Recognition: unknown
Who Defines "Best"? Towards Interactive, User-Defined Evaluation of LLM Leaderboards
Pith reviewed 2026-05-09 21:54 UTC · model grok-4.3
The pith
LLM leaderboards can be redesigned so users select and weight prompt slices to create their own model rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that leaderboard rankings are not universal but depend on the distribution and weighting of prompts in the underlying data, and that an interactive interface allowing users to define their own prompt slices and weights can surface these dependencies and produce context-specific rankings, as shown by dataset skew analysis, ranking variation across slices, and a qualitative probe study with the tool.
What carries the argument
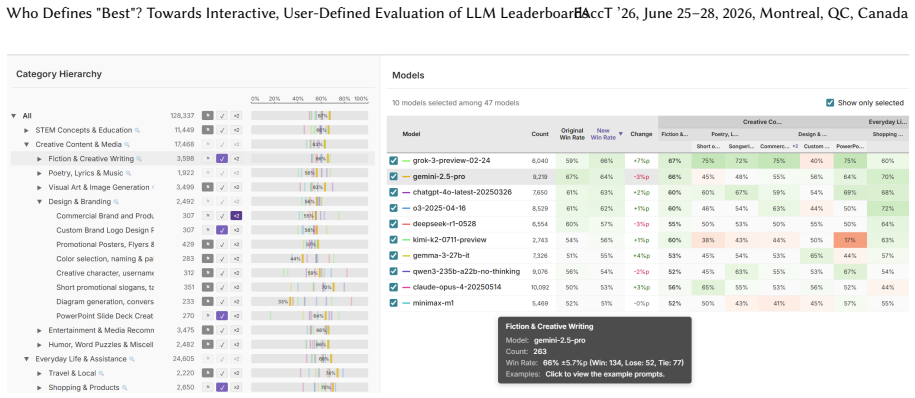
The interactive visualization interface that lets users select prompt slices from the dataset, assign weights to them, and dynamically recompute model rankings to reflect chosen priorities.
If this is right
- Model rankings change when users emphasize different prompt topics or types in the dataset.
- Dataset analysis can identify skews in topic coverage and the scope of preference judgments.
- Users gain a way to align evaluations directly with their own constraints and objectives.
- Leaderboards could move from single aggregate scores to multiple user-defined views.
Where Pith is reading between the lines
- Organizations might embed similar interfaces in internal model selection workflows to incorporate domain-specific or safety-focused priorities.
- Releasing more granular prompt metadata from benchmarks could enable broader customization across different leaderboards.
- Custom rankings produced this way could be tested for better alignment with downstream task success than static aggregates.
- The same slice-and-weight approach might extend to evaluations in other AI domains that rely on preference data.
Load-bearing premise
That users can select and weight prompt slices in ways that genuinely capture their real evaluation needs without the choices creating new distortions or oversights.
What would settle it
A study in which people with documented deployment goals use the interface to produce custom rankings and those rankings are then checked against independent measures of model performance in the users' actual contexts.
Figures


read the original abstract
LLM leaderboards are widely used to compare models and guide deployment decisions. However, leaderboard rankings are shaped by evaluation priorities set by benchmark designers, rather than by the diverse goals and constraints of actual users and organizations. A single aggregate score often obscures how models behave across different prompt types and compositions. In this work, we conduct an in-depth analysis of the dataset used in the LMArena (formerly Chatbot Arena) benchmark and investigate this evaluation challenge by designing an interactive visualization interface as a design probe. Our analysis reveals that the dataset is heavily skewed toward certain topics, that model rankings vary across prompt slices, and that preference-based judgments are used in ways that blur their intended scope. Building on this analysis, we introduce a visualization interface that allows users to define their own evaluation priorities by selecting and weighting prompt slices and to explore how rankings change accordingly. A qualitative study suggests that this interactive approach improves transparency and supports more context-specific model evaluation, pointing toward alternative ways to design and use LLM leaderboards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the LMArena (Chatbot Arena) benchmark dataset, finding heavy skew toward certain topics, variation in model rankings across prompt slices, and ambiguous use of preference judgments. It introduces an interactive visualization interface as a design probe that lets users select and weight prompt slices to define custom evaluation priorities and observe resulting ranking changes. A qualitative study is reported to suggest that the interface improves transparency and enables more context-specific model evaluation.
Significance. If the interface and qualitative findings hold, the work usefully highlights how fixed leaderboards embed designer priorities that may not match user needs, and demonstrates a concrete alternative via slice-based customization. The design-probe framing and focus on prompt composition are strengths that could inform future benchmark design. However, the absence of quantitative validation (e.g., inter-rater agreement on slices, ranking stability metrics, or controlled comparison to static leaderboards) limits the strength of the claim that user-defined evaluation is demonstrably superior or bias-free.
major comments (2)
- [Section 5 (Qualitative Study)] Section 5 (Qualitative Study): the claim that the interface 'improves transparency and supports more context-specific model evaluation' rests on an opaque qualitative component with no reported participant count, recruitment method, task protocol, or analysis procedure. Without these details it is impossible to assess whether the observed benefits are robust or whether slice selection/weighting introduces new user-specific biases or instability.
- [Section 3 (Dataset Analysis)] Section 3 (Dataset Analysis): the central motivation—that the dataset is 'heavily skewed' and that 'model rankings vary across prompt slices'—is asserted without reference to concrete statistics (topic-frequency tables, variance measures, or statistical tests for ranking shifts). These numbers are load-bearing for justifying the interactive interface; their omission leaves the design rationale under-supported.
minor comments (2)
- [Abstract] Abstract and Section 2: the phrase 'preference-based judgments are used in ways that blur their intended scope' is stated without an example or citation to the specific LMArena judgment format, reducing clarity for readers unfamiliar with the benchmark.
- [Section 4 (Interface)] Figure captions and interface description: labels for the visualization (e.g., how weights are applied, how slices are displayed) could be more precise to allow replication of the probe.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that the manuscript would benefit from expanded methodological details in the qualitative study and more explicit statistical support in the dataset analysis. We will revise accordingly to strengthen these sections while preserving the design-probe framing of the work.
read point-by-point responses
-
Referee: Section 5 (Qualitative Study): the claim that the interface 'improves transparency and supports more context-specific model evaluation' rests on an opaque qualitative component with no reported participant count, recruitment method, task protocol, or analysis procedure. Without these details it is impossible to assess whether the observed benefits are robust or whether slice selection/weighting introduces new user-specific biases or instability.
Authors: We acknowledge that the current reporting of the qualitative study is insufficiently detailed. In the revised manuscript we will expand Section 5 to explicitly state the participant count, recruitment approach, task protocol (including think-aloud instructions and slice-selection scenarios), and analysis procedure (thematic coding with reliability checks). These additions will allow readers to evaluate the robustness of the reported benefits and to consider any limitations, including the possibility of user-specific biases introduced by the customization features. We maintain that the study was intentionally exploratory as a design probe, but we agree that greater transparency is required. revision: yes
-
Referee: Section 3 (Dataset Analysis): the central motivation—that the dataset is 'heavily skewed' and that 'model rankings vary across prompt slices'—is asserted without reference to concrete statistics (topic-frequency tables, variance measures, or statistical tests for ranking shifts). These numbers are load-bearing for justifying the interactive interface; their omission leaves the design rationale under-supported.
Authors: The referee correctly identifies that concrete supporting statistics were not presented in the main text. Although the underlying analysis computed topic distributions and ranking variations, these were not reported with sufficient granularity. In the revision we will add to Section 3 a topic-frequency table, quantitative measures of ranking variance across slices, and results from statistical tests (e.g., rank correlation or distance metrics) demonstrating the observed shifts. This will provide a clearer empirical basis for the motivation and for the subsequent design of the interactive tool. revision: yes
Circularity Check
No circularity: independent dataset analysis and design probe
full rationale
The paper conducts an empirical analysis of the external LMArena public benchmark dataset, documenting topic skew, slice-dependent ranking shifts, and judgment-scope issues. It then presents an interactive visualization interface as a design probe allowing user-defined slice selection and weighting. A qualitative study is offered as suggestive evidence of improved transparency. None of the load-bearing steps reduce to self-definition, fitted-input-as-prediction, or self-citation chains. The derivation is linear and grounded in external data plus a separate user study; no equations, parameter fits, or uniqueness theorems are invoked that collapse back to the paper's own inputs. This is the expected non-circular outcome for an analysis-plus-probe paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The LMArena dataset is representative of broader LLM evaluation challenges and prompt distributions.
- ad hoc to paper Users can effectively define and apply their evaluation priorities by selecting and weighting prompt slices.
Reference graph
Works this paper leans on
-
[1]
Lora Aroyo and Chris Welty. 2015. Truth is a lie: Crowd truth and the seven myths of human annotation.AI Magazine36, 1 (2015), 15–24
2015
-
[2]
Solon Barocas, Anhong Guo, Ece Kamar, Jacquelyn Krones, Meredith Ringel Morris, Jennifer Wortman Vaughan, W Duncan Wadsworth, and Hanna Wallach. 2021. Designing disaggregated evaluations of ai systems: Choices, considerations, and tradeoffs. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. 368–378
2021
-
[3]
Meriem Boubdir, Edward Kim, Beyza Ermis, Sara Hooker, and Marzieh Fadaee. 2024. Elo uncovered: Robustness and best practices in language model evaluation.Advances in Neural Information Processing Systems (NeurIPS)37 (2024), 106135–106161
2024
-
[4]
Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on Fairness, Accountability and Transparency. PMLR, 77–91
2018
-
[5]
Ángel Alexander Cabrera, Will Epperson, Fred Hohman, Minsuk Kahng, Jamie Morgenstern, and Duen Horng Chau. 2019. FairVis: Visual analytics for discovering intersectional bias in machine learning. In2019 IEEE Conference on Visual Analytics Science and Technology (V AST). IEEE, 46–56
2019
-
[6]
Ángel Alexander Cabrera, Erica Fu, Donald Bertucci, Kenneth Holstein, Ameet Talwalkar, Jason I Hong, and Adam Perer. 2023. Zeno: An interactive framework for behavioral evaluation of machine learning. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI). 1–14
2023
- [7]
-
[8]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning (ICML)
2024
-
[9]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models.Journal of Machine Learning Research25, 70 (2024), 1–53
2024
-
[10]
Anamaria Crisan, Margaret Drouhard, Jesse Vig, and Nazneen Rajani. 2022. Interactive model cards: A human-centered approach to model documentation. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 427–439
2022
-
[11]
Fernando Diaz and Michael Madaio. 2024. Scaling laws do not scale. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 341–357
2024
-
[12]
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. 2024. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475(2024)
work page internal anchor Pith review arXiv 2024
-
[13]
Benjamin Feuer, Micah Goldblum, Teresa Datta, Sanjana Nambiar, Raz Besaleli, Samuel Dooley, Max Cembalest, and John P Dickerson
-
[14]
Style outweighs substance: Failure modes of llm judges in alignment benchmarking.The Thirteenth International Conference on Learning Representation (ICLR)(2024)
2024
-
[15]
2013.Statistical methods for rates and proportions
Joseph L Fleiss, Bruce Levin, and Myunghee Cho Paik. 2013.Statistical methods for rates and proportions. john wiley & sons
2013
-
[16]
Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios Nikolas Angelopoulos, and Ion Stoica. 2025. Prompt-to-Leaderboard: Prompt-Adaptive LLM Evaluations. InForty-second International Conference on Machine Learning (ICML)
2025
-
[17]
Mitchell L Gordon, Michelle S Lam, Joon Sung Park, Kayur Patel, Jeff Hancock, Tatsunori Hashimoto, and Michael S Bernstein. 2022. Jury learning: Integrating dissenting voices into machine learning models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–19
2022
-
[18]
Samuel Gratzl, Alexander Lex, Nils Gehlenborg, Hanspeter Pfister, and Marc Streit. 2013. Lineup: Visual analysis of multi-attribute rankings.IEEE Transactions on Visualization and Computer Graphics (VIS)19, 12 (2013), 2277–2286
2013
-
[19]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding.International Conference on Learning Representations (ICLR)(2021)
2021
-
[20]
Christine Herlihy, Kimberly Truong, Alexandra Chouldechova, and Miroslav Dudík. 2024. A structured regression approach for evaluating model performance across intersectional subgroups. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 313–325
2024
-
[21]
Walfrand, Jarvis Jin, Marie Tano, Ahmad Beirami, Erin van Liemt, Nithum Thain, Hakim Sidahmed, and Lucas Dixon
Jessica Hoffmann, Christiane Ahlheim, Zac Yu, Aria D. Walfrand, Jarvis Jin, Marie Tano, Ahmad Beirami, Erin van Liemt, Nithum Thain, Hakim Sidahmed, and Lucas Dixon. 2025. Improving Neutral Point-of-View Generation with Data- and Parameter-Efficient RL. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)(2025)
2025
-
[22]
Yangsibo Huang, Milad Nasr, Anastasios Angelopoulos, Nicholas Carlini, Wei-Lin Chiang, Christopher A Choquette-Choo, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Ken Ziyu Liu, et al. 2025. Exploring and mitigating adversarial manipulation of voting-based leaderboards.Forty-second International Conference on Machine Learning (ICML)(2025)
2025
-
[23]
Minsuk Kahng, Ian Tenney, Mahima Pushkarna, Michael Xieyang Liu, James Wexler, Emily Reif, Krystal Kallarackal, Minsuk Chang, Michael Terry, and Lucas Dixon. 2025. LLM Comparator: Interactive analysis of side-by-side evaluation of large language models.IEEE Transactions on Visualization and Computer Graphics (VIS)31, 1 (2025), 503–513. Who Defines "Best"?...
2025
-
[24]
Misha Khodak, Lester Mackey, Alexandra Chouldechova, and Miro Dudik. 2024. SureMap: Simultaneous mean estimation for single-task and multi-task disaggregated evaluation.Advances in Neural Information Processing Systems (NeurIPS)37 (2024), 21601–21635
2024
-
[25]
Tae Soo Kim, Yoonjoo Lee, Jamin Shin, Young-Ho Kim, and Juho Kim. 2024. EvalLM: Interactive evaluation of large language model prompts on user-defined criteria. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21
2024
-
[26]
Bernard Koch, Emily Denton, Alex Hanna, and Jacob G Foster. 2021. Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research.Proceedings of the Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks1 (2021)
2021
-
[27]
2018.Content analysis: An introduction to its methodology
Klaus Krippendorff. 2018.Content analysis: An introduction to its methodology. Sage publications
2018
-
[28]
Preethi Lahoti, Nicholas Blumm, Xiao Ma, Raghavendra Kotikalapudi, Sahitya Potluri, Qijun Tan, Hansa Srinivasan, Ben Packer, Ahmad Beirami, Alex Beutel, and Jilin Chen. 2023. Improving Diversity of Demographic Representation in Large Language Models via Collective-Critiques and Self-Voting. InProceedings of the 2023 Conference on Empirical Methods in Natu...
2023
-
[29]
Michelle S Lam, Janice Teoh, James A Landay, Jeffrey Heer, and Michael S Bernstein. 2024. Concept induction: Analyzing unstructured text with high-level concepts using lloom. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–28
2024
- [30]
-
[31]
Tianle Li, Wei-Lin Chiang, and Lisa Dunlap. 2024. Introducing Hard Prompts Category in Chatbot Arena. https://lmsys.org/blog/2024- 05-17-category-hard/
2024
-
[32]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. 2024. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline.Forty-second International Conference on Machine Learning (ICML)(2024)
2024
-
[33]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. 2022. Holistic evaluation of language models.Transactions on Machine Learning Research(2022)
2022
-
[34]
Zhiyi Ma, Kawin Ethayarajh, Tristan Thrush, Somya Jain, Ledell Wu, Robin Jia, Christopher Potts, Adina Williams, and Douwe Kiela
-
[35]
Dynaboard: An evaluation-as-a-service platform for holistic next-generation benchmarking.Advances in Neural Information Processing Systems (NeurIPS)34 (2021), 10351–10367
2021
-
[36]
Michael Madaio, Lisa Egede, Hariharan Subramonyam, Jennifer Wortman Vaughan, and Hanna Wallach. 2022. Assessing the fairness of ai systems: Ai practitioners’ processes, challenges, and needs for support.Proceedings of the ACM on Human-Computer Interaction6, CSCW1 (2022), 1–26
2022
-
[37]
Rui Min, Tianyu Pang, Chao Du, Qian Liu, Minhao Cheng, and Min Lin. 2025. Improving your model ranking on chatbot arena by vote rigging.Forty-second International Conference on Machine Learning (ICML)(2025)
2025
-
[38]
2012.Machine learning: a probabilistic perspective
Kevin P Murphy. 2012.Machine learning: a probabilistic perspective. MIT press
2012
-
[39]
Chris North. 2006. Toward measuring visualization insight.IEEE computer graphics and applications26, 3 (2006), 6–9
2006
-
[40]
Ziad Obermeyer, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. Dissecting racial bias in an algorithm used to manage the health of populations.Science366, 6464 (2019), 447–453
2019
-
[41]
Will Orr and Edward B Kang. 2024. AI as a sport: On the competitive epistemologies of benchmarking. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT). 1875–1884
2024
-
[42]
Stephan Pajer, Marc Streit, Thomas Torsney-Weir, Florian Spechtenhauser, Torsten Möller, and Harald Piringer. 2016. Weightlifter: Visual weight space exploration for multi-criteria decision making.IEEE Transactions on Visualization and Computer Graphics (VIS)23, 1 (2016), 611–620
2016
-
[43]
Stephen R Pfohl, Natalie Harris, Chirag Nagpal, David Madras, Vishwali Mhasawade, Olawale Salaudeen, Awa Dieng, Shannon Sequeira, Santiago Arciniegas, Lillian Sung, et al. 2025. Understanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness.arXiv preprint arXiv:2506.04193(2025)
-
[44]
Chau Minh Pham, Alexander Hoyle, Simeng Sun, Philip Resnik, and Mohit Iyyer. 2024. TopicGPT: A prompt-based topic modeling framework. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (NAACL). 2956–2984
2024
-
[45]
Reid Pryzant, Richard Diehl Martinez, Nathan Dass, Sadao Kurohashi, Dan Jurafsky, and Diyi Yang. 2020. Automatically neutralizing subjective bias in text. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 480–489
2020
-
[46]
Inioluwa Deborah Raji, Emily M Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna. 2021. AI and the everything in the whole wide world benchmark.Proceedings of the Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks (2021)
2021
-
[47]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). 4902–4912
2020
-
[48]
Mark Rofin, Vladislav Mikhailov, Mikhail Florinsky, Andrey Kravchenko, Tatiana Shavrina, Elena Tutubalina, Daniel Karabekyan, and Ekaterina Artemova. 2023. Vote’n’rank: Revision of benchmarking with social choice theory. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 670–686. FAccT ’26, June ...
2023
-
[49]
Jinwook Seo and Ben Shneiderman. 2005. A rank-by-feature framework for interactive exploration of multidimensional data.Information Visualization4, 2 (2005), 96–113
2005
-
[50]
Laleh Seyyed-Kalantari, Haoran Zhang, Matthew BA McDermott, Irene Y Chen, and Marzyeh Ghassemi. 2021. Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations.Nature medicine27, 12 (2021), 2176–2182
2021
-
[51]
Shreya Shankar, JD Zamfirescu-Pereira, Björn Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. Who validates the validators? aligning llm-assisted evaluation of llm outputs with human preferences. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–14
2024
- [52]
-
[53]
Shivalika Singh, Yiyang Nan, Alex Wang, Daniel D’Souza, Sayash Kapoor, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker. 2025. The leaderboard illusion. InAnnual Conference on Neural Information Processing Systems (NeurIPS)
2025
-
[54]
Venkatesh Sivaraman, Zexuan Li, and Adam Perer. 2025. Divisi: Interactive Search and Visualization for Scalable Exploratory Subgroup Analysis. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–17
2025
-
[55]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research(2023)
2023
-
[56]
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics (ACL). 13003–13051
2023
- [57]
- [58]
-
[59]
Vicuna Team. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03- 30-vicuna/
2023
-
[60]
Emily Wall, Subhajit Das, Ravish Chawla, Bharath Kalid‘indi, Eli T Brown, and Alex Endert. 2017. Podium: Ranking data using mixed-initiative visual analytics.IEEE Transactions on Visualization and Computer Graphics (VIS)24, 1 (2017), 288–297
2017
-
[61]
Junpeng Wang, Shixia Liu, and Wei Zhang. 2024. Visual analytics for machine learning: A data perspective survey.IEEE Transactions on Visualization and Computer Graphics (VIS)30, 12 (2024), 7637–7656
2024
-
[62]
Zihan Wang, Jingbo Shang, and Ruiqi Zhong. 2023. Goal-driven explainable clustering via language descriptions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). 10626–10649
2023
-
[63]
Minghao Wu and Alham Fikri Aji. 2025. Style over substance: Evaluation biases for large language models. InProceedings of the 31st International Conference on Computational Linguistics. 297–312
2025
-
[64]
Tongshuang Wu, Marco Tulio Ribeiro, Jeffrey Heer, and Daniel S Weld. 2019. Errudite: Scalable, reproducible, and testable error analysis. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). 747–763
2019
-
[65]
Guanhua Zhang and Moritz Hardt. 2024. Inherent trade-offs between diversity and stability in multi-task benchmarks. InProceedings of the 41st International Conference on Machine Learning (ICML). 58984–59002
2024
-
[66]
Xiaoyu Zhang, Jorge Piazentin Ono, Huan Song, Liang Gou, Kwan-Liu Ma, and Liu Ren. 2022. SliceTeller: A data slice-driven approach for machine learning model validation.IEEE Transactions on Visualization and Computer Graphics (VIS)29, 1 (2022), 842–852
2022
-
[67]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. WildChat: 1M ChatGPT interaction logs in the wild. InThe Twelfth International Conference on Learning Representations (ICLR)
2024
-
[68]
Child Clusters
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalea, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT-bench and chatbot arena.Advances in Neural Information Processing Systems (NeurIPS)36 (2023), 46595–46623. Who Defines "Best"? Towards Interact...
2023
-
[69]
Each reason should be 1-2 sentences, focusing on specific behaviors, qualities, or approaches
Winning Reasons: List 1-4 reasons why the winning model's response succeeded. Each reason should be 1-2 sentences, focusing on specific behaviors, qualities, or approaches
-
[70]
signature
Losing Reasons: List 1-4 reasons why the losing model's response failed. Each reason should be 1-2 sentences, focusing on specific shortcomings. ... A.3 Prompt Used for Analyzing Deterministic Math Questions in Section 3.3.1 A.3.1 Filtering Math Problems With Deterministic Answers. model: gpt-5.2-2025-12-11 You will be given a prompt. Your task is to dete...
2025
-
[71]
A concise response focuses on the core idea, key steps, or final result, while minimizing peripheral explanations
Conciseness: This criterion evaluates how directly and concisely the response addresses the question. A concise response focuses on the core idea, key steps, or final result, while minimizing peripheral explanations
-
[72]
Highly elaborative responses provide additional context, clarifications, motivations, or background explanations
Elaboration: Elaboration measures the extent to which the response goes beyond the minimum required answer. Highly elaborative responses provide additional context, clarifications, motivations, or background explanations
-
[73]
Structure-rich responses use explicit section headings, numbered steps, tables, code blocks, summaries, or conclusions to
Structure Richness: This criterion captures how formally and clearly the response is organized. Structure-rich responses use explicit section headings, numbered steps, tables, code blocks, summaries, or conclusions to
-
[74]
Strong performance includes step-by-step derivations, explicit intermediate steps, definitions, formulas, and sometimes alternative solution paths
Reasoning with Derivation: This dimension assesses how thoroughly the response develops its reasoning. Strong performance includes step-by-step derivations, explicit intermediate steps, definitions, formulas, and sometimes alternative solution paths. ... FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Minji Jung, Minjae Lee, Yejin Kim, Sarang Choi, and ...
2026
-
[75]
Rigorous responses explicitly state constraints, caveats, edge cases, and validation steps, such as checking conditions, discussing ambiguities,
Rigorous Assumption Handling: This criterion evaluates how carefully the response handles assumptions and limitations. Rigorous responses explicitly state constraints, caveats, edge cases, and validation steps, such as checking conditions, discussing ambiguities,
-
[76]
conciseness
User-Oriented Interaction: This dimension reflects how much the response is oriented toward ongoing interaction with the user. ... You must return a JSON object with the following keys: { "conciseness": "model_a" | "model_b" | "Both" | "None", "elaboration": "model_a" | "model_b" | "Both" | "None", ... "user_oriented_interaction": "model_a" | "model_b" | ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.