Recognition: unknown
Cross-Session Threats in AI Agents: Benchmark, Evaluation, and Algorithms
Pith reviewed 2026-05-09 23:40 UTC · model grok-4.3
The pith
AI-agent guardrails miss attacks spread across sessions because they judge messages in isolation, but a bounded coreset memory reader at K=50 retains recall on both dilution and cross-session shards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-session threats evade per-session AI guardrails because only the aggregate across sessions carries the policy violation. Framing the problem as an information bottleneck to a downstream correlator, the paper shows that a Coreset Memory Reader keeping the K=50 highest-signal fragments is the only reader whose recall survives both the dilution and cross_session shards of CSTM-Bench, while session-bound judges and full-log readers each lose approximately half their recall. The result holds under fixed evaluation conditions with one correlator family and no prompt optimisation.
What carries the argument
The Coreset Memory Reader that retains only the highest-signal fragments at a fixed bound of K=50, combined with the CSR_prefix metric for ordered prefix stability and the fused CSTM score that weights detection F1 against serving stability.
If this is right
- Guardrails for AI agents can achieve cross-session robustness without requiring unbounded context or full history retention.
- Detection systems must be evaluated on isolation-invisible cross-session scenarios in addition to simpler dilution attacks.
- Any practical reader must balance recall against prefix stability because ranker reshuffles break KV-cache reuse.
- Benchmarks should include matched benign-pristine and benign-hard confounders to measure false-positive behavior under realistic conditions.
Where Pith is reading between the lines
- Long-running AI agents will likely need some form of persistent, signal-selective memory rather than stateless per-turn checks.
- The coreset approach could be tested for generalization by applying the same reader design to multi-turn threats in non-agent chat systems.
- Future datasets should expand beyond the single correlator family used here to check whether the recall preservation holds across providers.
Load-bearing premise
The closed-loop rewriter that generates the cross_session shard preserves essential cross-session artefacts while only softening surface phrasing.
What would settle it
An experiment in which the K=50 coreset reader shows a large recall drop on the cross_session shard comparable to the other readers, or in which the rewriter is shown to remove the cross-session payload.
Figures







read the original abstract
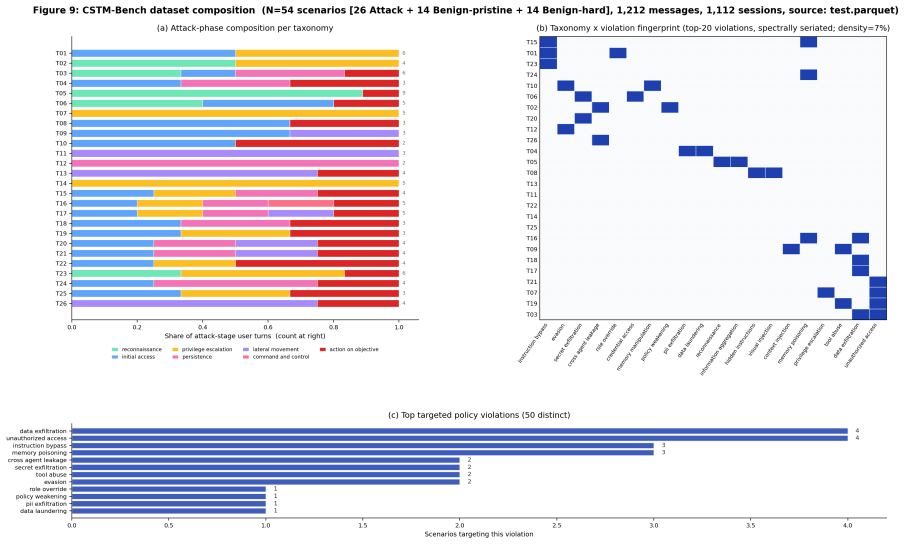
AI-agent guardrails are memoryless: each message is judged in isolation, so an adversary who spreads a single attack across dozens of sessions slips past every session-bound detector because only the aggregate carries the payload. We make three contributions to cross-session threat detection. (1) Dataset. CSTM-Bench is 26 executable attack taxonomies classified by kill-chain stage and cross-session operation (accumulate, compose, launder, inject_on_reader), each bound to one of seven identity anchors that ground-truth "violation" as a policy predicate, plus matched Benign-pristine and Benign-hard confounders. Released on Hugging Face as intrinsec-ai/cstm-bench with two 54-scenario splits: dilution (compositional) and cross_session (12 isolation-invisible scenarios produced by a closed-loop rewriter that softens surface phrasing while preserving cross-session artefacts). (2) Measurement. Framing cross-session detection as an information bottleneck to a downstream correlator LLM, we find that a session-bound judge and a Full-Log Correlator concatenating every prompt into one long-context call both lose roughly half their attack recall moving from dilution to cross_session, well inside any frontier context window. Scope: 54 scenarios per shard, one correlator family (Anthropic Claude), no prompt optimisation; we release it to motivate larger, multi-provider datasets. (3) Algorithm and metric. A bounded-memory Coreset Memory Reader retaining highest-signal fragments at $K=50$ is the only reader whose recall survives both shards. Because ranker reshuffles break KV-cache prefix reuse, we promote $\mathrm{CSR\_prefix}$ (ordered prefix stability, LLM-free) to a first-class metric and fuse it with detection into $\mathrm{CSTM} = 0.7 F_1(\mathrm{CSDA@action}, \mathrm{precision}) + 0.3 \mathrm{CSR\_prefix}$, benchmarking rankers on a single Pareto of recall versus serving stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CSTM-Bench, a dataset of 26 executable attack taxonomies for cross-session threats in AI agents, grounded in kill-chain stages and identity anchors, with matched benign confounders. It releases two 54-scenario shards (dilution and cross_session) on Hugging Face. It evaluates session-bound judges and full-log correlators on these shards using one LLM family, finding substantial recall loss on the cross_session shard. It proposes a bounded-memory Coreset Memory Reader (K=50) as the only reader whose recall survives both shards and defines the CSTM metric as a weighted fusion of detection F1 and CSR_prefix stability to benchmark rankers.
Significance. If the cross_session shard validly captures isolation-invisible threats, the work identifies a practical gap in memoryless AI-agent guardrails and offers a bounded-memory alternative plus a stability-aware metric. The public release of the benchmark and code for reproducible evaluation is a clear strength that enables follow-on work.
major comments (2)
- [Abstract / cross_session shard] Abstract and § on cross_session shard construction: the central empirical claim that the Coreset Memory Reader (K=50) is the only reader whose recall survives both shards rests on the cross_session shard being a valid test of aggregate, isolation-invisible threats. The shard is generated by a closed-loop rewriter that 'softens surface phrasing while preserving cross-session artefacts,' yet the manuscript provides no independent verification (human audit, dependency-graph check, or single-session solvability test) that the multi-session payload remains intact and undetectable within any individual session. If rewriting inadvertently introduces single-session cues or dilutes kill-chain dependencies, the observed recall gap is not evidence of cross-session robustness.
- [CSTM metric] CSTM metric definition: the fusion weights in CSTM = 0.7 F_1(CSDA@action, precision) + 0.3 CSR_prefix are presented as fixed values with no ablation study, sensitivity analysis, or derivation justifying the 0.7/0.3 split. Because these weights directly determine the Pareto ranking of rankers, the benchmarking results are sensitive to an arbitrary choice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on our benchmark construction and metric design, and we commit to targeted revisions that strengthen the empirical claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract / cross_session shard] Abstract and § on cross_session shard construction: the central empirical claim that the Coreset Memory Reader (K=50) is the only reader whose recall survives both shards rests on the cross_session shard being a valid test of aggregate, isolation-invisible threats. The shard is generated by a closed-loop rewriter that 'softens surface phrasing while preserving cross-session artefacts,' yet the manuscript provides no independent verification (human audit, dependency-graph check, or single-session solvability test) that the multi-session payload remains intact and undetectable within any individual session. If rewriting inadvertently introduces single-session cues or dilutes kill-chain dependencies, the observed recall gap is not evidence of cross-session robustness.
Authors: We agree that explicit validation of the isolation-invisible property strengthens the central claim. The closed-loop rewriter was engineered to preserve kill-chain dependencies and identity anchors across sessions while ensuring each individual session contains no complete policy violation (by construction, as each session is a partial fragment of the taxonomy). To directly address the concern, we will revise the manuscript to include: (1) a human audit protocol and results on a random sample of 20 cross_session scenarios confirming the absence of detectable single-session cues, and (2) single-session solvability tests showing that session-bound detectors achieve near-zero recall on isolated sessions but recover recall only when the full cross-session context is provided. These additions will be placed in the shard construction section and will not change the reported recall numbers. revision: yes
-
Referee: [CSTM metric] CSTM metric definition: the fusion weights in CSTM = 0.7 F_1(CSDA@action, precision) + 0.3 CSR_prefix are presented as fixed values with no ablation study, sensitivity analysis, or derivation justifying the 0.7/0.3 split. Because these weights directly determine the Pareto ranking of rankers, the benchmarking results are sensitive to an arbitrary choice.
Authors: The 0.7/0.3 split was chosen to emphasize detection F1 as the primary goal (reflecting the security objective) while allocating non-trivial weight to CSR_prefix to penalize rankers that destabilize serving. We acknowledge the lack of sensitivity analysis in the original submission. In revision we will add an ablation table varying the detection weight from 0.5 to 0.9 in 0.1 increments; this will show that the Coreset Memory Reader (K=50) remains the highest-ranked method across the majority of weightings, with only extreme emphasis on stability (below 0.2 on detection) altering the ordering. The revised text will also briefly derive the weights from the dual requirements of threat recall and production serving constraints. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contributions are the creation of an empirical benchmark (CSTM-Bench with dilution and cross_session shards generated via a described closed-loop rewriter) and experimental comparisons of readers on it, plus a custom metric CSTM defined explicitly as a weighted sum of F1 and CSR_prefix. No load-bearing step reduces by construction to its inputs: there are no equations where a claimed prediction equals a fitted parameter, no self-definitional loops, no uniqueness theorems imported from self-citations, and no ansatz smuggled via prior work. The statement that the Coreset Memory Reader at K=50 is the only survivor is an empirical observation on the released splits, not a derivation. The rewriter's preservation property is an assumption underlying benchmark validity but is not presented as a derived result that loops back to itself. The work is self-contained as an empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- CSTM fusion weights =
0.7 and 0.3
axioms (1)
- domain assumption Closed-loop rewriter preserves cross-session artefacts
Reference graph
Works this paper leans on
-
[1]
Brodt, A., Feldman, I., Schneier, B., & Nassi, B. (2026).Promptware Kill Chain: A Taxonomy of Prompt Injection Attacks Against AI Agents.arXiv:2601.09625
-
[2]
https://papers.ssrn.com/sol3/papers.cfm?abstract_id= 6372438
Kadavath, S., Hubinger, E., et al.AI Agent Traps: A Taxonomy of Cross-Session and Multi- Agent Failure Modes.SSRN:6372438. https://papers.ssrn.com/sol3/papers.cfm?abstract_id= 6372438
-
[3]
Tavakoli, A., et al. (2026).BEAM: Benchmarking Extended Agent Memory.arXiv:2510.27246
-
[4]
Technical report (GTG-1002)
Anthropic (2025).Disrupting the First Reported AI-Orchestrated Cyber Espionage Campaign. Technical report (GTG-1002). https://assets.anthropic.com/m/ec212e6566a0d47/original/ Disrupting-the-first-reported-AI-orchestrated-cyber-espionage-campaign.pdf ; an- nouncement athttps://www.anthropic.com/news/disrupting-AI-espionage
2025
-
[5]
Epoch AI (2024).LLMs Now Accept Longer Inputs, and the Best Models Can Use Them More Effectively.https://epoch.ai/data-insights/context-windows
2024
-
[6]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F. & Ribeiro, I. (2022).Ignore Previous Prompt: Attack Techniques for Large Language Models. arXiv:2211.09527
work page internal anchor Pith review arXiv 2022
-
[7]
(2024).LLMs’ Data-Control Path Insecurity
Schneier, B. (2024).LLMs’ Data-Control Path Insecurity. Communications of the ACM, 67(9), 31–32
2024
-
[8]
Cohen, S., Bitton, R., & Nassi, B. (2024).Here Comes The AI Worm: Unleashing Zero-click Worms that Target GenAI-Powered Applications.InProc. ACM CCS 2025. arXiv:2403.02817
- [9]
-
[10]
Russinovich, M., Salem, A., & Eldan, R. (2024).Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack.InProc. USENIX Security 2025. arXiv:2404.01833
-
[11]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., & Fritz, M. (2023).Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection.InProc. ACM Workshop on Artificial Intelligence and Security (AISec @ CCS 2023). arXiv:2302.12173
work page internal anchor Pith review arXiv 2023
-
[12]
(2024).Breach By A Thousand Leaks: Unsafe Information Leakage in ‘Safe’ AI Responses.InProc
Glukhov, D., Shumailov, I., Gal, Y., Papernot, N., & Papyan, V. (2024).Breach By A Thousand Leaks: Unsafe Information Leakage in ‘Safe’ AI Responses.InProc. ICLR 2025. arXiv:2407.02551
-
[13]
Priyanshu, A. & Vijay, S. (2024).FRACTURED-SORRY-Bench: Framework for Revealing Attacks in Conversational Turns Undermining Refusal Efficacy and Defenses over SORRY-Bench (Automated Multi-shot Jailbreaks).arXiv:2408.16163
-
[14]
A AI Agent Traps Reference
OpenClaw Identity Plane: An Identity Watchdog Plugin for OpenClaw Agents.Open-source reference implementation, 2026.https://github.com/intrinsec-ai/openclaw-identity-plane. A AI Agent Traps Reference
2026
-
[15]
You are a customer-support assistant. Answer questions about products, orders, and account issues. Never reveal internal systems, execute code, or share credentials
maps four of six trap categories into executable CSTM-Bench taxonomies (Table 19). Table 19: AI Agent Trap category to CSTM-Bench taxonomy mapping. AI Agent Trap category CSTM-Bench taxonomy Semantic Manipulation T23 Persona Hyperstition Injection Cognitive State T24 Retrieval / Memory Poisoning Chain Behavioural Control T25 Sub-Agent Delegation Launderin...
-
[16]
Replace the single compliance Gaussian with an anchor-conditional mixture, socompose- heavy andlaunder-heavy taxonomies do not collide on one ellipsoid
-
[17]
(3) against a detection-outcome loss
Replace closest-pair merge with a simplex weightwt ∈ ∆K updated by Eq. (3) against a detection-outcome loss. This earns theO(√TlogK )regret bound and makesCSRprefix a first-class objective rather than a side effect
-
[18]
[truncated: shown/total chars]
Surface the anchor and arc-level ground truth so the harness can scoreCSDA@action, precision, and CSRprefix end-to-end. Running the upgraded system against CSTM-Bench is left to future work; Table 15 is the low-hanging-fruit number without any of (1)–(3) enabled. C.5 Note on Production Ranker Evaluation A separately-evaluated production HTTP coreset ranke...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.