Recognition: unknown
Language as a Latent Variable for Reasoning Optimization
Pith reviewed 2026-05-09 21:37 UTC · model grok-4.3
The pith
Language functions as a latent variable that modulates LLMs' internal inference pathways, so optimizing policies over language variation improves reasoning accuracy and generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
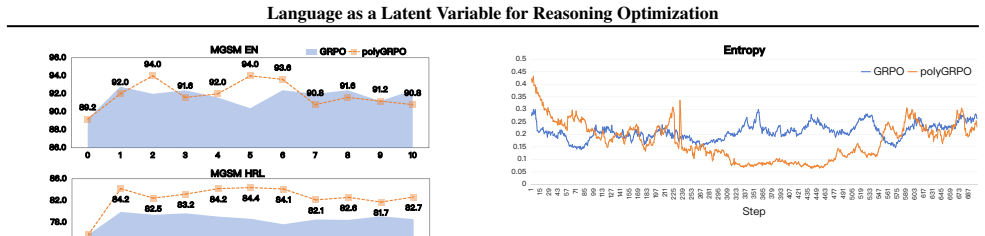
Language functions as a latent variable that structurally modulates the model's internal inference pathways rather than merely serving as an output medium. Treating language variation as an implicit exploration signal in policy optimization expands the latent reasoning space and produces consistent improvements in accuracy and cross-task generalization.
What carries the argument
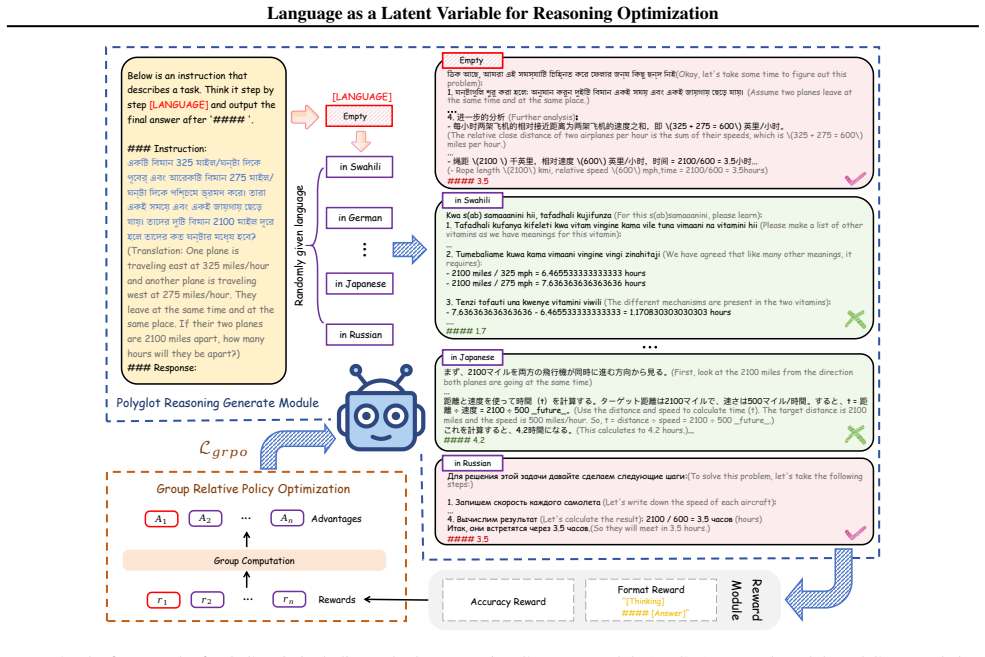
polyGRPO, an RL framework that generates polyglot preference data online under language-constrained and unconstrained conditions and optimizes the policy with respect to both answer accuracy and reasoning structure.
If this is right
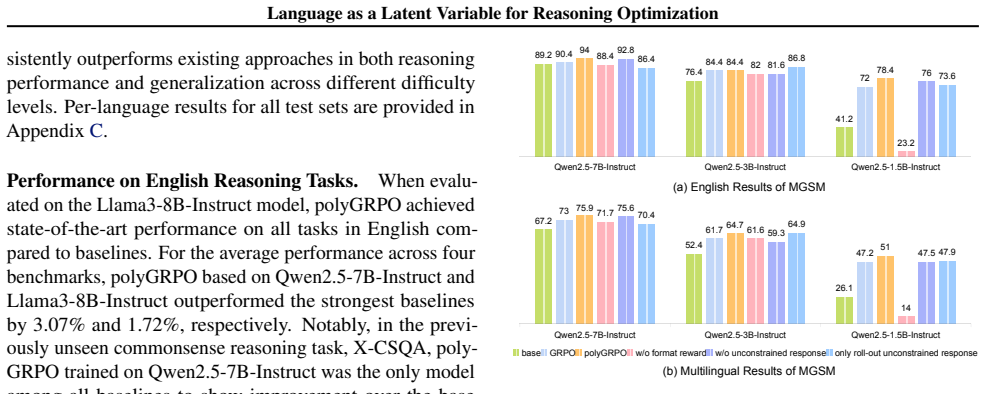
- Trained on only 18.1K multilingual math problems without chain-of-thought annotations, the method raises absolute accuracy by 6.72 percent on four English reasoning test sets.
- The same training produces a 6.89 percent gain on the corresponding multilingual benchmark.
- It is the only method that surpasses the base model on English commonsense reasoning (by 4.9 percent) despite receiving exclusively math training data.
- Allowing language to remain unconstrained during problem solving broadens the model's latent reasoning space and yields higher accuracy than language-constrained prompting.
Where Pith is reading between the lines
- The same language-variation signal could be inserted into supervised fine-tuning or other non-RL training loops to test whether the benefit is specific to policy optimization.
- The approach may generalize to scientific or coding domains if language constraints are used to sample alternative reasoning styles on the same underlying problems.
- Models trained this way might exhibit more robust performance if inference is allowed to switch languages mid-reasoning rather than committing to one language from the start.
Load-bearing premise
The observed accuracy gains result specifically from language modulating internal inference pathways rather than from ordinary reinforcement-learning dynamics or differences in data volume.
What would settle it
Train a control model on the same total volume of generated responses but without any language-constrained or multilingual prompts, then measure whether the accuracy gains on English and multilingual reasoning tests disappear.
Figures



read the original abstract
As LLMs reduce English-centric bias, a surprising trend emerges: non-English responses sometimes outperform English on reasoning tasks. We hypothesize that language functions as a latent variable that structurally modulates the model's internal inference pathways, rather than merely serving as an output medium. To test this, we conducted a Polyglot Thinking Experiment, in which models were prompted to solve identical problems under language-constrained and language-unconstrained conditions. Results show that non-English responses often achieve higher accuracy, and the best performance frequently occur when language is unconstrained, suggesting that multilinguality broadens the model's latent reasoning space. Based on this insight, we propose polyGRPO (Polyglot Group Relative Policy Optimization), an RL framework that treats language variation as an implicit exploration signal. It generates polyglot preference data online under language-constrained and unconstrained conditions, optimizing the policy with respect to both answer accuracy and reasoning structure. Trained on only 18.1K multilingual math problems without chain-of-thought annotations, polyGRPO improves the base model (Qwen2.5-7B-Instruct) by 6.72% absolute accuracy on four English reasoning testset and 6.89% in their multilingual benchmark. Remarkably, it is the only method that surpasses the base LLM on English commonsense reasoning task (4.9%), despite being trained solely on math data-highlighting its strong cross-task generalization. Further analysis reveals that treating language as a latent variable expands the model's latent reasoning space, yielding consistent and generalizable improvements in reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper hypothesizes that language functions as a latent variable modulating LLMs' internal inference pathways rather than serving only as an output format. It supports this via a Polyglot Thinking Experiment showing higher accuracy under language-unconstrained prompting, then introduces polyGRPO, an RL framework that generates online polyglot preference data (constrained and unconstrained) and optimizes GRPO on accuracy plus reasoning structure. Trained on 18.1K multilingual math problems without CoT, polyGRPO yields +6.72% absolute accuracy on four English reasoning benchmarks and +6.89% on a multilingual benchmark for Qwen2.5-7B-Instruct; it is the only method that improves English commonsense reasoning (+4.9%) despite math-only training, which the authors attribute to expanded latent reasoning space.
Significance. If the causal attribution to language-as-latent-variable holds after proper controls, the work would offer a concrete mechanism for using multilingual variation as an exploration signal in RL, with demonstrated cross-task generalization from math to commonsense. This could shift RL-for-reasoning practice toward polyglot data generation rather than monolingual or English-only regimes, and the empirical gains on a 7B model with modest data are noteworthy.
major comments (3)
- [§4 and §5.1] §4 (polyGRPO method) and §5.1 (main results): No monolingual GRPO baseline is reported that matches data volume, diversity injection, or optimization schedule. Without this control, the 6.72% English and 6.89% multilingual gains cannot be attributed specifically to language variation as a latent modulator rather than standard RL effects, preference-data quality, or increased exploration alone. This directly undermines the central claim.
- [§5.1 and §5.2] §5.1 and §5.2 (Polyglot Thinking Experiment and generalization results): Accuracy lifts are presented without statistical significance tests, confidence intervals, or multiple random seeds. In addition, the language-unconstrained condition is not compared against a standard (non-polyglot) prompting baseline with equivalent compute, leaving open whether the reported superiority reflects the hypothesized structural modulation or simply prompt diversity.
- [§3] §3 (Polyglot Thinking Experiment): The description of how language-unconstrained prompting is implemented and how it differs from ordinary multilingual prompting is insufficiently detailed to evaluate whether the experiment fairly isolates language as a latent variable. Specifics on prompt templates, decoding constraints, and how “best performance” is selected across languages are needed to support the interpretive step to “expands the model’s latent reasoning space.”
minor comments (2)
- [Abstract] Abstract: “four English reasoning testset” should be “testsets.”
- [§5.3] §5.3 (analysis): The claim that non-English responses “sometimes outperform” English is presented without quantitative breakdown by language or task; a table or figure showing per-language accuracy would strengthen the supporting evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental controls and clarity that will strengthen the manuscript. We respond point by point below and commit to revisions that directly address the concerns while preserving the core contribution on language as a latent variable.
read point-by-point responses
-
Referee: [§4 and §5.1] §4 (polyGRPO method) and §5.1 (main results): No monolingual GRPO baseline is reported that matches data volume, diversity injection, or optimization schedule. Without this control, the 6.72% English and 6.89% multilingual gains cannot be attributed specifically to language variation as a latent modulator rather than standard RL effects, preference-data quality, or increased exploration alone. This directly undermines the central claim.
Authors: We agree that a matched monolingual GRPO baseline is required to isolate the specific contribution of polyglot language variation. The manuscript presents polyGRPO as generating both constrained and unconstrained preference pairs online, but does not include the requested monolingual control. In the revised version we will add a monolingual GRPO baseline trained on the identical 18.1K math problems, using the same optimization schedule, reward formulation, and data volume, but restricted to English-only generation. This will allow quantitative attribution of any additional gains to the language-as-latent-variable mechanism rather than generic RL or exploration effects. revision: yes
-
Referee: [§5.1 and §5.2] §5.1 and §5.2 (Polyglot Thinking Experiment and generalization results): Accuracy lifts are presented without statistical significance tests, confidence intervals, or multiple random seeds. In addition, the language-unconstrained condition is not compared against a standard (non-polyglot) prompting baseline with equivalent compute, leaving open whether the reported superiority reflects the hypothesized structural modulation or simply prompt diversity.
Authors: We acknowledge the absence of statistical rigor and the missing standard-prompting comparison. In the revision we will report all main results with 95% confidence intervals, p-values from paired t-tests or bootstrap tests, and averages over at least three independent random seeds. For the Polyglot Thinking Experiment, we will add a standard English-only prompting baseline run with equivalent compute (same number of generations and decoding budget). This baseline will be contrasted with both the language-constrained and language-unconstrained conditions to demonstrate that performance gains arise from the expanded latent space rather than prompt diversity alone. revision: yes
-
Referee: [§3] §3 (Polyglot Thinking Experiment): The description of how language-unconstrained prompting is implemented and how it differs from ordinary multilingual prompting is insufficiently detailed to evaluate whether the experiment fairly isolates language as a latent variable. Specifics on prompt templates, decoding constraints, and how “best performance” is selected across languages are needed to support the interpretive step to “expands the model’s latent reasoning space.”
Authors: We will substantially expand §3 with the requested implementation details. Language-constrained prompting uses explicit templates of the form “Solve the following problem and answer only in [language]” together with decoding constraints that reject tokens outside the target language. Language-unconstrained prompting uses a neutral template (“Solve the following problem”) with no language specification and no decoding restrictions, allowing the model to select any language. “Best performance” is obtained by generating one response per condition and selecting the highest-accuracy answer across the unconstrained generations for each problem. The revised text will include the exact prompt templates, sampling parameters, and selection procedure to make the isolation of the latent-variable effect transparent. revision: yes
Circularity Check
No circularity: empirical method and results contain no self-referential reductions or load-bearing self-citations.
full rationale
The paper advances a hypothesis that language acts as a latent variable modulating reasoning pathways, supported by a Polyglot Thinking Experiment and the polyGRPO RL method. It reports empirical accuracy gains (6.72% English, 6.89% multilingual) from training on 18.1K math problems. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The central claims rest on benchmark comparisons and interpretive analysis of language variation effects rather than any tautological reduction to inputs. This is a standard empirical RL paper without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language choice structurally modulates internal inference pathways in LLMs
Reference graph
Works this paper leans on
-
[1]
Aaron Jaech and Adam Kalai and Adam Lerer and Adam Richardson and Ahmed El. OpenAI o1 System Card , journal =. 2024 , url =. doi:10.48550/ARXIV.2412.16720 , eprinttype =. 2412.16720 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.16720 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[3]
2025 , eprint=
Could Thinking Multilingually Empower LLM Reasoning? , author=. 2025 , eprint=
2025
-
[4]
Lianzhe Huang and Shuming Ma and Dongdong Zhang and Furu Wei and Houfeng Wang , editor =. Zero-shot Cross-lingual Transfer of Prompt-based Tuning with a Unified Multilingual Prompt , booktitle =. 2022 , url =. doi:10.18653/V1/2022.EMNLP-MAIN.790 , timestamp =
-
[5]
The Eleventh International Conference on Learning Representations,
Freda Shi and Mirac Suzgun and Markus Freitag and Xuezhi Wang and Suraj Srivats and Soroush Vosoughi and Hyung Won Chung and Yi Tay and Sebastian Ruder and Denny Zhou and Dipanjan Das and Jason Wei , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[6]
Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations , booktitle =
Nuo Chen and Zinan Zheng and Ning Wu and Ming Gong and Dongmei Zhang and Jia Li , editor =. Breaking Language Barriers in Multilingual Mathematical Reasoning: Insights and Observations , booktitle =. 2024 , url =
2024
-
[7]
Haoyang Huang and Tianyi Tang and Dongdong Zhang and Xin Zhao and Ting Song and Yan Xia and Furu Wei , editor =. Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-EMNLP.826 , timestamp =
-
[8]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[9]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al. The Llama 3 Herd of Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[10]
Yu , title =
Libo Qin and Qiguang Chen and Yuhang Zhou and Zhi Chen and Yinghui Li and Lizi Liao and Min Li and Wanxiang Che and Philip S. Yu , title =. CoRR , volume =. 2024 , url =
2024
-
[11]
Multilingual Large Language Models:
Shaolin Zhu and Supryadi and Shaoyang Xu and Haoran Sun and Leiyu Pan and Menglong Cui and Jiangcun Du and Renren Jin and Ant. Multilingual Large Language Models:. CoRR , volume =. 2024 , url =
2024
-
[12]
CoRR , volume=
EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models , author=. CoRR , volume=
-
[13]
CoRR , volume=
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement , author=. CoRR , volume=
-
[14]
2024 , eprint=
Aya 23: Open Weight Releases to Further Multilingual Progress , author=. 2024 , eprint=
2024
-
[15]
Benchmax: A comprehensive multilingual evaluation suite for large language models
Xu Huang and Wenhao Zhu and Hanxu Hu and Conghui He and Lei Li and Shujian Huang and Fei Yuan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.07346 , eprinttype =. 2502.07346 , timestamp =
-
[16]
Leonardo Ranaldi and Fabio Massimo Zanzotto , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2311.08097 , eprinttype =. 2311.08097 , timestamp =
-
[17]
Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
Libo Qin and Qiguang Chen and Fuxuan Wei and Shijue Huang and Wanxiang Che , editor =. Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.163 , timestamp =
-
[18]
Yongheng Zhang and Qiguang Chen and Min Li and Wanxiang Che and Libo Qin , editor =. AutoCAP: Towards Automatic Cross-lingual Alignment Planning for Zero-shot Chain-of-Thought , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.546 , timestamp =
-
[19]
m C o T : Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Huiyuan Lai and Malvina Nissim , editor =. mCoT: Multilingual Instruction Tuning for Reasoning Consistency in Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.649 , timestamp =
-
[20]
Linzheng Chai and Jian Yang and Tao Sun and Hongcheng Guo and Jiaheng Liu and Bing Wang and Xinnian Liang and Jiaqi Bai and Tongliang Li and Qiyao Peng and Zhoujun Li , editor =. AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA,. 2025 , url =. doi:10.1609/AAAI.V39I22.34524 ...
-
[21]
Do Multilingual Language Models Think Better in E nglish?
Julen Etxaniz and Gorka Azkune and Aitor Soroa and Oier Lopez de Lacalle and Mikel Artetxe , editor =. Do Multilingual Language Models Think Better in English? , booktitle =. 2024 , url =. doi:10.18653/V1/2024.NAACL-SHORT.46 , timestamp =
-
[22]
MindMerger: Efficiently Boosting
Zixian Huang and Wenhao Zhu and Gong Cheng and Lei Li and Fei Yuan , editor =. MindMerger: Efficiently Boosting. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[23]
Question Translation Training for Better Multilingual Reasoning
Wenhao Zhu and Shujian Huang and Fei Yuan and Shuaijie She and Jiajun Chen and Alexandra Birch , editor =. Question Translation Training for Better Multilingual Reasoning , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.498 , timestamp =
-
[24]
Dongkeun Yoon and Joel Jang and Sungdong Kim and Seungone Kim and Sheikh Shafayat and Minjoon Seo , editor =. LangBridge: Multilingual Reasoning Without Multilingual Supervision , booktitle =. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.405 , timestamp =
-
[25]
Weixuan Wang and Minghao Wu and Barry Haddow and Alexandra Birch , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.12663 , eprinttype =. 2502.12663 , timestamp =
-
[26]
MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization
Shuaijie She and Wei Zou and Shujian Huang and Wenhao Zhu and Xiang Liu and Xiang Geng and Jiajun Chen , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.539 , timestamp =
-
[27]
Wen Yang and Junhong Wu and Chen Wang and Chengqing Zong and Jiajun Zhang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.08964 , eprinttype =. 2410.08964 , timestamp =
-
[28]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =. 1707.06347 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , timestamp =
2023
-
[30]
Swaroop Mishra and Arindam Mitra and Neeraj Varshney and Bhavdeep Singh Sachdeva and Peter Clark and Chitta Baral and Ashwin Kalyan , editor =. NumGLUE:. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2022 , url =. doi:10.18653/V1/2022.ACL-LONG.246 , timestamp =
-
[31]
Bill Yuchen Lin and Seyeon Lee and Xiaoyang Qiao and Xiang Ren , editor =. Common Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning , booktitle =. 2021 , url =. doi:10.18653/V1/2021.ACL-LONG.102 , timestamp =
-
[32]
Linting Xue and Noah Constant and Adam Roberts and Mihir Kale and Rami Al. mT5:. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2021 , url =. doi:10.18653/V1/2021.NAACL-MAIN.41 , timestamp =
-
[33]
Yidan Zhang and Boyi Deng and Yu Wan and Baosong Yang and Haoran Wei and Fei Huang and Bowen Yu and Junyang Lin and Jingren Zhou , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.09116 , eprinttype =. 2411.09116 , timestamp =
-
[34]
2025 , url =
LogitLens4LLMs: A Logit Lens Toolkit for Modern Large Language Models , author =. 2025 , url =
2025
-
[35]
arXiv preprint arXiv:2505.05408 , year=
Crosslingual Reasoning through Test-Time Scaling , author=. arXiv preprint arXiv:2505.05408 , year=
-
[36]
Zheng Yuan and Hongyi Yuan and Chengpeng Li and Guanting Dong and Chuanqi Tan and Chang Zhou , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2308.01825 , eprinttype =. 2308.01825 , timestamp =
-
[37]
FastText.zip: Compressing text classification models
FastText.zip: Compressing text classification models , author=. arXiv preprint arXiv:1612.03651 , year=
-
[38]
Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018) , year=
Learning Word Vectors for 157 Languages , author=. Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018) , year=
2018
-
[39]
arXiv preprint arXiv:2504.18428 , year=
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts , author=. arXiv preprint arXiv:2504.18428 , year=
-
[40]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review arXiv
-
[41]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale, 2025 , author=. URL https://arxiv. org/abs/2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, et al
Magistral , author=. arXiv preprint arXiv:2506.10910 , year=
-
[43]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review arXiv
-
[44]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang and Beichen Zhang and Binyuan Hui and Bofei Gao and Bowen Yu and Chengpeng Li and Dayiheng Liu and Jianhong Tu and Jingren Zhou and Junyang Lin and Keming Lu and Mingfeng Xue and Runji Lin and Tianyu Liu and Xingzhang Ren and Zhenru Zhang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.12122 , eprinttype =. 2409.12122 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2409.12122 2024
-
[45]
Language of Thought Shapes Output Diversity in Large Language Models
Language of Thought Shapes Output Diversity in Large Language Models , author=. arXiv preprint arXiv:2601.11227 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.