Recognition: no theorem link
When VLMs 'Fix' Students: Identifying and Penalizing Over-Correction in the Evaluation of Multi-line Handwritten Math OCR
Pith reviewed 2026-05-13 22:39 UTC · model grok-4.3
The pith
VLMs often rewrite student handwritten math solutions instead of transcribing them, hiding errors, and PINK is a new metric that penalizes this over-correction to better match human judgment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
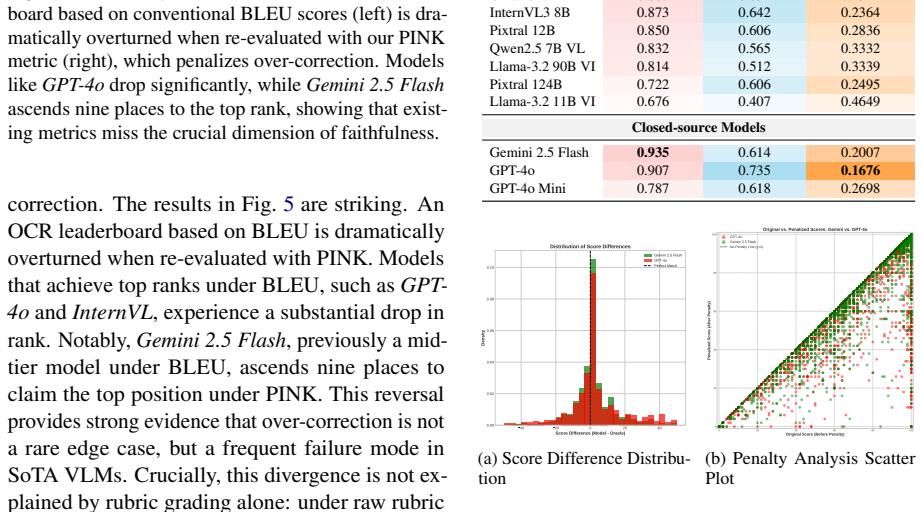
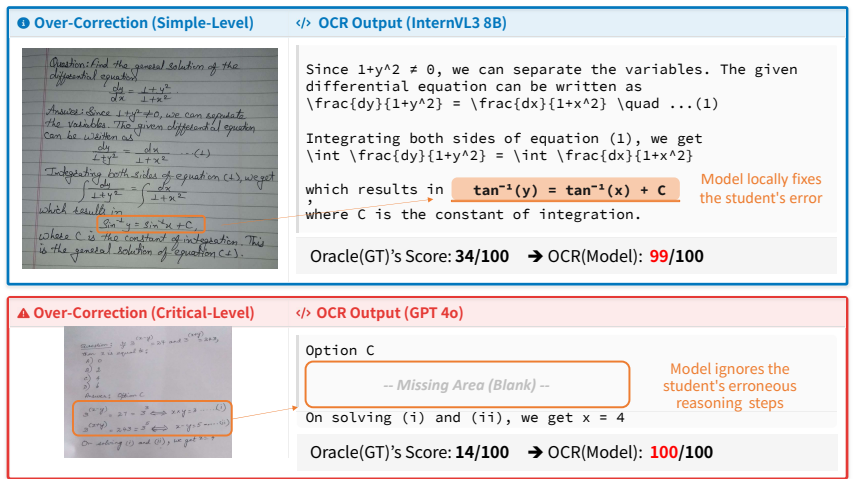
Vision-language models exhibit a systematic failure mode of over-correction when transcribing multi-line handwritten mathematics: instead of faithfully reproducing a student's work, they rewrite expressions to remove errors, thereby masking the very reasoning flaws an assessment must identify. PINK (Penalized INK-based score) counters this by using an LLM to perform rubric-based semantic grading that explicitly deducts for over-correction, producing scores that align more closely with human experts than lexical baselines and reversing model rankings on the FERMAT dataset.
What carries the argument
PINK (Penalized INK-based score), a semantic metric that applies LLM-driven rubric grading to multi-line transcriptions and subtracts points for any semantic or notational changes that were not present in the original student work.
If this is right
- Models such as GPT-4o receive sharply lower scores under PINK than under BLEU because of their tendency to rewrite student steps.
- Gemini 2.5 Flash ranks highest for faithful transcription once over-correction is penalized.
- Educational AI systems that rely on VLM OCR will miss student misconceptions unless the evaluation metric penalizes rewriting.
- Lexical metrics alone are insufficient for multi-line math because they cannot distinguish helpful cleanup from error concealment.
Where Pith is reading between the lines
- Training VLMs with an auxiliary objective that rewards exact reproduction of visible strokes rather than semantic cleanup could reduce over-correction at the source.
- The same penalization approach could be adapted to other faithful-transcription tasks such as handwritten code or diagram labeling.
- Deploying PINK in live educational platforms would surface student errors that current VLM pipelines currently suppress.
- Extending the rubric inside PINK to include step-by-step logical validity could further tighten alignment with actual learning outcomes.
Load-bearing premise
The LLM that performs the rubric grading inside PINK itself avoids over-correction or other biases when judging semantic fidelity.
What would settle it
A controlled human study in which experts rate the same set of transcriptions and find that PINK scores do not correlate more strongly with their judgments of faithfulness than BLEU scores do.
Figures















read the original abstract
Accurate transcription of handwritten mathematics is crucial for educational AI systems, yet current benchmarks fail to evaluate this capability properly. Most prior studies focus on single-line expressions and rely on lexical metrics such as BLEU, which fail to assess the semantic reasoning across multi-line student solutions. In this paper, we present the first systematic study of multi-line handwritten math Optical Character Recognition (OCR), revealing a critical failure mode of Vision-Language Models (VLMs): over-correction. Instead of faithfully transcribing a student's work, these models often "fix" errors, thereby hiding the very mistakes an educational assessment aims to detect. To address this, we propose PINK (Penalized INK-based score), a semantic evaluation metric that leverages a Large Language Model (LLM) for rubric-based grading and explicitly penalizes over-correction. Our comprehensive evaluation of 15 state-of-the-art VLMs on the FERMAT dataset reveals substantial ranking reversals compared to BLEU: models like GPT-4o are heavily penalized for aggressive over-correction, whereas Gemini 2.5 Flash emerges as the most faithful transcriber. Furthermore, human expert studies show that PINK aligns significantly better with human judgment (55.0% preference over BLEU's 39.5%), providing a more reliable evaluation framework for handwritten math OCR in educational settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs exhibit over-correction when transcribing multi-line handwritten math solutions (hiding student errors), introduces PINK as an LLM-based rubric grading metric that explicitly penalizes this behavior, reports ranking reversals versus BLEU on the FERMAT dataset (e.g., GPT-4o heavily penalized while Gemini 2.5 Flash ranks highest), and shows human experts prefer PINK (55.0%) over BLEU (39.5%).
Significance. If the central claims hold after addressing the grader validation, the work would be significant for educational AI: it identifies a previously under-studied failure mode in multi-line math OCR and supplies a semantic metric that better matches human judgment than lexical baselines, with potential to improve automated assessment of student reasoning.
major comments (2)
- [PINK metric and evaluation protocol] The PINK metric definition relies on an LLM for rubric-based grading to detect semantic correctness and penalize over-correction, but the manuscript provides no validation that this grader avoids the same over-correction bias demonstrated for VLMs (which share core architectures with the grader LLM); this assumption is load-bearing for the reported ranking reversals and human-preference results.
- [Human studies] The human expert preference study (55.0% for PINK vs. 39.5% for BLEU) is presented without details on participant count, annotation protocol, inter-rater reliability, or statistical significance testing; these omissions prevent assessment of whether the alignment claim is robust.
minor comments (1)
- [Abstract and dataset description] The composition, size, and diversity of the FERMAT dataset (number of multi-line samples, error types, student demographics) are not described, which would strengthen the generalizability claims for the 15-VLM evaluation.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive review. Their comments have helped us identify areas where the manuscript can be strengthened. We address each major comment below.
read point-by-point responses
-
Referee: [PINK metric and evaluation protocol] The PINK metric definition relies on an LLM for rubric-based grading to detect semantic correctness and penalize over-correction, but the manuscript provides no validation that this grader avoids the same over-correction bias demonstrated for VLMs (which share core architectures with the grader LLM); this assumption is load-bearing for the reported ranking reversals and human-preference results.
Authors: We thank the referee for pointing out this important consideration. The PINK metric is designed with explicit instructions in the LLM prompt to detect and penalize over-correction by comparing the transcription against the original student work for semantic fidelity. However, we acknowledge that without explicit validation of the grader, the results may be questioned. In the revised version, we will add a new subsection validating the LLM grader by having it evaluate a set of synthetic over-correction examples and reporting agreement with human experts. This will support the robustness of the reported rankings and preferences. revision: yes
-
Referee: [Human studies] The human expert preference study (55.0% for PINK vs. 39.5% for BLEU) is presented without details on participant count, annotation protocol, inter-rater reliability, or statistical significance testing; these omissions prevent assessment of whether the alignment claim is robust.
Authors: We apologize for not including sufficient details on the human study in the original submission. We will revise the manuscript to provide a full description of the participant recruitment (number of experts), the exact annotation protocol used for the preference study, calculations for inter-rater reliability, and the statistical tests applied to the preference percentages. These additions will allow for a better assessment of the claim's robustness. revision: yes
Circularity Check
No circularity: PINK is an independently defined LLM-rubric metric evaluated against human judgments
full rationale
The paper defines PINK explicitly as a new semantic metric that applies LLM-based rubric grading to penalize detected over-correction in VLM transcriptions of multi-line math. No equations or derivations reduce the metric to its own outputs by construction, no parameters are fitted and then relabeled as predictions, and no load-bearing claims rest on self-citations whose content is unverified. The reported ranking reversals and human preference (55% vs 39.5%) are presented as empirical outcomes of applying the metric, not as tautological consequences of its definition. The potential bias of the LLM grader itself is a separate correctness concern, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM can perform reliable rubric-based grading of math solutions
Reference graph
Works this paper leans on
-
[1]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xue- hui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Simulated Grading Scenario:Annotators are presented with a math problem and a “Student Solution.” Although this text is the VLM’s OCR transcription, it is presented as a student’s answer. Annotators are instructed to act as math teachers and grade the solution based on the provided Reference Answer
-
[3]
Blind Metric Comparison:After assigning their own score (0-10 scale), annotators are shown two automated scores labeled“Score A”and“Score B.”These correspond to the PINK and BLEU scores (normalized to the same scale). Crucially, the assignment of A/B ❓ Question (Common) Factorise 4y² − 12y + 9. 🧑🎓 Student Solution Observe 4y² = (2y)², 9 = 3² and 12y = 2 ...
-
[4]
Preference Selection:Finally, experts select which score (A or B) better reflects the true quality and faithfulness of the transcription compared to their own expert judgment. Also, annotators were recruited from our institu- tion and compensated through regular employment. They were fully informed about the research objec- tives and how their evaluations...
-
[5]
Analyze each expression character by character to identify any errors in formulas, calculations, or transformations, and provide a detailed justification explaining exactly where and why points were awarded or deducted
-
[6]
In line 3, the expression 2x+3 should be 2x-3, where the + sign at position 3 is incorrect
Include specific numbers, equations, or character positions in justification when necessary (e.g., "In line 3, the expression 2x+3 should be 2x-3, where the + sign at position 3 is incorrect")
-
[7]
Total score must be an integer between 0-100
-
[8]
Output only the JSON format below. No additional text. Output Format: { "scores": [ {"item": "Core Formula/Principle Identification", "score": 0~20, "justification": "..."}, {"item": "Condition/Boundary Application", "score": 0~20, "justification": "..."}, {"item": "Calculation Accuracy (Early-Mid)", "score": 0~20, "justification": "..."}, {"item": "Calcu...
-
[9]
GT (Ground Truth): The original correct LaTeX mathematical expression
-
[10]
Prediction: The OCR-predicted LaTeX mathematical expression Your task is to:
-
[11]
Identify all format differences using the categories below
-
[12]
Identify all recognition errors using the types below
-
[13]
Note the specific locations and nature of differences for the analysis
-
[14]
Classify based on what you found: - If only format differences found → "LaTeX format difference only" - If only recognition errors found → "Recognition error only" - If both found → "Both LaTeX and recognition errors" - If neither found → "No errors" Format Difference Categories: - Math Mode Difference: $ x $ vs \( x \) vs x - Spacing Difference: \quad vs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.