Recognition: unknown
Conformalized Super Learner
Pith reviewed 2026-05-08 10:04 UTC · model grok-4.3
The pith
The Super Learner ensemble produces prediction intervals with finite-sample coverage by weighting learner conformity scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mirroring the Super Learner weighting on learner-specific conformity scores and combining them via weighted majority vote, the resulting intervals achieve finite-sample coverage guarantees for continuous outcomes under exchangeability, potential violations, heteroscedasticity, sparsity, and other distributional heterogeneity.
What carries the argument
Weighted majority vote of learner-specific conformity scores that reuses the Super Learner's performance-based weights.
If this is right
- The intervals maintain valid finite-sample coverage under exchangeability and mild violations.
- Simulations show competitive performance relative to the true data-generating process.
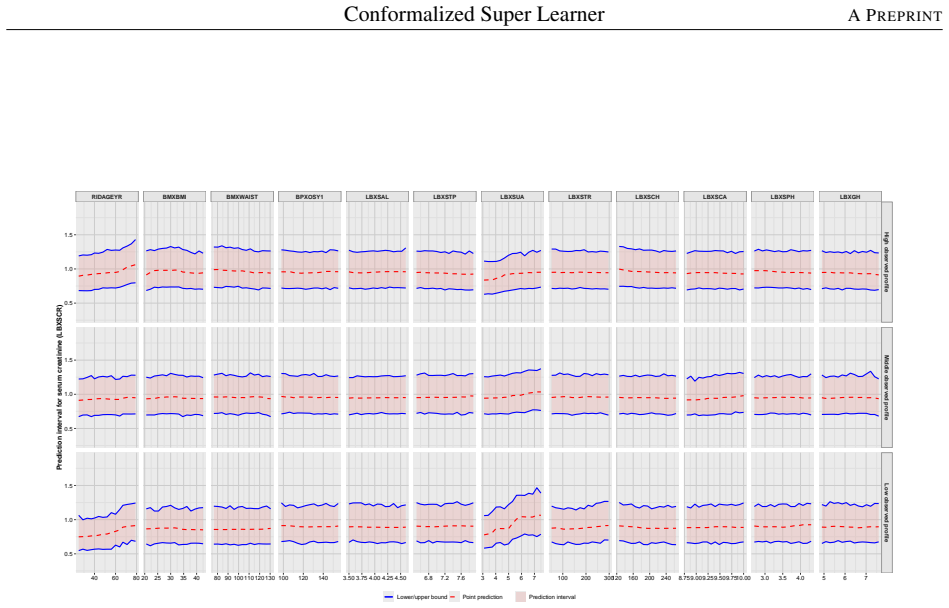
- The approach applies directly to regression tasks with non-linear effects, interactions, sparsity, heteroscedasticity, and outliers.
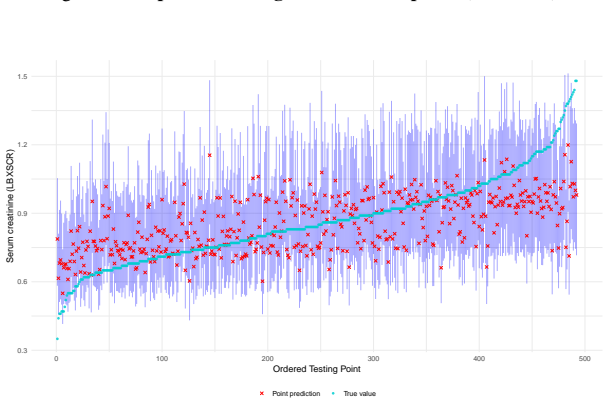
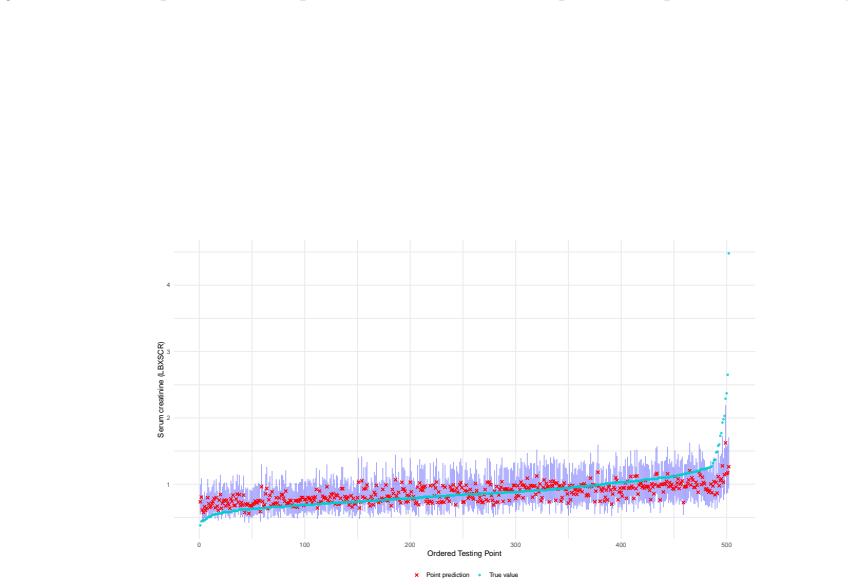
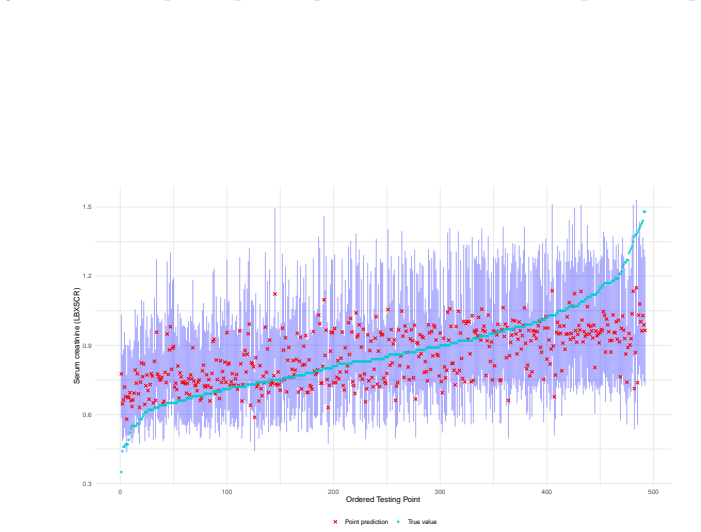
- It produces usable intervals in medical prediction settings such as creatinine level estimation.
Where Pith is reading between the lines
- The same weighting-plus-vote construction could be applied to other performance-weighted ensembles beyond the Super Learner.
- Extensions to dependent data structures would require only adjustments to the conformity score step.
- In high-stakes applications the method could reduce reliance on bootstrap or asymptotic interval methods.
Load-bearing premise
The data points satisfy exchangeability or the mild conditions that allow conformal prediction to guarantee coverage.
What would settle it
A dataset generated under exchangeability where the empirical coverage of the constructed intervals falls substantially below the nominal level.
Figures












read the original abstract
The Super Learner (SL) is a widely used ensemble method that combines predictions from a library of learners based on their predictive performance. Interval predictions are of considerable practical interest because they allow uncertainty in predictions produced by an individual learner or an ensemble to be quantified. Several methods have been proposed for constructing interval predictions based on the SL, however, these approaches are typically justified using asymptotic arguments or rely on computationally intensive procedures such as the bootstrap. Conformal prediction (CP) is a machine learning framework for constructing prediction intervals with finite-sample and asymptotic coverage guarantees under mild conditions. We propose coupling CP with the SL through a natural construction that mirrors the original SL framework, using individual learner weights and combining learner-specific conformity scores via a weighted majority vote. We characterize the properties of the resulting SL-based prediction intervals for continuous outcomes. We cover settings under exchangeability, potential violations of exchangeability, and data-generating mechanisms exhibiting heteroscedasticity, sparsity, and other forms of distributional heterogeneity. A comprehensive simulation study shows that the conformalized SL achieves valid finite-sample coverage with competitive performance relative to the true data-generating mechanism. A central contribution of this work is an application to predicting creatinine levels using socio-demographic, biometric, and laboratory measurements. This example demonstrates the benefits of an ensemble with carefully selected learners designed to capture key aspects of complex regression functions, including non-linear effects, interactions, sparsity, heteroscedasticity, and robustness to outliers.R
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes coupling conformal prediction with the Super Learner (SL) ensemble by constructing prediction intervals via a weighted majority vote on learner-specific conformity scores, where weights are the standard SL cross-validated weights. It characterizes the resulting intervals' properties for continuous outcomes under exchangeability, potential violations thereof, heteroscedasticity, sparsity, and heterogeneity. A simulation study reports valid finite-sample coverage and competitive performance, and the method is applied to creatinine level prediction using socio-demographic, biometric, and lab data.
Significance. If the finite-sample coverage claim holds after addressing the data-dependent weights, the work would provide a practical, distribution-free way to obtain valid intervals for a widely used ensemble method without relying on asymptotics or bootstrap. The simulation and real-data example illustrate utility for complex regression settings involving nonlinearity, interactions, and outliers.
major comments (1)
- [Theoretical characterization (properties under exchangeability)] The central finite-sample coverage claim under exchangeability rests on the weighted majority vote inheriting the uniform rank property of standard conformal scores. However, the SL weights are obtained via cross-validation on the training data (which overlaps with the points used to form conformity scores), breaking the symmetry required for the standard exchangeability argument. The characterization section must explicitly state the conditions (if any) under which coverage is preserved, or provide a modified proof that accounts for the dependence induced by the weights; without this, the guarantee does not transfer directly from individual learners.
minor comments (2)
- [Abstract] The abstract states that the method 'achieves valid finite-sample coverage' in simulations but does not clarify whether the theoretical characterization delivers unconditional finite-sample guarantees or only asymptotic or conditional results.
- [Simulation study] Simulation details on data exclusion rules, exact cross-validation scheme for SL weights, and how conformity scores are normalized across learners should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript on Conformalized Super Learner. The feedback highlights an important subtlety in the theoretical characterization, which we address point by point below. We will revise the manuscript to strengthen the presentation of the coverage guarantees.
read point-by-point responses
-
Referee: The central finite-sample coverage claim under exchangeability rests on the weighted majority vote inheriting the uniform rank property of standard conformal scores. However, the SL weights are obtained via cross-validation on the training data (which overlaps with the points used to form conformity scores), breaking the symmetry required for the standard exchangeability argument. The characterization section must explicitly state the conditions (if any) under which coverage is preserved, or provide a modified proof that accounts for the dependence induced by the weights; without this, the guarantee does not transfer directly from individual learners.
Authors: We agree that the data-dependent nature of the Super Learner weights, derived from cross-validation on the training set, requires explicit treatment to ensure the exchangeability argument is rigorous. The original characterization implicitly relies on the full dataset being exchangeable, which preserves symmetry for the weighted scores in the marginal sense, but we acknowledge that a direct transfer from unweighted conformal scores needs clarification. In the revised manuscript, we will update the theoretical section to explicitly state the conditions: the finite-sample coverage guarantee holds exactly when weights are computed on a hold-out set disjoint from the conformity score points, or approximately when using the full training data under exchangeability (with the dependence not affecting the uniform rank property due to permutation invariance of the CV procedure). We will include a brief proof sketch or reference to supporting arguments from the conformal prediction literature on data-dependent scores, along with a discussion of finite-sample robustness as evidenced by the simulations. revision: yes
Circularity Check
No significant circularity; coverage characterization is independent of fitted weights
full rationale
The paper defines a new aggregation of learner-specific conformity scores using SL weights (obtained via cross-validation) and claims to characterize finite-sample coverage under exchangeability for the resulting intervals. This characterization relies on standard conformal prediction rank-uniformity arguments applied to the aggregated nonconformity measure rather than redefining coverage in terms of the weights themselves. No equation reduces the coverage claim to a fitted quantity or prior self-citation; the construction is presented as a direct but non-tautological extension of existing CP and SL frameworks. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data points are exchangeable or satisfy mild conditions allowing conformal prediction to achieve finite-sample coverage.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2411.11824 , year=
A.N. Angelopoulos, R.F. Barber, and S. Bates. Theoretical foundations of conformal prediction.arXiv preprint arXiv:2411.11824,
-
[2]
M. Gasparin and A. Ramdas. Conformal online model aggregation.arXiv preprint arXiv:2403.15527, 2024a. M. Gasparin and A. Ramdas. Merging uncertainty sets via majority vote.arXiv preprint arXiv:2401.09379, 2024b. N. Gauraha and O. Spjuth. Synergy conformal prediction. InConformal and Probabilistic Prediction and Applications, pages 91–110. PMLR,
-
[3]
Department of Health and Human Ser- vices, Centers for Disease Control and Prevention, 2021-2023, https://wwwn.cdc.gov/nchs/nhanes/ continuousnhanes/default.aspx?Cycle=2021-2023
Hyattsville, MD: U.S. Department of Health and Human Ser- vices, Centers for Disease Control and Prevention, 2021-2023, https://wwwn.cdc.gov/nchs/nhanes/ continuousnhanes/default.aspx?Cycle=2021-2023. J. Neeven and E. Smirnov. Conformal stacked weather forecasting. InConformal and Probabilistic Prediction and Applications, pages 220–233. PMLR,
2021
- [4]
- [5]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.