Recognition: unknown
AEL: Agent Evolving Learning for Open-Ended Environments
Pith reviewed 2026-05-09 22:21 UTC · model grok-4.3
The pith
A two-timescale framework lets LLM agents improve across sequential tasks by pairing bandit memory selection with reflection-based failure diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
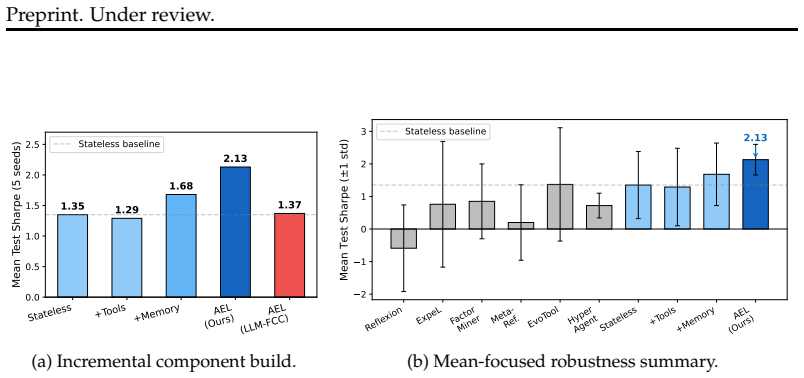
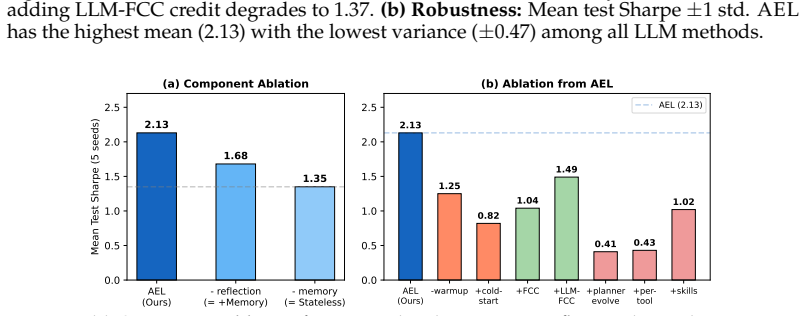
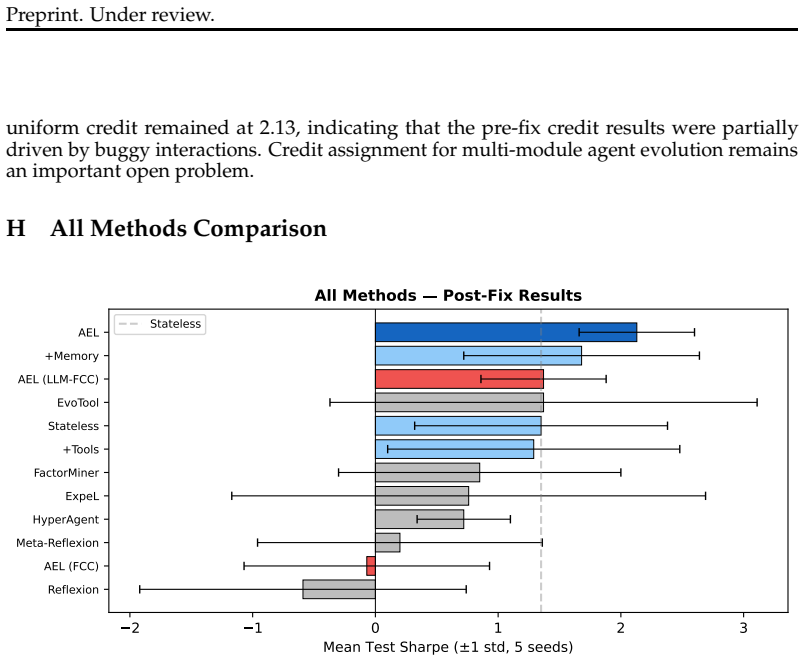
Agent Evolving Learning combines a fast Thompson Sampling bandit that chooses memory retrieval policies per episode with a slow LLM reflection process that diagnoses failure patterns and injects causal interpretive insights into the agent's decision prompt. This two-timescale setup turns past outcomes into an evolving strategy. On the sequential portfolio benchmark, it reaches a Sharpe ratio of 2.13±0.47, outperforming five published self-improving methods and all non-LLM baselines while showing the lowest variance among LLM approaches. Ablation variants confirm that memory and reflection together deliver a 58 percent cumulative gain over the stateless baseline, but every tested addition (pl
What carries the argument
The two-timescale AEL framework: a Thompson Sampling bandit selects retrieval policies on the fast scale while LLM-driven reflection diagnoses failures and supplies causal insights on the slow scale.
If this is right
- Memory retrieval guided by a bandit plus reflection-driven diagnosis converts past outcomes into improved future behavior across hundreds of episodes.
- A less-is-more pattern holds: adding planner evolution, skill extraction, or multiple credit assignment methods reduces performance gains from the core memory-plus-reflection pair.
- LLM agents achieve higher and more stable returns than both non-LLM baselines and other self-improving agent methods on sequential portfolio tasks.
- The central obstacle to agent self-improvement is learning how to interpret and apply remembered experience rather than increasing architectural complexity.
Where Pith is reading between the lines
- The observed variance reduction implies that structured reflection may stabilize agent decisions in other high-uncertainty sequential domains beyond finance.
- If reflection quality can be improved independently, the framework might scale to environments with episode counts far beyond 208 by iteratively sharpening the agent's interpretive frame.
- The degradation from extra mechanisms suggests testing whether similar less-is-more effects appear when AEL is applied to non-financial open-ended tasks such as game environments or workflow automation.
Load-bearing premise
LLM reflection can reliably diagnose failure patterns and insert accurate causal insights into prompts without adding noise or misleading interpretations that hurt later performance.
What would settle it
Disabling the reflection step or replacing it with random or generic prompts on the same 208-episode benchmark and checking whether the Sharpe ratio falls to or below the stateless baseline level would test whether the diagnostic insights are doing the claimed work.
Figures



read the original abstract
LLM agents increasingly operate in open-ended environments spanning hundreds of sequential episodes, yet they remain largely stateless: each task is solved from scratch without converting past experience into better future behavior. The central obstacle is not \emph{what} to remember but \emph{how to use} what has been remembered, including which retrieval policy to apply, how to interpret prior outcomes, and when the current strategy itself must change. We introduce \emph{Agent Evolving Learning} (\ael{}), a two-timescale framework that addresses this obstacle. At the fast timescale, a Thompson Sampling bandit learns which memory retrieval policy to apply at each episode; at the slow timescale, LLM-driven reflection diagnoses failure patterns and injects causal insights into the agent's decision prompt, giving it an interpretive frame for the evidence it retrieves. On a sequential portfolio benchmark (10 sector-diverse tickers, 208 episodes, 5 random seeds), \ael{} achieves a Sharpe ratio of 2.13$\pm$0.47, outperforming five published self-improving methods and all non-LLM baselines while maintaining the lowest variance among all LLM-based approaches. A nine-variant ablation reveals a ``less is more'' pattern: memory and reflection together produce a 58\% cumulative improvement over the stateless baseline, yet every additional mechanism we test (planner evolution, per-tool selection, cold-start initialization, skill extraction, and three credit assignment methods) \emph{degrades} performance. This demonstrates that the bottleneck in agent self-improvement is \emph{self-diagnosing how to use} experience rather than adding architectural complexity. Code and data: https://github.com/WujiangXu/AEL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Agent Evolving Learning (AEL), a two-timescale framework for LLM agents operating over hundreds of sequential episodes in open-ended environments. The fast timescale employs a Thompson Sampling bandit to select among memory retrieval policies; the slow timescale uses LLM reflection to diagnose failure patterns and inject causal interpretive frames into the agent's prompt. On a sequential portfolio benchmark (10 sector-diverse tickers, 208 episodes, 5 random seeds), AEL reports a Sharpe ratio of 2.13±0.47, outperforming five published self-improving LLM methods and all non-LLM baselines while showing the lowest variance among LLM approaches. A nine-variant ablation study finds that memory plus reflection yields a 58% cumulative gain over the stateless baseline, yet every additional mechanism tested (planner evolution, per-tool selection, cold-start initialization, skill extraction, and three credit-assignment variants) degrades performance, supporting a 'less is more' conclusion.
Significance. If the empirical results and ablation hold, the work supplies concrete evidence that the primary bottleneck in LLM agent self-improvement is learning how to use accumulated experience rather than adding architectural components. The 'less is more' pattern from the controlled ablation, combined with outperformance on an external sequential benchmark against published baselines, offers a falsifiable counter-example to the prevailing trend of increasingly elaborate agent systems. The provision of code and data further strengthens reproducibility.
major comments (3)
- [Methods (reflection component)] Methods, slow-timescale reflection description: the central claim that LLM reflection 'diagnoses failure patterns and injects causal insights' is load-bearing for both the two-timescale framing and the attribution of the 58% gain to memory+reflection. No direct measurement of reflection quality (human ratings of diagnostic accuracy, inter-seed consistency, or correlation between injected insights and subsequent episode-level performance deltas) is reported. Without such a check, the observed gains could be driven primarily by the Thompson Sampling bandit or incidental prompt effects rather than accurate causal diagnosis.
- [Experiments (ablation study)] Experiments, ablation table (nine variants): while the 'less is more' pattern is clearly shown, the table reports only point estimates and the main-result ±0.47 interval; no per-variant standard errors, p-values, or statistical tests on the performance degradations are provided. This makes it difficult to assess whether the degradation from added mechanisms is robust or could be explained by variance in the 5-seed runs.
- [Experiments (benchmark)] Results, benchmark description: the portfolio task uses 10 fixed tickers over 208 episodes. It is unclear whether the environment satisfies the 'open-ended' criterion stated in the introduction (novel task discovery, unbounded state spaces, or non-stationary objectives), which affects how far the 'less is more' conclusion generalizes beyond this specific sequential decision setting.
minor comments (2)
- [Abstract and Introduction] Abstract and §1: the phrase 'parameter-free' is used for the overall framework, yet the Thompson Sampling priors are listed as free parameters; clarify whether the priors are fixed across all experiments or tuned.
- [Figure 1] Figure 1 (framework diagram, if present): ensure the two timescales are visually distinguished and that the injection of reflection output into the prompt is explicitly labeled.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications and indicating revisions where the manuscript can be strengthened without misrepresenting the results.
read point-by-point responses
-
Referee: Methods, slow-timescale reflection description: the central claim that LLM reflection 'diagnoses failure patterns and injects causal insights' is load-bearing for both the two-timescale framing and the attribution of the 58% gain to memory+reflection. No direct measurement of reflection quality (human ratings of diagnostic accuracy, inter-seed consistency, or correlation between injected insights and subsequent episode-level performance deltas) is reported. Without such a check, the observed gains could be driven primarily by the Thompson Sampling bandit or incidental prompt effects rather than accurate causal diagnosis.
Authors: We agree that direct quantitative validation of reflection quality (e.g., human ratings or explicit correlation metrics) would provide stronger causal attribution. The current evidence is indirect, relying on the controlled ablation where memory+reflection alone accounts for the 58% gain while additional mechanisms degrade results, and on the separation of timescales (Thompson Sampling selects retrieval policies independently of the reflection content). In revision we will add representative examples of reflection outputs alongside corresponding episode performance changes in a new appendix section to illustrate the diagnostic and causal-injection process. revision: partial
-
Referee: Experiments, ablation table (nine variants): while the 'less is more' pattern is clearly shown, the table reports only point estimates and the main-result ±0.47 interval; no per-variant standard errors, p-values, or statistical tests on the performance degradations are provided. This makes it difficult to assess whether the degradation from added mechanisms is robust or could be explained by variance in the 5-seed runs.
Authors: We acknowledge that reporting only point estimates for the ablations limits assessment of robustness. The main result already includes the ±0.47 interval computed over 5 seeds; the ablation variants were run under identical conditions but summarized as means. In the revised manuscript we will add per-variant standard errors (computed from the 5 seeds) to the ablation table and include a brief note on pairwise comparisons where the degradation exceeds one standard error. revision: yes
-
Referee: Results, benchmark description: the portfolio task uses 10 fixed tickers over 208 episodes. It is unclear whether the environment satisfies the 'open-ended' criterion stated in the introduction (novel task discovery, unbounded state spaces, or non-stationary objectives), which affects how far the 'less is more' conclusion generalizes beyond this specific sequential decision setting.
Authors: The benchmark satisfies open-endedness through non-stationary market dynamics (price and volume processes evolve continuously across 208 episodes with no fixed task distribution), unbounded state spaces (continuous real-valued observations), and the requirement for ongoing adaptation without episode-level resets to a known distribution. While the set of 10 tickers is fixed, the objective and state transitions remain non-stationary and unbounded in time. We will revise the introduction and benchmark section to explicitly map these properties to the open-ended criteria and note the scope of generalization. revision: partial
Circularity Check
Empirical framework evaluated on external benchmark; no derivation reduces to inputs by construction
full rationale
The manuscript introduces a two-timescale agent framework (Thompson Sampling bandit at fast scale, LLM reflection at slow scale) and reports its Sharpe ratio on a held-out sequential portfolio benchmark (10 tickers, 208 episodes). No equations define a target quantity in terms of itself, no fitted parameters are relabeled as predictions, and no self-citations supply load-bearing uniqueness theorems or ansatzes. Ablation results are independent measurements on the same external data. The central claim therefore rests on observable performance rather than tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Thompson Sampling prior parameters
axioms (1)
- domain assumption LLMs can diagnose failure patterns and generate useful causal insights from past episodes
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review arXiv
-
[3]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ExpeL: LLM Agents Are Experiential Learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[4]
Evotool: Self-evolving tool-use policy optimization in llm agents via blame-aware mutation and diversity-aware selection , author=. arXiv preprint arXiv:2603.04900 , year=
-
[5]
arXiv preprint arXiv:2602.14670 , year=
FactorMiner: A Self-Evolving Agent with Skills and Experience Memory for Financial Alpha Discovery , author=. arXiv preprint arXiv:2602.14670 , year=
-
[6]
arXiv preprint arXiv:2509.03990 , year=
Meta-Policy Reflexion: Reusable Reflective Memory and Rule Admissibility for Resource-Efficient LLM Agent , author=. arXiv preprint arXiv:2509.03990 , year=
-
[7]
AutoAgent: Evolving Cognition and Elastic Memory Orchestration for Adaptive Agents , author=. arXiv preprint arXiv:2603.09716 , year=
-
[8]
arXiv preprint arXiv:2603.05578 , year=
Tool-Genesis: A Task-Driven Tool Creation Benchmark for Self-Evolving Language Agent , author=. arXiv preprint arXiv:2603.05578 , year=
-
[9]
arXiv preprint arXiv:2602.21158 , year=
SELAUR: Self Evolving LLM Agent via Uncertainty-aware Rewards , author=. arXiv preprint arXiv:2602.21158 , year=
-
[10]
arXiv preprint arXiv:2603.08403 , year=
SPIRAL: A Closed-Loop Framework for Self-Improving Action World Models via Reflective Planning Agents , author=. arXiv preprint arXiv:2603.08403 , year=
-
[11]
arXiv preprint arXiv:2603.10291 , year=
Hybrid Self-evolving Structured Memory for GUI Agents , author=. arXiv preprint arXiv:2603.10291 , year=
-
[12]
arXiv preprint arXiv:2603.10600 , year=
Trajectory-Informed Memory Generation for Self-Improving Agent Systems , author=. arXiv preprint arXiv:2603.10600 , year=
-
[13]
Proceedings of the 19th International Conference on World Wide Web , pages=
A Contextual-Bandit Approach to Personalized News Article Recommendation , author=. Proceedings of the 19th International Conference on World Wide Web , pages=
-
[14]
Advances in Neural Information Processing Systems , volume=
An Empirical Evaluation of Thompson Sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 25th Annual Conference on Learning Theory , pages=
Analysis of Thompson Sampling for the Multi-Armed Bandit Problem , author=. Proceedings of the 25th Annual Conference on Learning Theory , pages=
-
[16]
Contributions to the Theory of Games , volume=
A Value for n-Person Games , author=. Contributions to the Theory of Games , volume=. 1953 , publisher=
1953
-
[17]
Proceedings of the 36th International Conference on Machine Learning , pages=
Data Shapley: Equitable Valuation of Data for Machine Learning , author=. Proceedings of the 36th International Conference on Machine Learning , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
A Unified Approach to Interpreting Model Predictions , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , journal=
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , journal=
-
[20]
Proceedings of the 12th International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. Proceedings of the 12th International Conference on Learning Representations , year=
-
[21]
GAIA: a benchmark for General AI Assistants
Mialon, Gr\'. arXiv preprint arXiv:2311.12983 , year=
work page internal anchor Pith review arXiv
-
[22]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , journal=
-
[23]
OpenHands: An Open Platform for
Wang, Xingyao and others , journal=. OpenHands: An Open Platform for
-
[24]
Agentless: Demystifying
Xia, Chunqiu Steven and Deng, Yinlin and Dunn, Soren and Zhang, Lingming , journal=. Agentless: Demystifying
-
[25]
Advances in Neural Information Processing Systems , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Advances in Neural Information Processing Systems , title =
-
[26]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal=
-
[28]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[29]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review arXiv
-
[30]
and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E
Packer, Charles and Fang, Vivian and Patil, Shishir G. and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E. , journal=
-
[31]
A Survey on the Memory Mechanism of Large Language Model based Agents
A Survey on the Memory Mechanism of Large Language Model based Agents , author=. arXiv preprint arXiv:2404.13501 , year=
work page internal anchor Pith review arXiv
-
[32]
Understanding the Planning of
Huang, Xu and Liu, Weiwen and Chen, Xiaolong and Wang, Xingmei and Wang, Hao and Lian, Defu and Wang, Yasheng and Chen, Lifeng and others , journal=. Understanding the Planning of
-
[33]
Advances in Neural Information Processing Systems , volume=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and others , journal=
-
[35]
Hyperagents.arXiv preprint arXiv:2603.19461, 2026
Hyperagents , author=. arXiv , year=. 2603.19461 , archivePrefix=
-
[36]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[37]
Machine Learning , volume=
Finite-Time Analysis of the Multiarmed Bandit Problem , author=. Machine Learning , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.