Recognition: unknown
Beyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Pith reviewed 2026-05-09 22:25 UTC · model grok-4.3
The pith
X-GRAM improves language model accuracy by up to 4.4 points using frequency-aware compressed embedding tables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
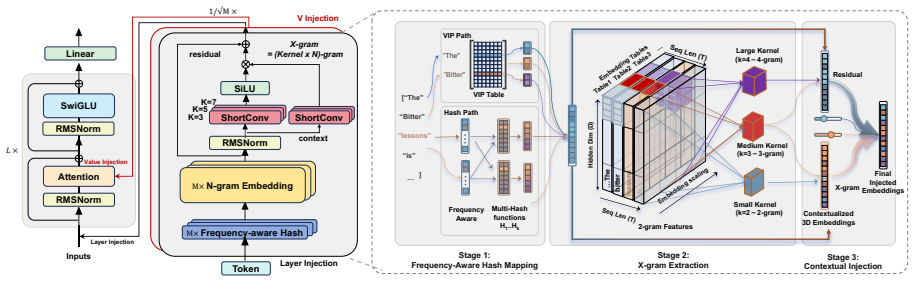
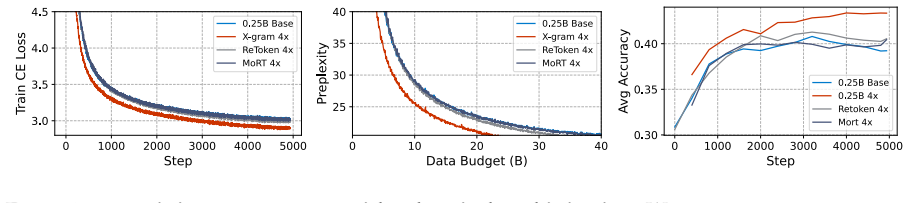
X-GRAM is a frequency-aware dynamic token-injection framework that uses hybrid hashing and alias mixing to compress the long tail of the vocabulary while preserving head capacity, refines the retrieved vectors with normalized SwiGLU ShortConv to pull out diverse local n-gram features, and routes these signals into attention value streams and inter-layer residuals via depth-aware gating. The design aligns static memory with dynamic context and decouples model capacity from FLOPs. At the 0.73B and 1.15B scales the method raises average accuracy by as much as 4.4 points over a vanilla backbone and 3.2 points over strong retrieval baselines, even when the embedding table is cut to 50 percent of
What carries the argument
X-GRAM, a frequency-aware dynamic token-injection framework that combines hybrid hashing with alias mixing for tail compression, normalized SwiGLU ShortConv for local n-gram feature extraction, and depth-aware gating for integration into attention and residuals.
If this is right
- Embedding tables can be made substantially smaller while still raising accuracy on downstream tasks.
- Model capacity can be scaled along a memory axis that is independent of FLOPs.
- Long-tail tokens receive usable representations without allocating full embedding slots to every rare word.
- Layer-specific demands can be met by routing refined signals through depth-aware gates rather than uniform tables.
Where Pith is reading between the lines
- The same frequency-aware compression and local-feature refinement could be applied to other large lookup structures such as those in retrieval-augmented generation systems.
- Scaling laws that treat memory size as a separate controllable variable might predict performance more accurately than parameter count alone.
- If the gains hold at larger scales, memory-augmented architectures could become a practical alternative to simply widening or deepening standard transformers.
Load-bearing premise
The accuracy gains come from the hybrid hashing, alias mixing, SwiGLU refinement, and depth-aware gating rather than from unstated differences in training data, optimizer settings, or evaluation protocols.
What would settle it
Re-run the 0.73B-scale experiments with identical training data, optimizer, and evaluation code but replace the X-GRAM components with ordinary embedding lookups and check whether the reported accuracy advantage disappears.
Figures







read the original abstract
Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes X-GRAM, a frequency-aware dynamic token-injection framework that uses hybrid hashing and alias mixing to compress the long tail of Zipfian distributions while preserving head capacity, refines retrieved vectors with normalized SwiGLU ShortConv for local n-gram features, and integrates them via depth-aware gating into attention and residuals. It claims this decouples model capacity from FLOPs and yields up to 4.4-point average accuracy gains over vanilla backbones and 3.2 points over retrieval baselines at 0.73B and 1.15B scales, even in a 50% table-size configuration.
Significance. If the accuracy gains are shown to be attributable to the proposed mechanisms under matched training and evaluation conditions, the work would be significant for introducing a memory-centric scaling axis that addresses under-training of rare tokens and slot collapse without increasing FLOPs. The public code link is a strength for potential reproducibility.
major comments (2)
- [Abstract] Abstract: The central empirical claims (4.4-point gain over vanilla backbone, 3.2-point gain over retrieval baselines, and effective 50% table compression) are presented without any information on datasets, number of runs, statistical significance, ablation studies, or confirmation that training data, optimizer (LR, schedule, steps, batch size), and evaluation protocols were identical across X-GRAM and all baselines. This is load-bearing for attributing observed deltas to hybrid hashing, alias mixing, normalized SwiGLU ShortConv, and depth-aware gating rather than uncontrolled experimental differences.
- [Abstract] Abstract: The 50% table-size configuration is described as achieving the reported gains, but it is unclear whether this ratio is an output of the X-GRAM design or an arbitrary fixed choice; no derivation or sensitivity analysis ties the compression factor to the frequency-aware mechanisms.
minor comments (1)
- [Abstract] Abstract: Typo in the final sentence: 'Code aviliable' should be 'Code available'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and for recommending major revision. We address each major comment point by point below, providing clarifications and committing to revisions that improve transparency without altering the core claims or experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (4.4-point gain over vanilla backbone, 3.2-point gain over retrieval baselines, and effective 50% table compression) are presented without any information on datasets, number of runs, statistical significance, ablation studies, or confirmation that training data, optimizer (LR, schedule, steps, batch size), and evaluation protocols were identical across X-GRAM and all baselines. This is load-bearing for attributing observed deltas to hybrid hashing, alias mixing, normalized SwiGLU ShortConv, and depth-aware gating rather than uncontrolled experimental differences.
Authors: We agree that the abstract's brevity leaves the empirical claims insufficiently contextualized for immediate attribution. The manuscript body details the evaluation benchmarks, confirms identical training data, optimizer settings, learning-rate schedules, step counts, batch sizes, and evaluation protocols across all compared models, reports results over multiple runs, and includes ablations isolating the contributions of hybrid hashing, alias mixing, normalized SwiGLU ShortConv, and depth-aware gating. To address the referee's concern directly in the abstract itself, we will revise it to concisely note the matched experimental conditions and reference the ablation results. We have also added statistical significance markers to the main results tables. revision: yes
-
Referee: [Abstract] Abstract: The 50% table-size configuration is described as achieving the reported gains, but it is unclear whether this ratio is an output of the X-GRAM design or an arbitrary fixed choice; no derivation or sensitivity analysis ties the compression factor to the frequency-aware mechanisms.
Authors: The 50% table-size configuration is not arbitrary; it is a direct demonstration of the frequency-aware mechanisms (hybrid hashing plus alias mixing) that compress the Zipfian tail while retaining head capacity. We will revise the manuscript to include both a brief derivation linking the compression ratio to the observed token-frequency statistics and a sensitivity analysis across a range of table-size ratios, showing that the accuracy gains remain stable under the proposed design. revision: yes
Circularity Check
No circularity: empirical framework with independent evaluations
full rationale
The paper proposes X-GRAM as a frequency-aware framework using hybrid hashing, alias mixing, normalized SwiGLU ShortConv, and depth-aware gating to address stated limitations in token lookup tables. It then reports empirical accuracy gains at 0.73B and 1.15B scales with 50% table size. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-citations. The central claims rest on experimental comparisons rather than tautological outputs, with no load-bearing self-citation chains or ansatz smuggling. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 50% table size configuration
axioms (2)
- domain assumption Token frequencies follow a Zipfian distribution that causes under-training of the long tail
- domain assumption Demand for embedding capacity is heterogeneous across model layers
invented entities (1)
-
X-GRAM framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2503.15798. 2 Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, and Wenfeng Liang. Conditional memory via scalable lookup: A new axis of sparsity for large language models,
- [2]
-
[3]
URL https: //arxiv.org/abs/2502.01637. 4 Ranajoy Sadhukhan, Sheng Cao, Harry Dong, Changsheng Zhao, Attiano Purpura- Pontoniere, Yuandong Tian, Zechun Liu, and Beidi Chen. Stem: Scaling transformers with embedding modules,
-
[4]
URLhttps://arxiv.org/abs/2601.10639. 5 Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Allyson Ettinger, Michal Guerquin, David He...
-
[5]
URLhttps://arxiv.org/abs/2501.00656. 6 Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Rein- hard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas,...
work page internal anchor Pith review arXiv
-
[6]
URLhttps://arxiv.org/abs/2406.11794. 7 Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, M...
-
[7]
URLhttps://arxiv.org/abs/2402.00159. 8 Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, Jason Phang, Laria Reynolds, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot 18 language model evaluation. InZenodo. https://doi.org...
-
[8]
URL https://arxiv.org/abs/2501.16975. 10 Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Az- zolini, et al. Deep learning recommendation model for personalization and recommendation systems.arXiv preprint arXiv:1906.00091,
-
[9]
Ginart, Maxim Naumov, Dheevatsa Mudigere, Jiyan Yang, and James Zou
11 Antonio A. Ginart, Maxim Naumov, Dheevatsa Mudigere, Jiyan Yang, and James Zou. Mixed dimension embeddings with application to memory-efficient recommendation systems. In 2021 IEEE International Symposium on Information Theory (ISIT), pages 2786–2791. IEEE,
2021
-
[10]
In defense of parameter sharing for model- compression.arXiv preprint arXiv:2310.11611,
15 Aditya Desai and Anshumali Shrivastava. In defense of parameter sharing for model- compression.arXiv preprint arXiv:2310.11611,
-
[11]
arXiv preprint arXiv:1809.10853 , year=
16 Alexei Baevski and Michael Auli. Adaptive input representations for neural language modeling.arXiv preprint arXiv:1809.10853,
-
[12]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
URL https: //arxiv.org/abs/1701.06538. 19 Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
URL https://arxiv.org/abs/ 2006.16668. 20 William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.The Journal of Machine Learning Research, 23(1):5232–5270,
work page internal anchor Pith review arXiv 2006
-
[14]
URLhttps://arxiv.org/abs/2401.04088. 22 Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL https://arxiv.org/abs/ 2401.06066. 23 Jan Ludziejewski, Jakub Krajewski, Kamil Adamczewski, Maciej Pióro, Michał Krutul, Szymon Antoniak, Kamil Ciebiera, Krystian Król, Tomasz Odrzygó´ zd´ z, Piotr Sankowski, Marek Cygan, and Sebastian Jaszczur. Scaling laws for fine-grained mixture of experts. In Proceedings of the 41st International Conference on Ma...
work page internal anchor Pith review arXiv
-
[16]
25 Yutian Zhou, Tao Lei, Henry Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al
URL https://proceedings.neurips.cc/paper/2021/hash/92bf5e6240737e0326ea59846a8 3e076-Abstract.html. 25 Yutian Zhou, Tao Lei, Henry Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing. InAdvances in Neural Information Processing Systems,
2021
-
[17]
URLhttps://arxiv.org/abs/2410.17897. 29 Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages...
-
[18]
We report the architectural hyperparameters that fully determine the compute profile of the Transformer blocks
Backbone configurations used in our experiments. We report the architectural hyperparameters that fully determine the compute profile of the Transformer blocks. Backbone setting SM A L LME D I U M Layers (𝐿) 10 12 Model width (𝑑) 1536 2048 FFN width (𝑑 ff ) 4096 5120 Attention heads (ℎ) 12 16 KV heads (ℎ kv ) 6 8 Sequence length 8192 8192 Vocabulary size ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.