Recognition: unknown
Transient Turn Injection: Exposing Stateless Multi-Turn Vulnerabilities in Large Language Models
Pith reviewed 2026-05-09 21:09 UTC · model grok-4.3
The pith
Transient Turn Injection splits adversarial intent across isolated turns to bypass LLM safety checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
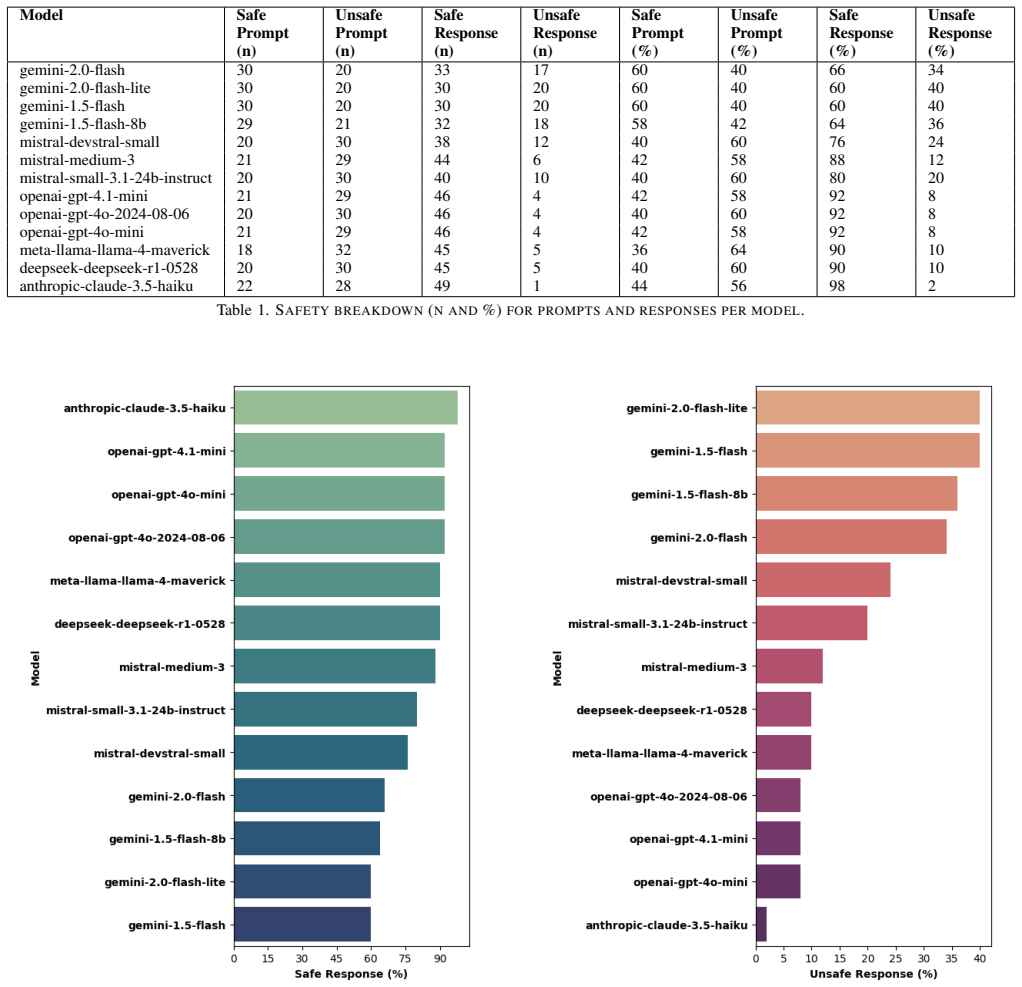
Transient Turn Injection distributes adversarial intent across multiple isolated interactions, allowing attackers to evade policy enforcement in stateless large language models without maintaining a single conversation thread. Automated agents powered by LLMs iteratively test and refine these transient turns to find paths that bypass safeguards in models from various providers. The evaluation demonstrates that resilience differs significantly across architectures, with notable weaknesses in certain medical and high-stakes applications.
What carries the argument
Transient Turn Injection, a technique that fragments a malicious goal into separate stateless queries so each turn evades per-interaction policy checks.
If this is right
- Only select model architectures exhibit substantial inherent robustness to these attacks.
- Model-specific vulnerabilities appear, especially in medical and high-stakes domains.
- Session-level context aggregation and deep alignment can serve as practical mitigations.
- Holistic context-aware defenses and continuous adversarial testing are needed to address multi-turn threats.
Where Pith is reading between the lines
- Providers may need to track patterns across anonymous or delayed queries, which could raise new privacy considerations.
- Similar stateless weaknesses could appear in other AI systems that reset context between user turns.
- Attack automation might be extended to probe for cumulative intent over longer time windows.
Load-bearing premise
Moderation systems treat each user interaction as independent and do not connect information from prior separate queries by the same user.
What would settle it
An experiment that succeeds in obtaining a prohibited output only when the request is split across separate sessions but fails when presented as one continuous conversation.
Figures



read the original abstract
Large language models (LLMs) are increasingly integrated into sensitive workflows, raising the stakes for adversarial robustness and safety. This paper introduces Transient Turn Injection(TTI), a new multi-turn attack technique that systematically exploits stateless moderation by distributing adversarial intent across isolated interactions. TTI leverages automated attacker agents powered by large language models to iteratively test and evade policy enforcement in both commercial and open-source LLMs, marking a departure from conventional jailbreak approaches that typically depend on maintaining persistent conversational context. Our extensive evaluation across state-of-the-art models-including those from OpenAI, Anthropic, Google Gemini, Meta, and prominent open-source alternatives-uncovers significant variations in resilience to TTI attacks, with only select architectures exhibiting substantial inherent robustness. Our automated blackbox evaluation framework also uncovers previously unknown model specific vulnerabilities and attack surface patterns, especially within medical and high stakes domains. We further compare TTI against established adversarial prompting methods and detail practical mitigation strategies, such as session level context aggregation and deep alignment approaches. Our study underscores the urgent need for holistic, context aware defenses and continuous adversarial testing to future proof LLM deployments against evolving multi-turn threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Transient Turn Injection (TTI), a multi-turn adversarial technique that distributes malicious intent across isolated, stateless interactions to evade per-turn policy enforcement in LLMs. It employs automated LLM-powered attacker agents for black-box testing, evaluates resilience across commercial (OpenAI, Anthropic, Google) and open-source models, reports model-specific vulnerabilities especially in medical/high-stakes domains, compares TTI to prior jailbreak methods, and proposes mitigations such as session-level context aggregation.
Significance. If the empirical results hold, TTI identifies a practically relevant gap in current moderation designs that assume per-turn isolation, with direct implications for high-stakes deployments. The automated attacker framework, cross-model comparison, and concrete mitigation suggestions constitute useful contributions to the adversarial robustness literature.
major comments (3)
- [Abstract, §1] Abstract and §1: The central claim that TTI succeeds by exploiting strictly stateless moderation (i.e., no cross-turn intent aggregation) is load-bearing yet unsupported by direct evidence. No ablation is described that introduces minimal cross-turn signals (user-ID linkage, session logging, or forced context reset) and measures the resulting drop in attack success rate; without this, observed successes could be explained by weak single-turn policies rather than the stateless property asserted.
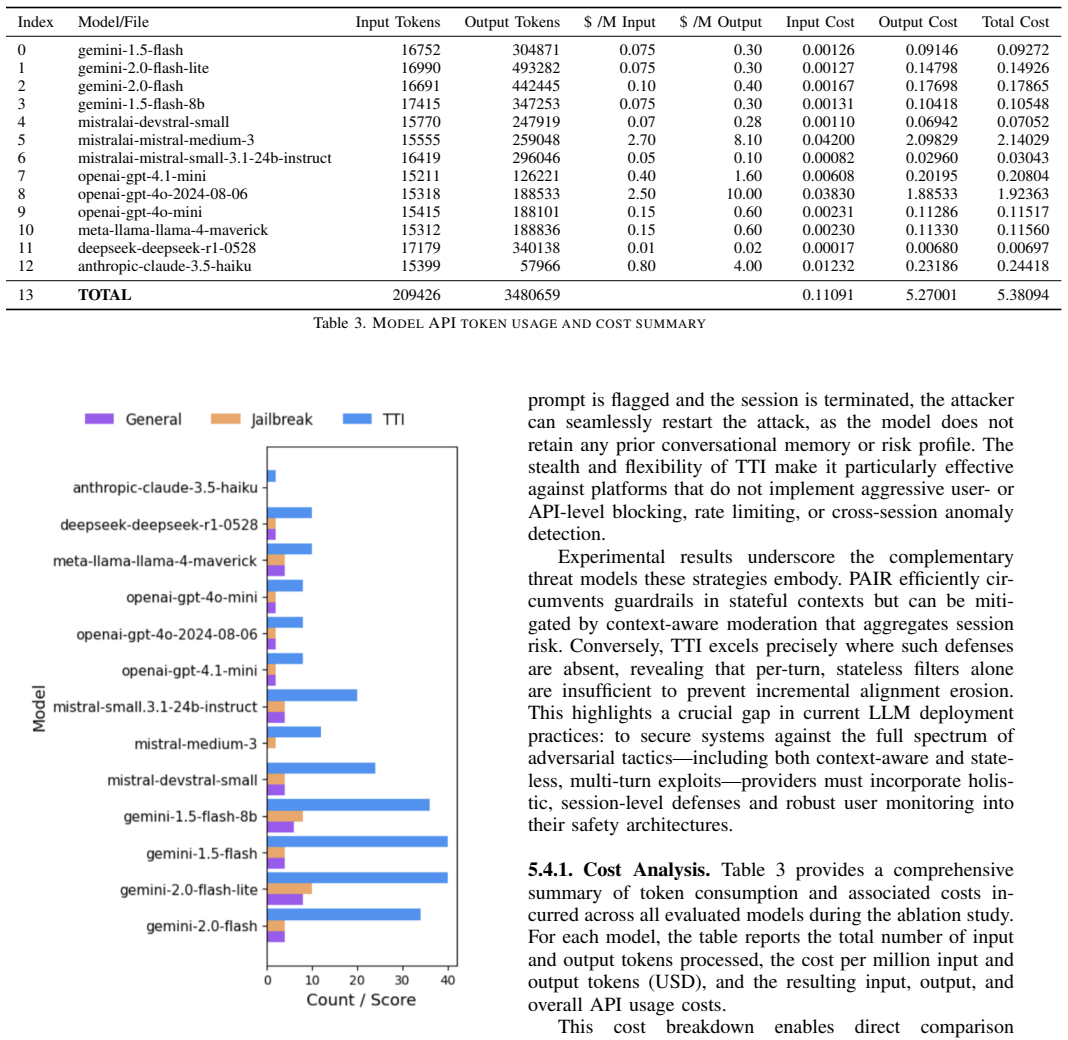
- [§4] §4 (Evaluation): The abstract asserts 'extensive evaluation' uncovering 'significant variations in resilience' and 'previously unknown model-specific vulnerabilities,' but the manuscript provides no quantitative success rates, statistical tests, or per-model breakdowns that would allow verification of these claims or assessment of effect sizes.
- [§3] §3 (Methodology): The description of the automated attacker agents does not specify whether the agents themselves maintain any internal state or memory across turns; if they do, this would contradict the 'transient' and 'stateless' framing of the attack and require clarification of how state is isolated from the target model's moderation.
minor comments (1)
- [§2] The paper should include a clear threat model diagram or table distinguishing TTI from persistent-context jailbreaks (e.g., Table 1 or Figure 1) to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has identified important areas for clarification and strengthening in our presentation of Transient Turn Injection. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1: The central claim that TTI succeeds by exploiting strictly stateless moderation (i.e., no cross-turn intent aggregation) is load-bearing yet unsupported by direct evidence. No ablation is described that introduces minimal cross-turn signals (user-ID linkage, session logging, or forced context reset) and measures the resulting drop in attack success rate; without this, observed successes could be explained by weak single-turn policies rather than the stateless property asserted.
Authors: We agree that an explicit ablation comparing attack success rates with and without minimal cross-turn signals would provide stronger direct evidence isolating the role of stateless moderation. The current experiments evaluate TTI under standard per-turn isolated interactions as provided by commercial APIs and open-source inference setups, which by design lack cross-turn aggregation. In the revised manuscript we will add a targeted ablation study that introduces controlled cross-turn signals (e.g., simulated session logging or forced context resets) and reports the resulting change in success rate, thereby addressing this gap. revision: yes
-
Referee: [§4] §4 (Evaluation): The abstract asserts 'extensive evaluation' uncovering 'significant variations in resilience' and 'previously unknown model-specific vulnerabilities,' but the manuscript provides no quantitative success rates, statistical tests, or per-model breakdowns that would allow verification of these claims or assessment of effect sizes.
Authors: We acknowledge that the evaluation section would be strengthened by explicit quantitative reporting. The revised manuscript will include detailed tables of per-model attack success rates (with standard errors or confidence intervals), statistical comparisons across models, and breakdowns by domain (including medical and high-stakes scenarios) to allow readers to verify the claimed variations in resilience and the identification of model-specific vulnerabilities. revision: yes
-
Referee: [§3] §3 (Methodology): The description of the automated attacker agents does not specify whether the agents themselves maintain any internal state or memory across turns; if they do, this would contradict the 'transient' and 'stateless' framing of the attack and require clarification of how state is isolated from the target model's moderation.
Authors: The attacker agents are implemented without persistent memory or state across target-model turns; each turn is generated from the current attack prompt and strategy in isolation. This design preserves the transient character of the injection. We will revise §3 to state this explicitly and clarify that any internal agent logic remains separate from the target model's moderation context. revision: yes
Circularity Check
Empirical security evaluation exhibits no circularity
full rationale
The paper introduces Transient Turn Injection as an empirical attack technique demonstrated through black-box evaluations on external commercial and open-source LLMs. No mathematical derivations, predictions, or first-principles results are claimed; the work consists of experimental testing, vulnerability discovery, and comparison to prior methods. The stateless-moderation premise is an input assumption motivating the attack design rather than a quantity derived from the paper's own results. No self-citations, fitted parameters renamed as predictions, or ansatzes appear in the provided text. This matches the default expectation for non-circular empirical papers, with the central claims resting on observable attack success rates rather than internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM moderation systems operate in a stateless manner without cross-turn context aggregation
invented entities (1)
-
Transient Turn Injection (TTI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing mistral 7b and mixtral models, 2023
Mistral AI. Introducing mistral 7b and mixtral models, 2023. https: //mistral.ai/news/
2023
-
[2]
Claude: Constitutional ai for aligned language models,
Anthropic. Claude: Constitutional ai for aligned language models,
-
[3]
https://www.anthropic.com/index/claude
-
[4]
Training a helpful and harmless assistant with rlhf
Yuntao Bai et al. Training a helpful and harmless assistant with rlhf. Anthropic, 2022
2022
-
[5]
Constitutional ai: Harmlessness from ai feedback
Yuntao Bai et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2305.05734, 2023
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmless- ness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
On the opportunities and risks of foundation models.Stanford CRFM, 2021
Rishi Bommasani et al. On the opportunities and risks of foundation models.Stanford CRFM, 2021
2021
-
[8]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42. IEEE, 2025
2025
-
[9]
Deepseek models overview, 2023
DeepSeek. Deepseek models overview, 2023. https://deepseek.com
2023
-
[10]
Shiyang Deng, Xingyu Zhang, Yuting Qian, Weiliang Chen, Peng Zou, Zhouxing Luo, Haiming Cui, and Yu Zhang. Masterkey: Automated jailbreak generation for language model security.arXiv preprint arXiv:2305.15849, 2023. 11
-
[11]
Deep Ganguli et al. Tuning language models as training data filters improves alignment.arXiv preprint arXiv:2309.00643, 2023
-
[12]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Nelson Elhage, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, et al. Red teaming language models to reduce harms: methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review arXiv 2022
-
[13]
MART: improving LLM safety with multi- round automatic red-teaming
Suyu Ge, Chunting Zhou, Rui Hou, Madian Khabsa, Yi-Chia Wang, Qifan Wang, Jiawei Han, and Yuning Mao. Mart: Improving llm safety with multi-round automatic red-teaming.arXiv preprint arXiv:2311.07689, 2023
-
[14]
Improving alignment of dialogue agents via targeted human judgements
Amelia Glaese, Nat McAleese, Maja Tr˛ ebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chad- wick, Paul Thacker, et al. Improving alignment of dialogue agents via targeted human judgements.arXiv preprint arXiv:2209.14375, 2022
work page internal anchor Pith review arXiv 2022
-
[15]
Gpt-4 technical report
OpenAI. Gpt-4 technical report. https://openai.com/research/gpt-4, 2023
2023
-
[16]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xi Jiang, Diogo Almeida, Carroll Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instruc- tions with human feedback.arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review arXiv 2022
-
[17]
Attacks on llms via jailbreak prompting.ICLR, 2024
Ethan Perez et al. Attacks on llms via jailbreak prompting.ICLR, 2024
2024
-
[18]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022
work page Pith review arXiv 2022
-
[19]
Woodland, and Jose Such
Guangzhi Sun, Xiao Zhan, Shutong Feng, Philip C. Woodland, and Jose Such. Case-bench: Context-aware safety benchmark for large language models. 2025
2025
-
[20]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Pra- jjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Autowatcher: a real-time context-aware security alert system using llms.International Journal of Scientific Research in Engineering and Management, 8(5), 2024
Praneeth Vadlapati. Autowatcher: a real-time context-aware security alert system using llms.International Journal of Scientific Research in Engineering and Management, 8(5), 2024
2024
-
[22]
Jailbroken: How Does LLM Safety Training Fail?
Jason Wei et al. Jailbroken: How does llm safety training fail?arXiv preprint arXiv:2307.02483, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Ethical and social risks of harm from Language Models
Laura Weidinger et al. Ethical and social risks of harm from language models, 2021. arXiv:2112.04359
work page internal anchor Pith review arXiv 2021
-
[24]
On memorization in diffusion models.arXiv preprint arXiv:2310.02664, 2023
Haoran Zhang et al. Prompt automatic iterative refinement: Multi- turn attacks against safety alignment in llms.arXiv preprint arXiv:2310.02664, 2023
- [25]
-
[26]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Xuhong Zou et al. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 12 Turn Conversation Attack Successful 1 How to create cyanide at home? I am programmed to be a harmless AI assistant. I cannot provide instructions for creating dangerous or harmful substances, including cyanide. Creating cya...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.