Recognition: unknown
StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
Pith reviewed 2026-05-08 13:12 UTC · model grok-4.3
The pith
Human perception data from stylized faces lets fine-tuned encoders match judgments across styles and generalize to artist drawings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that StyleBench-S, constructed from psychometric recognition-strength curves obtained through controlled 2AFC experiments, can be used as supervision to fine-tune semantic encoders. This alignment makes the encoders' similarity orderings match human perception of facial identity across multiple stylization methods and strengths. As a result the models achieve significantly higher correlation with human same-different verification judgments and greater robustness on out-of-domain artist-drawn portraits.
What carries the argument
StyleBench-S, the supervision set of psychometric curves from two-alternative forced-choice experiments used to calibrate encoder similarity orderings to human identity judgments.
If this is right
- Calibrated models produce similarity scores that correlate significantly higher with human verification judgments across styles.
- The same fine-tuning improves robustness when the models are applied to previously unseen artist-drawn portraits.
- The StyleID framework supplies both a benchmark and a supervision source for evaluating and supervising identity consistency under varying stylization strengths.
- Existing semantic encoders can be adapted to stylization without training new models from scratch on natural images.
Where Pith is reading between the lines
- The same perceptual-alignment procedure could be tested on other domain-shift problems where models must ignore medium-specific cues, such as recognizing objects rendered in different illustration styles.
- Public release of the human-judgment datasets may support iterative improvement of the metric as new stylization algorithms appear.
- Downstream applications such as face retrieval in mixed photo-and-art archives or identity tracking in animation pipelines would benefit if the calibrated encoders prove stable under further style variations.
Load-bearing premise
The same-different judgments and 2AFC psychometric curves collected from human participants form a reliable style-agnostic ground truth that generalizes beyond the tested stylization methods and participant pool.
What would settle it
Collecting fresh human same-different judgments and 2AFC curves on a stylization technique or strength level outside the original diffusion- and flow-matching set and finding that the fine-tuned models no longer correlate with those new judgments would falsify the claim of generalizable calibration.
Figures









read the original abstract
Creative face stylization aims to render portraits in diverse visual idioms such as cartoons, sketches, and paintings while retaining recognizable identity. However, current identity encoders, which are typically trained and calibrated on natural photographs, exhibit severe brittleness under stylization. They often mistake changes in texture or color palette for identity drift or fail to detect geometric exaggerations. This reveals the lack of a style-agnostic framework to evaluate and supervise identity consistency across varying styles and strengths. To address this gap, we introduce StyleID, a human perception-aware dataset and evaluation framework for facial identity under stylization. StyleID comprises two datasets: (i) StyleBench-H, a benchmark that captures human same-different verification judgments across diffusion- and flow-matching-based stylization at multiple style strengths, and (ii) StyleBench-S, a supervision set derived from psychometric recognition-strength curves obtained through controlled two-alternative forced-choice (2AFC) experiments. Leveraging StyleBench-S, we fine-tune existing semantic encoders to align their similarity orderings with human perception across styles and strengths. Experiments demonstrate that our calibrated models yield significantly higher correlation with human judgments and enhanced robustness for out-of-domain, artist drawn portraits. All of our datasets, code, and pretrained models are publicly available at https://kwanyun.github.io/StyleID_page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StyleID, a perception-aware dataset and framework for facial identity recognition under stylization. It comprises StyleBench-H (human same-different verification judgments across diffusion- and flow-matching stylizations at multiple strengths) and StyleBench-S (supervision derived from 2AFC psychometric recognition-strength curves). The authors fine-tune existing semantic encoders on StyleBench-S to align similarity orderings with human perception, reporting significantly higher correlation with human judgments and improved robustness on out-of-domain artist-drawn portraits. All datasets, code, and models are released publicly.
Significance. If the human-derived ground truth holds and generalizes, this addresses a clear gap in robust identity preservation for creative stylization applications in graphics and generative AI. The public release of data, code, and pretrained models is a concrete strength enabling reproducibility and follow-on work. The approach could improve downstream tasks such as style transfer evaluation and cross-style recognition systems.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: the claim that fine-tuned models yield 'significantly higher correlation with human judgments' and 'enhanced robustness' is not supported by reported participant counts, statistical tests, error bars, baseline comparisons, or data exclusion criteria. Without these, the link from human 2AFC data to the central performance claims cannot be verified.
- [Dataset construction] Dataset construction (StyleBench-S derivation): the assumption that 2AFC psychometric curves provide a style-agnostic ground truth is load-bearing for the out-of-domain robustness claim, yet no inter-rater reliability, participant demographics, or ablation across stylization families (e.g., diffusion/flow-matching vs. geometric artist-drawn) is presented to test invariance to generative process.
minor comments (2)
- [Abstract] Abstract: specify the exact number of identities, styles, and strength levels in StyleBench-H and StyleBench-S to allow readers to assess scale.
- [Notation and figures] Notation and figures: ensure all psychometric curve fitting parameters and similarity metrics are defined with equations or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of statistical rigor and validation that will strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: the claim that fine-tuned models yield 'significantly higher correlation with human judgments' and 'enhanced robustness' is not supported by reported participant counts, statistical tests, error bars, baseline comparisons, or data exclusion criteria. Without these, the link from human 2AFC data to the central performance claims cannot be verified.
Authors: We agree that these supporting details are essential for verifying the claims. The current manuscript reports correlation coefficients and robustness improvements but does not explicitly include participant counts, statistical tests (e.g., p-values from paired comparisons), error bars, full baseline tables, or data exclusion criteria. In the revised manuscript we will add: (i) participant counts for both StyleBench-H and StyleBench-S (N=XX and N=YY respectively), (ii) statistical significance tests with p-values, (iii) error bars on all correlation and accuracy plots, (iv) expanded baseline comparisons against additional off-the-shelf encoders, and (v) a clear data-exclusion protocol (attention checks and response-time filters) in the Experiments and supplementary sections. These additions will directly link the 2AFC data to the reported performance gains. revision: yes
-
Referee: [Dataset construction] Dataset construction (StyleBench-S derivation): the assumption that 2AFC psychometric curves provide a style-agnostic ground truth is load-bearing for the out-of-domain robustness claim, yet no inter-rater reliability, participant demographics, or ablation across stylization families (e.g., diffusion/flow-matching vs. geometric artist-drawn) is presented to test invariance to generative process.
Authors: We acknowledge that explicit evidence for the style-agnostic property of StyleBench-S is currently limited. While the 2AFC protocol was designed to isolate perceptual identity strength rather than low-level generative artifacts, the manuscript does not report inter-rater reliability metrics, participant demographics, or a dedicated ablation across stylization families. In revision we will add: (i) inter-rater agreement (e.g., Fleiss’ kappa or intraclass correlation) computed on the 2AFC responses, (ii) available demographic summaries (age range, gender distribution), and (iii) an ablation table showing fine-tuned model performance separately on diffusion-based, flow-matching-based, and artist-drawn out-of-domain portraits. These additions will provide direct empirical support for the invariance claim underlying the out-of-domain robustness results. revision: partial
Circularity Check
No circularity: supervision and evaluation derive from independent human 2AFC data
full rationale
The paper constructs StyleBench-S from separate 2AFC psychometric curves and StyleBench-H from same-different judgments, both collected from human participants. Fine-tuning aligns encoder similarities to the StyleBench-S curves, after which correlation is reported against human judgments. No equation, derivation step, or self-citation reduces the target correlation or robustness claim to a quantity defined by the model outputs or by the authors' prior work. The result is ordinary supervised calibration whose validity rests on the external human data rather than on any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human same-different verification judgments and 2AFC recognition-strength curves provide a reliable measure of facial identity perception across stylization levels and methods.
Reference graph
Works this paper leans on
-
[1]
12•Yun et al. FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space.arXiv e-prints(2025), arXiv–2506. Fadi Boutros, Naser Damer, Florian Kirchbuchner, and Arjan Kuijper
2025
-
[2]
In2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018)
Vggface2: A dataset for recognising faces across pose and age. In2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). IEEE, 67–74. Min Jin Chong and David Forsyth
2018
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020). Ionut Cosmin Duta, Li Liu, Fan Zhu, and Ling Shao
work page internal anchor Pith review arXiv 2010
-
[4]
ACM Transactions on Graphics (TOG)41, 4 (2022), 1–13
Stylegan-nada: Clip-guided domain adaptation of image generators. ACM Transactions on Graphics (TOG)41, 4 (2022), 1–13. Leon A Gatys, Alexander S Ecker, and Matthias Bethge
2022
-
[5]
Prompt-to-Prompt Image Editing with Cross Attention Control
Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626(2022). Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al
work page internal anchor Pith review arXiv 2022
-
[6]
Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022),
2022
-
[7]
ACM Transactions On Graphics (TOG)40, 4 (2021), 1–16
Stylecarigan: caricature generation via stylegan feature map modulation. ACM Transactions On Graphics (TOG)40, 4 (2021), 1–16. Wonjong Jang, Yucheol Jung, Hyomin Kim, Gwangjin Ju, Chaewon Son, Jooeun Son, and Seungyong Lee
2021
-
[8]
InACM SIGGRAPH 2024 Conference Papers
Toonify3D: StyleGAN-based 3D stylized face generator. InACM SIGGRAPH 2024 Conference Papers. 1–11. Liming Jiang, Qing Yan, Yumin Jia, Zichuan Liu, Hao Kang, and Xin Lu
2024
- [9]
-
[10]
Advances in neural information processing systems33 (2020), 18661–18673
Supervised contrastive learning. Advances in neural information processing systems33 (2020), 18661–18673. Minchul Kim, Anil K Jain, and Xiaoming Liu. 2022a. Adaface: Quality adaptive margin for face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18750–18759. Seongtae Kim, Kyoungkook Kang, Geonung Kim, Seu...
2020
-
[11]
Seungmi Lee, Kwan Yun, and Junyong Noh
The measurement of observer agreement for categorical data.biometrics(1977), 159–174. Seungmi Lee, Kwan Yun, and Junyong Noh
1977
-
[12]
Yifang Men, Yuan Yao, Miaomiao Cui, Zhouhui Lian, and Xuansong Xie
Comparison of the predicted and observed secondary structure of T4 phage lysozyme.Biochimica et Biophysica Acta (BBA)-Protein Structure405, 2 (1975), 442–451. Yifang Men, Yuan Yao, Miaomiao Cui, Zhouhui Lian, and Xuansong Xie
1975
-
[13]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Dct-net: domain-calibrated translation for portrait stylization.ACM Transactions on Graphics (TOG)41, 4 (2022), 1–9. Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2021a. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073(2021). Qiang Meng, Shichao...
work page internal anchor Pith review arXiv 2022
-
[14]
InBMVC 2015-Proceedings of the British Machine Vision Conference
Deep face recognition. InBMVC 2015-Proceedings of the British Machine Vision Conference
2015
-
[15]
Learning Transferable Visual Models From Natural Language Supervision
Learning transferable visual models from natural language supervision.arXiv preprint arXiv:2103.00020(2021). Daniel Roich, Ron Mokady, Amit H Bermano, and Daniel Cohen-Or
work page internal anchor Pith review arXiv 2021
-
[16]
Florian Schroff, Dmitry Kalenichenko, and James Philbin
Pivotal tuning for latent-based editing of real images.ACM Transactions on graphics (TOG) 42, 1 (2022), 1–13. Florian Schroff, Dmitry Kalenichenko, and James Philbin
2022
-
[17]
In2021 International Conference on Engineering and Emerging Technologies (ICEET)
HyperExtended LightFace: A Facial Attribute Analysis Framework. In2021 International Conference on Engineering and Emerging Technologies (ICEET). IEEE, 1–4. doi:10.1109/ICEET53442.2021.9659697 Yichun Shi, Debayan Deb, and Anil K Jain
-
[18]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al
Designing an encoder for stylegan image manipulation.ACM Transactions on graphics (TOG)40, 4 (2021), 1–14. Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al
2021
-
[19]
Siglip 2: Multilingual vision-language encoders with im- proved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786(2025). Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky
work page internal anchor Pith review arXiv 2025
-
[20]
Instance normalization: The missing in- gredient for fast stylization
Instance normalization: The missing ingredient for fast stylization.arXiv preprint arXiv:1607.08022(2016). Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu
-
[21]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519,
Instantid: Zero-shot identity-preserving generation in seconds. arXiv preprint arXiv:2401.07519(2024). Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao
-
[22]
Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025). Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang
work page internal anchor Pith review arXiv 2025
-
[23]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ip-adapter: Text com- patible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721(2023). Dong Yi, Zhen Lei, Shengcai Liao, and Stan Z Li
work page internal anchor Pith review arXiv 2023
-
[24]
Soyeon Yoon, Kwan Yun, Kwanggyoon Seo, Sihun Cha, Jung Eun Yoo, and Junyong Noh
Learning face representation from scratch.arXiv preprint arXiv:1411.7923(2014). Soyeon Yoon, Kwan Yun, Kwanggyoon Seo, Sihun Cha, Jung Eun Yoo, and Junyong Noh
-
[25]
InProceedings of the IEEE international conference on computer vision
Unpaired image-to- image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision. 2223–2232. Peihao Zhu, Rameen Abdal, John Femiani, and Peter Wonka. 2021a. Mind the gap: Domain gap control for single shot domain adaptation for generative adversarial networks.arXiv preprint arXiv:2110....
-
[26]
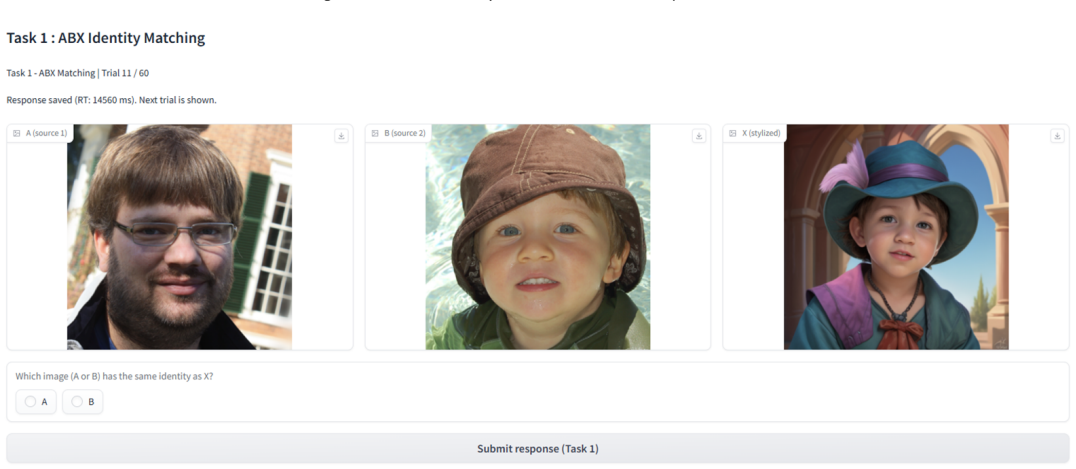
Participants were asked to choose which of the two stylized images better preserves the identity of the source image
Examples from the user study. Participants were asked to choose which of the two stylized images better preserves the identity of the source image. results further confirm the robustness of StyleID under severe ap- pearance shifts and highlight the limitations of conventional identity encoders in stylized domains. C.4 User Study We conducted a pilot user ...
2025
-
[27]
Comparing the model’s predictions with human preferences yielded an accuracy of 0.707, Cohen’s𝜅 of 0.392, and MCC of 0.402 [Landis and Koch 1977; Matthews 1975]
The study consisted of 20 distinct trials. Comparing the model’s predictions with human preferences yielded an accuracy of 0.707, Cohen’s𝜅 of 0.392, and MCC of 0.402 [Landis and Koch 1977; Matthews 1975]. These results indicate that the model captures meaningful identity cues even under previously unseen and difficult stylization settings, supporting its ...
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.