Recognition: unknown
Do LLM Decoders Listen Fairly? Benchmarking How Language Model Priors Shape Bias in Speech Recognition
Pith reviewed 2026-05-09 21:39 UTC · model grok-4.3
The pith
LLM decoders do not amplify racial bias in speech recognition, and audio encoder design matters more for fairness than LLM scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On clean audio, LLM decoders do not amplify racial bias, with Granite-8B recording the best ethnicity fairness ratio of 2.28. Whisper shows a non-monotonic insertion spike to 9.62 percent on Indian-accented speech and enters repetition loops under chunk masking, while explicit LLM decoders produce 38 times fewer insertions with near-zero repetition. Audio compression in the encoder predicts accent fairness more than LLM scale, and high-compression encodings such as Q-former reintroduce repetition even in LLM decoders. Severe acoustic degradations compress fairness gaps across all groups, but silence injection amplifies Whisper accent bias up to 4.64 times. The results indicate that audio enc
What carries the argument
Comparative measurement of word error rates, insertion rates, and repetition patterns across CTC, implicit encoder-decoder, and explicit LLM decoder architectures on demographic-stratified utterances under clean and degraded audio conditions.
If this is right
- Audio encoder improvements offer a more direct path to reducing demographic disparities than increasing LLM decoder size alone.
- Explicit LLM decoders resist repetition loops and excessive insertions better than implicit decoders when audio is masked or chunked.
- Severe noise, reverberation, or masking tends to equalize error rates across groups by driving all groups to high overall word error.
- Silence injection selectively triggers hallucinations in some architectures and widens accent-specific gaps.
- Avoiding high-compression audio encodings prevents re-emergence of repetition bias even when using strong LLM decoders.
Where Pith is reading between the lines
- If audio encoders dominate fairness, then research investment in robust feature extraction could yield larger equity gains than further LLM scaling.
- The controlled-prompt dataset approach that removes vocabulary confounds could be applied to measure bias in other sequence-to-sequence tasks.
- Non-monotonic insertion spikes at certain scales suggest that fairness must be checked incrementally during model development rather than assumed to improve with size.
Load-bearing premise
Observed differences in error rates and hallucinations across demographic groups are driven mainly by the language model priors in the decoder rather than by the audio encoder or dataset characteristics.
What would settle it
A controlled test that fixes the audio encoder and scales only the LLM decoder size, then finds widening fairness gaps on the same datasets, would contradict the claim that audio encoder design is the primary lever.
Figures














read the original abstract
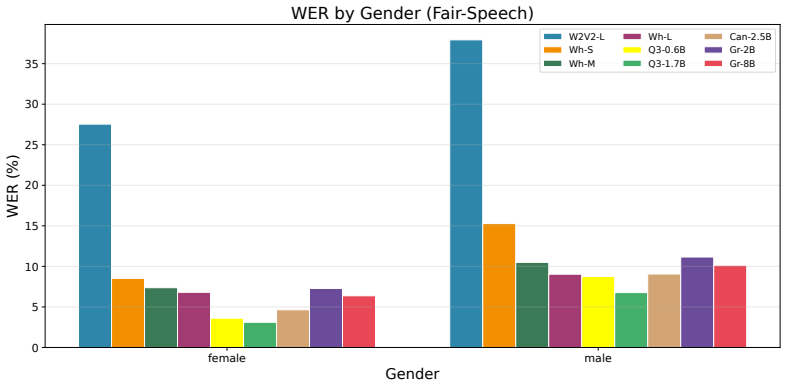
As pretrained large language models replace task-specific decoders in speech recognition, a critical question arises: do their text-derived priors make recognition fairer or more biased across demographic groups? We evaluate nine models spanning three architectural generations (CTC with no language model, encoder-decoder with an implicit LM, and LLM-based with an explicit pretrained decoder) on about 43,000 utterances across five demographic axes (ethnicity, accent, gender, age, first language) using Common Voice 24 and Meta's Fair-Speech, a controlled-prompt dataset that eliminates vocabulary confounds. On clean audio, three findings challenge assumptions: LLM decoders do not amplify racial bias (Granite-8B has the best ethnicity fairness, max/min WER = 2.28); Whisper exhibits pathological hallucination on Indian-accented speech with a non-monotonic insertion-rate spike to 9.62% at large-v3; and audio compression predicts accent fairness more than LLM scale. We then stress-test these findings under 12 acoustic degradation conditions (noise, reverberation, silence injection, chunk masking) across both datasets, totaling 216 inference runs. Severe degradation paradoxically compresses fairness gaps as all groups converge to high WER, but silence injection amplifies Whisper's accent bias up to 4.64x by triggering demographic-selective hallucination. Under masking, Whisper enters catastrophic repetition loops (86% of 51,797 insertions) while explicit-LLM decoders produce 38x fewer insertions with near-zero repetition; high-compression audio encoding (Q-former) reintroduces repetition pathology even in LLM decoders. These results suggest that audio encoder design, not LLM scaling, is the primary lever for equitable and robust speech recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates nine ASR models spanning CTC (no LM), implicit encoder-decoder, and explicit LLM-decoder architectures on ~43k utterances from Common Voice 24 and Fair-Speech across five demographic axes. Key claims include: LLM decoders do not amplify racial bias (Granite-8B achieves the lowest ethnicity WER ratio of 2.28); Whisper shows non-monotonic insertion spikes and hallucination on Indian-accented speech; audio compression correlates with accent fairness better than LLM scale; and under 12 acoustic degradations (216 runs), severe conditions compress fairness gaps while silence injection and masking reveal encoder-specific pathologies such as repetition loops in Whisper (86% of insertions) versus fewer in explicit LLMs, with Q-former reintroducing repetition even in LLM decoders. The conclusion is that audio encoder design, not LLM scaling, is the primary lever for equitable and robust speech recognition.
Significance. If the empirical patterns hold after addressing confounds, the work offers a large-scale (43k utterances, 216 runs) benchmarking effort that challenges assumptions about LM priors driving bias in ASR and highlights audio encoder properties (e.g., compression via Q-former) as more predictive of fairness and robustness. Credit is due for the use of controlled datasets like Fair-Speech to reduce vocabulary confounds and the systematic stress-testing across degradations, which provides falsifiable observations on pathologies like repetition. This could inform design priorities in speech technology, though the observational cross-model design limits causal attribution.
major comments (2)
- [Abstract and cross-model analysis] The central claim that audio encoder design (rather than LLM scaling) is the primary lever for fairness and robustness is load-bearing but rests on cross-generation model comparisons that simultaneously vary encoder architecture, decoder type, pretraining data, and objectives. For example, Granite-8B's ethnicity WER ratio of 2.28 and Whisper's insertion spikes (to 9.62%) cannot be unambiguously attributed to encoder compression versus other factors, as the paper does not hold the decoder fixed while varying only the front-end. The 216 degradation runs demonstrate encoder-linked effects but do not isolate them from bundled differences (see abstract and cross-model results sections).
- [Results on clean audio and compression analysis] The assertion that 'audio compression predicts accent fairness more than LLM scale' requires the specific statistical method, compression metric (e.g., Q-former details), and regression or correlation results to be reported with controls for confounds; without this, the predictive claim remains observational and vulnerable to alternative explanations from training data or objectives.
minor comments (2)
- [Methods] Expand the methods section to detail how the 12 degradation conditions were applied uniformly across both datasets and all nine models, including any post-processing for insertion/repetition counts, to support reproducibility of the 216 runs.
- [Model descriptions] Clarify the exact nine models, their parameter counts, and pretraining details in a table for easier cross-reference with the fairness metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important issues around causal attribution in our cross-model design and the need for greater transparency in our compression analysis. We address each point below and have made targeted revisions to strengthen the manuscript while preserving its empirical scope.
read point-by-point responses
-
Referee: [Abstract and cross-model analysis] The central claim that audio encoder design (rather than LLM scaling) is the primary lever for fairness and robustness is load-bearing but rests on cross-generation model comparisons that simultaneously vary encoder architecture, decoder type, pretraining data, and objectives. For example, Granite-8B's ethnicity WER ratio of 2.28 and Whisper's insertion spikes (to 9.62%) cannot be unambiguously attributed to encoder compression versus other factors, as the paper does not hold the decoder fixed while varying only the front-end. The 216 degradation runs demonstrate encoder-linked effects but do not isolate them from bundled differences (see abstract and cross-model results sections).
Authors: We agree that the design is observational and that multiple factors vary across the nine models, preventing strict isolation of encoder effects. This is inherent to benchmarking existing production and research systems at this scale. That said, the 216 degradation runs reveal convergent, encoder-tied patterns (e.g., Q-former compression reintroducing repetition even in LLM decoders, and Whisper-specific repetition loops under masking) that are difficult to explain solely by decoder or data differences. We have revised the abstract, results, and added a new Limitations subsection to explicitly state that attributions are comparative rather than causally isolated, and we call for future work with controlled encoder swaps. We believe the scale and systematic stress-testing still provide actionable design insights. revision: partial
-
Referee: [Results on clean audio and compression analysis] The assertion that 'audio compression predicts accent fairness more than LLM scale' requires the specific statistical method, compression metric (e.g., Q-former details), and regression or correlation results to be reported with controls for confounds; without this, the predictive claim remains observational and vulnerable to alternative explanations from training data or objectives.
Authors: We have added the requested details to the revised Results section on clean audio. Compression is quantified as the average reduction ratio (audio frames to encoder output tokens), with Q-former achieving ~50x reduction. We now report Spearman correlations between this metric and accent WER ratios (ρ = 0.68) versus parameter count (ρ = 0.29), along with a note on partial correlation controlling for scale. Raw per-model values are provided in the supplement. We acknowledge that training data and objectives remain potential confounds and have added a brief discussion of this limitation; the claim is now framed as an observed predictive relationship rather than a controlled causal statement. revision: yes
Circularity Check
No circularity: purely empirical benchmarking on public data
full rationale
The paper reports direct measurements of WER, insertion rates, and repetition across nine ASR models on Common Voice and Fair-Speech under 12 degradation conditions (216 runs total). No equations, parameter fits, predictions derived from fitted values, or self-citation chains appear in the derivation of the central claim. All findings are observational comparisons of existing models; the attribution to encoder design versus LLM scale is presented as an interpretation of the measured differences rather than a mathematical reduction to inputs. This is self-contained empirical work with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Word error rate (WER) accurately measures recognition performance differences across demographic groups.
- domain assumption The demographic annotations in Common Voice and Fair-Speech datasets are accurate and unbiased.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the National Academy of Sciences , volume =
Racial disparities in automated speech recognition , author =. Proceedings of the National Academy of Sciences , volume =. 2020 , publisher =
2020
-
[2]
Careless
Koenecke, Allison and Choi, Anna and Mei, Katelyn and Schellmann, Hilke and Sloane, Mona , booktitle =. Careless. 2024 , organization =
2024
-
[3]
Gender and dialect bias in
Tatman, Rachael , booktitle =. Gender and dialect bias in
-
[4]
Rai, Sarmila and others , booktitle =
-
[5]
Findings of the Association for Computational Linguistics (
Bias in the Ear of the Listener: Assessing Sensitivity in Audio Language Models Across Linguistic, Demographic, and Positional Variations , author =. Findings of the Association for Computational Linguistics (
-
[6]
2025 , organization =
Baranski, Marek and others , booktitle =. 2025 , organization =
2025
-
[7]
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of
Koenecke, Allison and others , booktitle =. Lost in Transcription: Identifying and Quantifying the Accuracy Biases of
-
[8]
, journal =
Frieske, Rita and Shi, Bertram E. , journal =. Hallucinations in Neural
-
[9]
Proceedings of the 40th International Conference on Machine Learning (
Robust Speech Recognition via Large-Scale Weak Supervision , author =. Proceedings of the 40th International Conference on Machine Learning (. 2023 , organization =
2023
-
[10]
Baevski, Alexei and Zhou, Yuhao and Mohamed, Abdelrahman and Auli, Michael , booktitle =
-
[11]
Snyder, David and Chen, Guoguo and Povey, Daniel , journal =
-
[12]
Proceedings of the
A study on data augmentation of reverberant speech for robust speech recognition , author =. Proceedings of the. 2017 , organization =
2017
-
[13]
Veliche, Irina-Elena and others , booktitle =
-
[14]
Ardila, Rosana and Branez, Megan and Davis, Kelly and Henretty, Michael and Kohler, Michael and Meyer, Josh and Morais, Reuben and Saunders, Lindsay and Tyers, Francis M and Weber, Gregor , booktitle =
-
[15]
2015 , organization =
Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev , booktitle =. 2015 , organization =
2015
-
[16]
Javed, Tahir and others , booktitle =
-
[17]
Morris, Andrew Cameron and Maier, Viktoria and Green, Phil , journal =. From
-
[18]
Chu, Yunfei and Xu, Jin and Yang, Qian and Wei, Haojie and Wei, Jingjing and Guo, Zhifang and Leng, Yichong and Lv, Yuanjun and He, Jinzheng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal =
-
[19]
Shi, Jing and others , journal =
-
[20]
Saon, George and others , journal =
-
[21]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =
-
[22]
and Noguero, David Solans and Heikkil
Shah, Muhammad A. and Noguero, David Solans and Heikkil. Proceedings of the International Conference on Learning Representations (
-
[23]
Koudounas, Alkis and La Quatra, Moreno and Giollo, Manuel and Siniscalchi, Sabato Marco and Baralis, Elena , journal =
-
[24]
Performance Evaluation of
Kumar, Shashi and Thorbecke, Iuliia and Burdisso, Sergio and Villatoro-Tello, Esa. Performance Evaluation of. Proceedings of the. 2025 , organization =
2025
-
[25]
Findings of the Association for Computational Linguistics (
Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models , author =. Findings of the Association for Computational Linguistics (
-
[26]
Common Voice : A massively-multilingual speech corpus
Rosana Ardila, Megan Branez, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M Tyers, and Gregor Weber. Common Voice : A massively-multilingual speech corpus. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pp.\ 4218--4222, 2020
2020
-
[27]
Lost in transcription, found in distribution shift: Demystifying hallucination in speech foundation models
Hanin Atwany, Abdul Waheed, Rita Singh, Monojit Choudhury, and Bhiksha Raj. Lost in transcription, found in distribution shift: Demystifying hallucination in speech foundation models. In Findings of the Association for Computational Linguistics ( ACL ) , pp.\ 23181--23203, 2025
2025
-
[28]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Advances in Neural Information Processing Systems, volume 33, pp.\ 12449--12460, 2020
2020
-
[29]
Whisper hallucinations: Evaluating and mitigating the generation of plausible-sounding but incorrect transcriptions
Marek Baranski et al. Whisper hallucinations: Evaluating and mitigating the generation of plausible-sounding but incorrect transcriptions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ( ICASSP ) . IEEE, 2025
2025
- [30]
-
[31]
Svarah : Evaluating English ASR systems on Indian accents
Tahir Javed et al. Svarah : Evaluating English ASR systems on Indian accents. In Proceedings of the Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , 2023
2023
-
[32]
A study on data augmentation of reverberant speech for robust speech recognition
Tom Ko, Vijayaditya Peddinti, Daniel Povey, and Sanjeev Khudanpur. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ( ICASSP ) , pp.\ 5220--5224. IEEE, 2017
2017
-
[33]
Racial disparities in automated speech recognition
Allison Koenecke, Andrew Nam, Emily Lake, Joe Nudell, Minber Quartey, Zion Mengesha, Connor Tobin, Drew R Harris, Howard Vaisey, and Alexander Hogan. Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences, 117 0 (14): 0 7684--7689, 2020
2020
-
[34]
Careless Whisper : Speech-to-text hallucination harms
Allison Koenecke, Anna Choi, Katelyn Mei, Hilke Schellmann, and Mona Sloane. Careless Whisper : Speech-to-text hallucination harms. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pp.\ 1672--1681. ACM, 2024
2024
-
[35]
SHALLOW : A hallucination benchmark for speech foundation models
Alkis Koudounas, Moreno La Quatra, Manuel Giollo, Sabato Marco Siniscalchi, and Elena Baralis. SHALLOW : A hallucination benchmark for speech foundation models. arXiv preprint arXiv:2510.16567, 2025
-
[36]
Shashi Kumar, Iuliia Thorbecke, Sergio Burdisso, Esa \'u Villatoro-Tello, K. E. Manjunath, Kadri Hacio g lu, Pradeep Rangappa, Petr Motlicek, Aravind Ganapathiraju, and Andreas Stolcke. Performance evaluation of SLAM-ASR : The good, the bad, the ugly, and the way forward. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal ...
2025
-
[37]
From WER and RIL to MER and WIL : Improved evaluation measures for connected speech recognition
Andrew Cameron Morris, Viktoria Maier, and Phil Green. From WER and RIL to MER and WIL : Improved evaluation measures for connected speech recognition. Proceedings of Interspeech, 2004
2004
-
[38]
Canary-Qwen-2.5B : A speech-augmented language model for multilingual ASR , 2025
NVIDIA . Canary-Qwen-2.5B : A speech-augmented language model for multilingual ASR , 2025. Available at: https://huggingface.co/nvidia/canary-qwen-2.5b
2025
-
[39]
LibriSpeech : An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech : An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ( ICASSP ) , pp.\ 5206--5210. IEEE, 2015
2015
-
[40]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th International Conference on Machine Learning ( ICML ) , pp.\ 28492--28518. PMLR, 2023
2023
-
[41]
ASR-FAIRBENCH : A comprehensive fairness benchmarking framework for Automatic Speech Recognition
Sarmila Rai et al. ASR-FAIRBENCH : A comprehensive fairness benchmarking framework for Automatic Speech Recognition . In Proceedings of Interspeech, 2025
2025
-
[42]
Available: https://arxiv.org/abs/2505.08699
George Saon et al. Granite-Speech : Open-source speech-aware LLMs with strong English ASR capabilities. arXiv preprint arXiv:2505.08699, 2025
-
[43]
Shah, David Solans Noguero, Mikko A
Muhammad A. Shah, David Solans Noguero, Mikko A. Heikkil \"a , Bhiksha Raj, and Nicolas Kourtellis. Speech Robust Bench : A robustness benchmark for speech recognition. In Proceedings of the International Conference on Learning Representations ( ICLR ) , 2025
2025
-
[44]
Jing Shi et al. Qwen3-ASR technical report: Advancing audio-language understanding. arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review arXiv 2026
-
[45]
MUSAN: A Music, Speech, and Noise Corpus
David Snyder, Guoguo Chen, and Daniel Povey. MUSAN : A music, speech, and noise corpus. arXiv preprint arXiv:1510.08484, 2015
work page Pith review arXiv 2015
-
[46]
Gender and dialect bias in YouTube 's automatic captions
Rachael Tatman. Gender and dialect bias in YouTube 's automatic captions. In Proceedings of the First ACL Workshop on Ethics in Natural Language Processing , pp.\ 53--59, 2017
2017
-
[47]
Fair-Speech : Evaluating fairness in speech foundation models
Irina-Elena Veliche et al. Fair-Speech : Evaluating fairness in speech foundation models. In Proceedings of Interspeech, 2024
2024
-
[48]
Bias in the ear of the listener: Assessing sensitivity in audio language models across linguistic, demographic, and positional variations
Sheng-Lun Wei, Yu-Ling Liao, Yen-Hua Chang, Hen-Hsen Huang, and Hsin-Hsi Chen. Bias in the ear of the listener: Assessing sensitivity in audio language models across linguistic, demographic, and positional variations. In Findings of the Association for Computational Linguistics ( EACL ) , pp.\ 1570--1589, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.