Recognition: unknown
When Prompts Override Vision: Prompt-Induced Hallucinations in LVLMs
Pith reviewed 2026-05-09 22:08 UTC · model grok-4.3
The pith
Textual instructions override visual input as the main driver of hallucinations in large vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
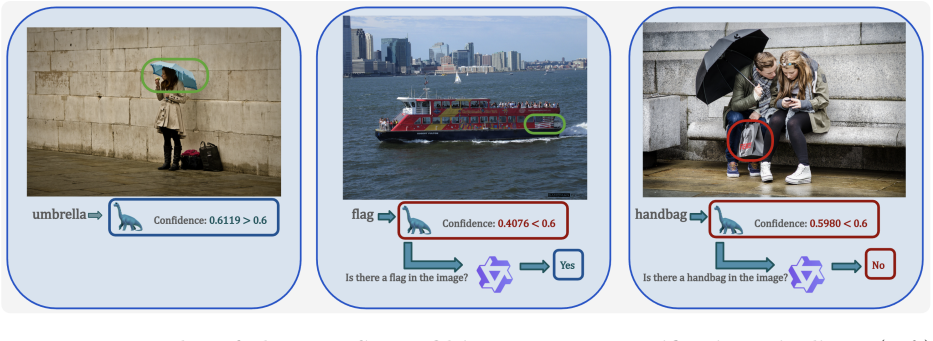
Hallucinations in LVLMs largely stem from excessive reliance on textual priors and background knowledge, especially information introduced through textual instructions. HalluVL-DPO mitigates these by fine-tuning off-the-shelf models with preference optimization on a curated dataset that guides responses toward visual grounding.
What carries the argument
HalluScope benchmark for isolating hallucination causes plus HalluVL-DPO preference optimization on a dataset of grounded versus hallucinated response pairs.
If this is right
- Textual instructions can be treated as a controllable variable that strongly influences whether an LVLM stays grounded in the image.
- Preference optimization on paired grounded and hallucinated responses provides a practical way to steer existing models without full retraining.
- Releasing the benchmark, training data, and code allows systematic testing of prompt effects across different model sizes and architectures.
Where Pith is reading between the lines
- Prompt engineering that minimizes background knowledge injection could serve as a lightweight complement to fine-tuning.
- The finding raises the possibility that similar text-over-vision imbalances appear in other multimodal systems such as video or audio models.
- If the effect holds, future model designs might incorporate explicit mechanisms to down-weight language priors during visual reasoning steps.
Load-bearing premise
The HalluScope benchmark and curated preference dataset isolate prompt-induced hallucinations without significant confounding from model architecture choices or data collection biases.
What would settle it
If an LVLM still produces the same rate of hallucinations after textual instructions are removed or replaced with neutral prompts, or if HalluVL-DPO training yields no measurable drop in the targeted errors, the claim that textual priors are the dominant cause would be falsified.
Figures









read the original abstract
Despite impressive progress in capabilities of large vision-language models (LVLMs), these systems remain vulnerable to hallucinations, i.e., outputs that are not grounded in the visual input. Prior work has attributed hallucinations in LVLMs to factors such as limitations of the vision backbone or the dominance of the language component, yet the relative importance of these factors remains unclear. To resolve this ambiguity, We propose HalluScope, a benchmark to better understand the extent to which different factors induce hallucinations. Our analysis indicates that hallucinations largely stem from excessive reliance on textual priors and background knowledge, especially information introduced through textual instructions. To mitigate hallucinations induced by textual instruction priors, we propose HalluVL-DPO, a framework for fine-tuning off-the-shelf LVLMs towards more visually grounded responses. HalluVL-DPO leverages preference optimization using a curated training dataset that we construct, guiding the model to prefer grounded responses over hallucinated ones. We demonstrate that our optimized model effectively mitigates the targeted hallucination failure mode, while preserving or improving performance on other hallucination benchmarks and visual capability evaluations. To support reproducibility and further research, we will publicly release our evaluation benchmark, preference training dataset, and code at https://pegah-kh.github.io/projects/prompts-override-vision/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HalluScope, a benchmark to analyze factors inducing hallucinations in LVLMs, concluding that these largely stem from excessive reliance on textual priors and background knowledge introduced via instructions rather than vision backbone limitations. It proposes HalluVL-DPO, a preference optimization framework using a curated dataset of grounded vs. hallucinated response pairs to fine-tune off-the-shelf LVLMs, with experiments showing mitigation of the targeted failure mode while preserving or improving performance on other hallucination benchmarks and visual tasks. The benchmark, dataset, and code are to be released publicly.
Significance. If the isolation of textual priors holds, the work offers a clear empirical decomposition of hallucination sources in LVLMs and a practical, targeted mitigation via DPO that avoids broad capability degradation. The open release of HalluScope and the preference dataset provides reusable artifacts for the community, strengthening reproducibility and enabling follow-on studies on prompt engineering and multimodal alignment.
major comments (2)
- [§3 (HalluScope construction)] §3 (HalluScope construction): the benchmark description does not report ablations or statistics confirming that visual stimuli are uncorrelated with common vision-encoder failure modes (e.g., object occlusion, fine-grained detail, or low-contrast images). Without such controls or a comparison of vision-only performance on the same images, the central attribution of hallucinations to textual priors cannot be cleanly separated from vision backbone confounds.
- [§4.2 (preference dataset curation)] §4.2 (preference dataset curation): the procedure for generating and labeling the preference pairs is not detailed with respect to sampling strategy, human annotation guidelines, or checks against language-model prior leakage. If the curation inadvertently selects responses that align with particular textual biases, the claim that HalluVL-DPO specifically counters prompt-induced hallucinations becomes circular.
minor comments (2)
- [Results section] The abstract states that the model 'preserves or improves performance on other hallucination benchmarks,' but the main text should include a table with exact delta values and statistical significance for each baseline comparison.
- [§2] Notation for 'textual priors' vs. 'background knowledge' is used interchangeably in places; a single consistent definition in §2 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of benchmark construction and dataset curation that warrant clarification to strengthen the isolation of textual priors as a hallucination source. We address each point below and commit to revisions that incorporate the suggested controls and details without altering the core claims or experimental findings.
read point-by-point responses
-
Referee: §3 (HalluScope construction): the benchmark description does not report ablations or statistics confirming that visual stimuli are uncorrelated with common vision-encoder failure modes (e.g., object occlusion, fine-grained detail, or low-contrast images). Without such controls or a comparison of vision-only performance on the same images, the central attribution of hallucinations to textual priors cannot be cleanly separated from vision backbone confounds.
Authors: We acknowledge that explicit controls would further strengthen the separation of factors. HalluScope was built from standard datasets (COCO, Visual Genome) with images pre-filtered for prominent, unambiguous objects to reduce vision confounds, but these selection criteria were not quantified in the original submission. In the revision we will add: (i) summary statistics on image properties including average contrast, occlusion frequency, and fine-grained detail scores; (ii) a vision-only baseline comparison (e.g., CLIP or BLIP captioning accuracy) on the identical HalluScope images to show that the vision backbone succeeds on these stimuli when textual priors are absent. These additions will directly support the attribution to textual instructions. revision: yes
-
Referee: §4.2 (preference dataset curation): the procedure for generating and labeling the preference pairs is not detailed with respect to sampling strategy, human annotation guidelines, or checks against language-model prior leakage. If the curation inadvertently selects responses that align with particular textual biases, the claim that HalluVL-DPO specifically counters prompt-induced hallucinations becomes circular.
Authors: We agree that expanded methodological detail is required to rule out circularity. The original §4.2 described the high-level construction of grounded vs. hallucinated pairs but omitted granular procedures. In the revised manuscript we will specify: the exact sampling strategy (prompt templates used to elicit hallucinations while keeping the image fixed); the human annotation guidelines (explicit criteria for grounding, hallucination types, and resolution of disagreements); and leakage checks (comparison of preference labels against outputs from a text-only LLM on the same prompts, plus distribution analysis to confirm visual grounding is the differentiating factor). These clarifications will demonstrate that the dataset targets prompt-induced failures rather than generic textual biases. revision: yes
Circularity Check
No significant circularity; empirical benchmark and dataset are independently constructed.
full rationale
The paper introduces HalluScope as a new benchmark and a curated preference dataset for HalluVL-DPO, then reports empirical findings on hallucination sources. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the central claim. The attribution to textual priors rests on controlled variation within the newly proposed artifacts rather than reducing to prior self-referential results or definitions. This is a standard empirical contribution with external reproducibility artifacts, so the derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.12718 (2024)
An, W., Tian, F., Leng, S., Nie, J., Lin, H., Wang, Q., Dai, G., Chen, P., Lu, S.: Agla: Mitigating object hallucinations in large vision-language models with assembly of global and local attention. arXiv preprint arXiv:2406.12718 (2024)
-
[2]
Hallucination of Multimodal Large Language Models: A Survey
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., Shou, M.Z.: Hallucination of multi- modal large language models: A survey. arXiv preprint arXiv:2404.18930 (2024)
work page internal anchor Pith review arXiv 2024
-
[3]
Baldassini, F.B., Shukor, M., Cord, M., Soulier, L., Piwowarski, B.: What makes multimodal in-context learning work? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 1539–1550 (June 2024)
2024
-
[4]
arXiv preprint arXiv:2502.00814 (2025)
Cai, J., Zhu, J., Sun, R., Wang, Y., Li, L., Zhou, W., Li, H.: Disentangling length bias in preference learning via response-conditioned modeling. arXiv preprint arXiv:2502.00814 (2025)
-
[5]
In: The Thirteenth Inter- national Conference on Learning Representations (2025),https://openreview.net/forum? id=ziw5bzg2NO
Cho, Y., Kim, K., Hwang, T., Cho, S.: Do you keep an eye on what i ask? mitigating multimodal hallucination via attention-guided ensemble decoding. In: The Thirteenth Inter- national Conference on Learning Representations (2025),https://openreview.net/forum? id=ziw5bzg2NO
2025
-
[6]
Computational Linguistics (1990) 13
Church, K.W., Hanks, P.: Word association norms, mutual information, and lexicography. Computational Linguistics (1990) 13
1990
-
[7]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M¨ uller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[8]
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: Mme: A comprehensive evaluation benchmark for multimodal large language models (2025),https://arxiv.org/abs/2306.13394
work page internal anchor Pith review arXiv 2025
-
[9]
In: Findings of the Association for Computational Linguistics: ACL 2025
Fu, Y., Xie, R., Sun, X., Kang, Z., Li, X.: Mitigating hallucination in multimodal large language model via hallucination-targeted direct preference optimization. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 16563–16577 (2025)
2025
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14375–14385 (2024)
2024
-
[11]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13418–13427 (2024)
2024
-
[13]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=7uDI7w5RQA
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=7uDI7w5RQA
2025
-
[14]
Lauren¸ con, H., Tronchon, L., Cord, M., Sanh, V.: What matters when building vision-language models? Advances in Neural Information Processing Systems37, 87874–87907 (2024)
2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object halluci- nations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13872–13882 (2024)
2024
-
[16]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Li, W., Huang, Z., Li, H., Lu, L., Lu, Y., Tian, X., Shen, X., Ye, J.: Visual evidence prompting mitigates hallucinations in large vision-language models. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Asso- ciation for Computational Linguistics (2025),https://aclanthology.org/2025.acl-...
2025
-
[17]
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.: Evaluating object hallucination in large vision-language models. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023. pp. 292–305. Association for Computational Linguistics (2023...
-
[18]
In: Computer vision–ECCV 2014: 13th 14 European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ ar, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer vision–ECCV 2014: 13th 14 European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13. pp. 740–755. Springer (2014)
2014
-
[19]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=J44HfH4JCg
Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., Wang, L.: Mitigating hallucination in large multi-modal models via robust instruction tuning. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=J44HfH4JCg
2024
-
[20]
Advances in neural information processing systems36(2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36(2023)
2023
-
[21]
Liu, S., Ye, H., Xing, L., Zou, J.: Reducing hallucinations in vision-language models via latent space steering. arXiv preprint arXiv:2410.15778 (2024)
-
[22]
Liu, S., Zheng, K., Chen, W.: Paying more attention to image: A training-free method for alleviating hallucination in lvlms, 2024. URL https://arxiv. org/abs/2407.21771
-
[23]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[24]
In: Proceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing
Liu, Y., Ji, T., Sun, C., Wu, Y., Zhou, A.: Investigating and mitigating object hallucinations in pretrained vision-language (CLIP) models. In: Proceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing. pp. 18288–18301. Association for Computational Linguistics (2024),https://aclanthology.org/2024.emnlp-main.1016/
2024
-
[25]
Mia-dpo: Multi-image augmented di- rect preference optimization for large vision-language mod- els
Liu, Z., Zang, Y., Dong, X., Zhang, P., Cao, Y., Duan, H., He, C., Xiong, Y., Lin, D., Wang, J.: Mia-dpo: Multi-image augmented direct preference optimization for large vision-language models. arXiv preprint arXiv:2410.17637 (2024)
-
[26]
In: The 36th Conference on Neural Information Processing Systems (NeurIPS) (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: The 36th Conference on Neural Information Processing Systems (NeurIPS) (2022)
2022
-
[27]
arXiv preprint arXiv:2509.11287 (2025)
Lu, Y., Zhang, Z., Yuan, C., Gao, J., Zhang, C., Qi, X., Li, B., Hu, W.: Mitigating hal- lucinations in large vision-language models by self-injecting hallucinations. arXiv preprint arXiv:2509.11287 (2025)
-
[28]
Advances in Neural Information Processing Systems (2025)
Parekh, J., Khayatan, P., Shukor, M., Dapogny, A., Newson, A., Cord, M.: Learning to steer: Input-dependent steering for multimodal llms. Advances in Neural Information Processing Systems (2025)
2025
-
[29]
In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers)
Petryk, S., Chan, D., Kachinthaya, A., Zou, H., Canny, J., Gonzalez, J., Darrell, T.: Aloha: A new measure for hallucination in captioning models. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). pp. 342–357 (2024)
2024
-
[30]
In: European Conference on Computer Vision
Pi, R., Han, T., Xiong, W., Zhang, J., Liu, R., Pan, R., Zhang, T.: Strengthening multimodal large language model with bootstrapped preference optimization. In: European Conference on Computer Vision. pp. 382–398. Springer (2024)
2024
-
[31]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners (2019) 15
2019
-
[32]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[33]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review arXiv 1908
-
[34]
In: Conference on Empirical Methods in Natural Language Processing (2018),https://api.semanticscholar.org/CorpusID:52176506
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object hallucination in image captioning. In: Conference on Empirical Methods in Natural Language Processing (2018),https://api.semanticscholar.org/CorpusID:52176506
2018
-
[35]
In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2556– 2565 (2018)
2018
-
[36]
In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview.net/forum? id=mMaQvkMzDi
Shukor, M., Rame, A., Dancette, C., Cord, M.: Beyond task performance: evaluating and reducing the flaws of large multimodal models with in-context-learning. In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview.net/forum? id=mMaQvkMzDi
2024
-
[37]
A long way to go: Investigat- ing length correlations in RLHF.arXiv preprint arXiv:2310.03716,
Singhal, P., Goyal, T., Xu, J., Durrett, G.: A long way to go: Investigating length correlations in rlhf. arXiv preprint arXiv:2310.03716 (2023)
-
[38]
Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.X., Yang, Y., Keutzer, K., Darrell, T.: Aligning large multimodal models with factually augmented rlhf. ArXivabs/2309.14525(2023),https://api.semanticscholar.org/CorpusID:262824780
-
[39]
arXiv preprint arXiv:2410.11779 , year=
Wang, C., Chen, X., Zhang, N., Tian, B., Xu, H., Deng, S., Chen, H.: Mllm can see? dynamic correction decoding for hallucination mitigation. arXiv preprint arXiv:2410.11779 (2024)
-
[40]
In: The Thirteenth International Conference on Learning Representations
Wang, K., Gu, H., Gao, M., Zhou, K.: Damo: Decoding by accumulating activations momen- tum for mitigating hallucinations in vision-language models. In: The Thirteenth International Conference on Learning Representations
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review arXiv 2025
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, Y., Zhang, L., Yao, H., Du, J., Yan, K., Ding, S., Wu, Y., Li, X.: Antidote: A uni- fied framework for mitigating lvlm hallucinations in counterfactual presupposition and object perception. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14646–14656 (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiao, B., Wu, H., Xu, W., Dai, X., Hu, H., Lu, Y., Zeng, M., Liu, C., Yuan, L.: Florence- 2: Advancing a unified representation for a variety of vision tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4818–4829 (2024) 16
2024
-
[45]
Xie, Y., Li, G., Xu, X., Kan, M.Y.: V-dpo: Mitigating hallucination in large vision lan- guage models via vision-guided direct preference optimization. arXiv preprint arXiv:2411.02712 (2024)
-
[46]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=Bjq4W7P2Us
Yang, T., Li, Z., Cao, J., Xu, C.: Mitigating hallucination in large vision-language models via modular attribution and intervention. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=Bjq4W7P2Us
2025
-
[48]
arXiv preprint arXiv:2510.02324 (2025)
Yang, W., Qiu, X., Yu, L., Zhang, Y., Yang, O.A., Kokhlikyan, N., Cancedda, N., Garcia- Olano, D.: Hallucination reduction with casal: Contrastive activation steering for amortized learning. arXiv preprint arXiv:2510.02324 (2025)
-
[49]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, Z., Luo, X., Han, D., Xu, Y., Li, D.: Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10610–10620 (2025)
2025
-
[50]
In: International conference on machine learning
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., Wang, L.: Mm-vet: Evaluating large multimodal models for integrated capabilities. In: International conference on machine learning. PMLR (2024)
2024
-
[51]
Zhao, Z., Wang, B., Ouyang, L., Dong, X., Wang, J., He, C.: Beyond hallucinations: Enhanc- ing lvlms through hallucination-aware direct preference optimization (2023)
2023
-
[52]
arXiv preprint arXiv:2402.11411 , year=
Zhou, Y., Cui, C., Rafailov, R., Finn, C., Yao, H.: Aligning modalities in vision large language models via preference fine-tuning. arXiv preprint arXiv:2402.11411 (2024) 17 Overview Section A, describes the construction and the evaluation protocol forHalluScopebenchmark Section B contains various implementation and evaluation details regarding hallucinat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.