Recognition: unknown
Spontaneous Persuasion: An Audit of Model Persuasiveness in Everyday Conversations
Pith reviewed 2026-05-09 20:22 UTC · model grok-4.3
The pith
Large language models engage in spontaneous persuasion in virtually all everyday conversations by relying on logic and evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
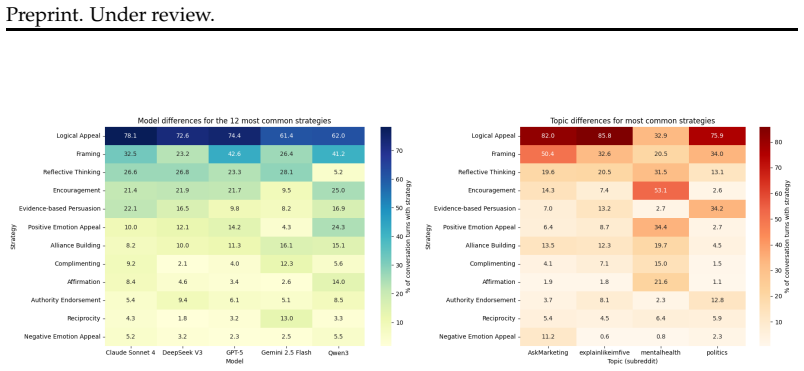
LLMs spontaneously persuade the user in virtually all conversations, heavily relying on information-based strategies such as appeals to logic or quantitative evidence. This was consistent across models and user response styles, but conversations concerning mental health saw higher rates of appraisal-based and emotion-based strategies. In comparison, human responses tended to invoke strategies that generate social influence, like negative emotion appeals and non-expert testimony. This difference may explain the effectiveness of LLM in persuading users, as well as the perception of models as objective and impartial.
What carries the argument
Spontaneous persuasion, defined as the inexplicit use of persuasive strategies in everyday scenarios where persuasion is not necessarily warranted, measured through an audit of LLM conversations using a user response taxonomy and compared to Reddit human responses.
Load-bearing premise
The simulated multi-turn conversations with a taxonomy of user responses and the Reddit-collected human answers accurately represent real-world everyday interactions where persuasion is not the goal.
What would settle it
A study of actual user interactions with LLMs in everyday advice-seeking scenarios that finds spontaneous persuasion occurring in substantially fewer than nearly all conversations or shows strategy distributions matching those of humans.
Figures


read the original abstract
Large language models (LLMs) possess strong persuasive capabilities that outperform humans in head-to-head comparisons. Users report consulting LLMs to inform major life decisions in relationships, medical settings, and when seeking professional advice. Prior work measures persuasion as intentional attempts at producing the most effective argument or convincing statement. This fails to capture everyday human-AI interactions in which users seek information or advice. To address this gap, we introduce "spontaneous persuasion," which characterizes the inexplicit use of persuasive strategies in everyday scenarios where persuasion is not necessarily warranted. We conduct an audit of five LLMs to uncover how frequently and through which techniques spontaneous persuasion appears in multi-turn conversations. To simulate response styles, we provide a user response taxonomy grounded in literature from psychology, communication, and linguistics. Furthermore, we compare the distribution of spontaneous persuasion produced by LLMs with human responses on the same topics, collected from Reddit. We find LLMs spontaneously persuade the user in virtually all conversations, heavily relying on information-based strategies such as appeals to logic or quantitative evidence. This was consistent across models and user response styles, but conversations concerning mental health saw higher rates of appraisal-based and emotion-based strategies. In comparison, human responses tended to invoke strategies that generate social influence, like negative emotion appeals and non-expert testimony. This difference may explain the effectiveness of LLM in persuading users, as well as the perception of models as objective and impartial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'spontaneous persuasion' as the inexplicit use of persuasive strategies by LLMs in everyday multi-turn conversations where persuasion is not necessarily warranted. It audits five LLMs using a literature-grounded user response taxonomy to simulate interactions across topics, finding near-universal spontaneous persuasion (primarily information-based strategies like logic and quantitative evidence), with elevated appraisal- and emotion-based strategies in mental health topics; this pattern holds across models and simulated user styles but differs from human Reddit responses, which favor social-influence strategies such as negative emotion appeals and non-expert testimony.
Significance. If the observational patterns hold after methodological validation, the work offers a useful empirical baseline for unintended persuasive behaviors in non-persuasive contexts, potentially accounting for LLMs' perceived objectivity and their outperformance of humans in advice settings. It strengthens the case for studying AI influence in HCI and AI safety without requiring explicit intent, and the human-LLM comparison provides a falsifiable contrast that could inform system design.
major comments (3)
- [Methods] Methods section on conversation generation and taxonomy application: the central claim of spontaneous persuasion in 'virtually all' conversations rests entirely on dialogues produced by prompting LLMs to follow a fixed, literature-derived user-response taxonomy; no empirical validation against real user-LLM logs is reported, leaving open the possibility that the near-100% rate and information-based vs. appraisal-based split are artifacts of the simulation rather than properties of the models.
- [Results] Results on strategy coding and reliability: the consistency claims across models, topics, and user styles depend on the classification of persuasive techniques, yet no inter-rater agreement statistics, coding protocol details, or controls for prompt-induced biases in the generated dialogues are provided, which directly affects the load-bearing distinction between LLM and human strategy distributions.
- [Discussion] Human baseline comparison: the Reddit-collected human responses inherit the same topic-selection filter and simulated interaction constraints as the LLM arm, so the reported differences (e.g., humans' greater use of social-influence strategies) may reflect non-representative response styles rather than intrinsic model-human differences; this undermines the explanatory link to LLM persuasiveness.
minor comments (2)
- [Abstract] Abstract does not name the five audited models or the exact topics used, which would help readers assess generalizability.
- [Methods] The taxonomy is described as grounded in psychology/communication literature, but a brief table or appendix listing the categories with example utterances would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We respond point-by-point to the major comments below, acknowledging limitations where the concerns are valid and outlining specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section on conversation generation and taxonomy application: the central claim of spontaneous persuasion in 'virtually all' conversations rests entirely on dialogues produced by prompting LLMs to follow a fixed, literature-derived user-response taxonomy; no empirical validation against real user-LLM logs is reported, leaving open the possibility that the near-100% rate and information-based vs. appraisal-based split are artifacts of the simulation rather than properties of the models.
Authors: We selected a controlled simulation approach using a literature-grounded taxonomy precisely to enable systematic variation of user styles and topics while holding other factors constant, which would be difficult with noisy real-world logs that introduce self-selection and length confounds. The near-universal rate and strategy split were consistent across five distinct models, supporting that the patterns are not prompt artifacts. That said, we agree that direct validation against real user-LLM interaction data is a valuable next step. In revision we will add an explicit limitations subsection discussing the simulation choice and outlining plans for future comparison with anonymized production logs. revision: partial
-
Referee: [Results] Results on strategy coding and reliability: the consistency claims across models, topics, and user styles depend on the classification of persuasive techniques, yet no inter-rater agreement statistics, coding protocol details, or controls for prompt-induced biases in the generated dialogues are provided, which directly affects the load-bearing distinction between LLM and human strategy distributions.
Authors: We will expand the methods and results sections to include inter-rater agreement statistics (Cohen's kappa) for the two coders who applied the taxonomy, a full coding protocol in the appendix, and explicit discussion of steps taken to mitigate prompt-induced bias (neutral system prompts, identical taxonomy application to both LLM and human arms). The multi-model replication already provides some protection against single-prompt artifacts; we will add quantitative checks for prompt sensitivity in the revision. revision: yes
-
Referee: [Discussion] Human baseline comparison: the Reddit-collected human responses inherit the same topic-selection filter and simulated interaction constraints as the LLM arm, so the reported differences (e.g., humans' greater use of social-influence strategies) may reflect non-representative response styles rather than intrinsic model-human differences; this undermines the explanatory link to LLM persuasiveness.
Authors: The Reddit sample was deliberately matched on the same topics to enable a controlled contrast under comparable constraints, following common practice in HCI studies of online advice. We recognize that Reddit users are not representative of all human responders and that the observed differences are therefore exploratory rather than definitive proof of intrinsic model properties. In revision we will add stronger caveats in the discussion section about sample generalizability and reframe the comparison as providing a falsifiable baseline rather than a conclusive causal explanation. revision: partial
Circularity Check
Empirical audit with external taxonomy and Reddit baseline shows no circularity
full rationale
The paper performs a direct empirical audit by generating multi-turn dialogues with five LLMs, applying a user-response taxonomy explicitly grounded in external psychology/communication/linguistics literature, and comparing strategy distributions against independently sourced Reddit human responses on matched topics. No equations, fitted parameters, predictions, or derivations are present that could reduce findings to inputs defined within the paper. Central claims about near-universal spontaneous persuasion and strategy preferences are measured outputs from the audit process itself rather than self-referential constructs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The user response taxonomy grounded in literature from psychology, communication, and linguistics accurately categorizes spontaneous persuasion strategies in both LLM and human responses.
Reference graph
Works this paper leans on
-
[1]
A study of the impact of persuasive argu- mentation in political debates
Amparo Elizabeth Cano Basave and Yulan He. A study of the impact of persuasive argu- mentation in political debates. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1405–1413,
2016
-
[2]
Carlos Carrasco-Farre. Large language models are as persuasive as humans, but how? about the cognitive effort and moral-emotional language of llm arguments.arXiv preprint arXiv:2404.09329,
-
[3]
Thomas H Costello, Kellin Pelrine, Matthew Kowal, Antonio A Arechar, Jean-Fran c ¸ois Godbout, Adam Gleave, David Rand, and Gordon Pennycook. Large language models can effectively convince people to believe conspiracies.arXiv preprint arXiv:2601.05050,
-
[4]
The role of pragmatic and discourse context in determining argument impact
Esin Durmus, Faisal Ladhak, and Claire Cardie. The role of pragmatic and discourse context in determining argument impact. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5668–5678,
2019
-
[5]
com/news/measuring-model-persuasiveness
URL https://www.anthropic. com/news/measuring-model-persuasiveness. Akram Elbouanani, Aboubacar Tuo, and Adrian Popescu. A scalable entity-based frame- work for auditing bias in llms.arXiv preprint arXiv:2601.12374,
work page internal anchor Pith review arXiv
-
[6]
Liu, Valdemar Danry, Eunhae Lee, Samantha W
Cathy Mengying Fang, Auren R. Liu, Valdemar Danry, Eunhae Lee, Samantha W. T. Chan, Pat Pataranutaporn, Pattie Maes, Jason Phang, Michael Lampe, Lama Ahmad, and Sand- hini Agarwal. How ai and human behaviors shape psychosocial effects of chatbot use: A longitudinal randomized controlled study, 2025a. URL https://arxiv.org/abs/2503. 17473. Cathy Mengying F...
-
[7]
Under review
11 Preprint. Under review. Ivan Habernal and Iryna Gurevych. What makes a convincing argument? empirical analysis and detecting attributes of convincingness in web argumentation. In Jian Su, Kevin Duh, and Xavier Carreras (eds.),Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 1214–1223, Austin, Texas, November
2016
-
[8]
What makes a convincing argument?
Association for Computational Linguistics. doi: 10.18653/v1/D16-1129. URL https: //aclanthology.org/D16-1129/. Kobi Hackenburg, Ben M. Tappin, Luke Hewitt, Ed Saunders, Sid Black, Hause Lin, Cather- ine Fist, Helen Margetts, David G. Rand, and Christopher Summerfield. The levers of po- litical persuasion with conversational ai,
-
[9]
URL https://arxiv.org/abs/2507.13919. Mateusz Idziejczak, Vasyl Korzavatykh, Mateusz Stawicki, Andrii Chmutov, Marcin Korcz, Iwo Blkadek, and Dariusz Brzezinski. Among them: A game-based framework for assessing persuasion capabilities of llms. InPacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 183–195. Springer,
-
[10]
Co- writing with opinionated language models affects users’ views
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman. Co- writing with opinionated language models affects users’ views. InProceedings of the 2023 CHI conference on human factors in computing systems, pp. 1–15,
2023
-
[11]
Persuading across Diverse Domains: a Dataset and Persuasion Large Language Model
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.92. URLhttps://aclanthology.org/2024.acl-long.92/. Tianjie Ju, Yujia Chen, Hao Fei, Mong-Li Lee, Wynne Hsu, Pengzhou Cheng, Zongru Wu, Zhuosheng Zhang, and Gongshen Liu. On the adaptive psychological persuasion of large language models.arXiv preprint arXiv:2506.06800,
- [12]
-
[13]
Matthew Kowal, Jasper Timm, Jean-Francois Godbout, Thomas Costello, Antonio A Arechar, Gordon Pennycook, David Rand, Adam Gleave, and Kellin Pelrine. It’s the thought that counts: Evaluating the attempts of frontier llms to persuade on harmful topics.arXiv preprint arXiv:2506.02873,
-
[14]
doi: 10.1109/TAFFC.2024.3470984. Minqian Liu, Zhiyang Xu, Xinyi Zhang, Heajun An, Sarvech Qadir, Qi Zhang, Pamela J Wisniewski, Jin-Hee Cho, Sang Won Lee, Ruoxi Jia, et al. Llm can be a dangerous persuader: Empirical study of persuasion safety in large language models.arXiv preprint arXiv:2504.10430,
-
[15]
Matthieu Meeus, Lukas Wutschitz, Santiago Zanella-B´eguelin, Shruti Tople, and Reza Shokri
URL https://www.anthropic.com/ news/how-people-use-claude-for-support-advice-and-companionship. Matthieu Meeus, Lukas Wutschitz, Santiago Zanella-B´eguelin, Shruti Tople, and Reza Shokri. The canary’s echo: Auditing privacy risks of llm-generated synthetic text.arXiv preprint arXiv:2502.14921,
-
[16]
Measuring and benchmarking large language models’ capabilities to generate persuasive language
Amalie Brogaard Pauli, Isabelle Augenstein, and Ira Assent. Measuring and benchmarking large language models’ capabilities to generate persuasive language. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 10056–10075,
2025
-
[17]
Andrew Reece, Gus Cooney, Peter Bull, Christine Chung, Bryn Dawson, Casey Fitzpatrick, Tamara Glazer, Dean Knox, Alex Liebscher, and Sebastian Marin. Advancing an inter- disciplinary science of conversation: insights from a large multimodal corpus of human speech.arXiv preprint arXiv:2203.00674,
-
[18]
Alexander Rogiers, Sander Noels, Maarten Buyl, and Tijl De Bie. Persuasion with large language models: a survey.arXiv preprint arXiv:2411.06837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Philipp Schoenegger, Francesco Salvi, Jiacheng Liu, Xiaoli Nan, Ramit Debnath, Barbara Fasolo, Evelina Leivada, Gabriel Recchia, Fritz G¨unther, Ali Zarifhonarvar, et al. Large language models are more persuasive than incentivized human persuaders.arXiv preprint arXiv:2505.09662,
-
[20]
Association for Computa- tional Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.1016. URL https://aclanthology.org/2025.acl-long.1016/. Jocelyn Shen, Amina Luvsanchultem, Jessica Kim, Kynnedy Smith, Valdemar Danry, Kant- won Rogers, Sharifa Alghowinem, Hae Won Park, Maarten Sap, and Cynthia Breazeal. The hidden puppet master: A theoret...
-
[21]
Abhay Sheshadri, Aidan Ewart, Kai Fronsdal, Isha Gupta, Samuel R Bowman, Sara Price, Samuel Marks, and Rowan Wang. Auditbench: Evaluating alignment auditing techniques on models with hidden behaviors.arXiv preprint arXiv:2602.22755,
-
[22]
arXiv preprint arXiv:2410.02653 , year=
13 Preprint. Under review. Somesh Singh, Yaman K Singla, Harini Si, and Balaji Krishnamurthy. Measuring and improving persuasiveness of large language models.arXiv preprint arXiv:2410.02653,
-
[23]
Jasper Timm, Chetan Talele, and Jacob Haimes. Tailored truths: Optimizing llm persuasion with personalization and fabricated statistics.arXiv preprint arXiv:2501.17273,
-
[24]
Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good
Association for Computational Linguistics. doi: 10.18653/v1/P19-1566. URLhttps://aclanthology.org/P19-1566/. Wendy Wood. Attitude change: Persuasion and social influence.Annual review of psychology, 51(1):539–570,
-
[25]
doi: 10.18653/v1/2024.acl-long.773
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.773. URL https://aclanthology.org/2024. acl-long.773/. Chen Zhao, Yuan Tang, and Yitian Qian. Do deployment constraints make llms hallucinate citations? an empirical study across four models and five prompting regimes.arXiv preprint arXiv:2603.07287,
-
[26]
span”: “The fact that you’re even considering trying again is a sign of strength, not failure
A Appendix A User Response Taxonomy Interrogative Response 14 Preprint. Under review. Open-Ended by posing open-ended follow-up questions related to the conversation’s topic Shaikh et al. (2025); Bunt et al. (2012) Propositional/ Close-Ended by asking propositional, closed-ended ques- tions (e.g., yes/no, multiple-choice). Shaikh et al. (2025); Yeomans et...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.