Recognition: unknown
Using Machine Mental Imagery for Representing Common Ground in Situated Dialogue
Pith reviewed 2026-05-09 23:40 UTC · model grok-4.3
The pith
Conversational agents track shared context better by incrementally building persistent visual representations from dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that an active visual scaffolding framework, which converts ongoing dialogue state into a growing set of depictive visual representations, reduces representational blur by forcing concrete scene commitments. Incremental externalization alone beats full-dialog text reasoning, visual scaffolding adds further gains, and a hybrid multimodal setup that keeps text for non-depictable content achieves the highest performance on the IndiRef benchmark.
What carries the argument
Active visual scaffolding: the incremental conversion of dialogue state into a persistent visual history that can be retrieved for grounded response generation.
If this is right
- Incremental externalization of dialogue state improves performance over full-dialog text reasoning even without visuals.
- Visual scaffolding reduces representational blur by enforcing concrete commitments to scene details.
- Textual representations remain preferable for non-depictable information such as abstract or internal states.
- A hybrid multimodal representation of common ground that combines depictive and propositional content yields the best overall results.
Where Pith is reading between the lines
- The same incremental visual scaffolding could be applied to embodied agents that must maintain consistent beliefs about a physical environment across multiple interactions.
- Testing the framework on longer, multi-session dialogues would reveal whether the visual history prevents drift in common ground more effectively than current context-window methods.
- The approach suggests a general principle that forcing intermediate representations into a different modality can mitigate compression losses that occur in single-modality reasoning chains.
Load-bearing premise
Multimodal models can generate accurate visual representations from dialogue without introducing errors or biases that outweigh the gains over text-only methods.
What would settle it
An experiment on a new set of dialogues containing similar but distinct entities where visual scaffolding produces more misidentifications or hallucinations than a pure text baseline.
Figures

















read the original abstract
Situated dialogue requires speakers to maintain a reliable representation of shared context rather than reasoning only over isolated utterances. Current conversational agents often struggle with this requirement, especially when the common ground must be preserved beyond the immediate context window. In such settings, fine-grained distinctions are frequently compressed into purely textual representations, leading to a critical failure mode we call \emph{representational blur}, in which similar but distinct entities collapse into interchangeable descriptions. This semantic flattening creates an illusion of grounding, where agents appear locally coherent but fail to track shared context persistently over time. Inspired by the role of mental imagery in human reasoning, and based on the increased availability of multimodal models, we explore whether conversational agents can be given an analogous ability to construct some depictive intermediate representations during dialogue to address these limitations. Thus, we introduce an active visual scaffolding framework that incrementally converts dialogue state into a persistent visual history that can later be retrieved for grounded response generation. Evaluation on the IndiRef benchmark shows that incremental externalization itself improves over full-dialog reasoning, while visual scaffolding provides additional gains by reducing representational blur and enforcing concrete scene commitments. At the same time, textual representations remain advantageous for non-depictable information, and a hybrid multimodal setting yields the best overall performance. Together, these findings suggest that conversational agents benefit from an explicitly multimodal representation of common ground that integrates depictive and propositional information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an active visual scaffolding framework, inspired by human mental imagery, allows conversational agents to incrementally externalize dialogue state into persistent visual representations to better maintain common ground in situated dialogue. It identifies 'representational blur' as a failure mode of purely textual representations and reports that on the IndiRef benchmark, incremental externalization improves over full-dialog reasoning, visual scaffolding yields additional gains by reducing blur and enforcing concrete commitments, textual representations remain useful for non-depictable information, and hybrid multimodal settings achieve the best overall performance.
Significance. If the empirical results hold, the work could meaningfully advance situated dialogue systems by demonstrating the value of explicitly multimodal common-ground representations that combine depictive and propositional elements. Strengths include the use of an external benchmark (IndiRef) and comparisons against textual baselines, which support reproducibility and allow direct assessment of the incremental and hybrid contributions.
major comments (2)
- [Abstract] Abstract: The reported benchmark gains on IndiRef are presented without implementation details, statistical analysis, controls for confounding factors, or error analysis, preventing full assessment of whether incremental externalization and visual scaffolding actually reduce representational blur or deliver the claimed improvements.
- [Evaluation] Evaluation section: The central assumption that multimodal models can reliably construct accurate, depictive intermediate representations from dialogue without introducing offsetting errors or biases requires concrete validation through error analysis or ablation studies on IndiRef.
minor comments (2)
- [Introduction] The term 'representational blur' is introduced in the abstract but would benefit from a formal definition or illustrative example early in the introduction to clarify its distinction from standard context-loss issues.
- A diagram of the active visual scaffolding pipeline (incremental externalization, retrieval, and hybrid generation) would improve clarity of the framework.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive feedback. We address each major comment below with clarifications from the manuscript and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported benchmark gains on IndiRef are presented without implementation details, statistical analysis, controls for confounding factors, or error analysis, preventing full assessment of whether incremental externalization and visual scaffolding actually reduce representational blur or deliver the claimed improvements.
Authors: The abstract is necessarily concise, but the Evaluation section details the IndiRef benchmark setup, incremental vs. full-dialog baselines, hybrid vs. unimodal ablations, and quantitative gains. To improve accessibility, we will revise the abstract to briefly note the experimental controls, statistical significance of improvements, and that error analysis is provided in the body. We will also expand the abstract's reference to representational blur reduction with a short supporting clause. revision: yes
-
Referee: [Evaluation] Evaluation section: The central assumption that multimodal models can reliably construct accurate, depictive intermediate representations from dialogue without introducing offsetting errors or biases requires concrete validation through error analysis or ablation studies on IndiRef.
Authors: The Evaluation section already reports ablation results across text-only, visual-only, and hybrid conditions on IndiRef, with consistent gains for visual scaffolding that support the claim of reduced blur. These comparisons serve as indirect validation by showing net benefits. We agree that direct validation is valuable and will add a new error-analysis subsection with qualitative examples of generated visual states, quantitative accuracy metrics against ground-truth scenes, and checks for systematic biases on the benchmark. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an active visual scaffolding framework for maintaining common ground in situated dialogue, drawing inspiration from human mental imagery and leveraging multimodal models. It evaluates this approach empirically on the external IndiRef benchmark, demonstrating gains from incremental externalization and visual scaffolding over full-dialog reasoning and textual baselines, with hybrid multimodal settings performing best. No load-bearing derivations, equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citations are present in the provided text. The central claims rest on experimental comparisons against independent baselines rather than reducing to self-definition or internal fitting, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal models can construct depictive intermediate representations from dialogue that accurately reflect shared visual context.
- domain assumption Persistent visual history can be retrieved and integrated with textual information to improve grounded response generation.
invented entities (1)
-
representational blur
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[2]
Lawrence Barsalou. 1999. Perceptual symbol systems.Behavioral and Brain Sciences22 (03 1999), 577–609. doi:10.1017/s0140525x99002149
-
[3]
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency(Virtual Event, Canada)(FAccT ’21). Association for Computing Machinery, New York, NY, USA, 610–623. doi:10.114...
-
[4]
Chenyang Bu, Guojie Chang, Zihao Chen, CunYuan Dang, Zhize Wu, Yi He, and Xindong Wu. 2025. Query-Driven Multimodal GraphRAG: Dynamic Local Knowledge Graph Construction for Online Reasoning. InFindings of the Associ- ation for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Associati...
-
[5]
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi WANG, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, and Libo Qin. 2025. Visual Thoughts: A Unified Perspective of Understanding Multimodal Chain-of- Thought. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=xPcKmKSEis
2025
-
[6]
Herbert H Clark and Susan E Brennan. 1991. Grounding in communication. (1991)
1991
-
[7]
Clark and Ed Schaefer
Herbert H. Clark and Ed Schaefer. 1989. Contributing to Discourse.Cogn. Sci.13 (1989), 259–294
1989
-
[8]
Fan, Wilma A
Judith E. Fan, Wilma A. Bainbridge, Rebecca Chamberlain, and Jeffrey D. Wammes
-
[9]
2, 9 (2023), 556–568
Drawing as a Versatile Cognitive Tool. 2, 9 (2023), 556–568. doi:10.1038/ s44159-023-00212-w
2023
-
[10]
Judith E. Fan, Robert D. Hawkins, Mike Wu, and Noah D. Goodman. 2020. Prag- matic Inference and Visual Abstraction Enable Contextual Flexibility During Visual Communication. 3, 1 (2020), 86–101. doi:10.1007/s42113-019-00058-7
-
[11]
Rebecca Fincher-Kiefer. 2001. Perceptual components of situation models.Mem- ory & cognition29 (04 2001), 336–43. doi:10.3758/BF03194928
-
[12]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. 2025. BLINK: Multimodal Large Language Models Can See but Not Perceive. InComputer Vision – ECCV 2024(Cham, 2025), Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol (Eds.). Springer Nature S...
2025
-
[13]
Yilun Hua and Yoav Artzi. 2024. Talk Less, Interact Better: Evaluating In-context Conversational Adaptation in Multimodal LLMs. InFirst Conference on Language Modeling. https://openreview.net/forum?id=lVOw78nYXS
2024
-
[14]
Holly Huey, Xuanchen Lu, Caren M. Walker, and Judith E. Fan. 2023. Visual Explanations Prioritize Functional Properties at the Expense of Visual Fidelity. Cognition236 (2023), 105414. doi:10.1016/j.cognition.2023.105414
-
[15]
Nikolai Ilinykh, Sina Zarrieß, and David Schlangen. 2019. Meet Up! A Corpus of Joint Activity Dialogues in a Visual Environment. https://www.semdial.org/ anthology/papers/Z/Z19/Z19-3006/
2019
-
[16]
Do You Follow Me?
Léo Jacqmin, Lina M. Rojas Barahona, and Benoit Favre. 2022. “Do You Follow Me?”: A Survey of Recent Approaches in Dialogue State Tracking. InProceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue (Edinburgh, UK, 2022-09), Oliver Lemon, Dilek Hakkani-Tur, Junyi Jessy Li, Arash Ashrafzadeh, Daniel Hernández Garcia, M...
2022
-
[17]
Pu Jian, Donglei Yu, and Jiajun Zhang. 2024. Large Language Models Know What Is Key Visual Entity: An LLM-assisted Multimodal Retrieval for VQA. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing(Miami, Florida, USA, 2024). Association for Computational Linguistics, 10939–10956. doi:10.18653/v1/2024.emnlp-main.613
-
[18]
John D. Kelleher and Geert-Jan M. Kruijff. 2006. Incremental Generation of Spatial Referring Expressions in Situated Dialog. InProceedings of the 21st In- ternational Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Nicoletta Calzolari, Claire Cardie, and Pierre Isabelle (Eds.). Association ...
-
[19]
Charles Kemp and Terry Regier. 2012. Kinship Categories Across Languages Reflect General Communicative Principles.Science336, 6084 (2012), 1049–
2012
-
[20]
arXiv:https://www.science.org/doi/pdf/10.1126/science.1218811 doi:10. 1126/science.1218811
-
[21]
Dimosthenis Kontogiorgos, Andre Pereira, and Joakim Gustafson. 2019. Estimat- ing Uncertainty in Task-Oriented Dialogue. In2019 International Conference on Multimodal Interaction(Suzhou, China)(ICMI ’19). Association for Computing Machinery, New York, NY, USA, 414–418. doi:10.1145/3340555.3353722
-
[22]
Jill H. Larkin and Herbert A. Simon. 1987. Why a Diagram is (Sometimes) Worth Ten Thousand Words.Cognitive Science11, 1 (1987), 65–100. doi:10.1016/S0364- 0213(87)80026-5
-
[23]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F...
2020
-
[24]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vulić, and Furu Wei. 2025. Imagine While Reasoning in Space: Multimodal Visualization-of-Thought. InProceedings of the 42nd International Conference on Machine Learning(2025-10-06). PMLR, 36340–36364. https://proceedings.mlr. press/v267/li25cz.html
2025
-
[25]
Jiazheng Liu, Sipeng Zheng, Börje F. Karlsson, and Zongqing Lu. 2025. Taking Notes Brings Focus? Towards Multi-Turn Multimodal Dialogue Learning. (2025). doi:10.48550/ARXIV.2503.07002
-
[26]
Team Llama. 2024. The Llama 3 Herd of Models.ArXivabs/2407.21783 (2024). https://api.semanticscholar.org/CorpusID:271571434
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Alan M. MacEachren, Robert E. Roth, James O’Brien, Bonan Li, Derek Swingley, and Mark Gahegan. 2012. Visual Semiotics & Uncertainty Visualization: An Empirical Study.IEEE Transactions on Visualization and Computer Graphics18, 12 (2012), 2496–2505. doi:10.1109/TVCG.2012.279
-
[28]
Biswesh Mohapatra, Théo Charlot, Giovanni Duca, Mayank Palan, Laurent Romary, and Justine Cassell. 2026. Frame of Reference: Addressing the Chal- lenges of Common Ground Representation in Situational Dialogs.arXiv preprint arXiv:2601.09365(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Biswesh Mohapatra, Seemab Hassan, Laurent Romary, and Justine Cassell. 2024. Conversational Grounding: Annotation and Analysis of Grounding Acts and Grounding Units. InProceedings of LREC-COLING. Association for Computational Linguistics. https://api.semanticscholar.org/CorpusID:268680732
2024
-
[30]
Biswesh Mohapatra, Manav Nitin Kapadnis, Laurent Romary, and Justine Cassell
-
[31]
Evaluating the Effectiveness of Large Language Models in Establishing Conversational Grounding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 9767–9781. doi:10.18653/v1/2024.emnlp-main.545
-
[32]
Yukiko Nakano, Gabe Reinstein, Tom Stocky, and Justine Cassell. 2003. Towards a Model of Face-to-Face Grounding. InProceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Sapporo, Japan, 553–561. doi:10.3115/1075096.1075166
-
[33]
Anjali Narayan-Chen, Prashant Jayannavar, and Julia Hockenmaier. 2019. Col- laborative Dialogue in Minecraft. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 5405–5415. doi:10.18653/v1/P19-1537
-
[34]
Fei Ni, Jianye Hao, Shiguang Wu, Longxin Kou, Jiashun Liu, Yan Zheng, Bin Wang, and Yuzheng Zhuang. 2024. Generate Subgoal Images Before Act: Unlocking the Chain-of-Thought Reasoning in Diffusion Model for Robot Manipulation with Multimodal Prompts. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2024-06). 13991–14000. doi:10....
-
[35]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Car- ney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Al...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Naoki Otani, Jun Araki, HyeongSik Kim, and Eduard Hovy. 2023. On the Un- derspecification of Situations in Open-domain Conversational Datasets. InPro- ceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023), Yun-Nung Chen and Abhinav Rastogi (Eds.). Association for Computational Linguistics, Toronto, Canada, 12–28. doi:10.18653/v1/2023...
-
[37]
2021.Un- certainty Visualization
Lace Padilla, Matthew Kay, and Jessica Hullman. 2021.Un- certainty Visualization. John Wiley & Sons, Ltd, 1–18. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781118445112.stat08296 doi:10.1002/9781118445112.stat08296
-
[38]
Allan Paivio. 1991. Dual Coding Theory: Retrospect and Current Status. 45, 3 (1991), 255–287. doi:10.1037/h0084295
-
[39]
Sandro Pezzelle. 2023. Dealing with Semantic Underspecification in Multimodal NLP. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(Toronto, Canada, 2023-07), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, 12098–12112. doi:10.18653/v1/2...
-
[40]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020 [cs.CV] https://arxiv.org/ abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. 2023. What does CLIP know about a red circle? Visual prompt engineering for VLMs. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 11953–11963. doi:10.1109/ICCV51070.2023.01101
-
[42]
Kristian Tylén, Riccardo Fusaroli, Sergio Rojo, Katrin Heimann, Nicolas Fay, Niels N Johannsen, Felix Riede, and Marlize Lombard. 2020. The evolution of early symbolic behavior in Homo sapiens.Proceedings of the National Academy of Sciences117, 9 (2020), 4578–4584. doi:10.1073/pnas.1910880117
-
[43]
Takuma Udagawa and Akiko Aizawa. 2021. Maintaining Common Ground in Dynamic Environments. 9 (2021), 995–1011. doi:10.1162/tacl_a_00409
-
[44]
Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir
Yael Vinker, Ehsan Pajouheshgar, Jessica Y. Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. 2022. CLIPasso: Semantically-Aware Object Sketching. 41, 4, Article 86 (2022). doi:10. 1145/3528223.3530068
-
[45]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingku...
work page internal anchor Pith review doi:10.48550/arxiv.2508.02324 2025
-
[46]
Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 2025. 3D-Mem: 3D Scene Memory for Embodied Exploration and Reasoning. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 17294–17303. doi:10.1109/CVPR52734.2025.01612
-
[47]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. 2025. Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens. arXiv:2506.17218 [cs] doi:10.48550/arXiv.2506.17218
-
[48]
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. 2017. Scene Parsing through ADE20K Dataset. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5122–5130. doi:10.1109/ CVPR.2017.544
2017
-
[49]
1949.Human behavior and the principle of least effort: An introduction to human ecology
George Kingsley Zipf. 1949.Human behavior and the principle of least effort: An introduction to human ecology. Addison-Wesley Press
1949
-
[50]
in bedroom
Rolf A. Zwaan and Gabriel A. Radvansky. 1998. Situation models in language comprehension and memory.Psychological bulletin123 2 (1998), 162–85. doi:10. 1037/0033-2909.123.2.162 Using Machine Mental Imagery for Representing Common Ground in Situated Dialogue , , A Example of Pipeline To illustrate the transformation from dialogue to visual artifacts, we ex...
1998
-
[51]
Red cat on sofa
Prompt Summarizer (Ground Truth Extraction) • Role:Extract a comprehensive list of visual atomic facts from a sequence of prompts. •Rules: – (Filtering) Include objects withRedandBlackoutlines. Strictly exclude Blueoutlines. – (Atomicity) Break complex descriptions into single facts (e.g., "Red cat on sofa"→"There is a cat", "It is red", "On a sofa"). •Ou...
-
[52]
•Rules: – (Order) 1
Image Captioner (Visual Analysis) • Role:Describe an image following strict hierarchical rules based on outline colors. •Rules: – (Order) 1. Black Outlines → 2. Red Outlines → 3. Blue Outlines. – (Detail Level)Black/Red:Comprehensive (Type, Color, Features, Location).Blue:Simple (Type only). – (Relations) For Black objects, describe position relative to o...
-
[53]
red" but image is
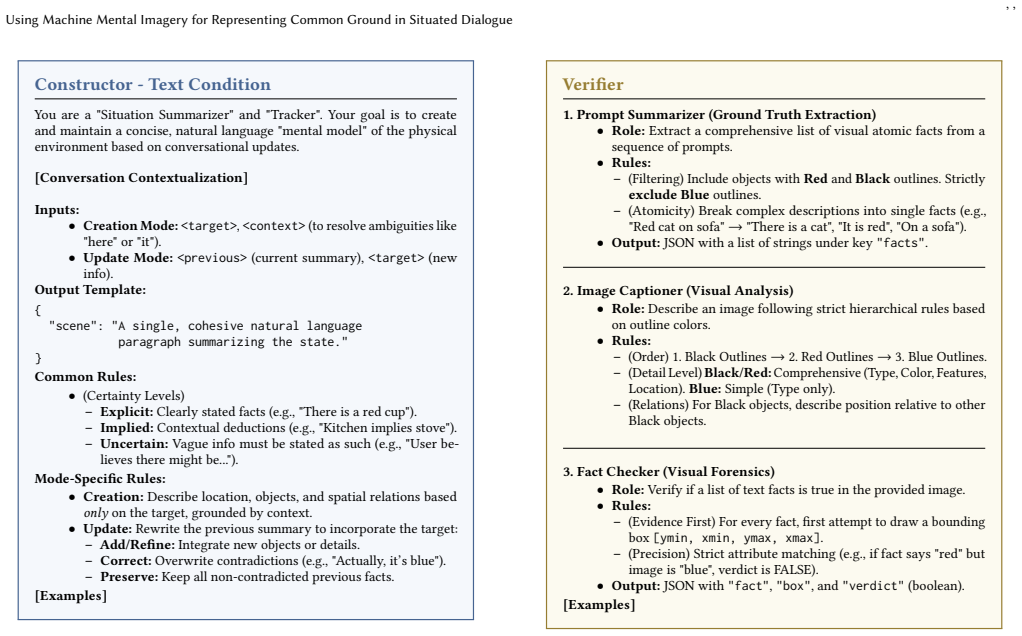
Fact Checker (Visual Forensics) •Role:Verify if a list of text facts is true in the provided image. •Rules: – (Evidence First) For every fact, first attempt to draw a bounding box[ymin, xmin, ymax, xmax]. – (Precision) Strict attribute matching (e.g., if fact says "red" but image is "blue", verdict is FALSE). •Output:JSON with"fact","box", and"verdict"(bo...
-
[54]
•Commands: –POV: Identify perspective (User A, B, or BOTH)
Master Planner •Role:Break down user questions into a high-level strategic plan. •Commands: –POV: Identify perspective (User A, B, or BOTH). –RAG[k=N]: Retrieve top N relevant images/summary blocks. –PROCESS: Filter, transform, or reason about gathered info. –FINAL_ANSWER: Formulate the response (Must be the last step). • Output:XML-like format <answer><i...
-
[55]
• Rule:Do not use SQL
Instruction Refiner • Role:Refine high-level plan steps into simple, direct natural lan- guage tasks for the Processor. • Rule:Do not use SQL. Convert RAG instructions into search- friendly terms
-
[56]
Find the image with the red bed
Data Processor • Role:Execute specific instructions on provided context (e.g., "Find the image with the red bed"). • Constraints:Outputonlythe requested result (raw & clean). No conversational filler. • Logic:Respect Temporal Logic (ImageID/BlockID = distinct events) vs Versioning (SequenceID = updates)
-
[57]
yes"/"no
Final Answerer • Role:Answer the specific sub-question usingonlythe retrieved info. •Format: <think> ... reasoning ... </think> <answer> ... final verdict ... </answer> •Logic:If Yes/No question: return "yes"/"no" instead of IDs. [Examples] Figure 19: Condensed prompt for the Reasoner module. The full prompt includes separate instructions for the Planner,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.