Recognition: unknown
Materialistic RIR: Material Conditioned Realistic RIR Generation
Pith reviewed 2026-05-09 23:58 UTC · model grok-4.3
The pith
Disentangled spatial and material modules generate controllable realistic room impulse responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our approach models the RIR using two modules: a spatial module that captures the influence of the spatial layout of the scene, and a material module that modulates this spatial RIR according to a user-specified material configuration. This explicitly disentangled design allows users to easily modify the material configuration of a scene and observe its impact on acoustics without altering the spatial structure or scene content. Our model provides significant improvements over prior approaches on both acoustic-based metrics (up to +16% on RTE) and material-based metrics (up to +70%).
What carries the argument
A spatial module producing a base room impulse response from scene layout, modulated by a separate material module that incorporates user-specified material properties.
If this is right
- Users gain the ability to change material configurations independently and see acoustic effects without altering spatial structure.
- Up to 16% improvement on acoustic metrics such as RTE over prior approaches.
- Up to 70% improvement on material-based metrics over prior approaches.
- Enhanced realism and material sensitivity shown in human perceptual studies compared to strongest baselines.
Where Pith is reading between the lines
- This separation could support real-time audio updates in interactive VR when users edit surface materials on the fly.
- The modular design might pair with automatic visual material detection to produce full acoustic models from scene images alone.
- Similar disentanglement could be tested on other propagation phenomena such as light transport or fluid flow if the same independence holds.
- pith_inferences
Load-bearing premise
Spatial layout effects and material properties can be cleanly separated into independent modules such that modulating the spatial RIR produces accurate results for any material combination.
What would settle it
Record real RIRs in a physical room, change only the surface materials while keeping geometry fixed, generate RIRs with the model using the new materials, and check if the differences in the generated responses match the measured differences in reverberation and frequency response.
Figures



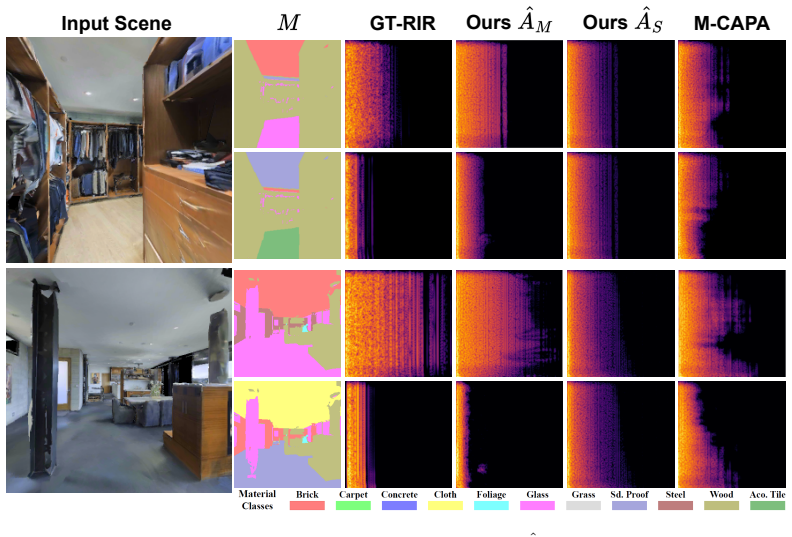

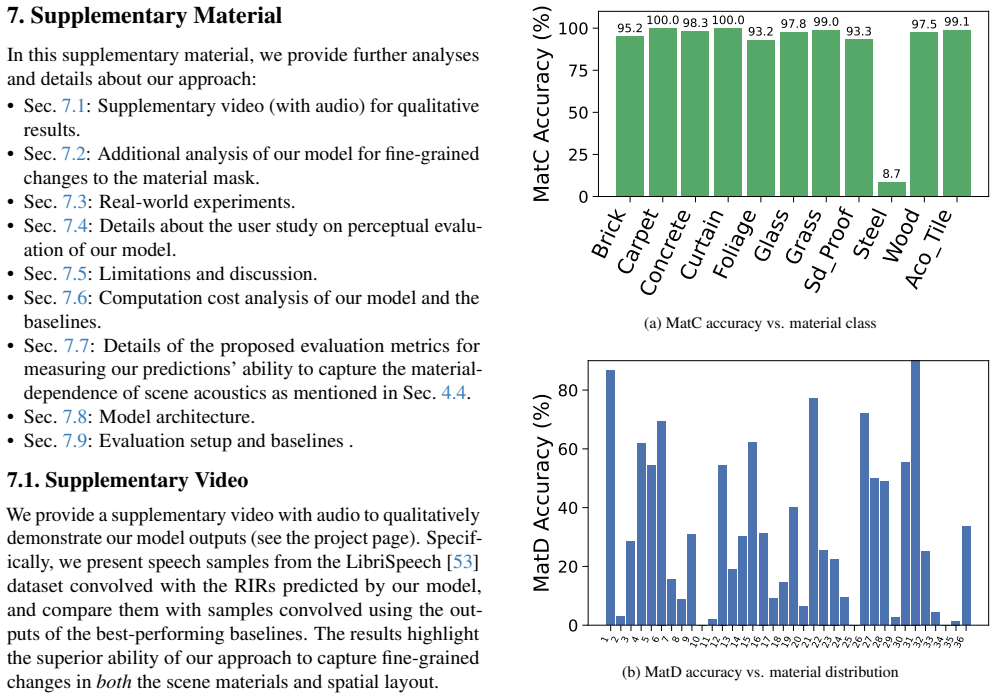

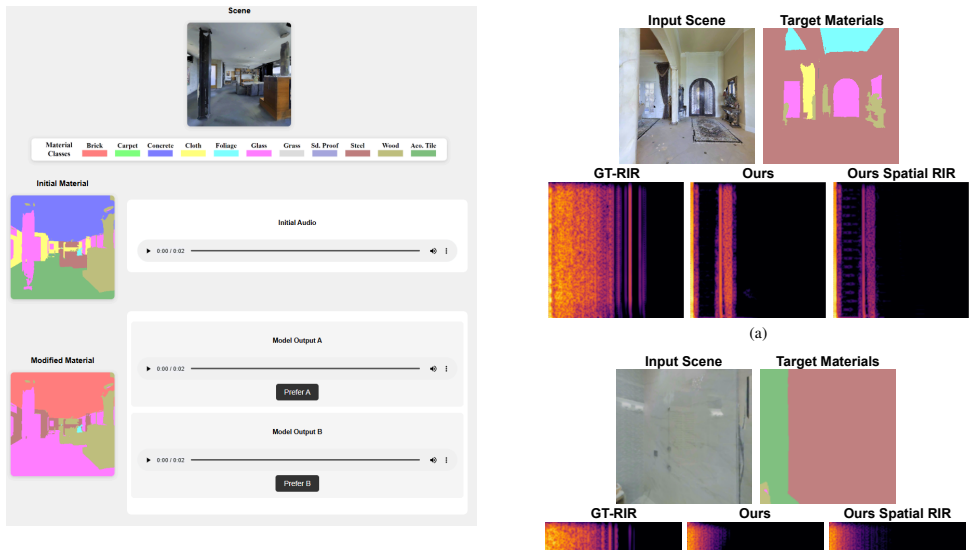

read the original abstract
Rings like gold, thuds like wood! The sound we hear in a scene is shaped not only by the spatial layout of the environment but also by the materials of the objects and surfaces within it. For instance, a room with wooden walls will produce a different acoustic experience from a room with the same spatial layout but concrete walls. Accurately modeling these effects is essential for applications such as virtual reality, robotics, architectural design, and audio engineering. Yet, existing methods for acoustic modeling often entangle spatial and material influences in correlated representations, which limits user control and reduces the realism of the generated acoustics. In this work, we present a novel approach for material-controlled Room Impulse Response (RIR) generation that explicitly disentangles the effects of spatial and material cues in a scene. Our approach models the RIR using two modules: a spatial module that captures the influence of the spatial layout of the scene, and a material module that modulates this spatial RIR according to a user-specified material configuration. This explicitly disentangled design allows users to easily modify the material configuration of a scene and observe its impact on acoustics without altering the spatial structure or scene content. Our model provides significant improvements over prior approaches on both acoustic-based metrics (up to +16% on RTE) and material-based metrics (up to +70%). Furthermore, through a human perceptual study, we demonstrate the improved realism and material sensitivity of our model compared to the strongest baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Materialistic RIR, a neural approach for generating Room Impulse Responses (RIRs) that explicitly disentangles spatial layout effects from material properties. It employs a spatial module to produce a base RIR from scene geometry and a material module to modulate it according to user-specified material configurations. This design is claimed to enable independent material editing without changing spatial structure or scene content. The authors report quantitative gains over prior methods (up to +16% on RTE acoustic metrics and +70% on material-based metrics) plus improved realism in a human perceptual study.
Significance. If the claimed disentanglement is validated, the work offers a useful advance for controllable acoustic simulation in VR, robotics, and architectural applications by moving beyond entangled representations. The explicit two-module separation and human study provide a concrete basis for user control and perceptual evaluation that prior learned RIR methods often lack.
major comments (2)
- [§3] §3 (Architecture): The description of the material module as a modulator does not specify mechanisms (e.g., frequency-dependent filtering or path-wise absorption application) that would provably preserve exact geometric delays, image-source positions, and diffraction timings produced by the spatial module. Without such guarantees or corresponding invariance tests, the central claim that material changes leave spatial structure unaltered remains unverified.
- [§5.2] §5.2 (Experiments, Table 2): Reported metric gains are presented without ablations that isolate whether material conditioning affects the spatial module's output (e.g., by freezing the spatial module and measuring changes in direct-sound arrival time or early-reflection statistics across material swaps). This test is load-bearing for the disentanglement guarantee.
minor comments (2)
- [Abstract / §3] The abstract and method section would benefit from a concise equation or diagram showing the exact composition of the final RIR (spatial output modulated by material features).
- [§5.3] Human study details (participant count, number of scenes/materials, forced-choice protocol, and significance testing) are referenced but not fully specified, limiting reproducibility of the perceptual claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The emphasis on rigorously validating the disentanglement between spatial layout and material properties is well-taken and aligns with the core contribution of our work. We address each major comment below and will revise the manuscript to strengthen the presentation of the architecture and experimental validation.
read point-by-point responses
-
Referee: [§3] §3 (Architecture): The description of the material module as a modulator does not specify mechanisms (e.g., frequency-dependent filtering or path-wise absorption application) that would provably preserve exact geometric delays, image-source positions, and diffraction timings produced by the spatial module. Without such guarantees or corresponding invariance tests, the central claim that material changes leave spatial structure unaltered remains unverified.
Authors: We agree that the architecture description in §3 would benefit from greater specificity regarding the modulation process. As a learned neural model, we do not claim formal mathematical guarantees of invariance. We will revise §3 to provide a more detailed account of the material module's implementation and how it is trained to respect the spatial structure produced by the first module. We will also add the suggested invariance tests, reporting direct-sound arrival times, image-source positions, and early-reflection statistics when material inputs are varied while holding the spatial module fixed. These updates will be incorporated in the revised manuscript. revision: partial
-
Referee: [§5.2] §5.2 (Experiments, Table 2): Reported metric gains are presented without ablations that isolate whether material conditioning affects the spatial module's output (e.g., by freezing the spatial module and measuring changes in direct-sound arrival time or early-reflection statistics across material swaps). This test is load-bearing for the disentanglement guarantee.
Authors: We acknowledge that the current experimental section lacks the explicit ablation of freezing the spatial module during material swaps. While our overall results and material-specific metrics provide supporting evidence, we agree that this targeted test would more directly substantiate the disentanglement. We will add the requested ablation to §5.2, including quantitative measurements of direct-sound arrival time and early-reflection statistics across material configurations with the spatial module held constant. The results will be reported alongside the existing Table 2 in the revised version. revision: yes
Circularity Check
No circularity in architecture or empirical claims
full rationale
The paper describes a neural architecture with separate spatial and material modules for RIR generation. Claims of explicit disentanglement and metric improvements (+16% RTE, +70% material metrics) plus perceptual study results rest on training and evaluation against external benchmarks and data, not on any self-referential definitions, fitted parameters renamed as predictions, or self-citation chains. No equations, derivations, or load-bearing self-citations appear in the provided text that reduce the central claims to inputs by construction. The disentanglement is an architectural design choice validated empirically rather than a mathematical result that circles back on itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Allen and David A
Jont B. Allen and David A. Berkley. Image method for effi- ciently simulating small-room acoustics.The Journal of the Acoustical Society of America, 65(4):943–950, 1979
1979
-
[2]
Direct-to-indirect acoustic radiance transfer.IEEE Transactions on Visualization and Computer Graphics, 18(2): 261–269, 2012
Lakulish Antani, Anish Chandak, Micah Taylor, and Dinesh Manocha. Direct-to-indirect acoustic radiance transfer.IEEE Transactions on Visualization and Computer Graphics, 18(2): 261–269, 2012
2012
-
[3]
Av-gs: Learning material and ge- ometry aware priors for novel view acoustic synthesis
Swapnil Bhosale, Haosen Yang, Diptesh Kanojia, Jiankang Deng, and Xiatian Zhu. Av-gs: Learning material and ge- ometry aware priors for novel view acoustic synthesis. In Advances in Neural Information Processing Systems, pages 28920–28937. Curran Associates, Inc., 2024
2024
-
[4]
1–a model zoo for robust monocular relative depth estimation
Reiner Birkl, Diana Wofk, and Matthias M¨uller. Midas v3.1 – a model zoo for robust monocular relative depth estimation. arXiv preprint arXiv:2307.14460, 2023
-
[5]
Interactive sound propagation with bidirec- tional path tracing.ACM Trans
Chunxiao Cao, Zhong Ren, Carl Schissler, Dinesh Manocha, and Kun Zhou. Interactive sound propagation with bidirec- tional path tracing.ACM Trans. Graph., 35(6), 2016
2016
-
[6]
Matterport3d: Learning from rgb-d data in indoor environments.International Conference on 3D Vision (3DV), 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.International Conference on 3D Vision (3DV), 2017
2017
-
[7]
Soundspaces: Audio- visual navigaton in 3d environments
Changan Chen, Unnat Jain, Carl Schissler, Sebastia Vi- cenc Amengual Gari, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, and Kristen Grauman. Soundspaces: Audio- visual navigaton in 3d environments. InECCV, 2020
2020
-
[8]
Seman- tic audio-visual navigation
Changan Chen, Ziad Al-Halah, and Kristen Grauman. Seman- tic audio-visual navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15516–15525, 2021
2021
-
[9]
Visual acoustic matching
Changan Chen, Ruohan Gao, Paul Calamia, and Kristen Grauman. Visual acoustic matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18858–18868, 2022
2022
-
[10]
Soundspaces 2.0: A simula- tion platform for visual-acoustic learning
Changan Chen, Carl Schissler, Sanchit Garg, Philip Kobernik, Alexander Clegg, Paul Calamia, Dhruv Batra, Philip W Robin- son, and Kristen Grauman. Soundspaces 2.0: A simula- tion platform for visual-acoustic learning. InNeurIPS 2022 Datasets and Benchmarks Track, 2022
2022
-
[11]
Novel-view acoustic synthesis
Changan Chen, Alexander Richard, Roman Shapovalov, Vamsi Krishna Ithapu, Natalia Neverova, Kristen Grauman, and Andrea Vedaldi. Novel-view acoustic synthesis. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6409–6419, 2023
2023
-
[12]
Mean-rir: Multi-modal environment-aware network for robust room impulse response estimation, 2025
Jiajian Chen, Jiakang Chen, Hang Chen, Qing Wang, Yu Gao, and Jun Du. Mean-rir: Multi-modal environment-aware network for robust room impulse response estimation, 2025
2025
-
[13]
Av-cloud: Spatial audio rendering through audio-visual cloud splatting
Mingfei Chen and Eli Shlizerman. Av-cloud: Spatial audio rendering through audio-visual cloud splatting. InAdvances in Neural Information Processing Systems, pages 141021– 141044. Curran Associates, Inc., 2024
2024
-
[14]
Gebru, Ishwarya Ananthabhotla, Christian Richardt, Dejan Markovic, Jake Sandakly, Steven Krenn, Todd Keebler, Eli Shlizerman, and Alexander Richard
Mingfei Chen, Israel D. Gebru, Ishwarya Ananthabhotla, Christian Richardt, Dejan Markovic, Jake Sandakly, Steven Krenn, Todd Keebler, Eli Shlizerman, and Alexander Richard. Soundvista: Novel-view ambient sound synthesis via visual- acoustic binding. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 8331–8341, 2025
2025
-
[15]
Sim2Real Transfer for Audio-Visual Nav- igation with Frequency-Adaptive Acoustic Field Prediction
Chen, Changan and Ramos, Jordi and Tomar, Anshul and Grauman, Kristen. Sim2Real Transfer for Audio-Visual Nav- igation with Frequency-Adaptive Acoustic Field Prediction. InIROS, 2024
2024
-
[16]
Adverb: Visually guided audio dereverberation
Sanjoy Chowdhury, Sreyan Ghosh, Subhrajyoti Dasgupta, An- ton Ratnarajah, Utkarsh Tyagi, and Dinesh Manocha. Adverb: Visually guided audio dereverberation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7884–7896, 2023
2023
-
[17]
Amen- gual Gari
Orchisama Das, Paul Calamia, and Sebastia V . Amen- gual Gari. Room impulse response interpolation from a sparse set of measurements using a modal architecture. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 960–964, 2021
2021
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
2021
-
[19]
Tenenbaum
Chuang Gan, Yiwei Zhang, Jiajun Wu, Boqing Gong, and Joshua B. Tenenbaum. Look, listen, and act: Towards audio- visual embodied navigation. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9701– 9707, 2020
2020
-
[20]
Soaf: Scene occlusion-aware neural acoustic field.arXiv preprint arXiv:2407.02264, 2024
Huiyu Gao, Jiahao Ma, David Ahmedt-Aristizabal, Chuong Nguyen, and Miaomiao Liu. Soaf: Scene occlusion-aware neural acoustic field.arXiv preprint arXiv:2407.02264, 2024
-
[21]
Gumerov and Ramani Duraiswami
Nail A. Gumerov and Ramani Duraiswami. A broadband fast multipole accelerated boundary element method for the three dimensional Helmholtz equation.The Journal of the Acoustical Society of America, 125(1):191–205, 2009
2009
-
[22]
Fdtd methods for 3-d room acoustics simulation with high-order accuracy in space and time.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(11):2112–2124, 2017
Brian Hamilton and Stefan Bilbao. Fdtd methods for 3-d room acoustics simulation with high-order accuracy in space and time.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(11):2112–2124, 2017
2017
-
[23]
Binaural tech- nique—basic methods for recording, synthesis, and repro- duction.Communication acoustics, pages 223–254, 2005
Dorte Hammershøi and Henrik Møller. Binaural tech- nique—basic methods for recording, synthesis, and repro- duction.Communication acoustics, pages 223–254, 2005
2005
-
[24]
The influence of the sigmoid function parameters on the speed of backpropagation learning
Jun Han and Claudio Moraga. The influence of the sigmoid function parameters on the speed of backpropagation learning. InInternational workshop on artificial neural networks, pages 195–201. Springer, 1995
1995
-
[25]
F.J. Harris. On the use of windows for harmonic analysis with the discrete fourier transform.Proceedings of the IEEE, 66 (1):51–83, 1978
1978
-
[26]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition.CoRR, abs/1512.03385, 2015
work page internal anchor Pith review arXiv 2015
-
[27]
Impulse response measurement techniques and their applicability in the real world, 2009
Martin Holters, Tobias Corbach, and Udo Z ¨olzer. Impulse response measurement techniques and their applicability in the real world, 2009
2009
-
[28]
Visual context-driven audio feature enhancement for robust end-to-end audio-visual speech recognition
Joanna Hong, Minsu Kim, Daehun Yoo, and Yong Man Ro. Visual context-driven audio feature enhancement for robust end-to-end audio-visual speech recognition. InInterspeech, 2022
2022
-
[29]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018
2018
-
[30]
Differentiable room acoustic rendering with multi-view vision priors
Derong Jin and Ruohan Gao. Differentiable room acoustic rendering with multi-view vision priors. InInternational Conference on Computer Vision (ICCV), 2025
2025
-
[31]
Evaluation of data augmentation tech- niques of room impulse responses for improved ai-based estimations
Christian Kehling. Evaluation of data augmentation tech- niques of room impulse responses for improved ai-based estimations. InProc. DAGA, pages 1285–1288, 2024
2024
-
[32]
Immersive spatial audio reproduction for vr/ar using room acoustic modelling from 360 images
Hansung Kim, Luca Remaggi, Philip JB Jackson, and Adrian Hilton. Immersive spatial audio reproduction for vr/ar using room acoustic modelling from 360 images. In2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pages 120–126. IEEE, 2019
2019
-
[33]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Deep neural networks for cross-modal estimations of acoustic reverberation character- istics from two-dimensional images
Homare Kon and Hideki Koike. Deep neural networks for cross-modal estimations of acoustic reverberation character- istics from two-dimensional images. InAudio Engineering Society Convention 144. Audio Engineering Society, 2018
2018
-
[35]
An auditory scaling method for reverb synthesis from a single two-dimensional image
Homare Kon and Hideki Koike. An auditory scaling method for reverb synthesis from a single two-dimensional image. Acoustical Science and Technology, 41(4):675–685, 2020
2020
-
[36]
Scene-aware audio for 360 videos.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
Dingzeyu Li, Timothy R Langlois, and Changxi Zheng. Scene-aware audio for 360 videos.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
2018
-
[37]
Blip- 2: bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning. JMLR.org, 2023
2023
-
[38]
Self-supervised audio-visual soundscape stylization
Tingle Li, Renhao Wang, Po-Yao Huang, Andrew Owens, and Gopala Anumanchipalli. Self-supervised audio-visual soundscape stylization. InEuropean Conference on Computer Vision, pages 20–40. Springer, 2024
2024
-
[39]
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu. Av-nerf: Learning neural fields for real-world audio-visual scene synthesis.ArXiv, abs/2302.02088, 2023
-
[40]
Neural acoustic context field: Rendering realistic room impulse response with neural fields, 2023
Susan Liang, Chao Huang, Yapeng Tian, Anurag Kumar, and Chenliang Xu. Neural acoustic context field: Rendering realistic room impulse response with neural fields, 2023
2023
-
[41]
Susan Liang, Chao Huang, Yunlong Tang, Zeliang Zhang, and Chenliang Xu. p-avas: Can physics-integrated audio-visual modeling boost neural acoustic synthesis? InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13942–13951, 2025
2025
-
[42]
Morgan & Claypool Publishers, 2022
Shiguang Liu and Dinesh Manocha.Sound synthesis, propa- gation, and rendering. Morgan & Claypool Publishers, 2022
2022
-
[43]
Hearing anywhere in any environment
Xiulong Liu, Anurag Kumar, Paul Calamia, Sebastia V Amen- gual, Calvin Murdock, Ishwarya Ananthabhotla, Philip Robin- son, Eli Shlizerman, Vamsi Krishna Ithapu, and Ruohan Gao. Hearing anywhere in any environment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5732–5741, 2025
2025
-
[44]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review arXiv 2016
-
[45]
Tarr, Joshua B
Andrew Luo, Yilun Du, Michael J. Tarr, Joshua B. Tenen- baum, Antonio Torralba, and Chuang Gan. Learning neural acoustic fields. InAdvances in Neural Information Processing Systems, 2022
2022
-
[46]
Active audio-visual separation of dynamic sound sources
Sagnik Majumder and Kristen Grauman. Active audio-visual separation of dynamic sound sources. InComputer Vision– ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIX, pages 551–
2022
-
[47]
Move2hear: Active audio-visual source separation
Sagnik Majumder, Ziad Al-Halah, and Kristen Grauman. Move2hear: Active audio-visual source separation. InPro- ceedings of the IEEE/CVF International Conference on Com- puter Vision, pages 275–285, 2021
2021
-
[48]
Few-Shot Audio-Visual Learning of En- vironment Acoustics
Sagnik Majumder, Changan Chen*, Ziad Al-Halah*, and Kristen Grauman. Few-Shot Audio-Visual Learning of En- vironment Acoustics. InConference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[49]
Cross-entropy loss functions: theoretical analysis and applications
Anqi Mao, Mehryar Mohri, and Yutao Zhong. Cross-entropy loss functions: theoretical analysis and applications. InPro- ceedings of the 40th International Conference on Machine Learning. JMLR.org, 2023
2023
-
[50]
Lin, and Dinesh Manocha
Ravish Mehra, Nikunj Raghuvanshi, Lauri Savioja, Ming C. Lin, and Dinesh Manocha. An efficient gpu-based time do- main solver for the acoustic wave equation.Applied Acoustics, 73(2):83–94, 2012
2012
-
[51]
Av-sam: Segment any- thing model meets audio-visual localization and segmentation
Shentong Mo and Yapeng Tian. Av-sam: Segment any- thing model meets audio-visual localization and segmentation. arXiv preprint arXiv:2305.01836, 2023
-
[52]
Maxime Oquab, Timoth´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Lab...
2023
-
[53]
Librispeech: an asr corpus based on public do- main audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public do- main audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
2015
-
[54]
Nikunj Raghuvanshi, Rahul Narain, and Ming C. Lin. Effi- cient and accurate sound propagation using adaptive rectangu- lar decomposition.IEEE Transactions on Visualization and Computer Graphics, 15(5):789–801, 2009
2009
-
[55]
Anton Ratnarajah and Dinesh Manocha. Listen2scene: Inter- active material-aware binaural sound propagation for recon- structed 3d scenes.2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), pages 254–264, 2023
2024
-
[56]
TS- RIR: Translated synthetic room impulse responses for speech augmentation
Anton Ratnarajah, Zhenyu Tang, and Dinesh Manocha. TS- RIR: Translated synthetic room impulse responses for speech augmentation. In2021 IEEE automatic speech recognition and understanding workshop (ASRU), pages 259–266. IEEE, 2021
2021
-
[57]
Fast-rir: Fast neural diffuse room impulse response generator
Anton Ratnarajah, Shi-Xiong Zhang, Meng Yu, Zhenyu Tang, Dinesh Manocha, and Dong Yu. Fast-rir: Fast neural diffuse room impulse response generator. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 571–575, 2022
2022
-
[58]
Towards improved room impulse response estimation for speech recognition
Anton Ratnarajah, Ishwarya Ananthabhotla, Vamsi Krishna Ithapu, Pablo Hoffmann, Dinesh Manocha, and Paul Calamia. Towards improved room impulse response estimation for speech recognition. InICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[59]
Av-rir: Audio-visual room im- pulse response estimation
Anton Ratnarajah, Sreyan Ghosh, Sonal Kumar, Purva Chiniya, and Dinesh Manocha. Av-rir: Audio-visual room im- pulse response estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27164–27175, 2024
2024
-
[60]
Reproducing real world acoustics in virtual reality using spherical cameras
Luca Remaggi, Hansung Kim, Philip JB Jackson, and Adrian Hilton. Reproducing real world acoustics in virtual reality using spherical cameras. InAudio Engineering Society Con- ference: 2019 AES International Conference on Immersive and Interactive Audio. Audio Engineering Society, 2019
2019
-
[61]
How Would It Sound? Material-Controlled Multimodal Acoustic Profile Generation for Indoor Scenes
Mahnoor Fatima Saad and Ziad Al-Halah. How Would It Sound? Material-Controlled Multimodal Acoustic Profile Generation for Indoor Scenes. InInternational Conference on Computer Vision (ICCV), 2025
2025
-
[62]
Interactive sound prop- agation and rendering for large multi-source scenes.ACM Transactions on Graphics (TOG), 36(4):1, 2016
Carl Schissler and Dinesh Manocha. Interactive sound prop- agation and rendering for large multi-source scenes.ACM Transactions on Graphics (TOG), 36(4):1, 2016
2016
-
[63]
Acous- tic classification and optimization for multi-modal rendering of real-world scenes.IEEE transactions on visualization and computer graphics, 24(3):1246–1259, 2017
Carl Schissler, Christian Loftin, and Dinesh Manocha. Acous- tic classification and optimization for multi-modal rendering of real-world scenes.IEEE transactions on visualization and computer graphics, 24(3):1246–1259, 2017
2017
-
[64]
Sinaga and Miin-Shen Yang
Kristina P. Sinaga and Miin-Shen Yang. Unsupervised k- means clustering algorithm.IEEE Access, 8:80716–80727, 2020
2020
-
[65]
Image2reverb: Cross-modal reverb impulse response synthesis.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 286–295, 2021
Nikhil Singh, Jeff Mentch, Jerry Ng, Matthew Beveridge, and Iddo Drori. Image2reverb: Cross-modal reverb impulse response synthesis.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 286–295, 2021
2021
-
[66]
Self-supervised visual acoustic matching.Advances in Neural Information Processing Systems, 36, 2024
Arjun Somayazulu, Changan Chen, and Kristen Grauman. Self-supervised visual acoustic matching.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[67]
Comparison of different impulse response mea- surement techniques.Journal of the Audio Engineering Soci- ety, 50(4):249–262, 2002
Guy-Bart Stan, Jean-Jacques Embrechts, and Dominique Ar- chambeau. Comparison of different impulse response mea- surement techniques.Journal of the Audio Engineering Soci- ety, 50(4):249–262, 2002
2002
-
[68]
INRAS: Implicit neural representation for audio scenes
Kun Su, Mingfei Chen, and Eli Shlizerman. INRAS: Implicit neural representation for audio scenes. InAdvances in Neural Information Processing Systems, 2022
2022
-
[69]
Gwa: A large high-quality acoustic dataset for audio processing
Zhenyu Tang, Rohith Aralikatti, Anton Jeran Ratnarajah, and Dinesh Manocha. Gwa: A large high-quality acoustic dataset for audio processing. InACM SIGGRAPH 2022 Conference Proceedings, pages 1–9, 2022
2022
-
[70]
Thompson
Lonny L. Thompson. A review of finite-element methods for time-harmonic acoustics.The Journal of the Acoustical Society of America, 119(3):1315–1330, 2006
2006
-
[71]
Audio-visual event localization in unconstrained videos
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chen- liang Xu. Audio-visual event localization in unconstrained videos. InProceedings of the European Conference on Com- puter Vision (ECCV), 2018
2018
-
[72]
CRC Press, 2014
Tor Erik Vigran.Building acoustics. CRC Press, 2014
2014
-
[73]
Michael V orl¨ander. Simulation of the transient and steady- state sound propagation in rooms using a new combined ray- tracing/image-source algorithm.The Journal of the Acoustical Society of America, 86(1):172–178, 1989
1989
-
[74]
Hearing anything anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, and Jiajun Wu. Hearing anything anywhere. InCVPR, 2024
2024
-
[75]
arXiv preprint arXiv:2211.05778 , year=
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, et al. Internimage: Exploring large-scale vision founda- tion models with deformable convolutions.arXiv preprint arXiv:2211.05778, 2022
-
[76]
Stephan Werner, Florian Klein, Annika Neidhardt, Ulrike Sloma, Christian Schneiderwind, and Karlheinz Branden- burg. Creation of auditory augmented reality using a position- dynamic binaural synthesis system—technical components, psychoacoustic needs, and perceptual evaluation.Applied Sciences, 11(3):1150, 2021
2021
-
[77]
Youtube movie reviews: Sentiment analysis in an audio-visual context.IEEE Intelligent Systems, 28(3): 46–53, 2013
Martin W ¨ollmer, Felix Weninger, Tobias Knaup, Bj ¨orn Schuller, Congkai Sun, Kenji Sagae, and Louis-Philippe Morency. Youtube movie reviews: Sentiment analysis in an audio-visual context.IEEE Intelligent Systems, 28(3): 46–53, 2013
2013
-
[78]
Binaural audio-visual localization
Xinyi Wu, Zhenyao Wu, Lili Ju, and Song Wang. Binaural audio-visual localization. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 2961–2968, 2021
2021
-
[79]
Empirical evalua- tion of rectified activations in convolutional network
Bing Xu. Empirical evaluation of rectified activations in convolutional network.arXiv preprint arXiv:1505.00853, 2015
-
[80]
Surround by sound: A review of spatial audio recording and reproduction.Applied Sciences, 7 (5):532, 2017
Wen Zhang, Parasanga N Samarasinghe, Hanchi Chen, and Thushara D Abhayapala. Surround by sound: A review of spatial audio recording and reproduction.Applied Sciences, 7 (5):532, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.