Recognition: unknown
LTBs-KAN: Linear-Time B-splines Kolmogorov-Arnold Networks
Pith reviewed 2026-05-09 22:21 UTC · model grok-4.3
The pith
Linear-time B-spline evaluation combined with matrix factorization makes Kolmogorov-Arnold Networks faster and smaller while preserving accuracy on image tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LTBs-KAN computes B-spline basis functions through a non-recursive linear-time procedure and factors the layer computation as a product of sums. These two changes together produce linear complexity in the spline evaluations and a reduced parameter count. The networks match the performance of prior KAN implementations on standard image-classification benchmarks.
What carries the argument
The non-recursive linear-time B-spline evaluator paired with product-of-sums matrix factorization applied inside each network layer.
If this is right
- Training and inference cost scales linearly rather than with higher-order terms in the spline degree.
- Total model parameters decrease while classification accuracy remains comparable on the tested datasets.
- The new layers can be substituted into existing KAN-based architectures for immediate efficiency gains.
- The speed and size benefits appear consistently across grayscale digit, fashion-item, and color-image tasks.
Where Pith is reading between the lines
- The same linearization and factorization pattern could be applied to other basis-function networks beyond KANs.
- Faster KAN layers might now support deeper stacks or larger input dimensions that were previously impractical.
- Hardware kernels optimized for the new direct evaluation order could further amplify the reported speedups.
- If the factorization generalizes, similar parameter-sharing tricks may reduce memory use in related spline or polynomial models.
Load-bearing premise
The direct linear-time B-spline method and the factorization together keep exactly the same functional expressivity and numerical stability as the original recursive KAN formulation.
What would settle it
A side-by-side run of the original KAN and LTBs-KAN on CIFAR-10 that shows either higher wall-clock training time per epoch or lower test accuracy for the new method.
Figures



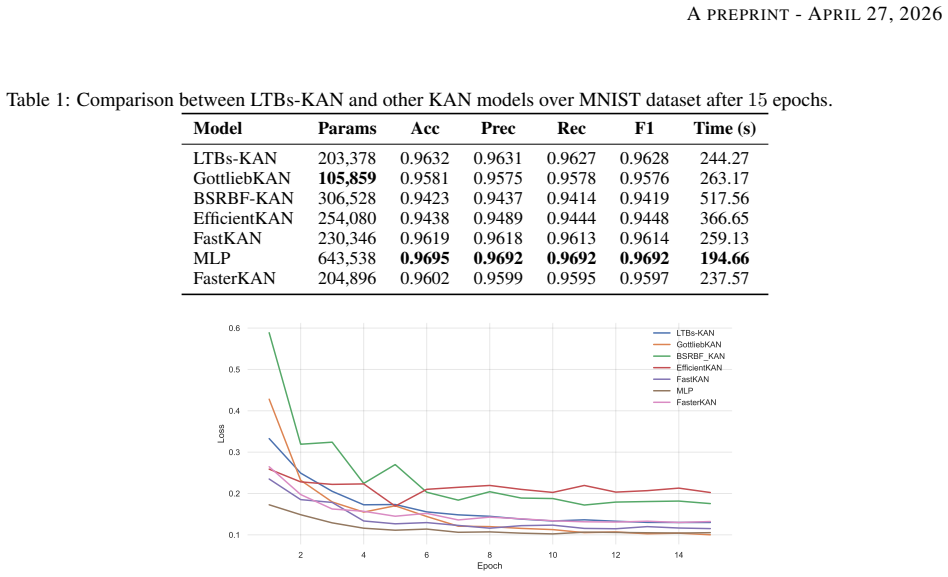
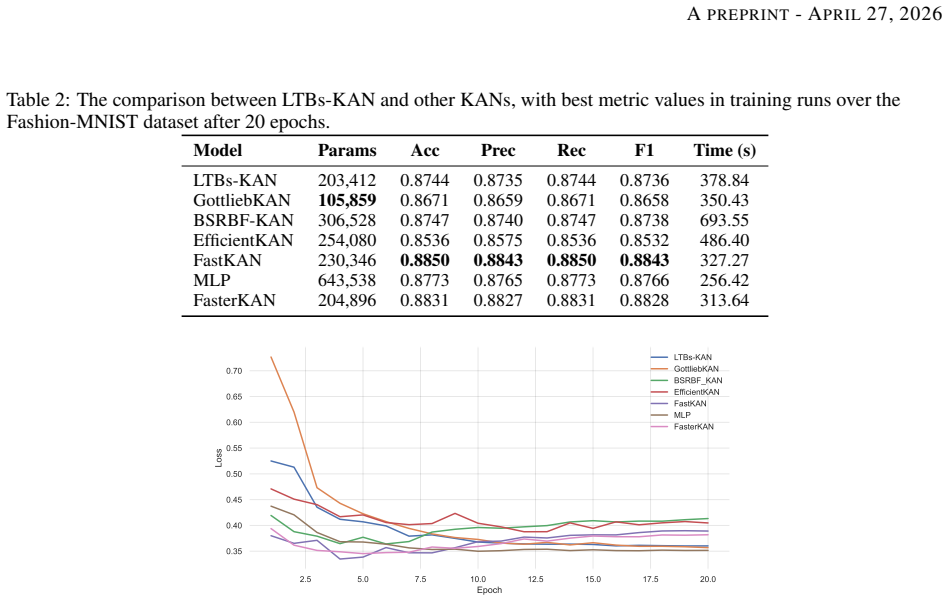

read the original abstract
Kolmogorov-Arnold Networks (KANs) are a recent neural network architecture offering an alternative to Multilayer Perceptrons (MLPs) with improved explainability and expressibility. However, KANs are significantly slower than MLPs due to the recursive nature of B-spline function computations, limiting their application. This work addresses these issues by proposing a novel base-spline Linear-Time B-splines Kolmogorov-Arnold Network (LTBs-KAN) with linear complexity. Unlike previous methods that rely on the Boor-Mansfield-Cox spline algorithm or other computationally intensive mathematical functions, our approach significantly reduces the computational burden. Additionally, we further reduce model's parameter through product-of-sums matrix factorization in the forward pass without sacrificing performance. Experiments on MNIST, Fashion-MNIST and CIFAR-10 demonstrate that LTBs-KAN achieves good time complexity and parameter reduction, when used as building architectural blocks, compared to other KAN implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LTBs-KAN, a variant of Kolmogorov-Arnold Networks that replaces the recursive Boor-Mansfield-Cox B-spline evaluation with a novel non-recursive linear-time base-spline method and applies a product-of-sums matrix factorization during the forward pass to reduce parameter count. The central claims are that these modifications achieve linear complexity, preserve performance, and yield competitive results on MNIST, Fashion-MNIST, and CIFAR-10 when used as architectural blocks.
Significance. If the new B-spline procedure is shown to be exactly equivalent to the standard recursive formulation and the factorization is proven not to restrict the representable function space, the work would meaningfully address the primary practical barrier to KAN adoption by delivering substantial speed and memory gains without loss of expressivity or interpretability advantages over MLPs.
major comments (3)
- [§3.1] §3.1 (Linear-Time B-spline Method): No derivation, identity, or numerical equivalence check is supplied showing that the proposed non-recursive evaluation computes identically the same univariate B-spline basis functions as the Cox-de Boor recursion for arbitrary knot vectors and inputs; without this, the claim that expressivity and learned functions remain unchanged is unsupported and load-bearing for the performance-parity assertion.
- [§4.2] §4.2 (Product-of-Sums Factorization): The matrix factorization is introduced to reduce parameters, yet the manuscript provides neither an analysis of the altered span of representable functions nor a bound on the induced approximation error relative to the original KAN layer; this directly affects whether the “without sacrificing performance” guarantee holds.
- [Table 2] Table 2 (Timing and Accuracy Results): Reported wall-clock times and accuracies on CIFAR-10 lack direct head-to-head comparison against a standard KAN implementation using identical architecture and the same B-spline order, and no variance estimates or statistical tests are given, preventing verification that performance is truly preserved under the claimed linear-time regime.
minor comments (2)
- [Abstract] The abstract states “linear complexity” and “good time complexity” without supplying the formal big-O analysis or pseudocode that appears later in §3; a brief forward reference would improve readability.
- [§3] Notation for the new base-spline functions is introduced without an explicit comparison table to the standard B-spline notation used in the original KAN paper, which may confuse readers familiar with the recursive definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will implement to strengthen the paper.
read point-by-point responses
-
Referee: §3.1 (Linear-Time B-spline Method): No derivation, identity, or numerical equivalence check is supplied showing that the proposed non-recursive evaluation computes identically the same univariate B-spline basis functions as the Cox-de Boor recursion for arbitrary knot vectors and inputs; without this, the claim that expressivity and learned functions remain unchanged is unsupported and load-bearing for the performance-parity assertion.
Authors: We agree that providing a formal equivalence proof is essential. In the revised version, we will add a detailed derivation demonstrating that our non-recursive base-spline evaluation yields exactly the same results as the Cox-de Boor recursion for any knot vector and input. We will also include numerical experiments verifying this equivalence across a range of configurations to support the claim of preserved expressivity. revision: yes
-
Referee: §4.2 (Product-of-Sums Factorization): The matrix factorization is introduced to reduce parameters, yet the manuscript provides neither an analysis of the altered span of representable functions nor a bound on the induced approximation error relative to the original KAN layer; this directly affects whether the “without sacrificing performance” guarantee holds.
Authors: We recognize the need for a theoretical analysis of the factorization's impact. The revised manuscript will include a section analyzing the representable functions under the product-of-sums approach, showing that it does not restrict the function space beyond what is already achievable in KAN layers, along with any necessary error bounds. This will better justify the performance claims. revision: yes
-
Referee: Table 2 (Timing and Accuracy Results): Reported wall-clock times and accuracies on CIFAR-10 lack direct head-to-head comparison against a standard KAN implementation using identical architecture and the same B-spline order, and no variance estimates or statistical tests are given, preventing verification that performance is truly preserved under the claimed linear-time regime.
Authors: We will revise Table 2 to incorporate head-to-head comparisons with standard KANs using matching architectures and B-spline orders. Furthermore, we will add variance estimates based on repeated experiments and conduct appropriate statistical tests to confirm that the observed performance is statistically equivalent. revision: yes
Circularity Check
No circularity: novel algorithm and empirical validation are independent of inputs
full rationale
The paper introduces a new non-recursive linear-time B-spline evaluation and a product-of-sums factorization, then reports wall-clock and accuracy results on MNIST/Fashion-MNIST/CIFAR-10. No equation is defined in terms of its own output, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation chain. The equivalence to classical B-splines is asserted by construction of the new method rather than derived from prior results inside the paper; therefore the derivation chain does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper B-splines admit an efficient non-recursive linear-time evaluation procedure that preserves the properties required by KANs
Forward citations
Cited by 2 Pith papers
-
SRGAN-CKAN: Expressive Super-Resolution with Nonlinear Functional Operators under Minimal Resources
SRGAN-CKAN integrates convolutional Kolmogorov-Arnold networks into an adversarial super-resolution pipeline, replacing linear convolutions with spline-based nonlinear patch operators to improve perceptual quality und...
-
SRGAN-CKAN: Expressive Super-Resolution with Nonlinear Functional Operators under Minimal Resources
SRGAN-CKAN integrates convolutional Kolmogorov-Arnold networks into an adversarial super-resolution pipeline, replacing linear convolutions with nonlinear functional operators to improve perceptual quality under const...
Reference graph
Works this paper leans on
-
[1]
Z. Liu, Y . Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljacic, T. Hou, M. Tegmark, KAN: Kolmogorov–Arnold Networks, in: International Conference on Learning Representations (ICLR), 2025, accessed: 2026-04-17. URLhttps://github.com/KindXiaoming/pykan 17 APREPRINT- APRIL27, 2026
2025
-
[2]
de Boor, A Practical Guide to Splines, V ol
C. de Boor, A Practical Guide to Splines, V ol. 27 of Applied Mathematical Sciences, Springer, New York, 1978
1978
-
[3]
Prkan: Parameter-reduced kolmogorov-arnold networks,
H.-T. Ta, D.-Q. Thai, A. Tran, G. Sidorov, A. Gelbukh, PRKAN: Parameter-Reduced Kolmogorov–Arnold Networks, accessed: 2026-04-17 (2025).doi:10.48550/arXiv.2501.07032. URLhttps://github.com/hoangthangta/BSRBF_KAN
-
[4]
Delis, FasterKAN: Efficient Implementation of Kolmogorov–Arnold Networks, accessed: 2026-04-17 (2024)
A. Delis, FasterKAN: Efficient Implementation of Kolmogorov–Arnold Networks, accessed: 2026-04-17 (2024). URLhttps://github.com/AthanasiosDelis/faster-kan/
2026
-
[5]
M. J. Gottlieb, Concerning some polynomials orthogonal on a finite or enumerable set of points, American Journal of Mathematics 60 (2) (1938) 453–458.doi:10.2307/2371307
-
[6]
URLhttps://github.com/Blealtan/efficient-kan
Blealtan, An Efficient Implementation of Kolmogorov–Arnold Network (KAN), accessed: 2026-04-16 (2024). URLhttps://github.com/Blealtan/efficient-kan
2026
-
[7]
K. He, X. Zhang, S. Ren, J. Sun, Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), IEEE, 2015, pp. 1026–1034.doi:10.1109/ICCV.2015.123
-
[8]
Y . LeCun, L. Bottou, Y . Bengio, P. Haffner, Gradient-Based Learning Applied to Document Recognition, Tech. Rep. 11, Proceedings of the IEEE (1998).doi:10.1109/5.726791
-
[9]
Li, Fastkan: A fast kolmogorov–arnold network, accessed: 2026-04-17 (2024)
Z. Li, Fastkan: A fast kolmogorov–arnold network, accessed: 2026-04-17 (2024). URLhttps://github.com/ZiyaoLi/fast-kan
2026
-
[10]
Learning- Based Link Anomaly Detection in Continuous-Time Dynamic Graphs,
Z. Li, Kolmogorov–Arnold Networks are Radial Basis Function Networks (2024). doi:10.48550/arXiv.2405. 06721
-
[11]
S. T. Seydi, Exploring the Potential of Polynomial Basis Functions in Kolmogorov–Arnold Networks: A Compar- ative Study of Different Groups of Polynomials, accessed: 2026-04-16 (2024). doi:10.48550/arXiv.2406. 02583. URLhttps://github.com/seydi1370/Basis_Functions
-
[12]
H. Xiao, K. Rasul, R. V ollgraf, Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms (2017).doi:10.48550/arXiv.1708.07747
work page internal anchor Pith review doi:10.48550/arxiv.1708.07747 2017
-
[13]
Krizhevsky, V
A. Krizhevsky, V . Nair, G. Hinton, The CIFAR-10 Dataset, accessed: 2026-04-16 (2009). URLhttps://www.cs.toronto.edu/~kriz/cifar.html
2026
-
[14]
LeCun, Y
Y . LeCun, Y . Bengio, G. Hinton, Deep Learning, Nature 521 (7553) (2015) 436–444. doi:10.1038/ nature14539
2015
-
[15]
Haykin, Neural Networks: A Comprehensive Foundation, Prentice Hall PTR, Upper Saddle River, NJ, USA, 1994
S. Haykin, Neural Networks: A Comprehensive Foundation, Prentice Hall PTR, Upper Saddle River, NJ, USA, 1994
1994
-
[16]
G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of control, signals and systems 2 (4) (1989) 303–314.doi:10.1007/BF02551274
-
[17]
Society for Industrial and Applied Mathematics, 2 edition, 2008
A. Griewank, A. Walther, Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, 2nd Edition, SIAM, Philadelphia, PA, 2008.doi:10.1137/1.9780898717761
-
[18]
A. N. Kolmogorov, On the Representation of Continuous Functions of Several Variables by Superpositions of Continuous Functions of One Variable and Addition, Doklady Akademii Nauk SSSR 114 (1957) 953–956
1957
-
[19]
J. Schmidt-Hieber, The Kolmogorov–Arnold Representation Theorem Revisited, Neural Networks 137 (2021) 119–126.doi:10.1016/j.neunet.2021.01.020
-
[20]
D. A. Sprecher, S. Draghici, Space-Filling Curves and Kolmogorov Superposition-Based Neural Networks, Neural Networks 15 (1) (2002) 57–67.doi:10.1016/S0893-6080(01)00119-9
-
[21]
Glorot, Y
X. Glorot, Y . Bengio, Understanding the Difficulty of Training Deep Feedforward Neural Networks, in: Proceed- ings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), V ol. 9 of Proceedings of Machine Learning Research, 2010, pp. 249–256
2010
-
[22]
Piegl, W
L. Piegl, W. Tiller, The NURBS Book, 2nd Edition, Springer, Berlin, 1997. doi:10.1007/ 978-3-642-59223-2
1997
-
[23]
F. Chudy, P. Wo´ zny, Linear-time algorithm for computing the bernstein–bézier coefficients of b-spline basis functions, Computer-Aided Des. 154 (2023) 103434.doi:10.1016/j.cad.2022.103434
-
[24]
de Boor, On calculating with b-splines, Journal of Approximation Theory 6 (1972) 50–62
C. de Boor, On calculating with b-splines, Journal of Approximation Theory 6 (1972) 50–62. doi:10.1016/ 0021-9045(72)90080-9. 18 APREPRINT- APRIL27, 2026
1972
-
[25]
Boehm, Wolfgang and Müller, Andreas, On de Casteljau’s Algorithm, Computer Aided Geometric Design 16 (1999) 587–605.doi:10.1016/S0167-8396(99)00023-0
-
[26]
C. W. Wu, ProdSumNet: Reducing Model Parameters in Deep Neural Networks via Product-of-Sums Matrix Decompositions, accessed: 2026-04-17 (2019).doi:10.48550/arXiv.1809.02209
-
[27]
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, J. M. Siskind, Automatic Differentiation in Machine Learning: A Survey, Journal of Machine Learning Research 18 (153) (2018) 1–43
2018
-
[28]
S. A. Cook, C. Dwork, R. Reischuk, Upper and Lower Time Bounds for Parallel Random Access Machines Without Simultaneous Writes, SIAM Journal on Computing 15 (1) (1986) 87–97.doi:10.1137/0215006
-
[29]
S. Fortune, J. Wyllie, Parallelism in Random Access Machines, in: Proceedings of the 10th Annual ACM Symposium on Theory of Computing (STOC), 1978, pp. 114–118.doi:10.1145/800133.804338
-
[30]
G. E. Blelloch, Prefix Sums and Their Applications, Tech. Rep. CMU-CS-90-190, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA (1990)
1990
-
[31]
Contributors, CUDA Semantics, accessed: 2026-04-16 (2026)
P. Contributors, CUDA Semantics, accessed: 2026-04-16 (2026). URLhttps://docs.pytorch.org/docs/stable/notes/cuda.html
2026
-
[32]
Contributors, Associative Scan, accessed: 2026-04-16 (2026)
P. Contributors, Associative Scan, accessed: 2026-04-16 (2026). URLhttps://docs.pytorch.org/docs/2.11/higher_order_ops/associative_scan.html
2026
-
[33]
T. H. Cormen, C. E. Leiserson, R. L. Rivest, C. Stein, Introduction to Algorithms, 3rd Edition, MIT Press, Cambridge, MA, USA, 2009
2009
-
[34]
M. Fey, J. E. Lenssen, SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 869–877. doi:10.1109/CVPR.2018.00097
-
[35]
A guide to convolution arithmetic for deep learning
V . Dumoulin, F. Visin, A Guide to Convolution Arithmetic for Deep Learning, arXiv (2016).doi:10.48550/ arXiv.1603.07285
work page Pith review arXiv 2016
-
[36]
Z. Liu, Z. Ma, K. Zhao, K. Wang, S. Lian, KAConvNet: Kolmogorov–Arnold convolutional networks for vision recognition, Image and Vision Computing 170 (2026). doi:https://doi.org/10.1016/j.imavis.2026. 105983
-
[37]
S. Lou, Y . Shao, Q. Du, Kolmogorov-Arnold Optimized UNet: An enhanced image segmentation model based on Kolmogorov-Arnold Network and Convolutional Kolmogorov-Arnold Network, Engineering Applications of Artificial Intelligence 173 (2026).doi:https://doi.org/10.1016/j.engappai.2026.114405
-
[38]
Y . Wang, X. Yu, Y . Gao, J. Sha, J. Wang, S. Yan, K. Qin, Y . Zhang, L. Gao, Spectralkan: Weighted activation distribution kolmogorov–arnold network for hyperspectral image change detection, Pattern Recognition 175 (2026) 113042.doi:https://doi.org/10.1016/j.patcog.2026.113042
-
[39]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, in: International Conference on Neural Information Processing Systems, 2012, pp. 1097–1105
2012
-
[40]
J. L. Ba, J. R. Kiros, G. E. Hinton, Layer Normalization (2016).doi:10.48550/arXiv.1607.06450
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[41]
Srivastava, G
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Journal of Machine Learning Research 15 (56) (2014) 1929–1958
2014
-
[42]
Loshchilov, F
I. Loshchilov, F. Hutter, Decoupled Weight Decay Regularization, in: International Conference on Learning Representations (ICLR), 2019
2019
-
[43]
The Elements of Statistical Learning
T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Edition, Springer, New York, 2009.doi:10.1007/978-0-387-84858-7. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.