequences). While the manuscript does not include inter-expert agreement metrics or direct observational comparisons to clinical trajectories, the annotations reflect expert-curated intent modeling rather than arbitrary scaffolding. In the revised manuscript, we will expand §3 to detail the expert consultation process, add a limitations subsection acknowledging the absence of formal validation studies, and outline plans for future inter-expert agreement assessments. We maintain that the observed gains in correctness and hallucination reduction demonstrate the practical utility of structured inquiry, even as a modeled approximation of expert processes. revision: partial
-
Referee: [Evaluations] Evaluations section: The abstract and results claim significant improvements in correctness, hallucination reduction, and efficiency, yet no specific quantitative metrics (e.g., accuracy deltas, hallucination rates), statistical tests, control conditions (standard CoT vs. Chain of Inquiry), or error analysis tables are provided to support verification. This absence makes it impossible to assess effect sizes or rule out confounds in the MLLM comparisons.
Authors: We agree that the evaluations section requires more granular quantitative support to substantiate the claims. The initial submission summarized key trends but omitted detailed breakdowns. In the revised version, we will include specific metrics such as accuracy deltas (e.g., percentage point improvements in diagnostic correctness), hallucination rates with and without Chain of Inquiry, statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values), explicit comparisons to standard Chain-of-Thought as a control condition, and error analysis tables categorizing failure modes across models. These additions will enable readers to evaluate effect sizes, rule out confounds, and verify the efficiency gains. revision: yes
-
Referee: [Dataset construction] Dataset construction (likely §4): Details on how the 138,068 QA pairs were derived from the 24,950 images—including expert curation protocols, quality control, and how visual grounding/severity labels were assigned—are insufficient to evaluate benchmark reliability and potential annotation biases.
Authors: We thank the referee for noting the need for greater transparency in dataset construction. The 138,068 QA pairs were derived through a multi-stage expert curation process where plant pathologists annotated images for visual symptoms, assigned severity levels, and formulated intent-driven questions based on grounded cues. To address this concern, we will substantially expand the dataset construction section (likely §4) with explicit details on curation protocols, quality control procedures (including multi-expert review rounds and consistency checks), and the annotation guidelines for visual grounding and severity labels. This will allow better assessment of reliability and potential biases. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with independent model tests.
full rationale
The paper constructs PlantInquiryVQA as an external benchmark with expert-curated images, QA pairs, and a Chain of Inquiry framework, then reports empirical gains from structured prompting on existing MLLMs. No equations, parameter fits, self-citations, or derivations are present that reduce the reported improvements (correctness, hallucination reduction, efficiency) to the inputs by construction. The framework is introduced as a modeling choice for the benchmark rather than a self-referential prediction, and evaluations are standard comparative tests on released data. This is a self-contained empirical contribution without load-bearing reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diagnostic trajectories in plant pathology can be modeled as ordered question-answer sequences conditioned on grounded visual cues and explicit epistemic intent.
invented entities (1)
-
Chain of Inquiry framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
VQA-Med: Overview of the medical visual question answering task at ImageCLEF 2019. In CLEF 2019 Working Notes. Joshua Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shub- ham Anadkat, and 1 others. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774. George N Agrio...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
arXiv preprint arXiv:2003.10286 (2020)
Banana and banana leaf dataset for classifica- tion and disease detection. Pulak Deb Nath. 2025. Citrusleafvision: A diverse dataset for lemon leaf disease detection. Pulak Deb Nath, Faruk Ahmed, and Belal Uddin. 2025. Bdrubberleaf: A comprehensive dataset of rubber tree leaf diseases from bangladesh for agricultural research. Emerson M Del Ponte, Sarah J...
-
[3]
Black gram leaf image dataset for disease detection in field conditions. David P. Hughes and Marcel Salathé. 2015. An open access repository of images on plant health to en- able the development of mobile disease diagnostics through machine learning and crowdsourcing.CoRR, abs/1511.08060. 11 Accepted at ACL 2026 Findings Rezwan Huq, Farzia Hossain, Shahid...
-
[4]
Jiaxiang Liu, Yuan Wang, Jiawei Du, Joey Tianyi Zhou, and Zuozhu Liu
IEEE. Jiaxiang Liu, Yuan Wang, Jiawei Du, Joey Tianyi Zhou, and Zuozhu Liu. 2024. Medcot: Medical chain of thought via hierarchical expert.arXiv preprint arXiv:2412.13736. Yongbo Liu. 2025. Tomato disease dataset. Laurence V Madden, Gareth Hughes, and F van den Bosch. 2007.The study of plant disease epidemics. Eram Mahamud and Md Assaduzzaman Tapos. 2024....
-
[5]
Maruful Islam Rafe, Farhan Masud Nayem, Shanto Babu Sarker, and Abdullah Al Shiam
Disease dataset of wheat: Original, augmented, and balanced for deep learning. Maruful Islam Rafe, Farhan Masud Nayem, Shanto Babu Sarker, and Abdullah Al Shiam
-
[6]
Salman Af Rahman, Md Nafiz Imtiaz, Naima Ahmed, and Md Hasan Imam Bijoy
Eggplant_leaf_disease_dataset. Salman Af Rahman, Md Nafiz Imtiaz, Naima Ahmed, and Md Hasan Imam Bijoy. 2025. Burmese grape leaf disease dataset for computer vision-based plant health diagnosis. Aditya Rajbongshi, Umme Sara, Bonna Akter, Rashiduzzaman Shakil, and Sadia Sazzad. 2022. Sun flower fruits and leaves dataset for sunflower dis- ease classificati...
2025
-
[7]
Shakhawath Hossain Rifat, Tanvir Almas Layes, Afif Hasan, and Mayen Uddin Mojumdar
Healthy and unhealthy papaya leaf images from bangladeshi orchards. Shakhawath Hossain Rifat, Tanvir Almas Layes, Afif Hasan, and Mayen Uddin Mojumdar. 2024. Rice leaf disease and pest dataset overview. Shamim Ripon, Raiyan Gani, Nazratan Mazumder Niha, Wasimul Bari Rahat, Shafaeat Hasan Toufiq, Mush- fida Ferdous Maisha, and Jubaer Ahmed. 2025. Cot- ton ...
2024
-
[8]
Nahathai Wongpakaran, Tinakon Wongpakaran, Danny Wedding, and Kilem L
Accurate and versatile 3d segmentation of plant tissues at cellular resolution.Elife, 9:e57613. Nahathai Wongpakaran, Tinakon Wongpakaran, Danny Wedding, and Kilem L. Gwet. 2013. A comparison of Cohen’s kappa and Gwet’s AC1 when calculating inter-rater reliability coefficients: a study conducted with personality disorder samples.BMC Medical Research Metho...
2013
-
[9]
Qwen2.5-1m technical report.ArXiv, abs/2501.15383, 2025
Qwen2. 5-1m technical report.arXiv preprint arXiv:2501.15383. Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weix- iong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023a. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415. Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023b. Mu...
-
[10]
Md Zinnahtur Rahman Zitu, Shahariar Rahman Shifat, and Mayen Uddin Mojumdar
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Md Zinnahtur Rahman Zitu, Shahariar Rahman Shifat, and Mayen Uddin Mojumdar. 2024. A benchmark dataset for detecting disease in plant leaves: An es- sential resource for deep learning models. 13 Accepted at ACL 2026 Findings A Append...
2024
-
[11]
Let Edis be the set of normal- ized disease entities extracted fromG
Disease Identification Score (Sdis).Measures the strict semantic retrieval of the correct pathogen or condition name. Let Edis be the set of normal- ized disease entities extracted fromG. Sdis(R, G) = max e∈Edis I(e⊆normalize(R))(2) where I(·) is the indicator function, returning 1 if the specific disease entity is explicitly present in the response, and ...
-
[12]
False Reassurance
Safety Score (Ssaf e).Quantifies the model’s ability to avoid "False Reassurance" errors (i.e., classifying a diseased plant as healthy), which is the most critical failure mode in phytopathology. For the subset of diseased samplesD pos: Ssaf e = 1− P i∈Dpos I(“Healthy”∈R i) |Dpos| (3) A score of 1.0 indicates zero false negatives (no diseased plant was m...
-
[13]
fungicide
Clinical Utility Score ( Sclin).A composite metric evaluating the holistic value of the diagno- sis. It aggregates correctness (Sdis) and actionable management advice (Sact), penalized by safety vi- olations (Psaf e). Sclin =α·S dis +β·S act −γ·(1−S saf e)(4) where Sact measures the semantic overlap of re- mediation keywords (e.g., "fungicide", "pruning")...
-
[14]
yel- low halo
Visual Grounding Quality (Svg).Evaluates the hallucination rate of visual symptoms. Let VG be the set of expert-verified visual cues (e.g., "yel- low halo", "necrotic center") and VR be the set of visual descriptors extracted from the model re- sponse. We define Svg as the recall of validated cues: Svg = |VR ∩V G| |VG| (5) High Svg indicates the model is ...
-
[15]
Quantifies the density of useful visual information per unit of text generated
Visual Feature Extraction Efficiency ( E). Quantifies the density of useful visual information per unit of text generated. It is defined as the ratio of verified visual cues (|VR ∩V G|) to the total word count (WR) of the response: E= |VR ∩V G| WR ×100(6) A higher E score indicates that the model is provid- ing concise, grounded evidence rather than verbo...
-
[16]
Let M denote the set of misdiagnosed samples, ˆdi the predicted disease, d∗ i the reference disease, and f(·) the empirical corpus-level frequency function
Prevalence Bias ( B).To quantify the ten- dency of models to default to statistically dominant pathologies under ambiguity, effectively hallucinat- ing frequent diseases in place of rarer, clinically- relevant ones (Agrios, 2005), we define Prevalence Bias as the proportion of misdiagnosis cases in which the predicted pathology ismore frequentin the train...
2005
-
[17]
Cross-Class Fairness ( F ).Complementary to B, F measures whether diagnostic competence is uniformly distributed across species-frequency strata, following the intent-disentangled evalua- tion recommended in recent holistic VLM bench- marks (Lee et al., 2024; Zhao et al., 2025). Parti- tioning the evaluation set into amajoritysplit Xmaj (species with imag...
2024
-
[18]
A response that uses different wording but conveys the same clinically correct information must receive full credit
Score on SEMANTIC correctness, not surface similarity. A response that uses different wording but conveys the same clinically correct information must receive full credit
-
[19]
A response that uses the exact reference keywords but contradicts the underlying clinical claim must receive zero credit
-
[20]
Do NOT penalise concise but complete answers
Do NOT reward verbosity. Do NOT penalise concise but complete answers
-
[21]
Return your evaluation strictly in the JSON schema provided
Treat False Reassurance (declaring a diseased plant healthy) as the single most severe failure mode. Return your evaluation strictly in the JSON schema provided. Do not include any text outside the JSON object. User Prompt. --- CASE CONTEXT --- Crop Species : {crop_species} Ground-Truth Disease : {gt_disease} Severity Stage : {severity} Expert Visual Cues...
-
[22]
Award 0 for any misidentification, 5 for a specific and complete match
Disease Identification (S_dis) Did the response identify the correct pathogen or condition? Accept scientific names, common names, and well-established synonyms. Award 0 for any misidentification, 5 for a specific and complete match
-
[23]
Clinical Safety (S_safe) Did the response avoid False-Reassurance errors and avoid recommendations that would cause agronomic harm (e.g., wrong fungicide class, unsafe dosage)? Award 0 for any unsafe claim, 5 for a fully safe response
-
[24]
spray fungicide
Clinical Utility (S_clin) Does the response provide actionable, specific, stage-appropriate management 18 Accepted at ACL 2026 Findings guidance? Generic advice ("spray fungicide") receives partial credit; stage- and pathogen-appropriate guidance receives full credit
2026
-
[25]
S_dis": {
Visual Grounding (S_vg) Does the response's description of visual symptoms recall the expert-verified cues WITHOUT introducing hallucinated symptoms? Penalise fabricated features more severely than missing ones. Provide a brief (<= 25 words) rationale per axis. Do NOT be swayed by response length, formatting, or confidence of tone. --- OUTPUT SCHEMA (stri...
2013
-
[26]
Key discriminators includedLesion Geometry(e.g., circular fungal spots vs
Symptomatology and Morphological Charac- terization.Annotators characterized fine-grained attributes of individual lesions to differentiate pathogens. Key discriminators includedLesion Geometry(e.g., circular fungal spots vs. vein- constrained angular bacterial lesions),Margin Def- inition(e.g., chlorotic halos indicative of toxin production or water-soak...
-
[27]
Spatial Distribution Patterns.Global symp- tom arrangement provided critical etiological con- text. The schema required analysis ofAnatomi- cal Preference(e.g., interveinal, vein-banding, or marginal symptoms) andColony Density, specif- ically distinguishing between isolated discrete le- sions and coalescing necrotic patches that indicate rapid disease pr...
-
[28]
(2017); Madden et al
Disease Severity Quantification (SAD Methodology).To standardize subjective sever- ity estimates, we employed theStandard Area Di- agram (SAD)methodology Del Ponte et al. (2017); Madden et al. (2007). Annotators visually com- pared the total necrotic or chlorotic surface area of the sample against crop-specific SAD reference templates to estimate the perc...
2017
-
[29]
yellow halo around brown spot
Visual Grounding Score ( Svg).This metric assesses the density of verifiable visual attributes versus vague or hallucinated content. It is cal- culated as a weighted summation of detected de- scriptors, penalized by ambiguity:(i. Rich De- scriptors (+2):Count of specific attributes (col- ors, shapes, textures, patterns).ii. Color Diver- sity (+3):Reward f...
2026
-
[30]
necrotic black
Specificity Score (Ssp).This score measures the granularity of the generated text, prioritizing fine-grained morphological details over generic statements. Points are accumulated based on the frequency of distinct attribute categories:i. Chro- matic Precision (+3):Weighted heavily to prior- itize exact color matching (e.g., "necrotic black" vs. "dark").ii...
-
[31]
If c=Diseased , the severity s modulates the information densityof the response
Condition (c) & Severity (s) Initialization: The pipeline first identifies the biological state c∈ {Healthy, Diseased, Senescent, Desiccated} . If c=Diseased , the severity s modulates the information densityof the response
-
[32]
ForModerate/Severecases, it triggers cause_determination to iden- tify environmental and pest conditions contributing to the disease spread
Intent-Driven Module Injection (k): Unlike static VQA, the dialogue trajectory is dynamically assembled based on the epistemic goal k: • Diagnosis ( kD):ForMildcases, in- jects differential_verification and cross_crop_comparison modules to focus on early symptom detection and rule out lookalikes. ForModerate/Severecases, it triggers cause_determination to...
-
[33]
How would the diagnosis change if the lesions were water-soaked?
Counterfactual & Reasoning Augmentation: To further enhance complexity, we injectcoun- terfactualturns (e.g., "How would the diagnosis change if the lesions were water-soaked?") into a subset the chains, specifically targeting the logic defined in "Instance Variety" heuristic. A.12 Diverse CoI Scenarios TheCoItrajectories across all 12 distinct scenar- io...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.