Recognition: unknown
AgentSearchBench: A Benchmark for AI Agent Search in the Wild
Pith reviewed 2026-05-08 11:57 UTC · model grok-4.3
The pith
A benchmark of nearly 10,000 real AI agents shows semantic similarity fails to predict actual task performance, while lightweight execution signals improve ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
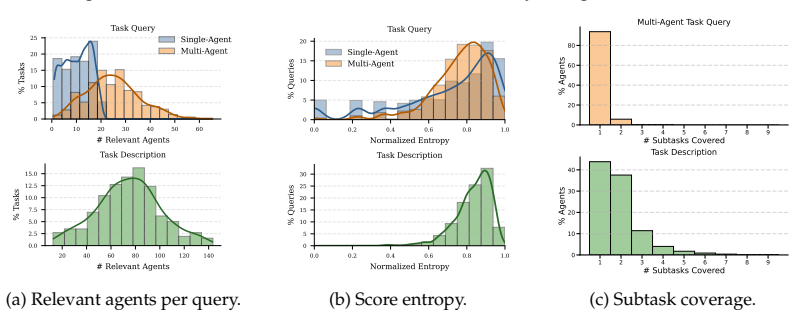
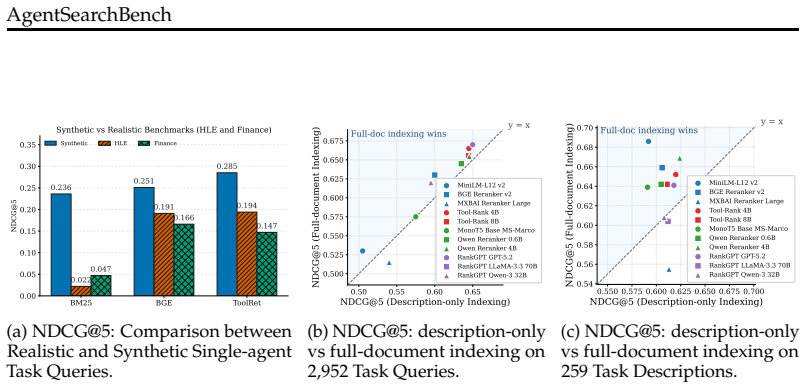
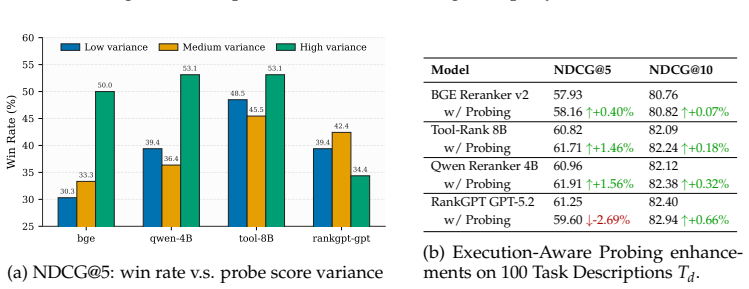
AgentSearchBench formalizes agent search as retrieval and reranking over nearly 10,000 real-world agents and shows that semantic-similarity methods produce rankings that diverge from execution-grounded performance, while lightweight behavioral signals including execution-aware probing substantially close that gap.
What carries the argument
Execution-grounded performance signals, obtained by running candidate agents on tasks, used both to label relevance and to train or guide reranking.
If this is right
- Description-only retrieval and reranking will systematically under-select agents that actually succeed on tasks.
- Lightweight execution probing can be added to existing search pipelines to raise ranking quality without heavy computation.
- Agent benchmarks and marketplaces should shift evaluation from textual similarity to measured execution outcomes.
- Search systems must treat agent capabilities as execution-dependent and compositional rather than static textual properties.
Where Pith is reading between the lines
- Platforms hosting many agents may need to expose lightweight execution interfaces to support better discovery.
- The same semantic-to-execution gap is likely to appear in tool selection or model routing, suggesting behavioral probing could generalize.
- Developers could build hybrid indexes that store both descriptions and compact behavioral profiles for faster, more accurate matching.
Load-bearing premise
The execution-grounded performance signals collected for the benchmark tasks accurately and fairly represent how suitable each agent would be across the full range of real-world tasks and providers.
What would settle it
A follow-up experiment that applies the same retrieval and probing methods to a fresh, unseen set of agents and tasks and finds that semantic-only rankings suddenly match or exceed the performance of execution-signal rankings.
Figures



read the original abstract
The rapid growth of AI agent ecosystems is transforming how complex tasks are delegated and executed, creating a new challenge of identifying suitable agents for a given task. Unlike traditional tools, agent capabilities are often compositional and execution-dependent, making them difficult to assess from textual descriptions alone. However, existing research and benchmarks typically assume well-specified functionalities, controlled candidate pools, or only executable task queries, leaving realistic agent search scenarios insufficiently studied. We introduce AgentSearchBench, a large-scale benchmark for agent search in the wild, built from nearly 10,000 real-world agents across multiple providers. The benchmark formalizes agent search as retrieval and reranking problems under both executable task queries and high-level task descriptions, and evaluates relevance using execution-grounded performance signals. Experiments reveal a consistent gap between semantic similarity and actual agent performance, exposing the limitations of description-based retrieval and reranking methods. We further show that lightweight behavioral signals, including execution-aware probing, can substantially improve ranking quality, highlighting the importance of incorporating execution signals into agent discovery. Our code is available at https://github.com/Bingo-W/AgentSearchBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentSearchBench, a benchmark built from nearly 10,000 real-world agents across providers. It formalizes agent search as retrieval and reranking under both high-level task descriptions and executable queries, with relevance labels derived from execution-grounded performance signals. Experiments demonstrate a consistent gap between semantic similarity and actual performance, plus substantial ranking gains from lightweight behavioral signals including execution-aware probing; code is released publicly.
Significance. If the execution-grounded labels prove reliable, the work is significant for exposing limitations of description-only retrieval in realistic agent ecosystems and for showing that simple behavioral probes can improve discovery. The scale, use of public real-world agents, and code release are strengths that support reproducibility and follow-on research in agent marketplaces.
major comments (2)
- [§4] §4 (Benchmark Construction and Evaluation Protocol): The manuscript provides insufficient detail on the execution protocol used to generate performance signals, including the number of trials per agent-task pair, handling of non-determinism, task difficulty calibration across providers, and attribution of execution failures. These factors are load-bearing for the central claim of a semantic-performance gap, as noisy or biased labels could artifactually inflate the reported discrepancy.
- [§5] §5 (Experiments): The improvements attributed to behavioral signals over semantic baselines are presented without reported variance, statistical significance tests, or breakdown by task/provider, making it unclear whether the gains are robust or concentrated in particular subsets; this weakens the claim that such signals 'substantially improve ranking quality.'
minor comments (2)
- [§1] The abstract and introduction use the term 'lightweight behavioral signals' without an early, precise definition or example; moving a short illustrative example to §1 would improve readability.
- [Figures] Figure captions and axis labels in the results figures could more explicitly indicate the exact metrics (e.g., nDCG@10 vs. precision) and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address the major comments point by point below and plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Benchmark Construction and Evaluation Protocol): The manuscript provides insufficient detail on the execution protocol used to generate performance signals, including the number of trials per agent-task pair, handling of non-determinism, task difficulty calibration across providers, and attribution of execution failures. These factors are load-bearing for the central claim of a semantic-performance gap, as noisy or biased labels could artifactually inflate the reported discrepancy.
Authors: We appreciate the referee's point that detailed execution protocols are essential for validating the performance signals and the observed semantic-performance gap. Section 4 of the manuscript outlines the benchmark construction process, including the derivation of relevance labels from execution results. However, we acknowledge that more granular information on trial counts, non-determinism mitigation, calibration, and failure attribution would enhance clarity and reproducibility. In the revised version, we will expand this section with these specifics, drawing from the implementation details in our released code. revision: yes
-
Referee: [§5] §5 (Experiments): The improvements attributed to behavioral signals over semantic baselines are presented without reported variance, statistical significance tests, or breakdown by task/provider, making it unclear whether the gains are robust or concentrated in particular subsets; this weakens the claim that such signals 'substantially improve ranking quality.'
Authors: We agree that including measures of variance, statistical tests, and subgroup analyses would provide stronger evidence for the robustness of the improvements from behavioral signals. The experiments in Section 5 demonstrate consistent gains across the benchmark, but we will revise to report standard deviations or confidence intervals, conduct appropriate significance tests (e.g., paired t-tests or Wilcoxon tests), and include breakdowns by task categories and agent providers to address this concern. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent ground truth
full rationale
The paper introduces AgentSearchBench as a collection of ~10,000 real-world agents evaluated via execution-grounded performance signals collected independently of the semantic similarity baselines. Retrieval/reranking methods are compared against these external signals rather than deriving performance from fitted parameters or self-referential definitions. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central claims to the inputs by construction. The reported gap and improvements from behavioral signals are direct empirical measurements, not forced by the evaluation protocol itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
URLhttps://doi.org/10.18653/v1/2024.findings-acl.137. Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Jimmy Lin. Ms marco: Benchmarking ranking models in the large-data regime. InProceedings of the 44th in- ternational ACM SIGIR conference on research and development in information retrieval, pp. 1566–1576, 2021. Nick Craswell, Bhaskar Mitr...
-
[3]
URLhttps://arxiv.org/abs/2109.10086. Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. Magentic-one: A generalist multi-agen...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[4]
Tool learning with foundation models,
URLhttps://openreview.net/forum?id=dHng2O0Jjr. Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi R. Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu,...
-
[5]
URLhttps://openreview.net/forum?id=mPdmDYIQ7f. Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Aishwarya Balwani, Sumana Basu, Denis Peskoff, Clinton Wang, Marcos Ayestaran, Sean M. Hendryx, Brad Kenstler, and Bing Liu. Re- searchrubrics: A benchmark of prompts and rubrics for deep resea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.