Recognition: 2 theorem links
· Lean TheoremRedParrot: Accelerating NL-to-DSL for Business Analytics via Query Semantic Caching
Pith reviewed 2026-05-15 15:13 UTC · model grok-4.3
The pith
RedParrot accelerates NL-to-DSL conversion by matching new queries against cached structural skeletons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RedParrot accelerates NL-to-DSL inference via a semantic cache of query skeletons. These skeletons are normalized structural patterns paired with their DSL outputs. An offline stage builds the cache; an online entity-agnostic embedding model trained by contrastive learning performs robust matching; and a heterogeneous RAG component supplies knowledge to adapt skeletons when new entities appear. The cache bypasses the costly multi-stage pipeline for matching requests.
What carries the argument
Semantic cache of query skeletons, matched by an entity-agnostic contrastive embedding model and adapted via heterogeneous RAG.
If this is right
- Real-time analytics dashboards can serve more concurrent users without added hardware.
- Error rates drop because fewer LLM calls reduce opportunities for compounding mistakes.
- The same skeleton cache works across both internal enterprise logs and public text-to-SQL benchmarks.
- Accuracy improves even on queries that require adaptation rather than exact reuse.
Where Pith is reading between the lines
- The skeleton approach could extend to other NL-to-code settings where queries share repeated control structures.
- Periodic cache refresh strategies would be needed if query patterns drift over time.
- Combining the cache with fine-tuned small models for adaptation might further reduce reliance on large LLMs.
Load-bearing premise
User queries in business analytics repeat often enough and follow stable structural patterns so that cached skeletons cover most new requests.
What would settle it
A test set of queries whose structures match none of the cached skeletons, where measured latency and accuracy gains disappear.
Figures







read the original abstract
Recently, at Xiaohongshu, the rapid expansion of e-commerce and advertising demands real-time business analytics with high accuracy and low latency. To meet this demand, systems typically rely on converting natural language (NL) queries into Domain-Specific Languages (DSLs) to ensure semantic consistency, validation, and portability. However, existing multi-stage LLM pipelines for this NL-to-DSL task suffer from prohibitive latency, high cost, and error propagation, rendering them unsuitable for enterprise-scale deployment. In this paper, we propose RedParrot, a novel NL-to-DSL framework that accelerates inference via a semantic cache. Observing the high repetition and stable structural patterns in user queries, RedParrot bypasses the costly pipeline by matching new requests against cached "query skeletons" (normalized structural patterns) and adapting their corresponding DSLs. Our core technical contributions include (1) an offline skeleton construction strategy, (2) an online, entity-agnostic embedding model trained via contrastive learning for robust matching, and (3) a heterogeneous Retrieval-Augmented Generation (RAG) method that integrates diverse knowledge sources to handle unseen entities. Experiments on six real enterprise datasets from Xiaohongshu show RedParrot achieves an average 3.6x speedup and an 8.26% accuracy improvement. Furthermore, on new public benchmarks adapted from Spider and BIRD, it boosts accuracy by 34.8%, substantially outperforming standard in-context learning baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RedParrot, a framework for accelerating NL-to-DSL conversion in business analytics via semantic caching of normalized query skeletons. It uses offline skeleton construction, contrastive learning to train an entity-agnostic embedding model for matching, and heterogeneous RAG to handle unseen entities. On six real enterprise datasets from Xiaohongshu, it reports an average 3.6x speedup and 8.26% accuracy improvement; on adapted Spider and BIRD benchmarks, it claims a 34.8% accuracy boost over standard in-context learning baselines.
Significance. If the performance claims are substantiated, RedParrot provides a practical method for reducing latency and cost in production NL-to-DSL pipelines where queries exhibit repetition. The offline skeleton construction combined with contrastive embeddings and RAG offers a concrete engineering contribution that could be adopted in enterprise analytics systems. The public-benchmark results, if reproducible, would strengthen the case for broader applicability beyond proprietary e-commerce data.
major comments (2)
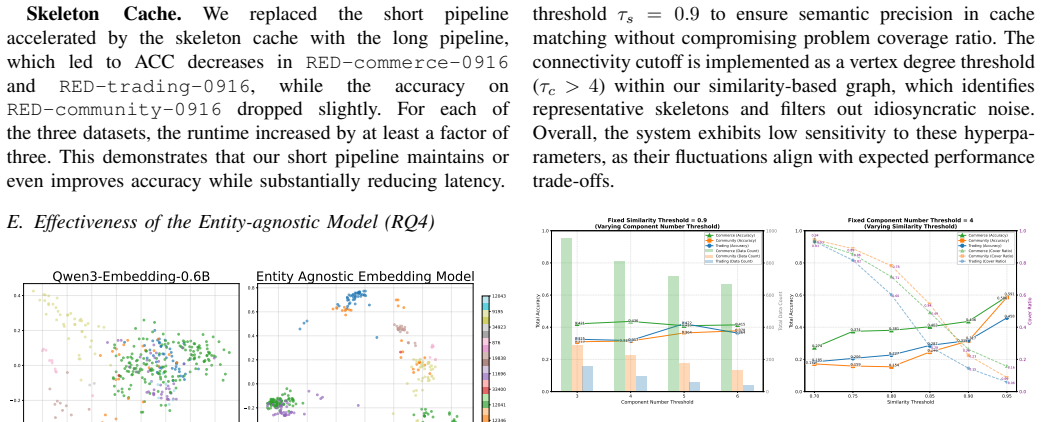
- [Abstract and Experiments] Abstract and Experiments section: the reported 3.6x speedup and accuracy gains are presented without any cache hit rates, breakdown of exact vs. semantic matches, false-positive rates of the contrastive embedding, or latency distribution when RAG fallback is invoked. These statistics are load-bearing for the central claim that semantic caching generalizes beyond high-frequency exact repeats.
- [Experiments] Experiments section: the evaluation lacks details on baseline implementations (e.g., exact prompting strategies for in-context learning), statistical significance tests, error bars, or precise train/test splits on both the Xiaohongshu and adapted Spider/BIRD datasets, making the 8.26% and 34.8% accuracy improvements difficult to verify.
minor comments (2)
- [Introduction] Introduction: the definition of 'query skeletons' as normalized structural patterns is introduced informally; a short formal definition or illustrative example early in the paper would improve clarity.
- [Method] The paper should explicitly state the training objective and negative sampling strategy for the contrastive embedding model to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the reported 3.6x speedup and accuracy gains are presented without any cache hit rates, breakdown of exact vs. semantic matches, false-positive rates of the contrastive embedding, or latency distribution when RAG fallback is invoked. These statistics are load-bearing for the central claim that semantic caching generalizes beyond high-frequency exact repeats.
Authors: We agree that these metrics are essential to substantiate the generalization claims. In the revised version, we will add a dedicated analysis subsection reporting cache hit rates (exact and semantic), false-positive rates of the contrastive embedding, and latency distributions broken down by RAG fallback invocations. This will clarify the contribution of semantic caching beyond exact repeats. revision: yes
-
Referee: [Experiments] Experiments section: the evaluation lacks details on baseline implementations (e.g., exact prompting strategies for in-context learning), statistical significance tests, error bars, or precise train/test splits on both the Xiaohongshu and adapted Spider/BIRD datasets, making the 8.26% and 34.8% accuracy improvements difficult to verify.
Authors: We acknowledge the need for greater experimental transparency. The revised manuscript will include: (1) exact prompting templates and hyperparameters for all in-context learning baselines, (2) results of statistical significance tests (e.g., paired t-tests) with p-values, (3) error bars on all reported metrics, and (4) precise train/test split ratios and dataset construction details for both the Xiaohongshu enterprise data and the adapted Spider/BIRD benchmarks. revision: yes
Circularity Check
No circularity: purely empirical system evaluation
full rationale
The paper describes a caching-based NL-to-DSL framework and reports measured speedups and accuracy gains on external enterprise and public benchmark datasets. No equations, derivations, or self-referential definitions are present that would reduce the reported performance numbers to fitted parameters or prior self-citations. The core claims rest on experimental outcomes rather than any closed-form reduction to the input assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User queries exhibit high repetition and stable structural patterns
invented entities (1)
-
query skeletons
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Observing the high repetition and stable structural patterns in user queries, RedParrot bypasses the costly pipeline by matching new requests against cached 'query skeletons' (normalized structural patterns) and adapting their corresponding DSLs.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
an online, entity-agnostic embedding model trained via contrastive learning for robust matching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chat2query: A zero-shot automatic exploratory data analysis system with large language models,
J.-P. Zhu, P. Cai, B. Niu, Z. Ni, K. Xu, J. Huang, J. Wan, S. Ma, B. Wang, D. Zhanget al., “Chat2query: A zero-shot automatic exploratory data analysis system with large language models,” in2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 5429–5432
work page 2024
-
[2]
Datalab: A unified platform for llm-powered business intelligence,
L. Weng, Y . Tang, Y . Feng, Z. Chang, R. Chen, H. Feng, C. Hou, D. Huang, Y . Li, H. Raoet al., “Datalab: A unified platform for llm-powered business intelligence,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 4346–4359
work page 2025
-
[3]
Tablecopilot: A table assistant empowered by natural language conditional table discovery,
L. Cui, G. Jiang, H. Li, K. Chen, L. Shou, and G. Chen, “Tablecopilot: A table assistant empowered by natural language conditional table discovery,”arXiv preprint arXiv:2507.08283, 2025
-
[4]
Cogsql: A cognitive framework for enhancing large language models in text- to-sql translation,
H. Yuan, X. Tang, K. Chen, L. Shou, G. Chen, and H. Li, “Cogsql: A cognitive framework for enhancing large language models in text- to-sql translation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 778–25 786
work page 2025
-
[5]
Text- to-sql empowered by large language models: A benchmark evaluation,
D. Gao, H. Wang, Y . Li, X. Sun, Y . Qian, B. Ding, and J. Zhou, “Text- to-sql empowered by large language models: A benchmark evaluation,” Proceedings of the VLDB Endowment, vol. 17, no. 5, pp. 1132–1145, 2024
work page 2024
-
[6]
Large language model based long-tail query rewriting in taobao search,
W. Peng, G. Li, Y . Jiang, Z. Wang, D. Ou, X. Zeng, D. Xu, T. Xu, and E. Chen, “Large language model based long-tail query rewriting in taobao search,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 20–28
work page 2024
-
[7]
Pneuma: Leveraging llms for tabular data representation and retrieval in an end-to-end system,
M. I. L. Balaka, D. Alexander, Q. Wang, Y . Gong, A. Krisnadhi, and R. Castro Fernandez, “Pneuma: Leveraging llms for tabular data representation and retrieval in an end-to-end system,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–28, 2025
work page 2025
-
[8]
Kcmf: A knowledge-compliant framework for schema and entity matching with fine-tuning-free llms,
Y . Xu, H. Li, K. Chen, and L. Shou, “Kcmf: A knowledge-compliant framework for schema and entity matching with fine-tuning-free llms,” arXiv preprint arXiv:2410.12480, 2024
-
[9]
Solo: Data discovery using natural language questions via a self-supervised approach,
Q. Wang and R. Castro Fernandez, “Solo: Data discovery using natural language questions via a self-supervised approach,”Proceedings of the ACM on Management of Data, vol. 1, no. 4, pp. 1–27, 2023
work page 2023
-
[10]
Y . Hu, J. Wang, and S. Rahman, “Lakevisage: Towards scalable, flexible and interactive visualization recommendation for data discovery over data lakes,”arXiv preprint arXiv:2504.02150, 2025
-
[11]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[12]
T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Romanet al., “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 3911–3921
work page 2018
-
[13]
J. Li, B. Hui, G. Qu, J. Yang, B. Li, B. Li, B. Wang, B. Qin, R. Geng, N. Huoet al., “Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls,”Advances in Neural Information Processing Systems, vol. 36, pp. 42 330–42 357, 2023
work page 2023
-
[14]
Realtime data processing at facebook,
G. J. Chen, J. L. Wiener, S. Iyer, A. Jaiswal, R. Lei, N. Simha, W. Wang, K. Wilfong, T. Williamson, and S. Yilmaz, “Realtime data processing at facebook,” inProceedings of the 2016 International Conference on Management of Data, 2016, pp. 1087–1098
work page 2016
-
[15]
Mesa: A geo-replicated online data warehouse for google’s advertising system,
A. Gupta, F. Yang, J. Govig, A. Kirsch, K. Chan, K. Lai, S. Wu, S. Dhoot, A. R. Kumar, A. Agiwalet al., “Mesa: A geo-replicated online data warehouse for google’s advertising system,”Communications of the ACM, vol. 59, no. 7, pp. 117–125, 2016
work page 2016
-
[16]
E. Begoli, J. Camacho-Rodr ´ıguez, J. Hyde, M. J. Mior, and D. Lemire, “Apache calcite: A foundational framework for optimized query pro- cessing over heterogeneous data sources,” inProceedings of the 2018 International Conference on Management of Data, 2018, pp. 221–230
work page 2018
-
[17]
From sketching to natural language: Expressive visual querying for accelerating insight,
T. Siddiqui, P. Luh, Z. Wang, K. Karahalios, and A. G. Parameswaran, “From sketching to natural language: Expressive visual querying for accelerating insight,”ACM SIGMOD Record, vol. 50, no. 1, pp. 51–58, 2021
work page 2021
-
[18]
The probabilistic relevance frame- work: Bm25 and beyond,
S. Robertson, H. Zaragozaet al., “The probabilistic relevance frame- work: Bm25 and beyond,”Foundations and Trends® in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009
work page 2009
-
[19]
A vector space search engine for web services,
C. Platzer and S. Dustdar, “A vector space search engine for web services,” inThird European Conference on Web Services (ECOWS’05). IEEE, 2005, pp. 9–pp
work page 2005
-
[20]
Available: https://github.com/hankcs/HanLP
“Hanlp.” [Online]. Available: https://github.com/hankcs/HanLP
-
[21]
The k-means algorithm: A comprehensive survey and performance evaluation,
M. Ahmed, R. Seraj, and S. M. S. Islam, “The k-means algorithm: A comprehensive survey and performance evaluation,”Electronics, vol. 9, no. 8, p. 1295, 2020
work page 2020
-
[22]
Supervised contrastive learn- ing,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learn- ing,”Advances in neural information processing systems, vol. 33, pp. 18 661–18 673, 2020
work page 2020
-
[23]
Learning metadata-agnostic rep- resentations for text-to-sql in-context example selection,
C. Mai, R.-e. Tal, and T. Mohamed, “Learning metadata-agnostic rep- resentations for text-to-sql in-context example selection,”arXiv preprint arXiv:2410.14049, 2024
-
[24]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Available: https://huggingface.co/Amu/tao-8k
“tao-8k.” [Online]. Available: https://huggingface.co/Amu/tao-8k
-
[27]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Linet al., “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
work page 2023
-
[29]
Tablegpt2: A large multimodal model with tabular data integration,
A. Su, A. Wang, C. Ye, C. Zhou, G. Zhang, G. Chen, G. Zhu, H. Wang, H. Xu, H. Chenet al., “Tablegpt2: A large multimodal model with tabular data integration,”arXiv preprint arXiv:2411.02059, 2024
-
[30]
Grammar prompting for domain-specific language generation with large language models,
B. Wang, Z. Wang, X. Wang, Y . Cao, R. A Saurous, and Y . Kim, “Grammar prompting for domain-specific language generation with large language models,”Advances in Neural Information Processing Systems, vol. 36, pp. 65 030–65 055, 2023
work page 2023
-
[31]
A survey of nl2sql with large language models: Where are we, and where are we going?
X. Liu, S. Shen, B. Li, P. Ma, R. Jiang, Y . Zhang, J. Fan, G. Li, N. Tang, and Y . Luo, “A survey of nl2sql with large language models: Where are we, and where are we going?”arXiv preprint arXiv:2408.05109, 2024
-
[32]
Viseval: A benchmark for data visualization in the era of large language models,
N. Chen, Y . Zhang, J. Xu, K. Ren, and Y . Yang, “Viseval: A benchmark for data visualization in the era of large language models,”IEEE Transactions on Visualization and Computer Graphics, 2024
work page 2024
-
[33]
Chat2data: An interactive data analysis system with rag, vector databases and llms,
X. Zhao, X. Zhou, and G. Li, “Chat2data: An interactive data analysis system with rag, vector databases and llms,”Proceedings of the VLDB Endowment, vol. 17, no. 12, pp. 4481–4484, 2024
work page 2024
-
[34]
Chatbi: Towards natural language to complex business intelligence sql,
J. Lian, X. Liu, Y . Shao, Y . Dong, M. Wang, Z. Wei, T. Wan, M. Dong, and H. Yan, “Chatbi: Towards natural language to complex business intelligence sql,”arXiv preprint arXiv:2405.00527, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.