Recognition: unknown
Trust-SSL: Additive-Residual Selective Invariance for Robust Aerial Self-Supervised Learning
Pith reviewed 2026-05-09 23:00 UTC · model grok-4.3
The pith
By adding per-sample trust weights as an additive residual to the contrastive loss with stop-gradient, Trust-SSL selectively enforces invariance only on reliable views to improve robustness in aerial self-supervised learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an additive-residual formulation of selective invariance, using a per-sample per-factor trust weight with stop-gradient applied to the weight, produces more robust representations than standard invariance enforcement or multiplicative gating when training on aerial imagery that contains haze, blur, rain, and occlusion.
What carries the argument
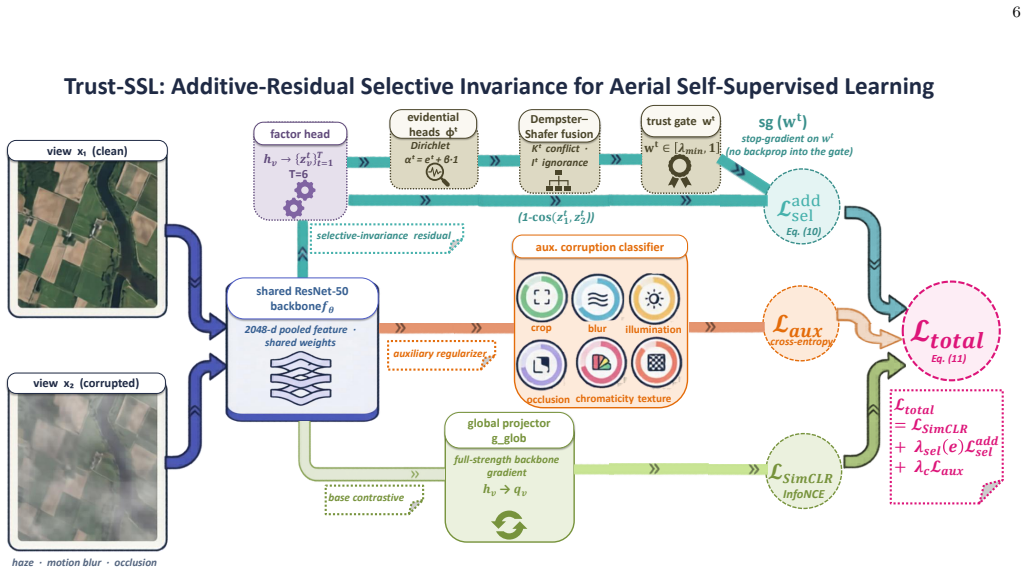
The additive-residual selective invariance mechanism: a trust weight computed per sample and per corruption factor is added to the base contrastive loss after a stop-gradient is applied to the weight, allowing down-weighting of unreliable alignments without impairing the backbone network.
If this is right
- The method records the highest mean linear-probe accuracy across six backbones on EuroSAT, AID, and NWPU-RESISC45.
- It produces the largest gains under severe information-erasing corruptions, including a 19.9-point improvement over SimCLR on EuroSAT haze at severity 5.
- Zero-shot cross-domain AUROC on BDD100K weather splits improves by 1 to 3 points.
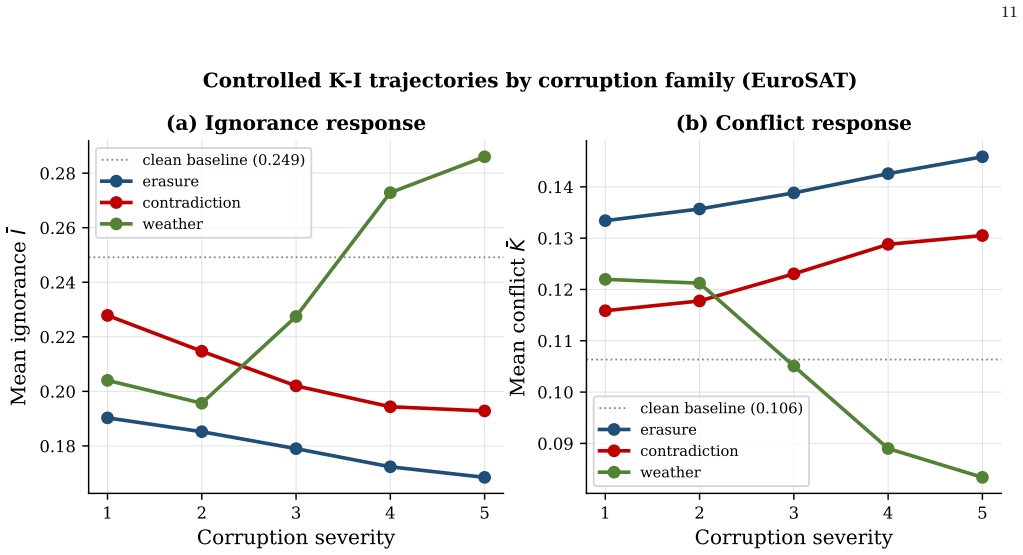
- An evidential variant using Dempster-Shafer fusion supplies interpretable signals of conflict and ignorance.
- Ablations isolating scalar uncertainty and cosine gating confirm that the additive-residual form is the main source of the gains.
Where Pith is reading between the lines
- The same additive-residual principle could be tested on non-contrastive SSL objectives such as VICReg or BYOL to check whether the benefit generalizes beyond contrastive losses.
- If trust weights can be derived from image statistics alone, the method might reduce reliance on hand-crafted augmentation pipelines in other noisy domains such as medical or satellite video.
- A natural extension would be to make the trust-weight computation differentiable and learned jointly with the backbone rather than pre-computed from data statistics.
- The observed robustness to information-erasing corruptions suggests the approach may also help in settings where labels are sparse or where domain shift arises from sensor differences.
Load-bearing premise
The per-sample per-factor trust weights can be computed reliably from the data without introducing new biases or instabilities.
What would settle it
Replace the learned trust weights with random values between 0 and 1 during training and check whether linear-probe accuracy on EuroSAT under haze corruption at severity 5 falls below the SimCLR baseline.
Figures




read the original abstract
Self-supervised learning (SSL) is a standard approach for representation learning in aerial imagery. Existing methods enforce invariance between augmented views, which works well when augmentations preserve semantic content. However, aerial images are frequently degraded by haze, motion blur, rain, and occlusion that remove critical evidence. Enforcing alignment between a clean and a severely degraded view can introduce spurious structure into the latent space. This study proposes a training strategy and architectural modification to enhance SSL robustness to such corruptions. It introduces a per-sample, per-factor trust weight into the alignment objective, combined with the base contrastive loss as an additive residual. A stop-gradient is applied to the trust weight instead of a multiplicative gate. While a multiplicative gate is a natural choice, experiments show it impairs the backbone, whereas our additive-residual approach improves it. Using a 200-epoch protocol on a 210,000-image corpus, the method achieves the highest mean linear-probe accuracy among six backbones on EuroSAT, AID, and NWPU-RESISC45 (90.20% compared to 88.46% for SimCLR and 89.82% for VICReg). It yields the largest improvements under severe information-erasing corruptions on EuroSAT (+19.9 points on haze at s=5 over SimCLR). The method also demonstrates consistent gains of +1 to +3 points in Mahalanobis AUROC on a zero-shot cross-domain stress test using BDD100K weather splits. Two ablations (scalar uncertainty and cosine gate) indicate the additive-residual formulation is the primary source of these improvements. An evidential variant using Dempster-Shafer fusion introduces interpretable signals of conflict and ignorance. These findings offer a concrete design principle for uncertainty-aware SSL. Code is publicly available at https://github.com/WadiiBoulila/trust-ssl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Trust-SSL, a modification to self-supervised contrastive learning for aerial imagery. It augments the alignment objective with a per-sample, per-factor trust weight computed from the data, combined additively with the base loss (rather than multiplicatively) and with a stop-gradient on the weight. The approach aims to avoid enforcing invariance between clean and severely degraded views (haze, blur, rain, occlusion). On a 210k-image corpus trained for 200 epochs, it reports the highest mean linear-probe accuracy across EuroSAT, AID, and NWPU-RESISC45 (90.20 % vs. 88.46 % SimCLR, 89.82 % VICReg) and the largest gains under severe corruptions (+19.9 points on EuroSAT haze at severity 5). Additional support comes from two ablations isolating the additive-residual form, cross-domain zero-shot Mahalanobis AUROC gains on BDD100K weather splits, and an evidential Dempster-Shafer variant. Public code is provided.
Significance. If the empirical results hold, the work supplies a concrete, reproducible design principle for uncertainty-aware SSL that improves robustness to real-world information-erasing degradations common in aerial data. Credit is due for the consistent gains across three standard benchmarks, the targeted corruption protocol, the cross-domain stress test, the isolation of the additive-residual component via ablations, and the release of code that enables verification. The approach could usefully inform subsequent SSL methods that must handle unreliable views without destabilizing backbone training.
major comments (1)
- [Ablation studies and corruption robustness experiments] The central interpretation that the trust weights implement 'selective invariance' by down-weighting semantically erased views rests on an untested assumption. No quantitative check is reported that the estimated per-sample, per-factor weights correlate with information-loss metrics (PSNR, SSIM, or semantic content measures) on the corrupted EuroSAT splits, nor is there a control experiment showing that random or constant weights would not produce comparable deltas. Without such evidence the +19.9-point corruption gain could arise from incidental regularization or variance reduction rather than the claimed selective mechanism; this directly affects the security of the design principle.
minor comments (2)
- [Abstract and method description] The abstract states that an evidential variant using Dempster-Shafer fusion 'introduces interpretable signals of conflict and ignorance,' yet the main text provides only a brief mention; a dedicated subsection with quantitative results and qualitative examples would strengthen the contribution.
- [Method] Notation for the trust weight (its exact functional form, any learned parameters, and the stop-gradient placement) should be presented with a single equation block early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work and the constructive major comment. We address the point on ablation studies and corruption robustness experiments below.
read point-by-point responses
-
Referee: The central interpretation that the trust weights implement 'selective invariance' by down-weighting semantically erased views rests on an untested assumption. No quantitative check is reported that the estimated per-sample, per-factor weights correlate with information-loss metrics (PSNR, SSIM, or semantic content measures) on the corrupted EuroSAT splits, nor is there a control experiment showing that random or constant weights would not produce comparable deltas. Without such evidence the +19.9-point corruption gain could arise from incidental regularization or variance reduction rather than the claimed selective mechanism; this directly affects the security of the design principle.
Authors: We agree that stronger direct evidence for the selective mechanism would increase confidence in the interpretation. The manuscript already reports two ablations (scalar uncertainty and cosine gate) that isolate the additive-residual formulation as the primary driver of gains, showing that other uncertainty-handling variants do not reproduce the same improvements. However, we did not include an explicit correlation analysis of the learned trust weights against information-loss metrics (PSNR, SSIM, or semantic content) on the corrupted EuroSAT splits, nor a random/constant-weight control experiment. In the revised manuscript we will add both: (1) quantitative correlation plots and statistics between per-sample, per-factor trust weights and PSNR/SSIM/semantic measures across the haze, blur, rain, and occlusion severity levels; (2) a control where learned weights are replaced by random or constant values to verify that the observed deltas (including the +19.9-point gain) are not explained by generic regularization. These additions will directly test the selective-invariance claim. revision: yes
Circularity Check
No significant circularity; empirical method with held-out validation.
full rationale
The paper introduces a trust-weighted additive-residual SSL objective and validates it via linear-probe accuracy on held-out splits of EuroSAT, AID, and NWPU-RESISC45 plus corruption benchmarks. Performance deltas are measured on external test data and do not reduce by the paper's own equations or definitions to quantities fitted inside the training loop. No self-definitional loops, fitted inputs renamed as predictions, load-bearing self-citations, or ansatzes smuggled via prior work appear in the derivation. The central design choice (additive residual with stop-gradient) is justified by ablation experiments rather than by construction or uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Enforcing invariance between augmented views improves representation quality when views preserve semantic content
- ad hoc to paper A per-sample per-factor trust weight can be computed to indicate view reliability without harming backbone training
invented entities (1)
-
trust weight
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised remote sensing feature learning: Learning paradigms, challenges, and future works,
C. Tao, J. Qi, M. Guo, Q. Zhu, and H. Li, “Self-supervised remote sensing feature learning: Learning paradigms, challenges, and future works,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–26, 2023
2023
-
[2]
Self-supervised pre-training for large-scale crop mapping using sentinel-2 time series,
Y. Xu, Y. Ma, and Z. Zhang, “Self-supervised pre-training for large-scale crop mapping using sentinel-2 time series,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 207, pp. 312–325, 2024
2024
-
[3]
Sdcluster: A clustering based self-supervised pre-training method for semantic segmentation of remote sensing images,
H. Xu, C. Zhang, P. Yue, and K. Wang, “Sdcluster: A clustering based self-supervised pre-training method for semantic segmentation of remote sensing images,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 223, pp. 1–14, 2025
2025
-
[4]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. E. Hinton, “A simple framework for contrastive learning of visual representations,” inProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, ser. Proceedings of Machine Learning Research. PMLR, 2020, pp. 1597–1607. [Online]. Available: http://proceedings.ml...
2020
-
[5]
Bootstrap your own latent - A new approach to self-supervised learning,
J. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. Á. Pires, Z. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, “Bootstrap your own latent - A new approach to self-supervised learning,” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems...
2020
-
[6]
Exploring simple siamese representation learning,
X. Chen and K. He, “Exploring simple siamese representation learning,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, 2021, pp. 15750–15758. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2021/html/Chen_Exploring_Simple_ Siamese_Representation_Learning_...
2021
-
[7]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds. PMLR, 2021, pp. 12310–12320. [Online]. Availab...
2021
-
[8]
Vicreg: Variance-invariance-covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y. LeCun, “Vicreg: Variance-invariance-covariance regularization for self-supervised learning,” inThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. [Online]. Available: https://openreview.net/forum?id=xm6YD62D1Ub
2022
-
[9]
What makes for good views for contrastive learning?
Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning?” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020...
2020
-
[10]
Hyperdehazing: A hyperspectral image dehazing benchmark dataset and a deep learning model for haze removal,
H. Fu, Z. Ling, G. Sun, J. Ren, A. Zhang, L. Zhang, and X. Jia, “Hyperdehazing: A hyperspectral image dehazing benchmark dataset and a deep learning model for haze removal,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 218, pp. 663–677, 2024
2024
-
[11]
Spatial–frequency dual-domain feature fusion network for low-light remote sensing image enhancement,
Z. Yao, G. Fan, J. Fan, M. Gan, and C. P. Chen, “Spatial–frequency dual-domain feature fusion network for low-light remote sensing image enhancement,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
2024
-
[12]
Benchmarking neural network robustness to common corruptions and perturbations,
D. Hendrycks and T. G. Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,” in7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. [Online]. Available: https://openreview.net/forum?id=HJz6tiCqYm
2019
-
[13]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, ser. JMLR Workshop and Conference Proceedings, M. Balcan and K. Q. Weinberger, Eds. JMLR.org, 2016, pp. 1050–1059. [O...
2016
-
[14]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” inAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V...
2017
-
[15]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks,
K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” inAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman...
2018
-
[16]
A mathematical theory of evidence turns 40,
G. Shafer, “A mathematical theory of evidence turns 40,”Int. J. Approx. Reason., vol. 79, pp. 7–25, 2016. [Online]. Available: https://doi.org/10.1016/j.ijar.2016.07.009
-
[17]
A generalization of bayesian inference,
A. P. Dempster, “A generalization of bayesian inference,” inClassic Works of the Dempster-Shafer Theory of Belief Functions, 1968. [Online]. Available: https://api.semanticscholar.org/CorpusID:44440896
1968
-
[18]
Jøsang,Subjective Logic - A Formalism for Reasoning Under Uncertainty, ser
A. Jøsang,Subjective Logic - A Formalism for Reasoning Under Uncertainty, ser. Artificial Intelligence: Foundations, Theory, and Algorithms. Springer, 2016. [Online]. Available: https://doi.org/10.1007/978-3-319-42337-1 17
-
[19]
Factorized contrastive learning: Going beyond multi-view redundancy,
P. P. Liang, Z. Deng, M. Q. Ma, J. Y. Zou, L. Morency, and R. Salakhutdinov, “Factorized contrastive learning: Going beyond multi-view redundancy,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Glober...
2023
-
[20]
K. He, H. Fan, Y. Wu, S. Xie, and R. B. Girshick, “Momentum contrast for unsupervised visual representation learning,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 9726–9735. [Online]. Available: https://doi.org/10.1109/CVPR42600.2020.00975
-
[21]
Viewmaker networks: Learning views for unsupervised representation learning,
A. Tamkin, M. Wu, and N. D. Goodman, “Viewmaker networks: Learning views for unsupervised representation learning,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. [Online]. Available: https://openreview.net/forum?id=enoVQWLsfyL
2021
-
[22]
Contrastive learning with hard negative samples,
J. D. Robinson, C. Chuang, S. Sra, and S. Jegelka, “Contrastive learning with hard negative samples,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. [Online]. Available: https://openreview.net/forum?id=CR1XOQ0UTh-
2021
-
[23]
Finger pinching and imagination classification: A fusion of cnn architectures for iomt-enabled bci applications,
G. Varone, W. Boulila, M. Driss, S. Kumari, M. K. Khan, T. R. Gadekallu, and A. Hussain, “Finger pinching and imagination classification: A fusion of cnn architectures for iomt-enabled bci applications,”Information Fusion, vol. 101, p. 102006, 2024
2024
-
[24]
Evidential deep learning to quantify classification uncertainty,
M. Sensoy, L. M. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,” in Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and ...
2018
-
[25]
Fusion of convolutional neural networks based on dempster–shafer theory for automatic pneumonia detection from chest x-ray images,
S. Ben Atitallah, M. Driss, W. Boulila, A. Koubaa, and H. Ben Ghezala, “Fusion of convolutional neural networks based on dempster–shafer theory for automatic pneumonia detection from chest x-ray images,”International Journal of Imaging Systems and Technology, vol. 32, no. 2, pp. 658–672, 2022
2022
-
[26]
Trusted multi-view classification with dynamic evidential fusion,
Z. Han, C. Zhang, H. Fu, and J. T. Zhou, “Trusted multi-view classification with dynamic evidential fusion,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 2, pp. 2551–2566, 2023. [Online]. Available: https://doi.org/10.1109/TPAMI.2022.3171983
-
[27]
Bigearthnet: A large-scale benchmark archive for remote sensing image understanding,
G. Sumbul, M. Charfuelan, B. Demir, and V. Markl, “Bigearthnet: A large-scale benchmark archive for remote sensing image understanding,” in2019 IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2019, Yokohama, Japan, July 28 - August 2, 2019. IEEE, 2019, pp. 5901–5904. [Online]. Available: https://doi.org/10.1109/IGARSS.2019.8900532
-
[28]
On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid,
Y. Long, G. Xia, S. Li, W. Yang, M. Y. Yang, X. X. Zhu, L. Zhang, and D. Li, “On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid,”IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens., vol. 14, pp. 4205–4230, 2021. [Online]. Available: https://doi.org/10.1109/JSTARS.2021.3070368
-
[29]
BDD100K: A diverse driving dataset for heterogeneous multitask learning,
F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, and T. Darrell, “BDD100K: A diverse driving dataset for heterogeneous multitask learning,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, W A, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 2633–2642. [Online]. Available: https:...
2020
-
[30]
Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,
J. Wang, Z. Zheng, A. Ma, X. Lu, and Y. Zhong, “Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,” inProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, J. Vanschoren and S. Yeung, Eds., 2021. [Online]. Available: htt...
2021
-
[31]
Deep Residual Learning for Image Recognition , isbn =
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 770–778. [Online]. Available: https://doi.org/10.1109/CVPR.2016.90
-
[32]
Large batch training of convolutional networks,
Y. You, I. Gitman, and B. Ginsburg, “Large batch training of convolutional networks,”arXiv: Computer Vision and Pattern Recognition, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:46294020
2017
-
[33]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,”IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens., vol. 12, no. 7, pp. 2217–2226, 2019. [Online]. Available: https://doi.org/10.1109/JSTARS.2019.2918242
-
[34]
AID: A benchmark data set for performance evaluation of aerial scene classification,
G. Xia, J. Hu, F. Hu, B. Shi, X. Bai, Y. Zhong, L. Zhang, and X. Lu, “AID: A benchmark data set for performance evaluation of aerial scene classification,”IEEE Trans. Geosci. Remote. Sens., vol. 55, no. 7, pp. 3965–3981, 2017. [Online]. Available: https://doi.org/10.1109/TGRS.2017.2685945
-
[35]
Remote sensing image scene classification: Benchmark and state of the art,
G. Cheng, J. Han, and X. Lu, “Remote sensing image scene classification: Benchmark and state of the art,”Proc. IEEE, vol. 105, no. 10, pp. 1865–1883, 2017. [Online]. Available: https://doi.org/10.1109/JPROC.2017.2675998
-
[36]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. B. Girshick, “Masked autoencoders are scalable vision learners,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24,
2022
-
[37]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
IEEE, 2022, pp. 15979–15988. [Online]. Available: https://doi.org/10.1109/CVPR52688.2022.01553
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.