Recognition: unknown
Differentially Private Model Merging
Pith reviewed 2026-05-10 01:10 UTC · model grok-4.3
The pith
Post-processing existing differentially private models with random selection or linear combination produces a model meeting any target privacy level without additional training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given models trained on identical data with different privacy parameters, random selection and linear combination serve as post-processing operations that produce a model satisfying any target differential privacy level. The privacy accounting is supplied in terms of Rényi DP and privacy loss distributions for general problems. For private mean estimation the privacy-utility tradeoff is fully characterized and linear combination is shown to dominate random selection.
What carries the argument
Random selection and linear combination of models trained on the same dataset with different privacy parameters, which compose to any target privacy level through post-processing.
Load-bearing premise
All input models must be trained on exactly the same dataset so their privacy guarantees compose correctly without extra leakage from data differences.
What would settle it
An empirical test on private mean estimation in which linear combination produces higher error than random selection at the same privacy level, or in which the measured privacy loss of either method exceeds the Rényi DP bound.
Figures





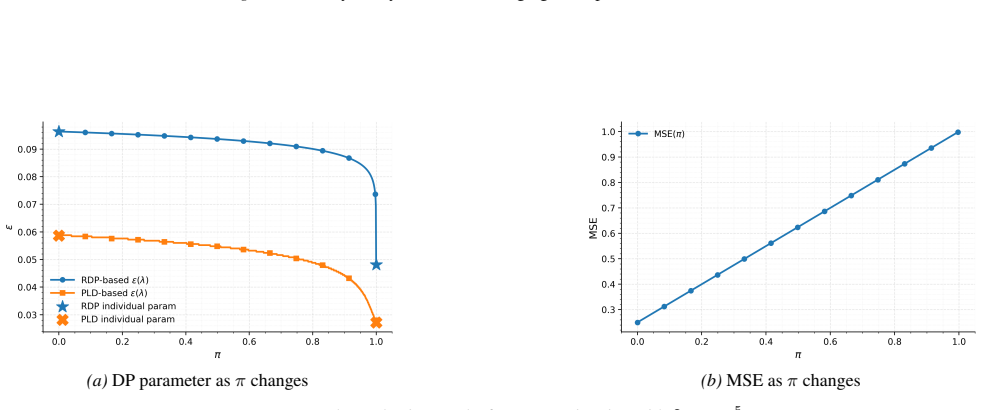
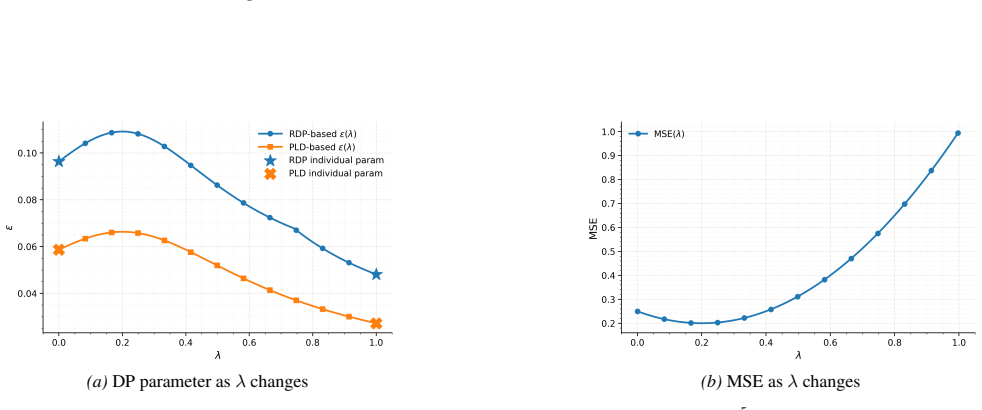
read the original abstract
In machine learning applications, privacy requirements during inference or deployment time could change constantly due to varying policies, regulations, or user experience. In this work, we aim to generate a magnitude of models to satisfy any target differential privacy (DP) requirement without additional training steps, given a set of existing models trained on the same dataset with different privacy/utility tradeoffs. We propose two post processing techniques, namely random selection and linear combination, to output a final private model for any target privacy parameter. We provide privacy accounting of these approaches from the lens of R'enyi DP and privacy loss distributions for general problems. In a case study on private mean estimation, we fully characterize the privacy/utility results and theoretically establish the superiority of linear combination over random selection. Empirically, we validate our approach and analyses on several models and both synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two post-processing techniques—random selection and linear combination—to combine pre-trained differentially private models (all trained on the identical dataset but with different privacy-utility tradeoffs) so that any target privacy parameter can be achieved without retraining. It supplies privacy accounting for these techniques via Rényi DP and privacy loss distributions for general problems, fully characterizes the privacy-utility tradeoff in a private mean estimation case study (showing linear combination is superior), and provides empirical validation on models and both synthetic and real-world datasets.
Significance. If the accounting correctly handles statistical dependence among the models, the work would be significant for flexible DP deployment in ML, allowing reuse of existing models for varying ε without retraining costs. The fully characterized mean-estimation case study, with its theoretical superiority proof, is a clear strength that supplies concrete, falsifiable predictions.
major comments (2)
- [General privacy accounting] General privacy accounting section: the claim to provide Rényi-DP and PLD accounting 'for general problems' is load-bearing for all target-ε guarantees, yet the derivations must use the exact joint privacy-loss random variable of the k dependent mechanisms (all functions of the same D). If the accounting instead applies independent-mixture formulas, triangle inequalities on Rényi orders, or marginal composition, the delivered (ε,δ) can be arbitrarily loose or incorrect; the manuscript should exhibit the joint PLD or prove why dependence does not affect the bound.
- [Case study on private mean estimation] Private mean estimation case study: while the theoretical characterization is a strength, the superiority proof for linear combination over random selection must be derived from the joint distribution under Gaussian noise on the shared sample; any implicit independence assumption would invalidate the comparison. Please state the exact privacy-loss random variable for the linear combination and confirm it yields the claimed utility improvement for every target ε.
minor comments (2)
- [Experiments] Empirical validation lacks reported error bars, number of runs, or full privacy-accounting details (e.g., exact δ values and composition steps), which would make the results easier to reproduce and compare.
- [Notation and definitions] Notation for the linear-combination weights (α) and the resulting privacy parameter should be introduced earlier and used consistently across the general accounting and the mean-estimation case study.
Simulated Author's Rebuttal
We thank the referee for their careful reading, constructive feedback, and recognition of the potential significance of our work for flexible DP model deployment. We address each major comment below with clarifications on our accounting approach and indicate the revisions we will make.
read point-by-point responses
-
Referee: General privacy accounting section: the claim to provide Rényi-DP and PLD accounting 'for general problems' is load-bearing for all target-ε guarantees, yet the derivations must use the exact joint privacy-loss random variable of the k dependent mechanisms (all functions of the same D). If the accounting instead applies independent-mixture formulas, triangle inequalities on Rényi orders, or marginal composition, the delivered (ε,δ) can be arbitrarily loose or incorrect; the manuscript should exhibit the joint PLD or prove why dependence does not affect the bound.
Authors: We agree that correct accounting requires the joint privacy-loss random variable, since all models are functions of the identical dataset D. Our general Rényi DP and PLD derivations are performed on the post-processed output (random selection or linear combination), which is a deterministic function of the tuple of model outputs; this uses the joint distribution by construction. We do not rely on independent-mixture formulas, triangle inequalities, or marginal composition. To address the concern, we will revise the general accounting section to explicitly exhibit the joint PLD of the combined mechanism and state that dependence is accounted for via the post-processing applied to the joint outputs. revision: partial
-
Referee: Private mean estimation case study: while the theoretical characterization is a strength, the superiority proof for linear combination over random selection must be derived from the joint distribution under Gaussian noise on the shared sample; any implicit independence assumption would invalidate the comparison. Please state the exact privacy-loss random variable for the linear combination and confirm it yields the claimed utility improvement for every target ε.
Authors: In the mean-estimation case study, each model is the empirical mean plus independent Gaussian noise whose variance is determined by its privacy parameter. Under neighboring datasets D and D', the joint distribution is multivariate Gaussian with identical mean shift in every coordinate. The linear combination is a univariate Gaussian whose variance is the corresponding quadratic form of the weights and individual variances. Its privacy-loss random variable is the log density ratio of this effective Gaussian under the two shifted means. We will add this explicit expression to the revised manuscript. The resulting utility (effective variance) is strictly smaller than that of random selection for any target ε, confirming the claimed superiority. revision: yes
Circularity Check
No significant circularity; accounting applies standard Rényi DP and PLD to post-processing without reduction to inputs.
full rationale
The derivation chain uses established external tools (Rényi DP composition and privacy loss distributions) to analyze random selection and linear combination post-processing on models trained with varying privacy budgets on identical data. The private mean estimation case study fully characterizes the joint privacy loss without fitting parameters to the target result or invoking self-citations as load-bearing uniqueness theorems. No quoted step equates a claimed prediction to its own fitted input or renames a known result via ansatz smuggling. The approach remains self-contained against external DP benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing models are trained on the same dataset with different privacy/utility tradeoffs
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[2]
Harvard Data Science Review , volume=
The 2020 census disclosure avoidance system topdown algorithm , author=. Harvard Data Science Review , volume=. 2022 , publisher=
2020
-
[3]
Journal of Artificial Intelligence Research , volume=
How to dp-fy ml: A practical guide to machine learning with differential privacy , author=. Journal of Artificial Intelligence Research , volume=
-
[4]
2010 IEEE 51st annual symposium on foundations of computer science , pages=
Boosting and differential privacy , author=. 2010 IEEE 51st annual symposium on foundations of computer science , pages=. 2010 , organization=
2010
-
[5]
Advances in Neural Information Processing Systems , volume=
Merging models with fisher-weighted averaging , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review arXiv
-
[7]
Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities
Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities , author=. arXiv preprint arXiv:2408.07666 , year=
-
[8]
Dataless knowl- edge fusion by merging weights of language models,
Dataless knowledge fusion by merging weights of language models , author=. arXiv preprint arXiv:2212.09849 , year=
-
[9]
Adamerging: Adaptive model merging for multi-task learning.arXiv preprint arXiv:2310.02575, 2023
Adamerging: Adaptive model merging for multi-task learning , author=. arXiv preprint arXiv:2310.02575 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[12]
Foundations and trends
The algorithmic foundations of differential privacy , author=. Foundations and trends. 2014 , publisher=
2014
-
[13]
International colloquium on automata, languages, and programming , pages=
Differential privacy , author=. International colloquium on automata, languages, and programming , pages=. 2006 , organization=
2006
-
[14]
Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
Deep learning with differential privacy , author=. Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
2016
-
[15]
Mironov, Ilya , booktitle=. R. 2017 , organization=
2017
-
[16]
Subsampled r
Wang, Yu-Xiang and Balle, Borja and Kasiviswanathan, Shiva Prasad , booktitle=. Subsampled r. 2019 , organization=
2019
-
[17]
Advances in Neural Information Processing Systems , volume=
Numerical composition of differential privacy , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security , pages=
Tight on budget? tight bounds for r-fold approximate differential privacy , author=. Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security , pages=
2018
-
[19]
Cryptology ePrint Archive , year=
Privacy loss classes: The central limit theorem in differential privacy , author=. Cryptology ePrint Archive , year=
-
[20]
arXiv preprint arXiv:2207.04380 , year=
Connect the dots: Tighter discrete approximations of privacy loss distributions , author=. arXiv preprint arXiv:2207.04380 , year=
-
[21]
International Conference on Artificial Intelligence and Statistics , pages=
Tight differential privacy for discrete-valued mechanisms and for the subsampled gaussian mechanism using fft , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[22]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Gaussian differential privacy , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
- [23]
-
[24]
International Conference on Artificial Intelligence and Statistics , pages=
Computing tight differential privacy guarantees using fft , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[25]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 2002 , publisher=
2002
-
[26]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[27]
arXiv preprint arXiv:2210.01864 , year=
Recycling scraps: Improving private learning by leveraging intermediate checkpoints , author=. arXiv preprint arXiv:2210.01864 , year=
-
[28]
International conference on machine learning , pages=
The composition theorem for differential privacy , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[29]
Opacus: User-friendly differential privacy library in PyTorch , author=. arXiv preprint arXiv:2109.12298 , year=
-
[30]
Proceedings on Privacy Enhancing Technologies , year=
Recycling Scraps: Improving Private Learning by Leveraging Checkpoints , author=. Proceedings on Privacy Enhancing Technologies , year=
-
[31]
ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models , year=
Can stochastic weight averaging improve generalization in private learning? , author=. ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models , year=
2023
-
[32]
Extremal dependence concepts , author=
-
[33]
Averaging weights leads to wider optima and better generalization , author=. arXiv preprint arXiv:1803.05407 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.