Recognition: unknown
Alignment has a Fantasia Problem
Pith reviewed 2026-05-09 21:33 UTC · model grok-4.3
The pith
AI alignment requires helping users form and refine their intent over time rather than assuming prompts fully express goals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
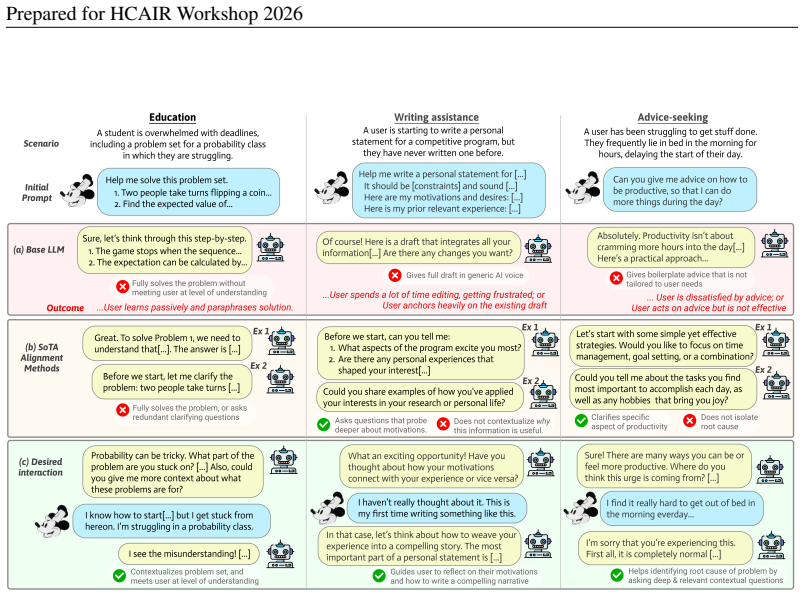
The paper's central claim is that Fantasia interactions occur when AI systems treat user prompts as complete expressions of intent, even though goals frequently form and change during the interaction process. Rather than treating users as rational oracles, AI should actively provide cognitive support to help form and refine intent over time. Achieving this requires an interdisciplinary synthesis of machine learning, interface design, and behavioral science to identify the mechanisms behind these failures, explain why existing interventions fall short, and outline a research agenda for designing and evaluating improved systems.
What carries the argument
Fantasia interactions: the mismatch in which AI follows an incomplete prompt as if it captured the user's full, stable intent, producing outputs that are compliant but misaligned with evolving needs.
If this is right
- Instruction-following alignment objectives will systematically produce convenient but ultimately misaligned outputs whenever user goals remain partially formed.
- AI interfaces must incorporate mechanisms such as reflective prompts or iterative clarification to support intent development across multiple turns.
- Alignment benchmarks should measure success by how well a system helps users resolve uncertainty rather than by immediate task completion alone.
- Insights from behavioral science on goal formation need to be translated into concrete AI design patterns and evaluation protocols.
- Current fixes like improved prompting remain insufficient because they continue to treat the initial prompt as the authoritative expression of intent.
Where Pith is reading between the lines
- This view suggests redesigning chat interfaces to include default goal-reflection steps before task execution begins.
- Safety evaluations may need to track how AI responses shape or stabilize user intent rather than only checking for immediate harm.
- The approach connects to human-computer interaction work on iterative refinement, offering ready patterns for implementation in AI tools.
- Adoption could reduce long-term user frustration in open-ended tasks by aligning outputs more closely with users' final understanding.
Load-bearing premise
Behavioral research on how people form goals applies directly to AI prompting and interaction, and AI can be redesigned to offer cognitive support without creating fresh misalignment risks.
What would settle it
A user study in which AI systems that provide explicit cognitive support for intent refinement produce no measurable improvement in final user satisfaction or goal alignment compared with standard instruction-following systems would falsify the central claim.
Figures

read the original abstract
Modern AI assistants are trained to follow instructions, implicitly assuming that users can clearly articulate their goals and the kind of assistance they need. Decades of behavioral research, however, show that people often engage with AI systems before their goals are fully formed. When AI systems treat prompts as complete expressions of intent, they can appear to be useful or convenient, but not necessarily aligned with the users' needs. We call these failures Fantasia interactions. We argue that Fantasia interactions demand a rethinking of alignment research: rather than treating users as rational oracles, AI should provide cognitive support by actively helping users form and refine their intent through time. This requires an interdisciplinary approach that bridges machine learning, interface design, and behavioral science. We synthesize insights from these fields to characterize the mechanisms and failures of Fantasia interactions. We then show why existing interventions are insufficient, and propose a research agenda for designing and evaluating AI systems that better help humans navigate uncertainty in their tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI assistants assume users articulate complete goals in prompts, but behavioral research shows goals often form during interaction, creating 'Fantasia interactions' where systems appear useful but fail to align with evolving user needs. It argues alignment research must shift from treating users as rational oracles to providing cognitive support for intent formation and refinement over time, synthesizes insights from machine learning, interface design, and behavioral science to characterize mechanisms and failures, shows why existing interventions are insufficient, and proposes an interdisciplinary research agenda.
Significance. If the argument holds, the work could reorient alignment research toward dynamic, user-centered intent support rather than static instruction following, highlighting a gap between current paradigms and real human goal formation. The synthesis of behavioral insights and the call for an agenda are constructive, though the absence of new empirical data or validated mechanisms limits the immediate technical impact.
major comments (2)
- [Section on existing interventions] In the section showing why existing interventions are insufficient, the manuscript asserts that current techniques (e.g., those based on instruction following or RLHF) fall short for Fantasia interactions but provides no specific counter-examples, failure cases, or direct comparisons to the behavioral literature; this assertion is load-bearing for the call to rethink alignment and requires concrete evidence.
- [Research agenda proposal] In the proposal for cognitive support via active intent refinement, the central claim that AI can feasibly help form and refine user intent without introducing new misalignment risks (such as imposing model priors on uncertain goals or creating dependency) is not supported by any safeguards, mechanisms, or risk analysis; this is load-bearing for the feasibility of the proposed research agenda.
minor comments (2)
- [Abstract] The abstract introduces 'Fantasia interactions' without a concise operational definition or etymology, which would help readers immediately grasp the core concept before the full synthesis.
- [Interdisciplinary synthesis] The manuscript would benefit from explicit discussion of how the proposed cognitive support differs from or extends existing HCI techniques for goal elicitation, to avoid overlap with prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments correctly identify areas where the manuscript would benefit from greater specificity and analysis. We address each major comment below, indicating revisions to be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: In the section showing why existing interventions are insufficient, the manuscript asserts that current techniques (e.g., those based on instruction following or RLHF) fall short for Fantasia interactions but provides no specific counter-examples, failure cases, or direct comparisons to the behavioral literature; this assertion is load-bearing for the call to rethink alignment and requires concrete evidence.
Authors: We agree that the original manuscript's synthesis of behavioral insights, while characterizing the mismatch between static instruction following and dynamic goal formation, does not supply explicit counter-examples or side-by-side comparisons. In the revised version we will add a dedicated subsection with concrete failure cases drawn from the cited behavioral and HCI literature. Examples will include users iteratively clarifying underspecified creative or planning tasks, where RLHF-optimized models overcommit to the initial prompt phrasing without scaffolding refinement, contrasted with empirical findings on goal emergence during interaction. These additions will directly support the claim that existing techniques are insufficient for Fantasia interactions. revision: yes
-
Referee: In the proposal for cognitive support via active intent refinement, the central claim that AI can feasibly help form and refine user intent without introducing new misalignment risks (such as imposing model priors on uncertain goals or creating dependency) is not supported by any safeguards, mechanisms, or risk analysis; this is load-bearing for the feasibility of the proposed research agenda.
Authors: This observation is accurate: the original agenda section outlines the direction of cognitive support but does not analyze or mitigate the specific new risks mentioned. We will revise the proposal to include an explicit discussion of these risks (model prior imposition and dependency formation) together with initial safeguards such as user-controlled refinement granularity, transparent signaling of model suggestions, and built-in evaluation criteria for over-reliance. We will position a fuller empirical risk analysis as an open item within the proposed interdisciplinary research agenda rather than asserting feasibility without support. revision: partial
Circularity Check
No circularity: argument synthesizes external literature without self-referential reduction
full rationale
The paper's core claim—that Fantasia interactions require rethinking alignment toward cognitive support for intent formation—is constructed as a synthesis of external behavioral science, interface design, and ML literature rather than any derivation that reduces to the paper's own inputs. No equations, fitted parameters, or self-citations appear as load-bearing steps; the definition of Fantasia interactions is explicitly tied to decades of cited behavioral research on goal formation, and the proposed research agenda follows from identifying gaps in existing interventions. This matches the default expectation for non-circular conceptual papers, with the central argument remaining independent of any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption People often engage with AI systems before their goals are fully formed, as shown by decades of behavioral research.
invented entities (1)
-
Fantasia interactions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2000 , publisher=
Behavioral economics , author=. 2000 , publisher=
2000
-
[5]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[6]
2023 , institution=
Large language models as simulated economic agents: What can we learn from homo silicus? , author=. 2023 , institution=
2023
-
[7]
Advances in Neural Information Processing Systems , volume=
Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
InThe F ourteenth International Conference on Learning Representations
Collaborative gym: A framework for enabling and evaluating human-agent collaboration , author=. arXiv preprint arXiv:2412.15701 , year=
-
[9]
Evaluating Human-Language Model Interaction , year=
Lee, Mina and Srivastava, Megha and Hardy, Amelia and Thickstun, John and Durmus, Esin and Paranjape, Ashwin and Gerard-Ursin, Ines and Li, Xiang Lisa and Ladhak, Faisal and Rong, Frieda and others , journal=. Evaluating Human-Language Model Interaction , year=
-
[10]
The Journal of the Learning Sciences , volume=
Cognitive tutors: Lessons learned , author=. The Journal of the Learning Sciences , volume=
-
[11]
Psychological Review , volume=
Acquisition of cognitive skill , author=. Psychological Review , volume=
-
[12]
NPJ Digital Medicine , volume=
Systematic review and meta-analysis of AI-based conversational agents for promoting mental health and well-being , author=. NPJ Digital Medicine , volume=. 2023 , publisher=
2023
-
[13]
2025 , institution=
How people use chatgpt , author=. 2025 , institution=
2025
-
[14]
A survey of personalized large language models: Progress and future directions, 2025
A survey of personalized large language models: Progress and future directions , author=. arXiv preprint arXiv:2502.11528 , year=
-
[15]
LaMP: When large language models meet personalization.arXiv preprint arXiv:2304.11406, 2023
Lamp: When large language models meet personalization , author=. arXiv preprint arXiv:2304.11406 , year=
-
[16]
Modeling future conversation turns to teach llms to ask clarifying questions
Modeling future conversation turns to teach llms to ask clarifying questions , author=. arXiv preprint arXiv:2410.13788 , year=
-
[17]
Star-gate: Teaching language models to ask clarifying questions
Star-gate: Teaching language models to ask clarifying questions , author=. arXiv preprint arXiv:2403.19154 , year=
-
[18]
arXiv preprint arXiv:2505.22526 , year=
AI instructional agent improves student's perceived learner control and learning outcome: empirical evidence from a randomized controlled trial , author=. arXiv preprint arXiv:2505.22526 , year=
-
[19]
Collabllm: From passive responders to active collaborators
Collabllm: From passive responders to active collaborators , author=. arXiv preprint arXiv:2502.00640 , year=
-
[20]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Controllable Mixed-Initiative Dialogue Generation through Prompting , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations , author=. NeurIPS 2023 Foundation Models for Decision Making Workshop , year=
2023
-
[24]
Clam: Selective clarification for ambiguous questions with generative language models
Clam: Selective clarification for ambiguous questions with generative language models , author=. arXiv preprint arXiv:2212.07769 , year=
-
[25]
The quarterly journal of economics , pages=
A behavioral model of rational choice , author=. The quarterly journal of economics , pages=. 1955 , publisher=
1955
-
[26]
Journal of Consumer Psychology , volume=
Choice overload: A conceptual review and meta-analysis , author=. Journal of Consumer Psychology , volume=. 2015 , publisher=
2015
-
[27]
arXiv preprint arXiv:2508.17281 , year=
From language to action: A review of large language models as autonomous agents and tool users , author=. arXiv preprint arXiv:2508.17281 , year=
-
[28]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Persona vectors: Monitoring and controlling character traits in language models , author=. arXiv preprint arXiv:2507.21509 , year=
work page internal anchor Pith review arXiv
-
[29]
Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
A taxonomy for human-llm interaction modes: An initial exploration , author=. Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
-
[30]
2002 , publisher=
Emotions in humans and artifacts , author=. 2002 , publisher=
2002
-
[31]
arXiv preprint arXiv:2510.25662 , year=
User Misconceptions of LLM-Based Conversational Programming Assistants , author=. arXiv preprint arXiv:2510.25662 , year=
-
[32]
Nature , volume=
People construct simplified mental representations to plan , author=. Nature , volume=. 2022 , publisher=
2022
-
[33]
, author=
Metacognition and cognitive monitoring: A new area of cognitive--developmental inquiry. , author=. American psychologist , volume=. 1979 , publisher=
1979
-
[34]
Procedia Computer Science , volume=
Mitigating Automation Bias in Generative AI Through Nudges: A Cognitive Reflection Test Study , author=. Procedia Computer Science , volume=. 2025 , publisher=
2025
-
[35]
JMIR Medical Education , volume=
ChatGPT in medical education: a precursor for automation bias? , author=. JMIR Medical Education , volume=. 2024 , publisher=
2024
-
[36]
Your brain on chatgpt: Accumulation of cognitive debt when using an ai assistant for essay writing task , author=. arXiv preprint arXiv:2506.08872 , year=
-
[37]
American economic review , volume=
Doing it now or later , author=. American economic review , volume=. 1999 , publisher=
1999
-
[38]
The Quarterly Journal of Economics , volume=
Golden eggs and hyperbolic discounting , author=. The Quarterly Journal of Economics , volume=. 1997 , publisher=
1997
-
[39]
Knowledge in organisations , pages=
The tacit dimension , author=. Knowledge in organisations , pages=. 2009 , publisher=
2009
-
[40]
, author=
Telling more than we can know: Verbal reports on mental processes. , author=. Psychological review , volume=. 1977 , publisher=
1977
-
[41]
arXiv preprint arXiv:2403.08950 , year=
Exploring prompt engineering practices in the enterprise , author=. arXiv preprint arXiv:2403.08950 , year=
-
[42]
2011 , publisher=
Metacognition: A literature review , author=. 2011 , publisher=
2011
-
[43]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
Bridging the gulf of envisioning: Cognitive challenges in prompt based interactions with llms , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
2024
-
[44]
arXiv preprint arXiv:2412.10380 , year=
Challenges in human-agent communication , author=. arXiv preprint arXiv:2412.10380 , year=
-
[45]
Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning , year=
Personalized Language Modeling from Personalized Human Feedback , author=. Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Personalizing reinforcement learning from human feedback with variational preference learning , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:2510.07925 , year=
Enabling Personalized Long-term Interactions in LLM-based Agents through Persistent Memory and User Profiles , author=. arXiv preprint arXiv:2510.07925 , year=
-
[48]
Extended abstracts of the 2021 CHI conference on human factors in computing systems , pages=
Prompt programming for large language models: Beyond the few-shot paradigm , author=. Extended abstracts of the 2021 CHI conference on human factors in computing systems , pages=
2021
-
[49]
Creativity in Context , author=
-
[50]
Proceedings of the annual meeting of the cognitive science society , volume=
Thinking with the body , author=. Proceedings of the annual meeting of the cognitive science society , volume=
-
[51]
URL: https: //arxiv.org/abs/2406.06608.arXiv:2406.06608
The prompt report: a systematic survey of prompt engineering techniques , author=. arXiv preprint arXiv:2406.06608 , year=
-
[52]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[53]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[54]
Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
Tools for Thought: Research and Design for Understanding, Protecting, and Augmenting Human Cognition with Generative AI , author=. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , pages=
- [55]
-
[56]
Transactions on Machine Learning Research , issn=
Personalization of Large Language Models: A Survey , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[57]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review arXiv
-
[58]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[59]
Steerable chatbots: Personalizing llms with preference-based activation steering , author=. arXiv preprint arXiv:2505.04260 , year=
-
[60]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
The steerability of large language models toward data-driven personas , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[61]
2nd Workshop on Models of Human Feedback for AI Alignment , year=
Language Model Personalization via Reward Factorization , author=. 2nd Workshop on Models of Human Feedback for AI Alignment , year=
-
[62]
arXiv preprint arXiv:2505.18882 , year=
Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach , author=. arXiv preprint arXiv:2505.18882 , year=
-
[63]
The Twelfth International Conference on Learning Representations , year=
Towards Understanding Sycophancy in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[64]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[65]
ACM Computing Surveys , year=
Instruction tuning for large language models: A survey , author=. ACM Computing Surveys , year=
-
[66]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[68]
arXiv preprint arXiv:2410.15553 , year=
Multi-if: Benchmarking llms on multi-turn and multilingual instructions following , author=. arXiv preprint arXiv:2410.15553 , year=
-
[69]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[70]
Lmrl gym: Benchmarks for multi-turn reinforcement learn- ing with language models
Lmrl gym: Benchmarks for multi-turn reinforcement learning with language models , author=. arXiv preprint arXiv:2311.18232 , year=
-
[71]
Behaviour & Information Technology , volume=
Determining the causes of user frustration in the case of conversational chatbots , author=. Behaviour & Information Technology , volume=. 2025 , publisher=
2025
-
[72]
2025 , howpublished =
AI and Frustration: How to Deal With It , author =. 2025 , howpublished =
2025
-
[73]
2025 , month = sep, howpublished =
AI-Generated ``Workslop'' Is Destroying Productivity , author =. 2025 , month = sep, howpublished =
2025
-
[74]
International Journal of Human--Computer Interaction , volume=
Ironies of generative AI: understanding and mitigating productivity loss in Human-AI interaction , author=. International Journal of Human--Computer Interaction , volume=. 2025 , publisher=
2025
-
[75]
2023 , url =
Nilsson, Peter , title =. 2023 , url =
2023
-
[76]
, title =
Russell, Stuart J. , title =. 2023 , url =
2023
-
[77]
IEEE Intelligent Systems and their Applications , volume=
Mixed-initiative interaction , author=. IEEE Intelligent Systems and their Applications , volume=. 1999 , publisher=
1999
-
[78]
Advances in neural information processing systems , volume=
Cooperative inverse reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[79]
arXiv preprint arXiv:2510.25744 , year=
Completion Collaboration: Scaling Collaborative Effort with Agents , author=. arXiv preprint arXiv:2510.25744 , year=
-
[80]
ACM Transactions on Computer-Human Interaction , volume=
What should we engineer in prompts? training humans in requirement-driven llm use , author=. ACM Transactions on Computer-Human Interaction , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.