Recognition: unknown
Beyond Acoustic Sparsity and Linguistic Bias: A Prompt-Free Paradigm for Mispronunciation Detection and Diagnosis
Pith reviewed 2026-05-08 09:22 UTC · model grok-4.3
The pith
A prompt-free framework decouples acoustic analysis from canonical pronunciation guidance for robust mispronunciation detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that an acoustic model enforcing monotonic frame-level alignment, combined with an implicit feedback strategy under the knowledge transfer principle, creates a prompt-free paradigm that decouples acoustic fidelity from explicit canonical guidance and thereby yields robust mispronunciation detection and diagnosis.
What carries the argument
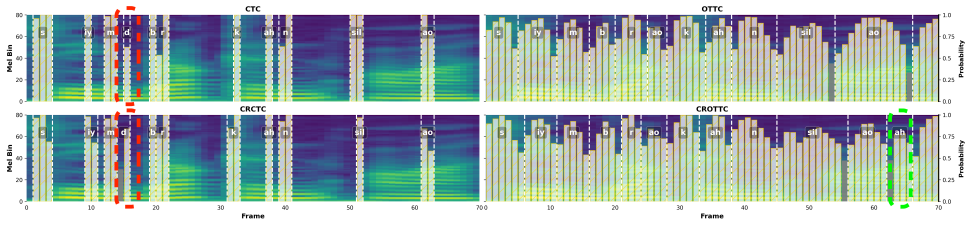
CROTTC, an acoustic model that enforces monotonic frame-level alignment to capture pronunciation deviations, paired with the IF strategy that implicitly injects mispronunciation information via knowledge transfer.
If this is right
- CROTTC-IF reaches 71.77 percent F1-score on the L2-ARCTIC dataset.
- CROTTC-IF reaches 71.70 percent F1-score on the Iqra'Eval2 leaderboard.
- Decoupling acoustics from explicit priors produces highly robust MDD across evaluated conditions.
- The method avoids both the neglect of transient cues in sequence-level CTC alignments and the prediction bias from canonical priors.
Where Pith is reading between the lines
- The framework could extend to accent adaptation tasks where avoiding explicit linguistic targets reduces unwanted bias.
- Evaluating the same decoupling on low-resource languages or child speech would test whether the robustness generalizes beyond the reported L2 benchmarks.
- Integration into language-learning interfaces might enable real-time diagnosis that operates without pre-loaded canonical references.
Load-bearing premise
The IF strategy can implicitly inject mispronunciation information effectively without introducing new biases or depending on the quality of the source models used for transfer.
What would settle it
A test showing that removing the IF component causes the F1-score to fall below 60 percent on L2-ARCTIC or that performance collapses on a new dataset using mismatched source models for transfer would falsify the value of the decoupling approach.
Figures





read the original abstract
Mispronunciation Detection and Diagnosis (MDD) requires modeling fine-grained acoustic deviations. However, current ASR-derived MDD systems often face inherent limitations. In particular, CTC-based models favor sequence-level alignments that neglect transient mispronunciation cues, while explicit canonical priors bias predictions toward intended targets. To address these bottlenecks, we propose a prompt-free framework decoupling acoustic fidelity from canonical guidance. First, we introduce CROTTC, an acoustic model enforcing monotonic, frame-level alignment to accurately capture pronunciation deviations. Second, we implicitly inject mispronunciation information via the IF strategy under the knowledge transfer principle. Experiments show CROTTC-IF achieves a 71.77% F1-score on L2-ARCTIC and 71.70% F1-score on the Iqra'Eval2 leaderboard. With empirical analysis, we demonstrate that decoupling acoustics from explicit priors provides highly robust MDD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a prompt-free framework for Mispronunciation Detection and Diagnosis (MDD) called CROTTC-IF. It introduces CROTTC as an acoustic model that enforces monotonic frame-level alignment to capture transient pronunciation deviations, addressing limitations of CTC-based sequence-level alignments. It further employs an IF strategy under the knowledge transfer principle to implicitly inject mispronunciation information, thereby decoupling acoustic fidelity from explicit canonical priors. Experiments report F1-scores of 71.77% on L2-ARCTIC and 71.70% on the Iqra'Eval2 leaderboard, supported by empirical analysis claiming robustness from this decoupling.
Significance. If the reported results and analysis hold with proper controls, the work could advance MDD by mitigating alignment biases and linguistic priors in ASR-derived systems, potentially improving sensitivity to fine-grained acoustic cues. The prompt-free design and high benchmark scores suggest practical value for robust, generalizable detection, especially in low-resource linguistic settings. The focus on monotonic alignment and implicit transfer offers a distinct direction from prior explicit-prior methods.
major comments (3)
- Abstract: The reported F1-scores of 71.77% on L2-ARCTIC and 71.70% on Iqra'Eval2 are presented without any details on baseline methods, error bars, data splits, or ablation studies, making it impossible to evaluate the claimed improvements or the robustness of the decoupling approach.
- IF strategy section: The knowledge transfer principle for implicit injection relies on source models and training details that are unspecified, creating dependence on prior components and potential for new biases, which directly undermines the central claim of decoupling from explicit priors.
- Empirical analysis: The demonstration that decoupling acoustics from explicit priors yields highly robust MDD rests on undescribed analysis, with no specific controls, comparisons, or evidence provided to substantiate the robustness conclusion.
minor comments (1)
- Abstract: Acronyms CROTTC and IF are used without initial expansion or brief definition, reducing immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our work on the prompt-free CROTTC-IF framework for MDD. We address each major comment point by point below, providing explanations grounded in the manuscript and proposing targeted revisions to enhance clarity, reproducibility, and substantiation of claims without altering the core contributions.
read point-by-point responses
-
Referee: Abstract: The reported F1-scores of 71.77% on L2-ARCTIC and 71.70% on Iqra'Eval2 are presented without any details on baseline methods, error bars, data splits, or ablation studies, making it impossible to evaluate the claimed improvements or the robustness of the decoupling approach.
Authors: The abstract is deliberately concise to highlight the main results and contributions. Comprehensive details on baseline methods (including comparisons to CTC-based and prior-prior MDD systems), data splits (standard L2-ARCTIC partitions and Iqra'Eval2 leaderboard protocol), error bars (reported as standard deviations across multiple runs in Tables 2 and 3), and ablation studies (Section 5.2) are provided in the experimental sections. To address the concern directly, we will revise the abstract to include a brief parenthetical note on key baselines and data protocols while maintaining length constraints, and ensure the abstract explicitly references the experimental section for full evaluation. revision: partial
-
Referee: IF strategy section: The knowledge transfer principle for implicit injection relies on source models and training details that are unspecified, creating dependence on prior components and potential for new biases, which directly undermines the central claim of decoupling from explicit priors.
Authors: We agree that full specification of the source models and training details is essential for reproducibility and to rigorously support the decoupling claim. The manuscript describes the IF strategy at a high level in Section 3.2 under the knowledge transfer principle, but we acknowledge the need for explicit details on the pre-trained source models (e.g., specific ASR backbones), loss formulations, and hyperparameter settings. In the revised manuscript, we will expand Section 3.2 with a new subsection providing these specifications, including how implicit injection avoids explicit canonical priors, along with pseudocode for the transfer process. This will eliminate any ambiguity and strengthen the evidence against introduced biases. revision: yes
-
Referee: Empirical analysis: The demonstration that decoupling acoustics from explicit priors yields highly robust MDD rests on undescribed analysis, with no specific controls, comparisons, or evidence provided to substantiate the robustness conclusion.
Authors: The empirical analysis demonstrating robustness via decoupling is presented in Section 5.3, which includes targeted comparisons of CROTTC-IF against explicit-prior variants, controls for monotonic vs. non-monotonic alignment, and cross-dataset robustness tests on varied L2 accents and noise conditions. Specific evidence includes performance deltas in ablations and qualitative alignment visualizations. However, to make the controls and comparisons more explicit and accessible, we will revise Section 5.3 to add a dedicated paragraph summarizing the experimental controls, include an additional table of robustness metrics, and expand the discussion of how these substantiate the central claim. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents CROTTC as an acoustic model with monotonic frame-level alignment and IF as an implicit knowledge-transfer injection, then reports empirical F1 scores on external L2-ARCTIC and Iqra'Eval2 benchmarks. No equations, derivations, or self-citations appear in the provided text that reduce any claimed prediction or first-principles result to the inputs by construction. The decoupling claim is supported by external leaderboard results rather than internal re-use of fitted parameters or self-referential definitions, rendering the reported performance self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge transfer principle enables effective implicit injection of mispronunciation cues without explicit priors
invented entities (2)
-
CROTTC
no independent evidence
-
IF strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Mispronunciation Detection and Diagnosis (MDD) plays an in- dispensable role across a spectrum of applications, ranging from general Computer-Aided Pronunciation Training (CAPT) for L2 learners to religious domains such as Qur’anic recitation, as highlighted by the Iqra’Eval Challenges [1, 2]. The core chal- lenge of MDD lies in acoustic fide...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Related Works Currently, modern MDD approaches broadly fall into two cate- gories: dictation-style and text-prompting style. 2.1. Dictation-Style MDD and the Acoustic Trap Dictation-style methods aim to recognize the uttered phoneme sequence exclusively from acoustic-related features. For exam- ple, Leung et al. introduced a CTC framework and demon- strat...
2025
-
[3]
Our approach, as illustrated in the left panel of Figure 1, is built upon two core pillars: Consistency Regularization(CR)and Optimal Temporal Transport Classifi- cation(OTTC)
Consistency Regularization on Optimal Temporal Transport Classification In this section, we analyze the inherent limitations of CTC and introduce the architecture of our proposed frame-wise dense acoustic model:CROTTC. Our approach, as illustrated in the left panel of Figure 1, is built upon two core pillars: Consistency Regularization(CR)and Optimal Temp...
-
[4]
As illustrated in the middle and right panels of Fig
Indirect Fusion of Mispronunciation Information via Knowledge Transfer In this section, we detail our Indirect Fusion (IF) strategy for in- corporating mispronunciation information into LM, namedIF- MDD. As illustrated in the middle and right panels of Fig. 1, IF-MDD treats canonical phonemes and mispronunciation cues as privileged information available e...
-
[5]
As illustrated in Fig
Leveraging LLMs to Investigate Canonical Information Effect on MDD To empirically investigate the impact of explicit canonical in- formation and strong linguistic priors, this section introduces an LLM-based architecture, denoted asLLM-MDD. As illustrated in Fig. 3, we replace the conventional lightweight LM with an open-source LLM, which serves as a high...
-
[6]
Experimental Evaluation This section comprehensively evaluates our CROTTC-IF framework against conventional dictation- and text-prompting- style baselines, alongside an empirical analysis of canonical pri- ors using LLM-MDD. 6.1. Datasets Table 1 summarizes the L2 English datasets utilized in our ex- periments. The most widely recognized among these is L2...
-
[7]
Unlike standard L2 English benchmarks, Qur’anic 6In MDD, PER is considered secondary to F1 and FRR [9,22]
Iqra’Eval2 Challenge The Iqra’Eval2 Challenge [2] provides an ideal arena for our framework. Unlike standard L2 English benchmarks, Qur’anic 6In MDD, PER is considered secondary to F1 and FRR [9,22]. High PER often reflects redundant insertions that do not degrade diagnostic accuracy, as evidenced by our robust COR at 92.42%. Table 6:Overview of the Iqra’...
-
[8]
Conclusion and Future Work In this paper, we proposedCROTTC-IF, a canonical prompt- free framework designed to overcome the inherent acoustic and linguistic bottlenecks in MDD. By integrating a dedi- cated acoustic frontend with an implicit knowledge transfer lan- guage model, our architecture achieves robust, state-of-the-art performance across diverse s...
-
[9]
The authors have verified all content and re- tain full responsibility for the accuracy and originality of this work
Generative AI Use Disclosure Generative AI technology was employed strictly for minor grammatical corrections and stylistic improvements during the drafting process. The authors have verified all content and re- tain full responsibility for the accuracy and originality of this work
-
[10]
Iqra’eval: A shared task on qur’anic pronunciation assessment,
Y . El Kheir, A. Meghanani, H. O. Toyinet al., “Iqra’eval: A shared task on qur’anic pronunciation assessment,” inArabicNLP, 2025, pp. 443–452
2025
-
[11]
Towards a unified benchmark for arabic pronunciation assessment: Quranic recita- tion as case study,
Y . E. Kheir, O. Ibrahim, A. Meghananiet al., “Towards a unified benchmark for arabic pronunciation assessment: Quranic recita- tion as case study,” 2025
2025
-
[12]
Phone-level pronunciation scoring and assessment for interactive language learning,
S. M. Witt and S. J. Young, “Phone-level pronunciation scoring and assessment for interactive language learning,”Speech com- munication, vol. 30, no. 2-3, pp. 95–108, 2000
2000
-
[13]
Implementation of an extended recognition network for mispronunciation detection and diagnosis in computer-assisted pronunciation training
A. M. Harrison, W.-K. Lo, X. Qianet al., “Implementation of an extended recognition network for mispronunciation detection and diagnosis in computer-assisted pronunciation training.” inSLaTE, 2009, pp. 45–48
2009
-
[14]
Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neural networks,
K. Li, X. Qian, and H. Meng, “Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neural networks,”IEEE/ACM TASLP, vol. 25, no. 1, pp. 193–207, 2016
2016
-
[15]
Connectionist tempo- ral classification: labelling unsegmented sequence data with re- current neural networks,
A. Graves, S. Fern ´andez, F. Gomezet al., “Connectionist tempo- ral classification: labelling unsegmented sequence data with re- current neural networks,” inICML, 2006, pp. 369–376
2006
-
[16]
Hybrid CTC/attention archi- tecture for end-to-end speech recognition,
S. Watanabe, T. Hori, S. Kimet al., “Hybrid CTC/attention archi- tecture for end-to-end speech recognition,”IEEE JSTSP, vol. 11, no. 8, pp. 1240–1253, 2017
2017
-
[17]
Sequence transduction with recurrent neural net- works,
A. Graves, “Sequence transduction with recurrent neural net- works,”ICML, 2012
2012
-
[18]
CNN-RNN-CTC based end- to-end mispronunciation detection and diagnosis,
W.-K. Leung, X. Liu, and H. Meng, “CNN-RNN-CTC based end- to-end mispronunciation detection and diagnosis,” inICASSP, 2019, pp. 8132–8136
2019
-
[19]
wav2vec 2.0: a frame- work for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamedet al., “wav2vec 2.0: a frame- work for self-supervised learning of speech representations,” in NeurIPS, 2020
2020
-
[20]
Hubert: Self- supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsaiet al., “Hubert: Self- supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM TASLP, vol. 29, pp. 3451–3460, 2021
2021
-
[21]
mHuBERT-147: A Compact Multilingual HuBERT Model,
M. Z. Boito, V . Iyer, N. Lagoset al., “mHuBERT-147: A Compact Multilingual HuBERT Model,” inInterspeech 2024, 2024
2024
-
[22]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chenet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE JSTSP, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[23]
A study on fine-tuning wav2vec2. 0 model for the task of mispronunciation detection and diagnosis
L. Peng, K. Fu, B. Linet al., “A study on fine-tuning wav2vec2. 0 model for the task of mispronunciation detection and diagnosis.” inInterspeech, 2021, pp. 4448–4452
2021
-
[24]
Improving mispro- nunciation detection with wav2vec2-based momentum pseudo- labeling for accentedness and intelligibility assessment,
M. Yang, K. Hirschi, S. D. Looneyet al., “Improving mispro- nunciation detection with wav2vec2-based momentum pseudo- labeling for accentedness and intelligibility assessment,” inInter- speech, 2022, pp. 4481–4485
2022
-
[25]
Multi-view multi-task representation learning for mispronunciation detection,
Y . EL Kheir, S. Chowdhury, and A. Ali, “Multi-view multi-task representation learning for mispronunciation detection,” inSLaTE 2023, 2023, pp. 86–90
2023
-
[26]
Pg-mdd: Prompt-guided mispronunciation detection and diagnosis leveraging articulatory features,
M.-S. Lin, B.-C. Yan, T.-H. Loet al., “Pg-mdd: Prompt-guided mispronunciation detection and diagnosis leveraging articulatory features,” inAPSIPA ASC. IEEE, 2024, pp. 1–6
2024
-
[27]
Hafs2Vec: A system for the IqraEval Arabic and qur’anic phoneme-level pronunciation assessment,
A. Ibrahim, “Hafs2Vec: A system for the IqraEval Arabic and qur’anic phoneme-level pronunciation assessment,” inArabic- NLP, Nov. 2025, pp. 453–456
2025
-
[28]
Metapseud at iqra’eval: Domain adaptation with multi-stage fine-tuning for phoneme-level qur’anic mispronunci- ation detection,
A. Mansour, “Metapseud at iqra’eval: Domain adaptation with multi-stage fine-tuning for phoneme-level qur’anic mispronunci- ation detection,” inArabicNLP, Nov. 2025, pp. 475–479
2025
-
[29]
Sed-mdd: Towards sentence de- pendent end-to-end mispronunciation detection and diagnosis,
Y . Feng, G. Fu, Q. Chenet al., “Sed-mdd: Towards sentence de- pendent end-to-end mispronunciation detection and diagnosis,” in ICASSP 2020 - 2020 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2020, pp. 3492– 3496
2020
-
[30]
Phoneme mispronunciation detection by jointly learning to align,
B. Lin and L. Wang, “Phoneme mispronunciation detection by jointly learning to align,” inICASSP, 2022, pp. 6822–6826
2022
-
[31]
Mispronunciation de- tection and diagnosis without model training: A retrieval-based approach,
H. T. Tu, H. V . Khanh, T. T. Datet al., “Mispronunciation de- tection and diagnosis without model training: A retrieval-based approach,”arXiv preprint arXiv:2511.20107, 2025
-
[32]
An approach to mispronuncia- tion detection and diagnosis with acoustic, phonetic and linguistic (apl) embeddings,
W. Ye, S. Mao, F. Soonget al., “An approach to mispronuncia- tion detection and diagnosis with acoustic, phonetic and linguistic (apl) embeddings,” inICASSP. IEEE, 2022, pp. 6827–6831
2022
-
[33]
Text-aware end-to-end mispronunciation detection and diagnosis,
L. Peng, Y . Gao, B. Linet al., “Text-aware end-to-end mispronunciation detection and diagnosis,”arXiv preprint arXiv:2206.07289, 2022
-
[34]
Coca-mdd: A coupled cross-attention based framework for streaming mispronunciation detection and diagnosis,
N. Zheng, L. Deng, W. Huanget al., “Coca-mdd: A coupled cross-attention based framework for streaming mispronunciation detection and diagnosis,” inInterspeech 2022, 2022, pp. 4352– 4356
2022
-
[35]
Effective graph-based modeling of articulation traits for mispronunciation detection and diagnosis,
B.-C. Yan, H.-W. Wang, Y .-C. Wanget al., “Effective graph-based modeling of articulation traits for mispronunciation detection and diagnosis,” inICASSP. IEEE, 2023, pp. 1–5
2023
-
[36]
Peppanet: Effective mispronunciation detection and diagnosis leveraging phonetic, phonological, and acoustic cues,
B.-C. Yan, H.-W. Wang, and B. Chen, “Peppanet: Effective mispronunciation detection and diagnosis leveraging phonetic, phonological, and acoustic cues,” inIEEE SLT, 2022, pp. 1045– 1051
2022
-
[37]
Slam-llm: A modular, open- source multimodal large language model framework and best practice for speech, language, audio and music processing,
Z. Ma, G. Yang, W. Chenet al., “Slam-llm: A modular, open- source multimodal large language model framework and best practice for speech, language, audio and music processing,”Proc. IEEE Journal of Selected Topics in Signal Processing, 2026
2026
-
[38]
Y . Chu, J. Xu, Q. Yanget al., “Qwen2-audio technical report,” arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Prompting large language models with mispronunciation detection and diagnosis abilities,
M. Wu, J. Xu, X. Wuet al., “Prompting large language models with mispronunciation detection and diagnosis abilities,” inInter- speech, 2024, pp. 2990–2994
2024
-
[40]
Integrating potential pronuncia- tions for enhanced mispronunciation detection and diagnosis abil- ity in LLMs,
M. Wu, J. Xu, X. Chenet al., “Integrating potential pronuncia- tions for enhanced mispronunciation detection and diagnosis abil- ity in LLMs,” inICASSP. IEEE, 2025, pp. 1–5
2025
-
[41]
Phoneme-controlled llm with self-supervised speech prompts for mispronunciation detec- tion,
Z. Song, Z. Kadeer, M. Kahaeret al., “Phoneme-controlled llm with self-supervised speech prompts for mispronunciation detec- tion,”ACMMM Asia, 2025
2025
-
[42]
Leveraging large language mod- els to refine automatic feedback generation at articulatory level in computer aided pronunciation training
H. Zhong, Y . Xie, and Z. Yao, “Leveraging large language mod- els to refine automatic feedback generation at articulatory level in computer aided pronunciation training.” inINTERSPEECH, 2024
2024
-
[43]
Mispronunciation detection and diagnosis based on large language models,
Y . Xie, H. Zhong, X. Lanet al., “Mispronunciation detection and diagnosis based on large language models,”Computer Speech & Language, p. 101942, 2026
2026
-
[44]
Development of shadowing speech corpora to measure instantaneous intelligibil- ity as sequential annotation on L2 speech,
N. Minematsu, C. Zhu, G. Dangtranet al., “Development of shadowing speech corpora to measure instantaneous intelligibil- ity as sequential annotation on L2 speech,” inTech. Rep. Speech, Acoust. Soc. Jpn, 2022, pp. 7–12
2022
-
[45]
A pilot study of applying sequence-to-sequence voice conversion to evaluate the intelligi- bility of l2 speech using a native speaker’s shadowings,
H. Geng, D. Saito, and N. Minematsu, “A pilot study of applying sequence-to-sequence voice conversion to evaluate the intelligi- bility of l2 speech using a native speaker’s shadowings,” inProc. APSIPA ASC, 2024, pp. 1–6
2024
-
[46]
A perception-based l2 speech intelligibility indicator: Leveraging a rater’s shadowing and sequence-to-sequence voice conversion,
——, “A perception-based l2 speech intelligibility indicator: Leveraging a rater’s shadowing and sequence-to-sequence voice conversion,” inProc. Interspeech 2025, 2025, pp. 2420–2424
2025
-
[47]
Why does CTC result in peaky behavior?
A. Zeyer, R. Schl ¨uter, and H. Ney, “Why does CTC result in peaky behavior?”arXiv preprint arXiv:2105.14849, 2021
-
[48]
Bayes risk ctc: Controllable ctc alignment in sequence-to-sequence tasks,
J. Tian, B. Yan, J. Yuet al., “Bayes risk ctc: Controllable ctc alignment in sequence-to-sequence tasks,”arXiv preprint arXiv:2210.07499, 2022
-
[49]
Delay-penalized ctc imple- mented based on finite state transducer,
Z. Yao, W. Kang, F. Kuanget al., “Delay-penalized ctc imple- mented based on finite state transducer,” inProc. Interspeech 2023, 2023, pp. 1329–1333
2023
-
[50]
A differentiable align- ment framework for sequence-to-sequence modeling via optimal transport,
Y . Kaloga, S. Kumar, P. Motliceket al., “A differentiable align- ment framework for sequence-to-sequence modeling via optimal transport,”arXiv preprint arXiv:2502.01588, 2025
-
[51]
CR-CTC: Consistency regular- ization on ctc for improved speech recognition,
Z. Yao, W. Kang, X. Yanget al., “CR-CTC: Consistency regular- ization on ctc for improved speech recognition,” inICLR, 2024
2024
-
[52]
A new learning paradigm: Learning using privileged information,
V . Vapnik and A. Vashist, “A new learning paradigm: Learning using privileged information,”Neural networks, vol. 22, no. 5-6, pp. 544–557, 2009
2009
-
[53]
Learning using privileged informa- tion: similarity control and knowledge transfer,
V . Vapnik and R. Izmailov, “Learning using privileged informa- tion: similarity control and knowledge transfer,”The Journal of Machine Learning Research, vol. 16, no. 1, pp. 2023–2049, 2015
2023
-
[54]
Implicit transfer of privileged acoustic information in a generalized knowledge distillation framework
T. Fukuda and S. Thomas, “Implicit transfer of privileged acoustic information in a generalized knowledge distillation framework.” inInterspeech, 2020, pp. 41–45
2020
-
[55]
Efficient knowledge dis- tillation from an ensemble of teachers
T. Fukuda, M. Suzuki, G. Kurataet al., “Efficient knowledge dis- tillation from an ensemble of teachers.” inInterspeech, 2017, pp. 3697–3701
2017
-
[56]
Temporal order preserved optimal transport-based cross-modal knowledge transfer learning for asr,
X. Lu, P. Shen, Y . Tsaoet al., “Temporal order preserved optimal transport-based cross-modal knowledge transfer learning for asr,” in2024 SLT, 2024, pp. 1–8
2024
-
[57]
Unifying distilla- tion and privileged information,
D. Lopez-Paz, L. Bottou, B. Sch ¨olkopfet al., “Unifying distilla- tion and privileged information,”ICLR, 2016
2016
-
[58]
Pi-dual: using privileged information to distinguish clean from noisy labels,
K. Wang, G. Ortiz-Jimenez, R. Jenattonet al., “Pi-dual: using privileged information to distinguish clean from noisy labels,” in ICML, 2024
2024
-
[59]
When does privileged information explain away label noise?
G. Ortiz-Jimenez, M. Collier, A. Nawalgariaet al., “When does privileged information explain away label noise?” inICML, 2023, pp. 26 646–26 669
2023
-
[60]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Luet al., “Roformer: Enhanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[61]
Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention,
H. Tachibana, K. Uenoyama, and S. Aihara, “Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention,” inICASSP. IEEE, 2018, pp. 4784–4788
2018
-
[62]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Walliset al., “Lora: Low-rank adaptation of large language models.”Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[63]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiuet al., “Conformer: Convolution- augmented transformer for speech recognition,” inInterspeech, 2020, pp. 5036–5040
2020
-
[64]
A. Grattafiori, A. Dubey, A. Jauhriet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[65]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[66]
L2-arctic: A non-native english speech corpus,
G. Zhao, S. Sonsaat, A. Silpachaiet al., “L2-arctic: A non-native english speech corpus,” inInterspeech, 2018, p. 2783–2787
2018
-
[67]
speechocean762: An open- source non-native english speech corpus for pronunciation assess- ment,
J. Zhang, Z. Zhang, Y . Wanget al., “speechocean762: An open- source non-native english speech corpus for pronunciation assess- ment,” inProc. Interspeech 2021, 2021
2021
-
[68]
Ume english speech database read by japanese students (ume-erj),
S. D. C. of the Priority Areas Project, “Ume english speech database read by japanese students (ume-erj),” jun 2007
2007
-
[69]
English read by japanese phonetic cor- pus: An interim report,
T. Makino and R. Aoki, “English read by japanese phonetic cor- pus: An interim report,”Research in Language, vol. 9, no. 2, pp. 79–95, 2012
2012
-
[70]
Mispronunciation detection and diagnosis in L2 english speech using multidistribution deep neural networks,
K. Li, X. Qian, and H. Meng, “Mispronunciation detection and diagnosis in L2 english speech using multidistribution deep neural networks,”IEEE/ACM TASLP, vol. 25, no. 1, pp. 193–207, 2017
2017
-
[71]
Phonetic rnn-transducer for mispronunciation diagnosis,
D. Y . Zhang, S. Saha, and S. Campbell, “Phonetic rnn-transducer for mispronunciation diagnosis,” inICASSP, 2023, pp. 1–5
2023
-
[72]
A study of mispronunciation detec- tion and diagnosis based on meta-learning,
Y . Wan, Y . Shi, B. Linet al., “A study of mispronunciation detec- tion and diagnosis based on meta-learning,” inICASSP, 2024, pp. 12 792–12 796
2024
-
[73]
Pronunciation error detection model based on feature fusion,
C. Zhu, A. Wumaier, D. Weiet al., “Pronunciation error detection model based on feature fusion,”Speech Communication, vol. 156, p. 103009, 2024
2024
-
[74]
He, B.-C
Y .-Y . He, B.-C. Yan, T.-H. Loet al., “JAM: A unified neural archi- tecture for joint multi-granularity pronunciation assessment and phone-level mispronunciation detection and diagnosis towards a comprehensive capt system,” in2024 APSIPA ASC, 2024, pp. 1– 6
2024
-
[75]
Muffin: Multifaceted pro- nunciation feedback model with interactive hierarchical neural modeling,
B.-C. Yan, M.-K. Tsai, and B. Chen, “Muffin: Multifaceted pro- nunciation feedback model with interactive hierarchical neural modeling,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 4295–4310, 2025
2025
-
[76]
A Joint Model for Pronunciation Assessment and Mispronunciation Detection and Diagnosis with Multi-task Learning,
H. Ryu, S. Kim, and M. Chung, “A Joint Model for Pronunciation Assessment and Mispronunciation Detection and Diagnosis with Multi-task Learning,” inInterspeech 2023, 2023, pp. 959–963
2023
-
[77]
Phonetic inventory for an Arabic speech corpus,
N. Halabi and M. Wald, “Phonetic inventory for an Arabic speech corpus,” inLREC, May 2016, pp. 734–738
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.