Recognition: unknown
TTS-PRISM: A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis
Pith reviewed 2026-05-08 11:59 UTC · model grok-4.3
The pith
TTS-PRISM embeds a 12-dimensional schema into a model that reasons about and scores fine-grained perceptual flaws in Mandarin text-to-speech output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TTS-PRISM establishes a perceptual reasoning model for Mandarin TTS by embedding a 12-dimensional diagnostic schema through instruction tuning on a dataset built from adversarial perturbations and expert anchors. On a 1,600-sample test set, it achieves better alignment with human judgments than generalist models, and when applied to six TTS paradigms, it produces diagnostic flags that distinguish their capabilities at a fine-grained level.
What carries the argument
The 12-dimensional perceptual schema, populated via targeted synthesis with adversarial perturbations and expert anchors, then embedded into an end-to-end model through schema-driven instruction tuning that forces explicit scoring and reasoning.
If this is right
- TTS developers can run any new system through the model to receive dimension-by-dimension flags instead of a single score.
- Training loops can use the per-dimension scores to focus optimization on the weakest perceptual areas.
- The open-source checkpoints allow direct comparison of future TTS variants against the same diagnostic baseline.
- Production pipelines gain an automated way to reject outputs that fail on specific stability or expressiveness flags.
Where Pith is reading between the lines
- The same schema-plus-tuning pattern could be recreated for other languages by repeating the perturbation and anchoring steps with native listeners.
- If the diagnostic flags prove stable, they could serve as auxiliary rewards inside reinforcement learning from human feedback for TTS.
- Integrating the model as a lightweight checker before deployment might reduce the need for large-scale human listening tests.
Load-bearing premise
The twelve dimensions, derived from adversarial perturbations and expert anchors, capture every important aspect of human judgment of Mandarin speech without gaps or systematic bias.
What would settle it
Human listeners on a new Mandarin speech set identify a recurring quality problem that none of the twelve dimensions accounts for, or TTS-PRISM scores diverge sharply from human ratings on additional test samples.
Figures


read the original abstract
While generative text-to-speech (TTS) models approach human-level quality, monolithic metrics fail to diagnose fine-grained acoustic artifacts or explain perceptual collapse. To address this, we propose TTS-PRISM, a multi-dimensional diagnostic framework for Mandarin. First, we establish a 12-dimensional schema spanning stability to advanced expressiveness. Second, we design a targeted synthesis pipeline with adversarial perturbations and expert anchors to build a high-quality diagnostic dataset. Third, schema-driven instruction tuning embeds explicit scoring criteria and reasoning into an efficient end-to-end model. Experiments on a 1,600-sample Gold Test Set show TTS-PRISM outperforms generalist models in human alignment. Profiling six TTS paradigms establishes intuitive diagnostic flags that reveal fine-grained capability differences. TTS-PRISM is open-source, with code and checkpoints at https://github.com/xiaomi-research/tts-prism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TTS-PRISM, a multi-dimensional diagnostic framework for Mandarin TTS. It first establishes a 12-dimensional perceptual schema spanning stability to advanced expressiveness, then designs a targeted synthesis pipeline using adversarial perturbations and expert anchors to create a diagnostic dataset, and finally applies schema-driven instruction tuning to embed explicit scoring criteria and reasoning into an efficient end-to-end model. Experiments on a 1,600-sample Gold Test Set are claimed to show that TTS-PRISM outperforms generalist models in human alignment, while profiling six TTS paradigms yields intuitive diagnostic flags revealing fine-grained capability differences. The work is released open-source with code and checkpoints.
Significance. If the empirical results hold after proper validation, TTS-PRISM could meaningfully advance TTS evaluation by replacing monolithic metrics with interpretable, fine-grained perceptual diagnostics, particularly for Mandarin speech where current tools are limited. The open-source release of code and checkpoints would further support reproducibility and adoption in both research and industry settings for targeted model improvement.
major comments (2)
- [Abstract] Abstract: the central claims of outperformance in human alignment on the 1,600-sample Gold Test Set and establishment of diagnostic flags for six TTS paradigms are asserted without any quantitative metrics, baseline details, statistical tests, ablation results, or effect sizes, leaving the empirical support for the framework's utility invisible in the provided text.
- [Schema construction] The 12-dimensional schema (introduced via adversarial perturbations and expert anchors): this construction is load-bearing for all downstream claims of human alignment and fine-grained profiling, yet no coverage analysis, inter-rater agreement metrics with naïve listeners, or correlation with open-ended perceptual reports are reported, raising the risk that the schema omits critical dimensions or embeds selection/anchoring biases that would make reported alignment metrics tautological rather than independently predictive.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important opportunities to strengthen the presentation of empirical results and the validation of the perceptual schema. We address each major comment point-by-point below and have prepared revisions to the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of outperformance in human alignment on the 1,600-sample Gold Test Set and establishment of diagnostic flags for six TTS paradigms are asserted without any quantitative metrics, baseline details, statistical tests, ablation results, or effect sizes, leaving the empirical support for the framework's utility invisible in the provided text.
Authors: We agree that the abstract, as a high-level summary, would be strengthened by including key quantitative indicators. In the revised version we have added concise references to the main human-alignment metrics (correlation with expert ratings on the Gold Test Set), the primary baselines (generalist LLMs), and the statistical significance of the observed improvements, while preserving the abstract's brevity. Full tables of results, ablation studies, and effect sizes remain in the Experiments section. revision: yes
-
Referee: [Schema construction] The 12-dimensional schema (introduced via adversarial perturbations and expert anchors): this construction is load-bearing for all downstream claims of human alignment and fine-grained profiling, yet no coverage analysis, inter-rater agreement metrics with naïve listeners, or correlation with open-ended perceptual reports are reported, raising the risk that the schema omits critical dimensions or embeds selection/anchoring biases that would make reported alignment metrics tautological rather than independently predictive.
Authors: The schema was constructed from a systematic review of TTS perceptual literature combined with iterative expert consultation to span stability through advanced expressiveness. Expert anchors and adversarial perturbations were employed to isolate dimensions during dataset creation. We acknowledge that coverage analysis, naïve-listener agreement, and correlation with open-ended reports were not reported. In the revision we will add: (i) a mapping of the 12 dimensions to commonly reported perceptual issues in Mandarin TTS, (ii) inter-rater reliability statistics obtained from a supplementary panel of naïve listeners on a held-out subset, and (iii) Pearson correlations between schema-based scores and free-form listener descriptions. These additions will further demonstrate that the Gold Test Set labels were collected independently of schema construction, thereby avoiding circularity. revision: yes
Circularity Check
No circularity detected; framework is externally grounded without reduction to inputs by construction.
full rationale
The paper describes a sequential construction: a 12-dimensional schema is established, a synthesis pipeline with adversarial perturbations and expert anchors creates the diagnostic dataset, schema-driven tuning produces the model, and performance is reported on a distinct 1,600-sample Gold Test Set for human alignment. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described chain that would make any result equivalent to its inputs by definition. The claims rest on the external test set and labels rather than tautological self-reference, rendering the process self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
12-dimensional perceptual schema
no independent evidence
Reference graph
Works this paper leans on
-
[1]
black box
Introduction Driven by the rapid evolution of large-scale generative mod- els, modern Text-to-Speech (TTS) [ 1, 2, 3, 4, 5, 6] systems have achieved human-level capabilities. However, the traditional Mean Opinion Score (MOS) [7] faces a “black box” dilemma: its single scalar obscures real capabilities in pronunciation, prosody, and emotion, and fails to c...
-
[2]
TTS-PRISM: A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis
Methodology To enable fine-grained diagnosis of generative speech, we pro- pose TTS-PRISM, a framework comprising a hierarchical evalu- ation schema, a targeted data synthesis pipeline, and a diagnostic scoring model. Crucially, to eliminate subjective ambiguity, we anchor each score level to explicit tolerance thresholds (e.g., defining specific artifact...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Compute-matched
Experimental Setup 3.1. Dataset & Training Configuration To evaluate alignment precision, we build a stratified 1,600- sample Mandarin Gold Test Set, strictly disjoint from training data, with 20% out-of-distribution (OOD) samples (unseen TTS and real recordings) and all labels validated via consensus-based expert annotation. For training, we perform full...
-
[4]
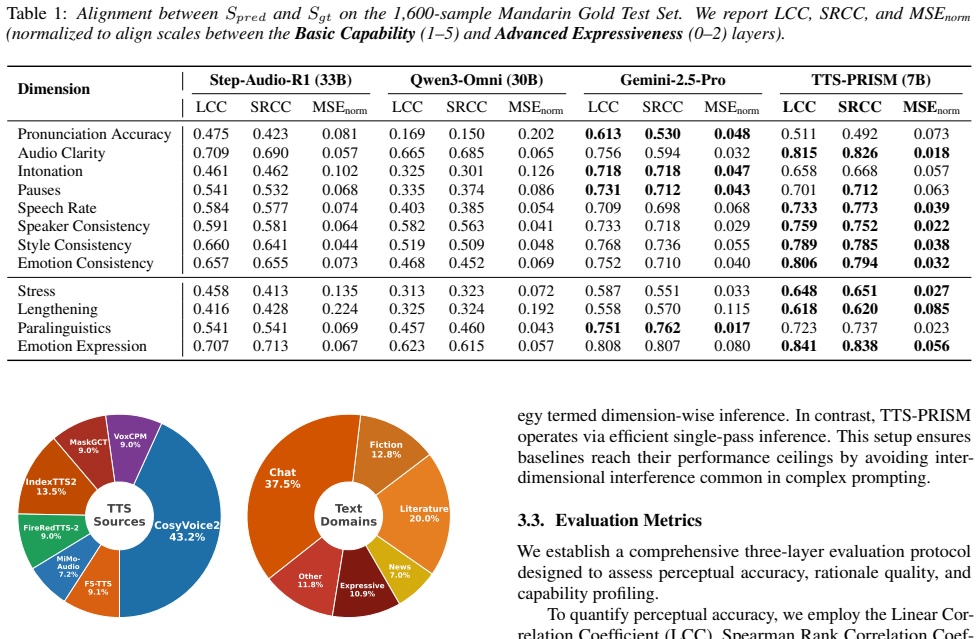
Results 4.1. Fine-grained Accuracy and Rationale Quality Table 1 shows TTS-PRISM’s superior alignment on the 1,600- sample Gold Test Set. Noise-injected training enables acute sen- sitivity to physical noise and artifacts. For Emotion Expression, our expert-anchored samples mitigate over-smoothing in general- ist models, enabling precise high-arousal quan...
-
[5]
Experiments demonstrate superior human alignment and leading TTS profiling over generalist models
Conclusion We propose TTS-PRISM, a fine-grained Mandarin speech di- agnostic framework. Experiments demonstrate superior human alignment and leading TTS profiling over generalist models. However, Pronunciation Accuracy limitations reveal the inherent intelligibility tolerance of ASR backbones—a bias difficult to override via instruction tuning. Future wor...
-
[6]
These tools were not used to generate any core scientific ideas, experimental data, or technical contributions
Generative AI Use Disclosure During the preparation of this manuscript, the authors used gen- erative AI tools exclusively for the purpose of language editing and manuscript polishing to improve readability. These tools were not used to generate any core scientific ideas, experimental data, or technical contributions. All authors have thoroughly reviewed ...
-
[7]
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shiet al., “CosyV oice 3: Towards in-the- wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
-
[8]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. JianZhao, K. Yu, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inAnnual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 6255–6271
2025
-
[9]
MaskGCT: Zero-shot text-to- speech with masked generative codec transformer,
Y . Wang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “MaskGCT: Zero-shot text-to- speech with masked generative codec transformer,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guoet al., “Qwen3-TTS technical report,” arXiv preprint arXiv:2601.15621, 2026
-
[11]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “IndexTTS2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech,” arXiv preprint arXiv:2506.21619, 2025
-
[12]
FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot,
K. Xie, F. Shen, J. Li, F. Xie, X. Tang, and Y . Hu, “FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot,”arXiv preprint arXiv:2509.02020, 2025
-
[13]
Mean opinion score (MOS) revisited: Methods and applications, limitations and alter- natives,
R. C. Streijl, S. Winkler, and D. S. Hands, “Mean opinion score (MOS) revisited: Methods and applications, limitations and alter- natives,”Multimedia Systems, vol. 22, no. 2, pp. 213–227, 2016
2016
-
[14]
SpeechBERTScore: Reference-aware automatic evaluation of speech generation leveraging NLP evaluation metrics,
T. Saeki, S. Maiti, S. Takamichi, S. Watanabe, and H. Saruwatari, “SpeechBERTScore: Reference-aware automatic evaluation of speech generation leveraging NLP evaluation metrics,” inAnnual Conference of the International Speech Communication Associa- tion (INTERSPEECH). ISCA, 2024, pp. 4943–4947
2024
-
[15]
SpeechAlign: Aligning speech generation to human preferences,
D. Zhang, Z. Li, S. Li, X. Zhang, P. Wang, Y . Zhou, and X. Qiu, “SpeechAlign: Aligning speech generation to human preferences,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024, pp. 50 343–50 360
2024
-
[16]
Emo-DPO: Controllable emotional speech synthesis through direct preference optimization,
X. Gao, C. Zhang, Y . Chen, H. Zhang, and N. F. Chen, “Emo-DPO: Controllable emotional speech synthesis through direct preference optimization,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[17]
SpeechJudge: Towards human-level judgment for speech naturalness,
X. Zhang, C. Wang, H. Liao, Z. Li, Y . Wang, L. Wang, D. Jia, Y . Chen, X. Li, Z. Chenet al., “SpeechJudge: Towards human-level judgment for speech naturalness,”arXiv preprint arXiv:2511.07931, 2025
-
[18]
WavReward: Spoken dia- logue models with generalist reward evaluators,
S. Ji, T. Liang, Y . Li, J. Zuo, M. Fang, J. He, Y . Chen, Z. Liu, Z. Jiang, X. Chenget al., “WavReward: Spoken dia- logue models with generalist reward evaluators,”arXiv preprint arXiv:2505.09558, 2025
-
[19]
AudioJudge: Understanding what works in large audio model based speech evaluation,
P. Manakul, W. H. Gan, M. J. Ryan, A. S. Khan, W. Sirichote- dumrong, K. Pipatanakul, W. Held, and D. Yang, “AudioJudge: Understanding what works in large audio model based speech evaluation,”arXiv preprint arXiv:2507.12705, 2025
-
[20]
SpeechLLM-as-Judges: Towards General and Interpretable Speech Quality Evaluation
H. Wang, J. Zhao, Y . Yang, S. Liu, J. Chen, Y . Zhang, S. Zhao, J. Li, J. Zhou, H. Sunet al., “SpeechLLM-as-Judges: Towards general and interpretable speech quality evaluation,”arXiv preprint arXiv:2510.14664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Read to hear: A zero-shot pronunciation assessment using textual descriptions and LLMs,
Y .-W. Chen, M. Ma, and J. Hirschberg, “Read to hear: A zero-shot pronunciation assessment using textual descriptions and LLMs,” in Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025, pp. 2682–2694
2025
-
[22]
VStyle: A benchmark for voice style adaptation with spoken instructions,
J. Zhan, M. Han, Y . Xie, C. Wang, D. Zhang, K. Huang, H. Shi, D. Wang, T. Song, Q. Chenget al., “VStyle: A benchmark for voice style adaptation with spoken instructions,”arXiv preprint arXiv:2509.09716, 2025
-
[23]
MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues,
G. Bai, J. Liu, X. Bu, Y . He, J. Liu, Z. Zhou, Z. Lin, W. Su, T. Ge, B. Zhenget al., “MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues,” in Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 7421–7454
2024
-
[24]
X. Wang, Z. Zhao, S. Ren, S. Zhang, S. Li, X. Li, Z. Wang, L. Qiu, G. Wan, X. Caoet al., “Audio Turing test: Benchmarking the human-likeness of large language model-based text-to-speech systems in Chinese,”arXiv preprint arXiv:2505.11200, 2025
-
[25]
NISQA: A deep CNN-self-attention model for multidimensional speech qual- ity prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A deep CNN-self-attention model for multidimensional speech qual- ity prediction with crowdsourced datasets,” inAnnual Conference of the International Speech Communication Association (INTER- SPEECH). ISCA, 2021, pp. 2127–2131
2021
-
[26]
SOMOS: The Samsung open MOS dataset for the evaluation of neural text- to-speech synthesis,
G. Maniati, A. Vioni, N. Ellinas, K. Nikitaras, K. Klapsas, J. S. Sung, G. Jho, A. Chalamandaris, and P. Tsiakoulis, “SOMOS: The Samsung open MOS dataset for the evaluation of neural text- to-speech synthesis,” inAnnual Conference of the International Speech Communication Association (INTERSPEECH). ISCA, 2022, pp. 2388–2392
2022
-
[27]
How do voices from past speech synthesis challenges compare today?
E. Cooper and J. Yamagishi, “How do voices from past speech synthesis challenges compare today?” inISCA Speech Synthesis Workshop (SSW), 2021, pp. 184–189
2021
-
[28]
WenetSpeech: A 10000+ hours multi- domain Mandarin corpus for speech recognition,
B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zenget al., “WenetSpeech: A 10000+ hours multi- domain Mandarin corpus for speech recognition,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6182–6186
2022
-
[29]
AISHELL-3: A multi-speaker Mandarin TTS corpus and the baselines,
Y . Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “AISHELL-3: A multi-speaker Mandarin TTS corpus and the baselines,” inAnnual Conference of the International Speech Communication Associa- tion (INTERSPEECH). ISCA, 2021, pp. 2756–2760
2021
-
[30]
Consistent and specific multi-view subspace clustering,
S. Luo, C. Zhang, W. Zhang, and X. Cao, “Consistent and specific multi-view subspace clustering,” inAAAI Conference on Artificial Intelligence (AAAI), 2018
2018
-
[31]
H. Liao, Q. Ni, Y . Wang, Y . Lu, H. Zhan, P. Xie, Q. Zhang, and Z. Wu, “NVSpeech: An integrated and scalable pipeline for human- like speech modeling with paralinguistic vocalizations,”arXiv preprint arXiv:2508.04195, 2025
-
[32]
Advanc- ing zero-shot text-to-speech intelligibility across diverse domains via preference alignment,
X. Zhang, Y . Wang, C. Wang, Z. Li, Z. Chen, and Z. Wu, “Advanc- ing zero-shot text-to-speech intelligibility across diverse domains via preference alignment,” inAnnual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 12 251–12 270
2025
-
[33]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabili- ties,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback,
W. Xu, D. Wang, L. Pan, Z. Song, M. Freitag, W. Wang, and L. Li, “INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback,” inConference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 5967–5994
2023
-
[35]
Y . Zhou, G. Zeng, X. Liu, X. Li, R. Yu, Z. Wang, R. Ye, W. Sun, J. Gui, K. Liet al., “V oxCPM: Tokenizer-free TTS for context- aware speech generation and true-to-life voice cloning,”arXiv preprint arXiv:2509.24650, 2025
-
[36]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “CosyV oice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Mimo-audio: Audio language models are few-shot learners,
D. Zhang, G. Wang, J. Xue, K. Fang, L. Zhao, R. Ma, S. Ren, S. Liu, T. Guo, W. Zhuanget al., “MiMo-Audio: Audio language models are few-shot learners,”arXiv preprint arXiv:2512.23808, 2025
-
[38]
Step-audio-r1 technical report,
F. Tian, X. T. Zhang, Y . Zhang, H. Zhang, Y . Li, D. Liu, Y . Deng, D. Wu, J. Chen, L. Zhaoet al., “Step-Audio-R1 technical report,” arXiv preprint arXiv:2511.15848, 2025
-
[39]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-Omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.