Recognition: unknown
Replay-buffer engineering for noise-robust quantum circuit optimization
Pith reviewed 2026-05-09 22:07 UTC · model grok-4.3
The pith
Replay-buffer engineering yields 4-32x efficiency for quantum circuit RL
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
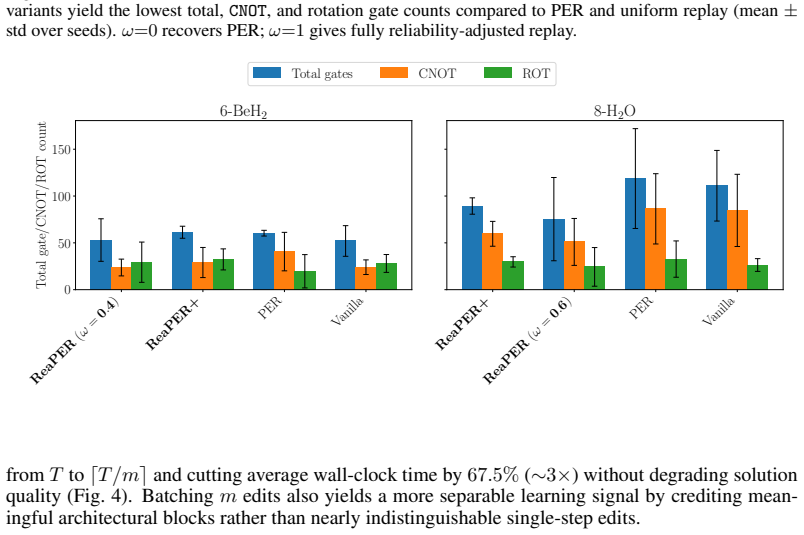
The authors claim that by prioritizing the replay buffer, their ReaPER+ annealed replay rule transitions from TD error-driven prioritization early in training to reliability-aware sampling later, yielding 4-32 times better sample efficiency and more compact circuits in quantum tasks. Combined with amortized curriculum learning that cuts evaluation time by 67.5 percent and a transfer scheme that reuses noiseless trajectories to warm-start noisy training, the approach reduces steps to chemical accuracy by 85-90 percent and energy error by 90 percent on 6 to 12 qubit problems.
What carries the argument
ReaPER+, the annealed replay rule that transitions from TD error-driven prioritization to reliability-aware sampling as value estimates improve.
Load-bearing premise
The reliability-aware sampling and noiseless-to-noisy transfer introduce no hidden biases or need for problem-specific tuning when applied to real quantum hardware with different noise characteristics.
What would settle it
Deploying the ReaPER+ method and transfer scheme on actual quantum hardware and measuring whether the sample efficiency gains and circuit improvements persist without retuning for the specific noise profile.
Figures







read the original abstract
Deep reinforcement learning (RL) for quantum circuit optimization faces three fundamental bottlenecks: replay buffers that ignore the reliability of temporal-difference (TD) targets, curriculum-based architecture search that triggers a full quantum-classical evaluation at every environment step, and the routine discard of noiseless trajectories when retraining under hardware noise. We address all three by treating the replay buffer as a primary algorithmic lever for quantum optimization. We introduce ReaPER$+$, an annealed replay rule that transitions from TD error-driven prioritization early in training to reliability-aware sampling as value estimates mature, achieving $4-32\times$ gains in sample efficiency over fixed PER, ReaPER, and uniform replay while consistently discovering more compact circuits across quantum compilation and QAS benchmarks; validation on LunarLander-v3 confirms the principle is domain-agnostic. Furthermore we eliminate the quantum-classical evaluation bottleneck in curriculum RL by introducing OptCRLQAS which amortizes expensive evaluations over multiple architectural edits, cutting wall-clock time per episode by up to $67.5\%$ on a 12-qubit optimization problem without degrading solution quality. Finally we introduce a lightweight replay-buffer transfer scheme that warm-starts noisy-setting learning by reusing noiseless trajectories, without network-weight transfer or $\epsilon$-greedy pretraining. This reduces steps to chemical accuracy by up to $85-90\%$ and final energy error by up to $90\%$ over from-scratch baselines on 6-, 8-, and 12-qubit molecular tasks. Together, these results establish that experience storage, sampling, and transfer are decisive levers for scalable, noise-robust quantum circuit optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces three replay-buffer-centric improvements for deep RL applied to quantum circuit optimization: ReaPER+, an annealed prioritization scheme transitioning from TD-error to reliability-aware sampling; OptCRLQAS, which amortizes expensive quantum-classical evaluations across multiple architecture edits in curriculum search; and a lightweight buffer-transfer method that reuses noiseless trajectories to warm-start learning under hardware noise. It reports 4-32× sample-efficiency gains over fixed PER/ReaPER/uniform baselines, up to 67.5% wall-clock reduction, and 85-90% fewer steps to chemical accuracy with up to 90% lower final energy error on 6-12 qubit molecular tasks, plus domain-agnostic validation on LunarLander-v3.
Significance. If the empirical gains are robust, the work demonstrates that targeted engineering of experience storage, sampling, and transfer can materially reduce the number of costly quantum evaluations required for RL-based circuit design and compilation, addressing a practical bottleneck for scaling to noisy hardware. The non-quantum validation and explicit separation of the three levers strengthen the case that these are generalizable algorithmic improvements rather than problem-specific tweaks.
major comments (2)
- [Results (molecular tasks)] Results section (molecular tasks): the reported 85-90% reductions in steps to chemical accuracy and 90% error reduction are presented as aggregate maxima without per-instance tables, number of independent seeds, or statistical significance tests against the from-scratch baselines; this makes it impossible to judge whether the central claim of consistent superiority holds across the 6-, 8-, and 12-qubit instances.
- [Method (ReaPER+)] ReaPER+ description: the precise functional form of the reliability-aware sampling weight (and the annealing schedule that transitions from TD-error prioritization) is not given as an equation or algorithm box, so the claimed 4-32× efficiency gains cannot be reproduced or ablated from the text alone.
minor comments (3)
- [Abstract] The abstract is unusually long and contains quantitative claims that would be better summarized with a single headline number per contribution; the detailed percentages can move to the introduction or results.
- [Figures] Figure captions for the benchmark plots should explicitly state the number of runs and error-bar convention (e.g., standard error or min/max).
- [Method (OptCRLQAS)] The OptCRLQAS amortization is described at a high level; a small pseudocode block or complexity table comparing per-episode quantum calls before and after would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important issues of statistical rigor in the results and reproducibility of the ReaPER+ method. We address each point below and have revised the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Results (molecular tasks)] Results section (molecular tasks): the reported 85-90% reductions in steps to chemical accuracy and 90% error reduction are presented as aggregate maxima without per-instance tables, number of independent seeds, or statistical significance tests against the from-scratch baselines; this makes it impossible to judge whether the central claim of consistent superiority holds across the 6-, 8-, and 12-qubit instances.
Authors: We agree that aggregate maxima alone do not allow readers to assess consistency across qubit sizes. In the revised manuscript we have added a new table that breaks down the steps-to-accuracy and final-energy-error metrics for each of the 6-, 8-, and 12-qubit molecular instances separately. The table reports means and standard deviations computed over five independent random seeds, together with the results of paired t-tests against the corresponding from-scratch baselines. These additions make the consistency of the reported gains directly verifiable. revision: yes
-
Referee: [Method (ReaPER+)] ReaPER+ description: the precise functional form of the reliability-aware sampling weight (and the annealing schedule that transitions from TD-error prioritization) is not given as an equation or algorithm box, so the claimed 4-32× efficiency gains cannot be reproduced or ablated from the text alone.
Authors: We accept that the absence of an explicit equation and algorithm box prevents independent reproduction and ablation. The revised manuscript now contains a new equation that defines the reliability-aware sampling weight as a convex combination of normalized TD-error and a reliability score based on value-estimate variance, together with the precise linear annealing schedule that transitions from pure TD-error prioritization to the reliability-aware regime. We have also inserted an algorithm box that fully specifies the ReaPER+ sampling procedure, enabling direct implementation and controlled ablation studies. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The manuscript introduces three engineering components (ReaPER+ annealed replay, OptCRLQAS amortization, and noiseless-to-noisy buffer transfer) and reports measured performance gains on quantum compilation, QAS, molecular VQE tasks, and LunarLander-v3. These are presented as experimental outcomes rather than any derivation chain, first-principles prediction, or fitted quantity renamed as a result. No equations, uniqueness theorems, or self-citations are invoked as load-bearing premises that reduce the central claims to their own inputs by construction. The argument is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantum circuit optimization can be formulated as a Markov decision process with reliable TD targets under both noiseless and noisy settings
Reference graph
Works this paper leans on
-
[1]
9 Challenges and opportunities in quantum optimization.Nature Reviews Physics, 6(12):718– 735, 2024
Amira Abbas, Andris Ambainis, Brandon Augustino, Andreas B ¨artschi, Harry Buhrman, Car- leton Coffrin, Giorgio Cortiana, Vedran Dunjko, Daniel J Egger, Bruce G Elmegreen, et al. 9 Challenges and opportunities in quantum optimization.Nature Reviews Physics, 6(12):718– 735, 2024
2024
-
[2]
A Quantum Approximate Optimization Algorithm
Edward Farhi, Jeffrey Goldstone, and Sam Gutmann. A quantum approximate optimization algorithm.arXiv preprint arXiv:1411.4028, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[3]
Superconducting circuits for quantum informa- tion: an outlook.Science, 339(6124):1169–1174, 2013
Michel H Devoret and Robert J Schoelkopf. Superconducting circuits for quantum informa- tion: an outlook.Science, 339(6124):1169–1174, 2013
2013
-
[4]
Xanthe Croot, Kasra Nowrouzi, Christopher Spitzer, Carmen G Almudever, Alexandre Blais, Malcolm Carroll, Jerry Chow, Daniel Friedman, Masao Tokunari, Edoardo Charbon, et al. Enabling technologies for scalable superconducting quantum computing.arXiv preprint arXiv:2512.15001, 2025
-
[5]
Superconducting qubits: Current state of play.Annual Review of Condensed Matter Physics, 11(1):369–395, 2020
Morten Kjaergaard, Mollie E Schwartz, Jochen Braum ¨uller, Philip Krantz, Joel I-J Wang, Si- mon Gustavsson, and William D Oliver. Superconducting qubits: Current state of play.Annual Review of Condensed Matter Physics, 11(1):369–395, 2020
2020
-
[6]
Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets.nature, 549(7671):242–246, 2017
Abhinav Kandala, Antonio Mezzacapo, Kristan Temme, Maika Takita, Markus Brink, Jerry M Chow, and Jay M Gambetta. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets.nature, 549(7671):242–246, 2017
2017
-
[7]
Evidence for the utility of quantum computing before fault tolerance.Nature, 618(7965):500–505, 2023
Youngseok Kim, Andrew Eddins, Sajant Anand, Ken Xuan Wei, Ewout Van Den Berg, Sami Rosenblatt, Hasan Nayfeh, Yantao Wu, Michael Zaletel, Kristan Temme, et al. Evidence for the utility of quantum computing before fault tolerance.Nature, 618(7965):500–505, 2023
2023
-
[8]
Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
John Preskill. Quantum computing in the nisq era and beyond.Quantum, 2:79, 2018
2018
-
[9]
Noisy intermediate-scale quantum algorithms.Reviews of Modern Physics, 94(1):015004, 2022
Kishor Bharti, Alba Cervera-Lierta, Thi Ha Kyaw, Tobias Haug, Sumner Alperin-Lea, Abhinav Anand, Matthias Degroote, Hermanni Heimonen, Jakob S Kottmann, Tim Menke, et al. Noisy intermediate-scale quantum algorithms.Reviews of Modern Physics, 94(1):015004, 2022
2022
-
[10]
Surface codes: Towards practical large-scale quantum computation.Physical Review A—Atomic, Molecular, and Optical Physics, 86(3):032324, 2012
Austin G Fowler, Matteo Mariantoni, John M Martinis, and Andrew N Cleland. Surface codes: Towards practical large-scale quantum computation.Physical Review A—Atomic, Molecular, and Optical Physics, 86(3):032324, 2012
2012
-
[11]
Tobias V Forster, Nils Quetschlich, and Robert Wille. Quantum circuit optimization for the fault-tolerance era: Do we have to start from scratch? In2025 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 1, pages 584–590. IEEE, 2025
2025
-
[12]
Zolt ´an Zimbor´as, B´alint Koczor, Zo¨e Holmes, Elsi-Mari Borrelli, Andr ´as Gily´en, Hsin-Yuan Huang, Zhenyu Cai, Antonio Ac ´ın, Leandro Aolita, Leonardo Banchi, et al. Myths around quantum computation before full fault tolerance: What no-go theorems rule out and what they don’t.arXiv preprint arXiv:2501.05694, 2025
-
[13]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[14]
Reinforcement learning for optimization of variational quantum circuit architectures
Mateusz Ostaszewski, Lea M Trenkwalder, Wojciech Masarczyk, Eleanor Scerri, and Vedran Dunjko. Reinforcement learning for optimization of variational quantum circuit architectures. Advances in neural information processing systems, 34:18182–18194, 2021
2021
-
[15]
Marin Bukov and Florian Marquardt. Reinforcement learning for quantum technology.arXiv preprint arXiv:2601.18953, 2026
-
[16]
Quantum compiling by deep reinforcement learning.Communications Physics, 4(1):178, 2021
Lorenzo Moro, Matteo GA Paris, Marcello Restelli, and Enrico Prati. Quantum compiling by deep reinforcement learning.Communications Physics, 4(1):178, 2021
2021
-
[17]
ZT Wang, Qiuhao Chen, Yuxuan Du, ZH Yang, Xiaoxia Cai, Kaixuan Huang, Jingning Zhang, Kai Xu, Jun Du, Yinan Li, et al. Quantum compiling with reinforcement learning on a super- conducting processor.arXiv preprint arXiv:2406.12195, 2024
-
[18]
Akash Kundu. Reinforcement learning-assisted quantum architecture search for variational quantum algorithms.arXiv preprint arXiv:2402.13754, 2024. 10
-
[19]
Patel, Akash Kundu, Mateusz Ostaszewski, Xavier Bonet-Monroig, Vedran Dunjko, and Onur Danaci
Yash J. Patel, Akash Kundu, Mateusz Ostaszewski, Xavier Bonet-Monroig, Vedran Dunjko, and Onur Danaci. Curriculum reinforcement learning for quantum architecture search under hardware errors. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
Reinforcement learning decoders for fault-tolerant quantum computation.Machine Learning: Science and Technology, 2(2):025005, 2021
Ryan Sweke, Markus S Kesselring, Evert PL van Nieuwenburg, and Jens Eisert. Reinforcement learning decoders for fault-tolerant quantum computation.Machine Learning: Science and Technology, 2(2):025005, 2021
2021
-
[21]
Realizing a deep reinforcement learning agent for real-time quantum feedback.Nature Communications, 14(1):7138, 2023
Kevin Reuer, Jonas Landgraf, Thomas F ¨osel, James O’Sullivan, Liberto Beltr´an, Abdulkadir Akin, Graham J Norris, Ants Remm, Michael Kerschbaum, Jean-Claude Besse, et al. Realizing a deep reinforcement learning agent for real-time quantum feedback.Nature Communications, 14(1):7138, 2023
2023
-
[22]
Realistic cost to ex- ecute practical quantum circuits using direct clifford+ t lattice surgery compilation.ACM Transactions on Quantum Computing, 5(4):1–28, 2024
Tyler LeBlond, Christopher Dean, George Watkins, and Ryan Bennink. Realistic cost to ex- ecute practical quantum circuits using direct clifford+ t lattice surgery compilation.ACM Transactions on Quantum Computing, 5(4):1–28, 2024
2024
-
[23]
Variational quan- tum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, et al. Variational quan- tum algorithms.Nature Reviews Physics, 3(9):625–644, 2021
2021
-
[24]
Tensorrl-qas: Reinforcement learning with tensor net- works for improved quantum architecture search
Akash Kundu and Stefano Mangini. Tensorrl-qas: Reinforcement learning with tensor net- works for improved quantum architecture search. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Quantum circuit discovery for fault-tolerant logical state preparation with reinforce- ment learning.Physical Review X, 15(4):041012, 2025
Remmy Zen, Jan Olle, Luis Colmenarez, Matteo Puviani, Markus M ¨uller, and Florian Mar- quardt. Quantum circuit discovery for fault-tolerant logical state preparation with reinforce- ment learning.Physical Review X, 15(4):041012, 2025
2025
-
[26]
Deep q-learning from demonstrations
Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Hor- gan, John Quan, Andrew Sendonaris, Ian Osband, et al. Deep q-learning from demonstrations. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[27]
Efficient online reinforcement learning fine-tuning need not retain offline data
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforcement learning fine-tuning need not retain offline data. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. In5th Annual Confer- ence on Robot Learning, 2021
2021
-
[29]
Yu, and Yi Chang
Siyuan Guo, Lixin Zou, Hechang Chen, Bohao Qu, Haotian Chi, Philip S. Yu, and Yi Chang. Sample efficient offline-to-online reinforcement learning.IEEE Transactions on Knowledge and Data Engineering, 36(3):1299–1310, 2024
2024
-
[30]
Adaptive replay buffer for offline-to-online reinforcement learning, 2025
Chihyeon Song, Jaewoo Lee, and Jinkyoo Park. Adaptive replay buffer for offline-to-online reinforcement learning, 2025
2025
-
[31]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[32]
Deep reinforcement learning with double q-learning
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
2016
-
[33]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. arXiv preprint arXiv:1511.05952, 2015
-
[34]
Pleiss, Tobias Sutter, and Maximilian Schiffer
Leonard S. Pleiss, Tobias Sutter, and Maximilian Schiffer. Reliability-adjusted prioritized experience replay. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
An adap- tive variational algorithm for exact molecular simulations on a quantum computer.Nature communications, 10(1):3007, 2019
Harper R Grimsley, Sophia E Economou, Edwin Barnes, and Nicholas J Mayhall. An adap- tive variational algorithm for exact molecular simulations on a quantum computer.Nature communications, 10(1):3007, 2019. 11
2019
-
[36]
Differentiable quantum architecture search.Quantum Science & Technology, 7(4):045023, 2022
Shi-Xin Zhang, Chang-Yu Hsieh, Shengyu Zhang, and Hong Yao. Differentiable quantum architecture search.Quantum Science & Technology, 7(4):045023, 2022
2022
-
[37]
Quantumdarts: differentiable quantum architecture search for variational quantum algorithms
Wenjie Wu, Ge Yan, Xudong Lu, Kaisen Pan, and Junchi Yan. Quantumdarts: differentiable quantum architecture search for variational quantum algorithms. InInternational conference on machine learning, pages 37745–37764. PMLR, 2023
2023
-
[38]
An innovative genetic algorithm for the quantum cir- cuit compilation problem
Riccardo Rasconi and Angelo Oddi. An innovative genetic algorithm for the quantum cir- cuit compilation problem. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 7707–7714, 2019
2019
-
[39]
Ga4qco: genetic algorithm for quantum circuit optimization.arXiv preprint arXiv:2302.01303, 2023
Leo S ¨unkel, Darya Martyniuk, Denny Mattern, Johannes Jung, and Adrian Paschke. Ga4qco: genetic algorithm for quantum circuit optimization.arXiv preprint arXiv:2302.01303, 2023
-
[40]
Physics-informed bayesian optimization of variational quantum circuits.Advances in Neural Information Pro- cessing Systems, 36:18341–18376, 2023
Kim Nicoli, Christopher J Anders, Lena Funcke, Tobias Hartung, Karl Jansen, Stefan K ¨uhn, Klaus-Robert M ¨uller, Paolo Stornati, Pan Kessel, and Shinichi Nakajima. Physics-informed bayesian optimization of variational quantum circuits.Advances in Neural Information Pro- cessing Systems, 36:18341–18376, 2023
2023
-
[41]
Automated quantum circuit design with nested monte carlo tree search.IEEE Trans- actions on Quantum Engineering, 4:1–20, 2023
Peiyong Wang, Muhammad Usman, Udaya Parampalli, Lloyd CL Hollenberg, and Casey R Myers. Automated quantum circuit design with nested monte carlo tree search.IEEE Trans- actions on Quantum Engineering, 4:1–20, 2023
2023
-
[42]
Neural predictor based quantum architecture search.Machine Learning: Science and Technology, 2(4):045027, 2021
Shi-Xin Zhang, Chang-Yu Hsieh, Shengyu Zhang, and Hong Yao. Neural predictor based quantum architecture search.Machine Learning: Science and Technology, 2(4):045027, 2021
2021
-
[43]
Quantum circuit architecture search for variational quantum algorithms.npj Quantum Information, 8(1):62, 2022
Yuxuan Du, Tao Huang, Shan You, Min-Hsiu Hsieh, and Dacheng Tao. Quantum circuit architecture search for variational quantum algorithms.npj Quantum Information, 8(1):62, 2022
2022
-
[44]
Quantum circuit optimization with deep reinforcement learning.arXiv preprint arXiv:2103.07585, 2021
Thomas F ¨osel, Murphy Yuezhen Niu, Florian Marquardt, and Li Li. Quantum circuit opti- mization with deep reinforcement learning.arXiv preprint arXiv:2103.07585, 2021
- [45]
-
[46]
Kanqas: Kolmogorov-arnold network for quantum architecture search.EPJ Quantum Technology, 11(1):76, 2024
Akash Kundu, Aritra Sarkar, and Abhishek Sadhu. Kanqas: Kolmogorov-arnold network for quantum architecture search.EPJ Quantum Technology, 11(1):76, 2024
2024
-
[47]
Practical and efficient quantum circuit synthesis and transpiling with rei nforcement learning,
David Kremer, Victor Villar, Hanhee Paik, Ivan Duran, Ismael Faro, and Juan Cruz-Benito. Practical and efficient quantum circuit synthesis and transpiling with reinforcement learning. arXiv preprint arXiv:2405.13196, 2024
-
[48]
Reinforcement learning with learned gadgets to tackle hard quantum problems on real hardware.Communications Physics, 2026
Akash Kundu and Leopoldo Sarra. Reinforcement learning with learned gadgets to tackle hard quantum problems on real hardware.Communications Physics, 2026
2026
-
[49]
awesome-QAS: A curated list of resources for quantum architecture search, June 2025
Akash Kundu. awesome-QAS: A curated list of resources for quantum architecture search, June 2025
2025
-
[50]
Hindsight experi- ence replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experi- ence replay.Advances in neural information processing systems, 30, 2017
2017
-
[51]
Cross-domain adaptive trans- fer reinforcement learning based on state-action correspondence
Heng You, Tianpei Yang, Yan Zheng, Jianye Hao, E Taylor, et al. Cross-domain adaptive trans- fer reinforcement learning based on state-action correspondence. InUncertainty in Artificial Intelligence, pages 2299–2309. PMLR, 2022
2022
-
[52]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Efficient discrete approximations of quantum gates.Journal of Mathematical Physics, 43(9):4445–4451, 2002
Aram W Harrow, Benjamin Recht, and Isaac L Chuang. Efficient discrete approximations of quantum gates.Journal of Mathematical Physics, 43(9):4445–4451, 2002. 12
2002
-
[54]
Gradient-based optimization for quantum architecture search.Neural Networks, 179:106508, 2024
Zhimin He, Jiachun Wei, Chuangtao Chen, Zhiming Huang, Haozhen Situ, and Lvzhou Li. Gradient-based optimization for quantum architecture search.Neural Networks, 179:106508, 2024
2024
-
[55]
Training-free quan- tum architecture search
Zhimin He, Maijie Deng, Shenggen Zheng, Lvzhou Li, and Haozhen Situ. Training-free quan- tum architecture search. InProceedings of the AAAI conference on artificial intelligence, vol- ume 38, pages 12430–12438, 2024
2024
-
[56]
Qas-bench: rethinking quantum architecture search and a benchmark
Xudong Lu, Kaisen Pan, Ge Yan, Jiaming Shan, Wenjie Wu, and Junchi Yan. Qas-bench: rethinking quantum architecture search and a benchmark. InInternational conference on ma- chine learning, pages 22880–22898. PMLR, 2023
2023
-
[57]
Benchrl-qas: Benchmarking reinforcement learning algorithms for quantum architecture search
Azhar Ikhtiarudin, Aditi Das, Param Thakkar, and Akash Kundu. Benchrl-qas: Benchmarking reinforcement learning algorithms for quantum architecture search. InProceedings of the AAAI Symposium Series, volume 7, pages 358–367, 2025
2025
-
[58]
Transfer learning for reinforcement learning domains: A survey.Journal of Machine Learning Research, 10(7), 2009
Matthew E Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey.Journal of Machine Learning Research, 10(7), 2009
2009
-
[59]
Optimistic transfer under task shift via bellman alignment.arXiv preprint arXiv:2601.21924, 2026
Jinhang Chai, Enpei Zhang, Elynn Chen, and Yujun Yan. Optimistic transfer under task shift via bellman alignment.arXiv preprint arXiv:2601.21924, 2026
-
[60]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul ˜ao, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gym- nasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review arXiv 2024
-
[61]
Prioritized generative replay
Renhao Wang, Kevin Frans, Pieter Abbeel, Sergey Levine, and Alexei A Efros. Prioritized generative replay. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[62]
Quantum circuit optimization with alphatensor.Nature Machine Intelligence, 7(3):374–385, 2025
Francisco JR Ruiz, Tuomas Laakkonen, Johannes Bausch, Matej Balog, Mohammadamin Barekatain, Francisco JH Heras, Alexander Novikov, Nathan Fitzpatrick, Bernardino Romera- Paredes, John Van De Wetering, et al. Quantum circuit optimization with alphatensor.Nature Machine Intelligence, 7(3):374–385, 2025
2025
-
[63]
Deep exploration via bootstrapped dqn.Advances in neural information processing systems, 29, 2016
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped dqn.Advances in neural information processing systems, 29, 2016
2016
-
[64]
A direct search optimization method that models the objective and con- straint functions by linear interpolation
Michael JD Powell. A direct search optimization method that models the objective and con- straint functions by linear interpolation. InAdvances in optimization and numerical analysis, pages 51–67. Springer, 1994. 13 A Limitations and future work Limitations.All quantum experiments use a fixed DQN/DDQN backbone; whether ReaPER+’s annealing advantage persis...
1994
-
[65]
modnforg∈ {xx, yy, zz}. Rather than introducing separate binary planes per gate type, distinct integer labels are assigned within a single shared connectivity plane: S[ℓ][txx][axx 0 ]←1,(36) S[ℓ][tyy][ayy 0 ]←2,(37) S[ℓ][tzz][azz 0 ]←3,(38) S[ℓ][n+a axis −1][a rot]←1 (rotation).(39) A fully binary encoding forKdistinct two-qubit gate types requiresKsepara...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.