Recognition: 2 theorem links
· Lean TheoremQuantifying Divergence in Inter-LLM Communication Through API Retrieval and Ranking
Pith reviewed 2026-05-15 12:56 UTC · model grok-4.3
The pith
LLMs show moderate agreement on API selection overall but diverge sharply on open-ended tasks compared to structured ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
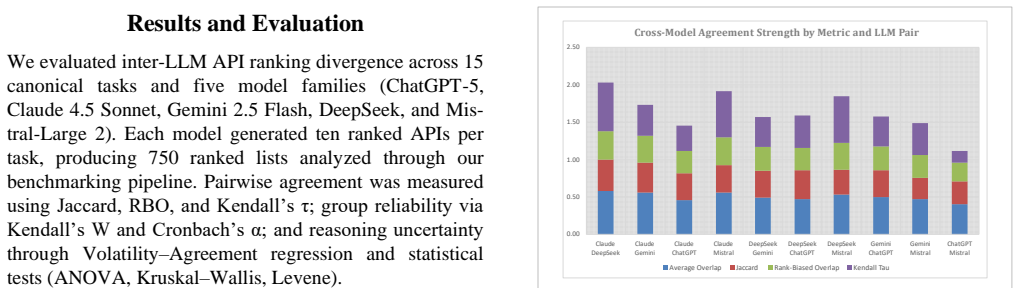
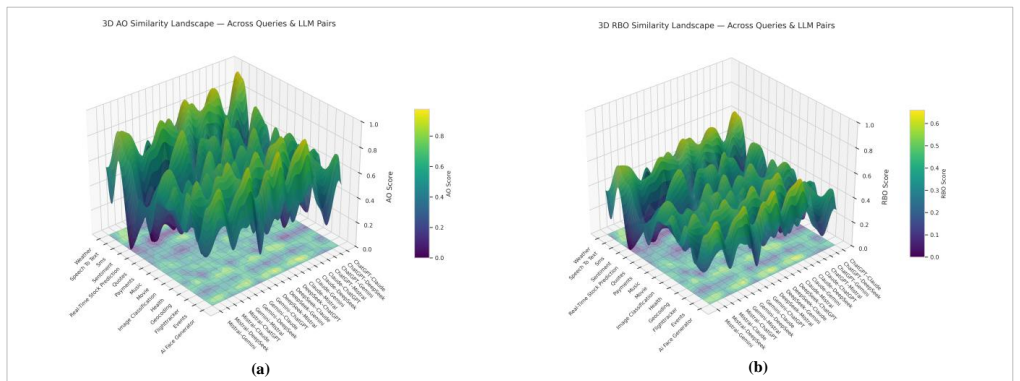
Inter-LLM divergence in API retrieval and ranking is moderate on average but strongly domain-dependent, with structured tasks producing stable rankings across models and open-ended tasks producing higher volatility, as shown by set, rank, and consensus metrics applied to fifteen domains and five model families.
What carries the argument
Unified benchmarking framework that quantifies inter-LLM divergence via set-based, rank-based, and consensus metrics applied to API discovery and ranking outputs.
If this is right
- Consensus weighting can be used to improve coordination reliability among heterogeneous LLMs in multi-agent setups.
- Structured tasks support more stable orchestration while open-ended tasks require extra safeguards against ranking instability.
- Apparent agreement across models can conceal systematic instability in the specific APIs chosen for a task.
- Diagnostic benchmarks of this form can detect coordination risks before multi-agent systems are deployed.
Where Pith is reading between the lines
- In real deployments, this divergence could cause inconsistent agent behavior when models independently select APIs for the same user goal.
- The pattern implies that model selection for agent teams should be domain-aware rather than uniform across all tasks.
- Extending the same metrics to larger or newer model families could test whether divergence grows or shrinks with scale.
Load-bearing premise
The fifteen chosen API domains and five model families are representative enough that the observed domain dependence will hold more generally, and the chosen metrics capture disagreement that matters for real actions rather than superficial ranking differences.
What would settle it
A new experiment on a fresh collection of domains or model families that finds roughly equal divergence levels across structured and open-ended tasks would falsify the domain-dependence claim.
Figures

read the original abstract
Large language models (LLMs) increasingly operate as autonomous agents that reason over external APIs to perform complex tasks. However, their reliability and agreement remain poorly characterized. We present a unified benchmarking framework to quantify inter-LLM divergence, defined as the extent to which models differ in API discovery and ranking under identical tasks. Across 15 canonical API domains and 5 major model families, we measure pairwise and group-level agreement using set-, rank-, and consensus-based metrics including Average Overlap, Jaccard similarity, Rank-Biased Overlap, Kendall's tau, Kendall's W, and Cronbach's alpha. Results show moderate overall alignment (AO about 0.50, tau about 0.45) but strong domain dependence: structured tasks (Weather, Speech-to-Text) are stable, while open-ended tasks (Sentiment Analysis) exhibit substantially higher divergence. Volatility and consensus analyses reveal that coherence clusters around data-bound domains and degrades for abstract reasoning tasks. These insights enable reliability-aware orchestration in multi-agent systems, where consensus weighting can improve coordination among heterogeneous LLMs. Beyond performance benchmarking, our results reveal systematic failure modes in multi-agent LLM coordination, where apparent agreement can mask instability in action-relevant rankings. This hidden divergence poses a pre-deployment safety risk and motivates diagnostic benchmarks for early detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmarking framework to quantify inter-LLM divergence in API discovery and ranking across 15 canonical domains and 5 model families. It computes pairwise and group agreement via set-, rank-, and consensus metrics (Average Overlap, Jaccard, Rank-Biased Overlap, Kendall's tau, Kendall's W, Cronbach's alpha), reporting moderate overall alignment (AO ≈ 0.50, tau ≈ 0.45) with strong domain dependence: structured tasks (Weather, Speech-to-Text) show stability while open-ended tasks (Sentiment Analysis) exhibit higher divergence. Volatility and consensus analyses are used to identify coherence clusters, with implications for reliability-aware orchestration and safety risks in multi-agent LLM systems.
Significance. If the empirical patterns hold after addressing the top-k concern, the work supplies a useful diagnostic toolkit for characterizing LLM consistency in agentic API use, an area of growing practical importance. The domain-dependent findings could guide consensus-weighting strategies in heterogeneous multi-agent setups. The paper's strength lies in its systematic application of multiple agreement metrics to a concrete retrieval task, though the safety-risk interpretation hinges on whether observed divergences affect the top-ranked APIs that actually determine agent behavior.
major comments (2)
- [§4.2] §4.2 (Results): The reported AO ≈ 0.50 and tau ≈ 0.45 are computed over full API rankings. No top-1/3 or top-k restricted analysis is provided to test whether disagreement is concentrated in lower ranks; if so, the practical divergence in agent actions (and thus the claimed safety risk for multi-agent coordination) would be substantially smaller.
- [§3.1] §3.1 (Experimental Setup): The selection of exactly 15 domains and 5 model families is presented without justification or sensitivity analysis; it is therefore unclear whether the observed domain dependence generalizes beyond the chosen sample or is an artifact of the particular API distributions.
minor comments (2)
- [Abstract] Abstract: Numerical claims (AO about 0.50, tau about 0.45) are given without accompanying standard errors, confidence intervals, or statistical tests; these should be added for interpretability.
- [Figure 3] Figure 3: Axis labels and legend entries use inconsistent abbreviations (e.g., “AO” vs. “Avg. Overlap”); standardize notation across all figures and tables.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and will revise the manuscript accordingly to strengthen the practical relevance of our findings.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Results): The reported AO ≈ 0.50 and tau ≈ 0.45 are computed over full API rankings. No top-1/3 or top-k restricted analysis is provided to test whether disagreement is concentrated in lower ranks; if so, the practical divergence in agent actions (and thus the claimed safety risk for multi-agent coordination) would be substantially smaller.
Authors: We agree that top-k restricted analyses are necessary to evaluate the practical impact on agent behavior, as only the highest-ranked APIs typically determine downstream actions. Our existing data already contains full rankings for all models and domains, so we can compute Average Overlap, Jaccard, RBO, and Kendall's tau restricted to top-1, top-3, and top-5 without new experiments. We will add these results as a dedicated subsection in §4.2, including a revised discussion of safety implications that distinguishes between full-list divergence and action-relevant top-k divergence. revision: yes
-
Referee: [§3.1] §3.1 (Experimental Setup): The selection of exactly 15 domains and 5 model families is presented without justification or sensitivity analysis; it is therefore unclear whether the observed domain dependence generalizes beyond the chosen sample or is an artifact of the particular API distributions.
Authors: The 15 domains were selected to cover a deliberate spectrum from highly structured, deterministic tasks (Weather, Speech-to-Text) to open-ended, subjective ones (Sentiment Analysis, Code Generation), drawing on common categories in agentic API benchmarks. The five model families were chosen to include the dominant commercial providers and leading open-source models available during data collection. We acknowledge that explicit selection criteria and sensitivity checks were not included. In revision we will expand §3.1 with a clear rationale, supported by references to prior API usage surveys, and add a limitations subsection discussing the scope of generalizability. A comprehensive sensitivity analysis across additional domains would require new data collection and is beyond the current study scope. revision: partial
Circularity Check
No significant circularity: purely empirical benchmarking with standard metrics
full rationale
The paper reports direct measurements of inter-LLM agreement on API retrieval and ranking using off-the-shelf set-, rank-, and consensus-based metrics (Average Overlap, Jaccard, RBO, Kendall's tau, Kendall's W, Cronbach's alpha) computed over experimental outputs from 15 domains and 5 model families. No derivation chain, first-principles prediction, fitted parameter renamed as prediction, or uniqueness theorem is present. All reported quantities (AO ~0.50, tau ~0.45, domain dependence) are computed results, not reductions to inputs by construction. The study is self-contained against external benchmarks and contains no self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 15 selected API domains represent a sufficient sample of real-world tasks for measuring general divergence patterns.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results show moderate overall alignment (AO about 0.50, tau about 0.45) but strong domain dependence: structured tasks (Weather, Speech-to-Text) are stable, while open-ended tasks (Sentiment Analysis) exhibit substantially higher divergence.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We measure pairwise and group-level agreement using set-, rank-, and consensus-based metrics including Average Overlap, Jaccard similarity, Rank-Biased Overlap, Kendall's tau, Kendall's W, and Cronbach's alpha.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Kendall rank correlation coefficient
Abdi, Hervé. "The Kendall rank correlation coefficient." Encyclopedia of measurement and statistics 2 (2007): 508-510. Aiello, Marco, and Ilche Georgievski. "Service composition in the ChatGPT era." Service Oriented Computing and Applications 17, no. 4 (2023): 233-238. Aiello, Marco. "A Paradigm Shift in Service Research: The Case of Service Composition."...
work page 2007
-
[2]
Llm-generated microservice implementations from restful api defini- tions
Chauhan, Saurabh, Zeeshan Rasheed, Abdul Malik Sami, Zheying Zhang, Jussi Rasku, Kai -Kristian Kemell, and Pekka Abrahamsson. "Llm-generated microservice implementations from restful api defini- tions." arXiv preprint arXiv:2502.09766 (2025). Cho, Eunseong, and Seonghoon Kim. "Cronbach’s coefficient alpha: Well known but poorly understood." Organizational...
-
[3]
Further generalizations of the Jaccard index
Costa, Luciano da F. "Further generalizations of the Jaccard index." arXiv preprint arXiv:2110.09619 (2021). Cronbach, Lee J. "Coefficient alpha and the internal structure of tests." psychometrika 16, no. 3 (1951): 297-334. Deng, Sida, Rubing Huang, Man Zhang, Chenhui Cui, Dave Towey, and Rongcun Wang. "LRASGen: LLM-based RESTful API Specifica- tion Gener...
-
[4]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Li, Minghao, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Hai- yang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. "Api-bank: A com- prehensive benchmark for tool -augmented llms." arXiv preprint arXiv:2304.08244 (2023). Li, Wen, Hongshuai Ren, Yamei Nie, Zihao Liu, Guosheng Kang, Jianxun Liu, and Zhenlian Peng. "Crawling and Exploring RESTful Web APIs fro...
work page internal anchor Pith review arXiv 2023
-
[5]
A survey on LLM-based multi-agent systems: workflow, infrastructure, and chal- lenges
Li, Xinyi, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. "A survey on LLM-based multi-agent systems: workflow, infrastructure, and chal- lenges." Vicinagearth 1, no. 1 (2024):
work page 2024
-
[6]
Kendall rank correlation and Mann -Kendall trend test
McLeod, A. Ian. "Kendall rank correlation and Mann -Kendall trend test." R package Kendall 602 (2005): 1-10. Morais, Gabriel, Edwin Lemelin, Mehdi Adda, and Dominik B ork. "Large Language Models for API Classification: An Explorative Study." (2025). Pesl, Robin D., Miles Stötzner, Ilche Georgievski, and Marco Aiello. "Uncovering LLMs for service-compositi...
work page 2005
-
[7]
LLMSRec: Large language model with service network aug- mentation for web service recommendation
Peng, Qian, Buqing Cao, Xiang Xie, Hongfan Ye, Jianxun Liu, and Zhao Li. "LLMSRec: Large language model with service network aug- mentation for web service recommendation." Knowledge -Based Sys- tems (2025): 113710. Ponelat, Josh, and Lukas Rosenstock. Designing APIs with Swagger and OpenAPI. Simon and Schuster,
work page 2025
-
[8]
Postman, 7th Annual State of the API Report, Available Online: https://www.postman.com/state-of-api/2025/, Last Accessed Novem- ber
work page 2025
-
[9]
Toolformer: Language models can teach them- selves to use tools
Schick, Timo, Jane Dwivedi -Yu, Roberto Dessì, Roberta Raileanu , Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. "Toolformer: Language models can teach them- selves to use tools." Advances in Neural Information Processing Sys- tems 36 (2023): 68539-68551. Sheng, Ying, Sudeep Gandhe, Bharg av Kanagal, Nick Edmonds, Zachar...
work page 2023
-
[10]
Song, Yifan, Weimi n Xiong, Dawei Zhu, Wenhao Wu, Han Qian, Mingbo Song, Hailiang Huang et al. "Restgpt: Connecting large lan- guage models with real -world restful apis." arXiv preprint arXiv:2306.06624 (2023). Tzachristas, Ioannis. "Creating an LLM-based AI-agent: A high-level methodology towards enhancing LLMs with APIs." arXiv preprint arXiv:2412.1323...
-
[11]
LLM- Based Agents for Tool Learning: A Survey: W. Xu et al
Xu, Weikai, Chengrui Huang, Shen Gao, and Shuo Shang. "LLM- Based Agents for Tool Learning: A Survey: W. Xu et al." Data Science and Engineering (2025): 1-31. Yokotsuji, Ryutaro, Donghui Lin, and Fumito Uwano. "LLM -Based Interoperable IoT Service Platform." In 2024 IEEE/WIC International Conference on Web Inte lligence and Intelligent Agent Technology (W...
work page 2025
-
[12]
A consistent extension of Condorcet’s election principle
Young, H. Peyton, and Arthur Levenglick. "A consistent extension of Condorcet’s election principle." SIAM Journal on applied Mathemat- ics 35, no. 2 (1978): 285-300. Zhang, Ke, Che nxi Zhang, Chong Wang, Chi Zhang, YaChen Wu, Zhenchang Xing, Yang Liu, Qingshan Li, and Xin Peng. "LogiAgent: Automated Logical Testing for REST Systems with LLM -Based Multi-A...
-
[13]
RESTLess: Enhancing State-of-the-Art REST API Fuzzing with LLMs in Cloud Service Computing
Zheng, Tao, Jiang Shao, Jinqiao Dai, Shuyu Jiang, Xingshu Chen, and Changxiang Shen. "RESTLess: Enhancing State-of-the-Art REST API Fuzzing with LLMs in Cloud Service Computing." IEEE Transactions on Services Computing (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.