Recognition: unknown
ChangeQuery: Advancing Remote Sensing Change Analysis for Natural and Human-Induced Disasters from Visual Detection to Semantic Understanding
Pith reviewed 2026-05-08 12:37 UTC · model grok-4.3
The pith
ChangeQuery turns paired optical and radar satellite images into answers for detailed disaster damage queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
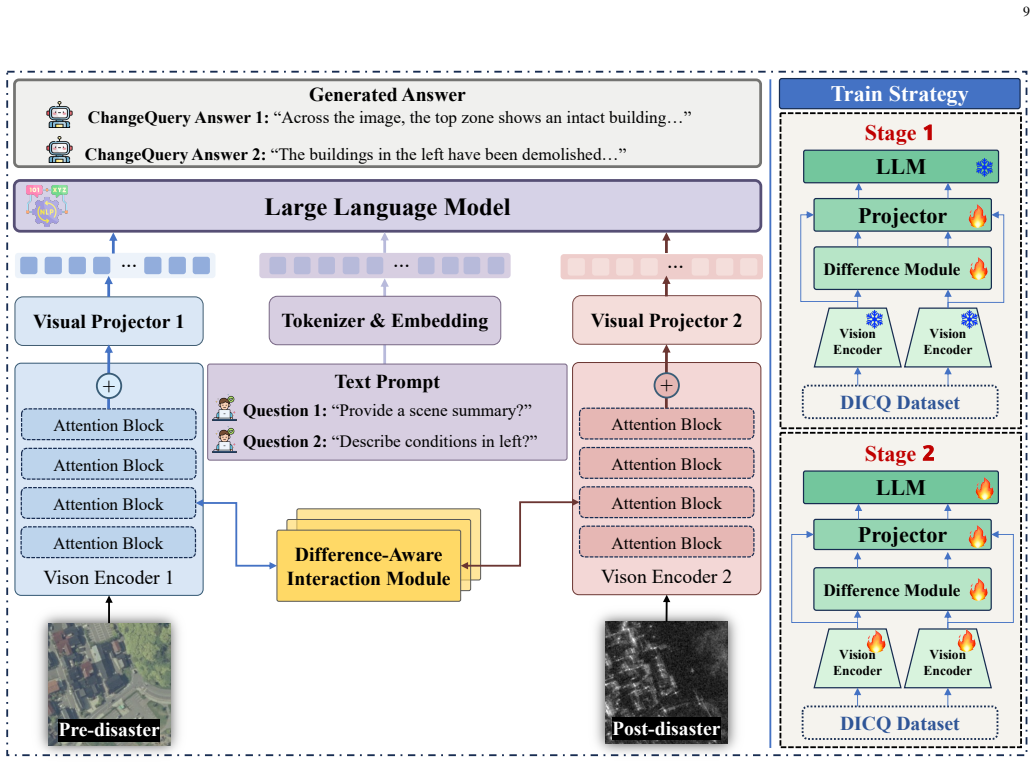
ChangeQuery is a unified multimodal framework that acts as an interactive disaster analyst, supporting multi-task reasoning from diverse user queries to produce precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. It is trained on the DICQ dataset that couples pre-event optical semantics with post-event SAR structural features across balanced natural catastrophes and armed conflicts, using an Automated Semantic Annotation Pipeline that follows a statistics-first, generation-later paradigm to create grounded hierarchical instruction sets from raw segmentation masks.
What carries the argument
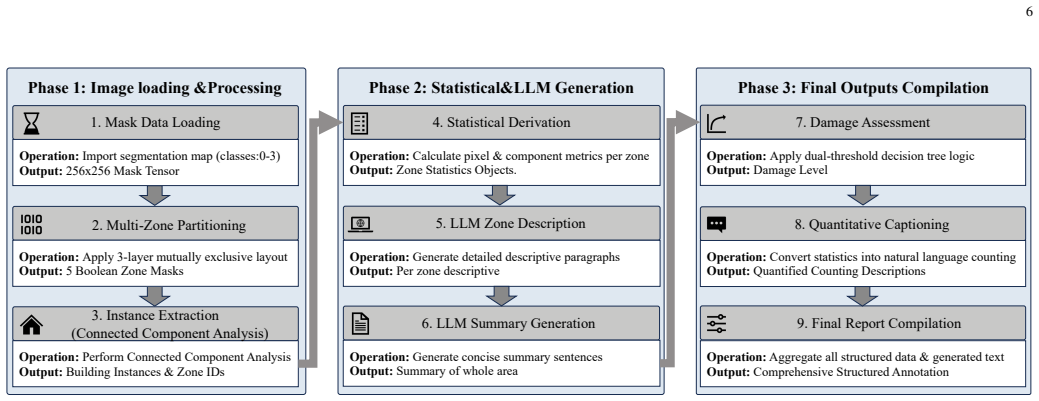
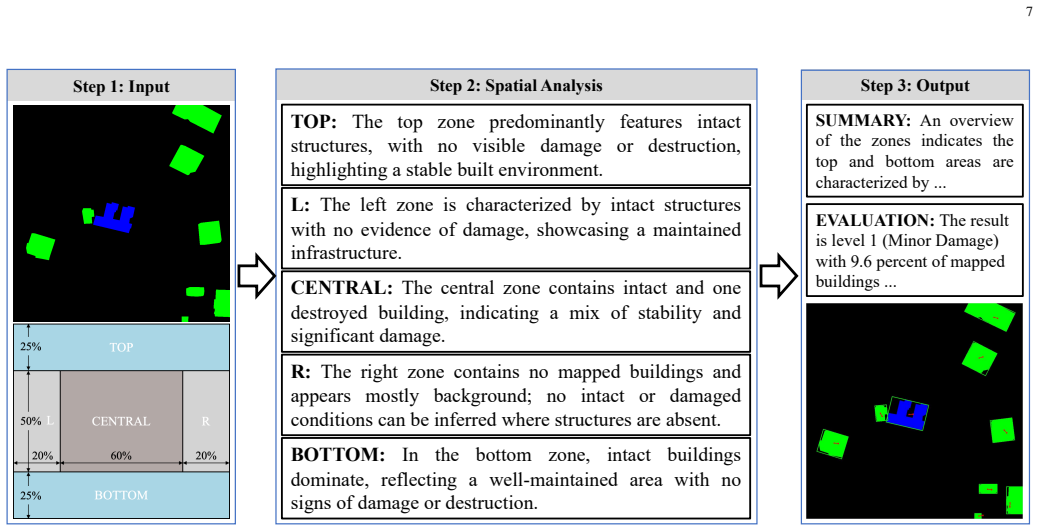
The Automated Semantic Annotation Pipeline, which transforms raw segmentation masks into grounded hierarchical instruction sets via a statistics-first paradigm to equip the model with fine-grained spatial and quantitative awareness for query-driven reasoning.
If this is right
- The system supports analysis under all weather conditions by incorporating SAR data for post-event structural information.
- It removes the prevailing bias toward natural disasters by including balanced data from armed conflicts.
- Outputs include both quantitative damage figures and textual summaries in response to varied user queries.
- The approach outperforms prior vision-language methods on strategic, high-level reasoning tasks in disaster monitoring.
Where Pith is reading between the lines
- The same statistics-first annotation method could be adapted to generate training data for query-based analysis in non-disaster remote sensing domains such as agriculture or urban change.
- Pairing the interactive model with incoming real-time satellite feeds might allow near-continuous updating of damage assessments during ongoing events.
- The balanced natural-and-conflict dataset structure suggests a template for constructing training resources in other multimodal domains where scenario bias is a known issue.
Load-bearing premise
The Automated Semantic Annotation Pipeline produces high-quality, unbiased hierarchical instruction sets that enable effective interactive reasoning without introducing artifacts from the statistics-first generation process.
What would settle it
A test set of real disaster events with expert-written answers to complex mixed queries, where the model's numerical damage estimates and textual descriptions are scored for accuracy against those expert answers.
Figures







read the original abstract
Rapid situational awareness is critical in post-disaster response. While remote sensing damage assessment is evolving from pixel-level change detection to high-level semantic analysis, existing vision-language methodologies still struggle to provide actionable intelligence for complex strategic queries. They remain severely constrained by unimodal optical dependence, a prevailing bias towards natural disasters, and a fundamental lack of grounded interactivity. To address these limitations, we present ChangeQuery, a unified multimodal framework designed for comprehensive, all-weather disaster situation awareness. To overcome modality constraints and scenario biases, we construct the Disaster-Induced Change Query (DICQ) dataset, a large-scale benchmark coupling pre-event optical semantics with post-event SAR structural features across a balanced distribution of natural catastrophes and armed conflicts. Furthermore, to provide the high-quality supervision required for interactive reasoning, we propose a novel Automated Semantic Annotation Pipeline. Adhering to a ``statistics-first, generation-later'' paradigm, this engine automatically transforms raw segmentation masks into grounded, hierarchical instruction sets, effectively equipping the model with fine-grained spatial and quantitative awareness. Trained on this structured data, the ChangeQuery architecture operates as an interactive disaster analyst. It supports multi-task reasoning driven by diverse user queries, delivering precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. Extensive experiments demonstrate that ChangeQuery establishes a new state-of-the-art, providing a robust and interpretable solution for complex disaster monitoring. The code is available at \href{https://sundongwei.github.io/changequery/}{https://sundongwei.github.io/changequery/}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChangeQuery, a multimodal vision-language framework for semantic disaster change analysis in remote sensing. It constructs the DICQ dataset pairing pre-event optical and post-event SAR imagery across natural disasters and armed conflicts, proposes an Automated Semantic Annotation Pipeline that converts segmentation masks into hierarchical instruction sets via a 'statistics-first, generation-later' approach, and trains an interactive model supporting multi-task queries for damage quantification and summaries. The abstract asserts that extensive experiments establish new state-of-the-art performance and robustness.
Significance. If the central claims hold, the work would meaningfully advance remote sensing change analysis from pixel-level detection toward grounded, query-driven semantic understanding, particularly by addressing all-weather SAR integration and human-induced disaster scenarios that are underrepresented in prior benchmarks. The public code release and emphasis on interactive reasoning represent concrete strengths that could support reproducibility and downstream applications in disaster response.
major comments (2)
- [Automated Semantic Annotation Pipeline description] The Automated Semantic Annotation Pipeline is load-bearing for all downstream claims (dataset quality, fine-grained spatial/quantitative awareness, and SOTA performance), yet the manuscript provides no quantitative validation of its output (e.g., human agreement rates, error analysis on hallucinated statistics, or ablation comparing pipeline variants to manual annotation).
- [Abstract and experimental claims] The abstract and architecture sections assert SOTA results and robustness across tasks without reporting any metrics, baselines, ablation studies, or error analysis; this prevents evaluation of whether the pipeline-induced supervision actually delivers the claimed precise damage quantification.
minor comments (2)
- [Dataset construction] Clarify the exact composition of the DICQ dataset (number of image pairs, class balance statistics, and train/val/test splits) to allow independent assessment of scenario coverage.
- [Pipeline description] The phrase 'statistics-first, generation-later' is used without a formal definition or pseudocode; adding a concise algorithmic outline would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of the Automated Semantic Annotation Pipeline and the experimental claims.
read point-by-point responses
-
Referee: [Automated Semantic Annotation Pipeline description] The Automated Semantic Annotation Pipeline is load-bearing for all downstream claims (dataset quality, fine-grained spatial/quantitative awareness, and SOTA performance), yet the manuscript provides no quantitative validation of its output (e.g., human agreement rates, error analysis on hallucinated statistics, or ablation comparing pipeline variants to manual annotation).
Authors: We agree that quantitative validation of the pipeline outputs is necessary to support the downstream claims. The current manuscript describes the pipeline design and its 'statistics-first, generation-later' approach but does not include human evaluation metrics. In the revised version we will add a new subsection reporting inter-annotator agreement rates (e.g., Cohen's kappa with expert remote-sensing analysts), error analysis on generated quantitative statistics, and an ablation comparing pipeline-generated instructions against fully manual annotations on a held-out subset of the DICQ dataset. revision: yes
-
Referee: [Abstract and experimental claims] The abstract and architecture sections assert SOTA results and robustness across tasks without reporting any metrics, baselines, ablation studies, or error analysis; this prevents evaluation of whether the pipeline-induced supervision actually delivers the claimed precise damage quantification.
Authors: The Experiments section (Section 4) already contains the full set of quantitative results, including task-specific metrics, baseline comparisons, ablation studies on the annotation pipeline, and error analysis for damage quantification. However, we acknowledge that the abstract and architecture descriptions do not explicitly reference these numbers. We will revise the abstract to include key performance figures and SOTA comparisons, and we will add explicit cross-references from the architecture section to the relevant experimental tables and figures to demonstrate how the pipeline supervision enables precise quantification. revision: yes
Circularity Check
No circularity in the derivation chain
full rationale
The paper introduces ChangeQuery as an empirical multimodal framework trained on a newly constructed DICQ dataset and supervised via an Automated Semantic Annotation Pipeline that follows a statistics-first paradigm to generate hierarchical instructions from segmentation masks. No equations, derivations, or first-principles claims are presented that could reduce to self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The SOTA assertions rest on training and experimental results rather than any closed logical loop, making the contribution self-contained as a data-driven engineering advance.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-event optical and post-event SAR imagery provide complementary structural and semantic information sufficient for comprehensive disaster analysis.
- ad hoc to paper The statistics-first automated pipeline generates grounded, hierarchical instruction sets that supply high-quality supervision for interactive reasoning.
Reference graph
Works this paper leans on
-
[1]
Review of big data and processing frameworks for disaster response applications,
G. Gid ´ofalvi, “Review of big data and processing frameworks for disaster response applications,”ISPRS Int. J. Geo-Inf., vol. 8, p. 387, 2019
2019
-
[2]
Moni- toring war destruction from space using machine learning,
H. Mueller, A. Groeger, J. Hersh, A. Matranga, and J. Serrat, “Moni- toring war destruction from space using machine learning,”Proc. Natl. Acad. Sci., vol. 118, no. 23, 2021
2021
-
[3]
Time-series satellite remote sensing reveals gradually increasing war damage in the gaza strip,
S. Holail, T. Saleh, X. Xiao, J. Xiao, G.-S. Xia, Z. Shao, M. Wang, J. Gong, and D. Li, “Time-series satellite remote sensing reveals gradually increasing war damage in the gaza strip,”Natl. Sci. Rev., vol. 11, no. 9, p. 304, 2024
2024
-
[4]
Integrating machine learning and remote sensing in disaster management: A decadal review of post-disaster building damage assessment,
S. Al Shafian and D. Hu, “Integrating machine learning and remote sensing in disaster management: A decadal review of post-disaster building damage assessment,”Buildings, vol. 14, no. 8, p. 2344, 2024
2024
-
[5]
M2cd: A unified multimodal framework for optical-sar change detection with mixture of experts and self-distillation,
Z. Liu, J. Zhang, W. Wang, and Y . Gu, “M2cd: A unified multimodal framework for optical-sar change detection with mixture of experts and self-distillation,”IEEE Geosci. Remote Sens. Lett., vol. 22, pp. 1–5, 2025
2025
-
[6]
Changemamba: Re- mote sensing change detection with spatiotemporal state space model,
H. Chen, J. Song, C. Han, J. Xia, and N. Yokoya, “Changemamba: Re- mote sensing change detection with spatiotemporal state space model,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–20, 2024
2024
-
[7]
Change detection on remote sensing images using dual-branch multilevel intertemporal network,
Y . Feng, J. Jiang, H. Xu, and J. Zheng, “Change detection on remote sensing images using dual-branch multilevel intertemporal network,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–15, 2023
2023
-
[8]
Adapting segment anything model for change detection in vhr remote sensing images,
L. Ding, K. Zhu, D. Peng, H. Tang, K. Yang, and L. Bruzzone, “Adapting segment anything model for change detection in vhr remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–11, 2024
2024
-
[9]
Change captioning: A new paradigm for multitemporal remote sensing image analysis,
G. Hoxha, S. Chouaf, F. Melgani, and Y . Smara, “Change captioning: A new paradigm for multitemporal remote sensing image analysis,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–14, 2022
2022
-
[10]
Changes to captions: An attentive network for remote sensing change captioning,
S. Chang and P. Ghamisi, “Changes to captions: An attentive network for remote sensing change captioning,”IEEE Trans. Image Process., vol. 32, pp. 6047–6060, 2023
2023
-
[11]
Remote sens- ing spatiotemporal vision–language models: A comprehensive survey,
C. Liu, J. Zhang, K. Chen, M. Wang, Z. Zou, and Z. Shi, “Remote sens- ing spatiotemporal vision–language models: A comprehensive survey,” IEEE Geosci. Remote Sens. Mag., pp. 2–42, 2025
2025
-
[12]
Remote sensing chatgpt: Solving remote sensing tasks with chatgpt and visual models,
H. Guo, X. Su, C. Wu, B. Du, L. Zhang, and D. Li, “Remote sensing chatgpt: Solving remote sensing tasks with chatgpt and visual models,” inIEEE Int. Geosci. Remote Sens. Symp., 2024, pp. 11 474–11 478
2024
-
[13]
Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,
X. Guo, J. Lao, B. Dang, Y . Zhang, L. Yu, L. Ru, L. Zhong, Z. Huang, K. Wu, D. Hu, H. He, J. Wang, J. Chen, M. Yang, Y . Zhang, and Y . Li, “Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,” inConf. Comput. Vis. Pattern Recognit., 2024, pp. 27 662–27 673
2024
-
[14]
Sam-6d: Segment anything model meets zero-shot 6d object pose estimation,
J. Lin, L. Liu, D. Lu, and K. Jia, “Sam-6d: Segment anything model meets zero-shot 6d object pose estimation,” inConf. Comput. Vis. Pattern Recognit., 2024, pp. 27 906–27 916
2024
-
[15]
Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing domain,
W. Zhang, M. Cai, T. Zhang, Y . Zhuang, and X. Mao, “Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing domain,”IEEE Trans. Geosci. Remote Sens., 2024
2024
-
[16]
Changeclip: Remote sensing change detection with multimodal vision-language representation learn- ing,
S. Dong, L. Wang, B. Du, and X. Meng, “Changeclip: Remote sensing change detection with multimodal vision-language representation learn- ing,”ISPRS J. Photogramm. Remote Sens., vol. 208, pp. 53–69, 2024. 13
2024
-
[17]
Building disaster damage assessment in satellite imagery with multi-temporal fusion,
E. Weber and H. Kan ´e, “Building disaster damage assessment in satellite imagery with multi-temporal fusion,”arXiv:2004.05525, 2020
-
[18]
Disasterm3: A remote sensing vision- language dataset for disaster damage assessment and response,
J. Wang, W. Xuan, H. Qi, Z. Liu, K. Liu, Y . Wu, H. Chen, J. Song, J. Xia, Z. Zheng, and N. Yokoya, “Disasterm3: A remote sensing vision- language dataset for disaster damage assessment and response,”Adv. Neural Inf. Process. Syst., 2025
2025
-
[19]
Deep learning-based damage mapping with insar coherence time series,
O. L. Stephenson, T. K ¨ohne, E. Zhan, B. E. Cahill, S.-H. Yun, Z. E. Ross, and M. Simons, “Deep learning-based damage mapping with insar coherence time series,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–17, 2022
2022
-
[20]
BRIGHT: a globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response,
H. Chen, J. Song, O. Dietrich, C. Broni-Bediako, W. Xuan, J. Wang, X. Shao, Y . Wei, J. Xia, C. Lan, K. Schindler, and N. Yokoya, “BRIGHT: a globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response,”Earth Syst. Sci. Data, vol. 17, no. 11, pp. 6217–6253, 2025
2025
-
[21]
Time series change vector analysis for semisupervised abrupt land cover change detection,
I. A. Listiani, M. Zanetti, and F. Bovolo, “Time series change vector analysis for semisupervised abrupt land cover change detection,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–15, 2025
2025
-
[22]
A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain,
F. Bovolo and L. Bruzzone, “A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain,” IEEE Trans. Geosci. Remote Sens., vol. 45, no. 1, pp. 218–236, 2007
2007
-
[23]
Fully convolutional siamese networks for change detection,
R. Caye Daudt, B. Le Saux, and A. Boulch, “Fully convolutional siamese networks for change detection,” inIEEE Int. Conf. Image Process., 2018, pp. 4063–4067
2018
-
[24]
A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images,
C. Zhang, P. Yue, D. Tapete, L. Jiang, B. Shangguan, L. Huang, and G. Liu, “A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images,”ISPRS J. Photogramm. Remote Sens., vol. 166, pp. 183–200, 2020
2020
-
[25]
Remote sensing image change detection with transformers,
H. Chen, Z. Qi, and Z. Shi, “Remote sensing image change detection with transformers,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–14, 2022
2022
-
[26]
A transformer-based siamese network for change detection,
W. G. C. Bandara and V . M. Patel, “A transformer-based siamese network for change detection,”arXiv:2201.01293, 2022
-
[27]
Infrared small target detection via joint low rankness and local smoothness prior,
P. Liu, J. Peng, H. Wang, D. Hong, and X. Cao, “Infrared small target detection via joint low rankness and local smoothness prior,”IEEE Trans. Geosci. Remote Sens., 2024
2024
-
[28]
Class-incremental learning for remote sensing scene classification via stable diffusion based data regeneration,
B. Zhang, X. Cao, S. Wang, and D. Meng, “Class-incremental learning for remote sensing scene classification via stable diffusion based data regeneration,”IEEE Trans. Geosci. Remote Sens., pp. 1–1, 2026
2026
-
[29]
Ctvnet: Gradient prior-guided deep unfolding network for infrared small target detection,
P. Liu, L. Pang, J. Peng, Y . Luo, J. Liu, and X. Cao, “Ctvnet: Gradient prior-guided deep unfolding network for infrared small target detection,” IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–14, 2025
2025
-
[30]
Earthquake damage as- sessment of buildings using vhr optical and sar imagery,
D. Brunner, G. Lemoine, and L. Bruzzone, “Earthquake damage as- sessment of buildings using vhr optical and sar imagery,”IEEE Trans. Geosci. Remote Sens., vol. 48, no. 5, pp. 2403–2420, 2010
2010
-
[31]
A conditional adversarial network for change detection in heterogeneous images,
X. Niu, M. Gong, T. Zhan, and Y . Yang, “A conditional adversarial network for change detection in heterogeneous images,”IEEE Geosci. Remote Sens. Lett., vol. 16, no. 1, pp. 45–49, 2019
2019
-
[32]
A deep translation (gan) based change detection network for optical and sar remote sensing images,
X. Li, Z. Du, Y . Huang, and Z. Tan, “A deep translation (gan) based change detection network for optical and sar remote sensing images,” ISPRS J. Photogramm. Remote Sens., vol. 179, pp. 14–34, 2021
2021
-
[33]
Structure consistency- based graph for unsupervised change detection with homogeneous and heterogeneous remote sensing images,
Y . Sun, L. Lei, X. Li, X. Tan, and G. Kuang, “Structure consistency- based graph for unsupervised change detection with homogeneous and heterogeneous remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–21, 2022
2022
-
[34]
Unsupervised multimodal change detection based on structural relationship graph representation learning,
H. Chen, N. Yokoya, C. Wu, and B. Du, “Unsupervised multimodal change detection based on structural relationship graph representation learning,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–18, 2022
2022
-
[35]
Learning from multimodal and multitemporal earth observation data for building damage mapping,
B. Adriano, N. Yokoya, J. Xia, H. Miura, W. Liu, M. Matsuoka, and S. Koshimura, “Learning from multimodal and multitemporal earth observation data for building damage mapping,”ISPRS J. Photogramm. Remote Sens., vol. 175, pp. 132–143, 2021
2021
-
[36]
Building damage mapping through heterogeneous feature consistency and knowledge integration,
X. Zeng and Y . Qu, “Building damage mapping through heterogeneous feature consistency and knowledge integration,” inIEEE Int. Geosci. Remote Sens. Symp., 2025, pp. 233–236
2025
-
[37]
Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man- made disasters,
Z. Zheng, Y . Zhong, J. Wang, A. Ma, and L. Zhang, “Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man- made disasters,”Remote Sens. Environ., vol. 265, p. 112636, 2021
2021
-
[38]
Dynamicearthnet: Daily multi-spectral satellite dataset for semantic change segmentation,
A. Toker, L. Kondmann, M. Weber, M. Eisenberger, A. Camero, J. Hu, A. P. Hoderlein, c. S ¸enaras, T. Davis, D. Cremers, G. Marchisio, X. X. Zhu, and L. Leal-Taix´e, “Dynamicearthnet: Daily multi-spectral satellite dataset for semantic change segmentation,” inIEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 21 158–21 167
2022
-
[39]
Exploring models and data for remote sensing image caption generation,
X. Lu, B. Wang, X. Zheng, and X. Li, “Exploring models and data for remote sensing image caption generation,”IEEE Trans. Geosci. Remote Sens., vol. 56, no. 4, pp. 2183–2195, 2018
2018
-
[40]
Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,
C. Liu, R. Zhao, H. Chen, Z. Zou, and Z. Shi, “Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–20, 2022
2022
-
[41]
Captioning changes in bi-temporal remote sensing images,
S. Chouaf, G. Hoxha, Y . Smara, and F. Melgani, “Captioning changes in bi-temporal remote sensing images,” inIEEE Int. Geosci. Remote Sens. Symp., 2021, pp. 2891–2894
2021
-
[42]
A lightweight sparse focus transformer for remote sensing image change captioning,
D. Sun, Y . Bao, J. Liu, and X. Cao, “A lightweight sparse focus transformer for remote sensing image change captioning,”IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 17, pp. 18 727–18 738, 2024
2024
-
[43]
Mask approximation net: A novel diffusion model approach for remote sensing change captioning,
D. Sun, J. Yao, W. Xue, C. Zhou, P. Ghamisi, and X. Cao, “Mask approximation net: A novel diffusion model approach for remote sensing change captioning,”IEEE Trans. Geosci. Remote Sens., 2025
2025
-
[44]
Scnet: Lightweight spatial-channel attention network for remote sensing change captioning,
D. Sun, Y . Wang, J. Yao, W. Yu, X. Cao, and P. Ghamisi, “Scnet: Lightweight spatial-channel attention network for remote sensing change captioning,”IEEE Trans. Geosci. Remote Sens., 2026
2026
-
[45]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdv. Neural Inf. Process. Syst., vol. 36, 2023, pp. 34 892–34 916
2023
-
[46]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,”arXiv:2304.10592, 2023
work page internal anchor Pith review arXiv 2023
-
[47]
Remoteclip: A vision language foundation model for remote sensing, 2024
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou, “Remoteclip: A vision language foundation model for remote sensing,” arXiv:2306.11029, 2024
-
[48]
Earthvqa: towards queryable earth via relational reasoning-based remote sensing visual question answering,
J. Wang, Z. Zheng, Z. Chen, A. Ma, and Y . Zhong, “Earthvqa: towards queryable earth via relational reasoning-based remote sensing visual question answering,”Proc. AAAI Conf. Artif. Intell., p. 609, 2024
2024
-
[49]
Rsgpt: A remote sensing vision language model and benchmark.ArXiv, abs/2307.15266, 2023
Y . Hu, J. Yuan, C. Wen, X. Lu, and X. Li, “Rsgpt: A remote sensing vision language model and benchmark,”arXiv:2307.15266, 2023
-
[50]
Spatiotemporal enhancement and interlevel fusion network for remote sensing images change detection,
Y . Huang, X. Li, Z. Du, and H. Shen, “Spatiotemporal enhancement and interlevel fusion network for remote sensing images change detection,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–14, 2024
2024
-
[51]
On the opportunities and challenges of foundation models for geospatial artificial intelligence,
G. Mai, W. Huang, J. Sun, S. Song, D. Mishra, N. Liu, S. Gao, T. Liu, G. Cong, Y . Hu, C. Cundy, Z. Li, R. Zhu, and N. Lao, “On the opportunities and challenges of foundation models for geospatial artificial intelligence,”arXiv:2304.06798, 2023
-
[52]
Rsvg: Exploring data and models for visual grounding on remote sensing data,
Y . Zhan, Z. Xiong, and Y . Yuan, “Rsvg: Exploring data and models for visual grounding on remote sensing data,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–13, 2023
2023
-
[53]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models,”arXiv:2407.07895, 2024
work page internal anchor Pith review arXiv 2024
-
[54]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, Y . Li, Z. Liu, and C. Li, “Llava-onevision: Easy visual task transfer,” arXiv:2408.03326, 2024
work page internal anchor Pith review arXiv 2024
-
[55]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shaoet al., “Internvl3: Exploring advanced training and test- time recipes for open-source multimodal models,”arXiv:2504.10479, 2025
work page internal anchor Pith review arXiv 2025
-
[56]
Z. Wang, M. Wang, S. Xu, Y . Li, and B. Zhang, “Ccexpert: Advancing mllm capability in remote sensing change captioning with difference- aware integration and a foundational dataset,”arXiv:2411.11360, 2024
-
[57]
Teochat: A large vision-language assistant for temporal earth observation data,
J. A. Irvin, E. R. Liu, J. C. Chen, I. Dormoy, J. Kim, S. Khanna, Z. Zheng, and S. Ermon, “Teochat: A large vision-language assistant for temporal earth observation data,” inInt. Conf. Learn. Represent., 2025
2025
-
[58]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Int. Conf. Learn. Represent., vol. 1, no. 2, p. 3, 2022
2022
-
[59]
ROUGE: A package for automatic evaluation of summaries,
C.-Y . Lin, “ROUGE: A package for automatic evaluation of summaries,” inText Summ. Branches Out, 2004, pp. 74–81
2004
-
[60]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments,
S. Banerjee and A. Lavie, “METEOR: An automatic metric for MT evaluation with improved correlation with human judgments,” inProc. ACL Workshop Intrins. Extrins. Eval. Meas. Mach. Transl. Summ., 2005, pp. 65–72
2005
-
[61]
Sentence-t5: Scalable sentence encoders from pre-trained text- to-text models,
J. Ni, G. Hernandez Abrego, N. Constant, J. Ma, K. Hall, D. Cer, and Y . Yang, “Sentence-t5: Scalable sentence encoders from pre-trained text- to-text models,” inFindings Assoc. Comput. Linguist., 2022, pp. 1864– 1874
2022
-
[62]
Rscc: A large-scale remote sensing change caption dataset for disaster events,
Z. Chen, C. Wang, N. Zhang, and F. Zhang, “Rscc: A large-scale remote sensing change caption dataset for disaster events,” inAdv. Neural Inf. Process. Syst., 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.