Recognition: unknown
FreqFormer: Hierarchical Frequency-Domain Attention with Adaptive Spectral Routing for Long-Sequence Video Diffusion Transformers
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
FreqFormer splits video token features into frequency bands and assigns different attention operators to each band, reducing quadratic costs in long-sequence diffusion transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
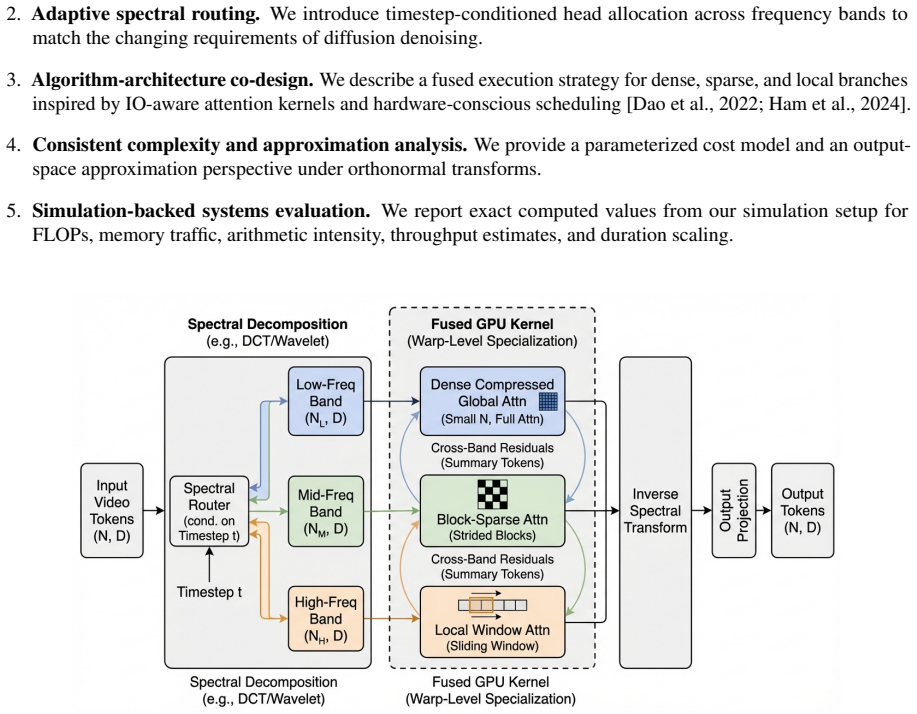
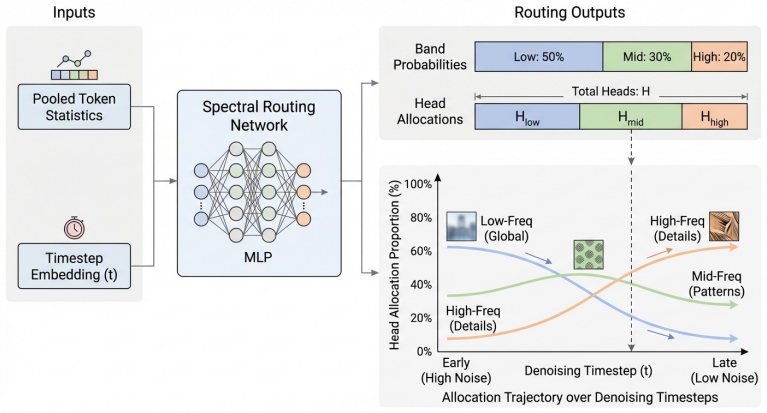
Video features in diffusion processes are spectrally structured, with low frequencies carrying global layout and coarse motion while high frequencies carry texture and fine detail. FreqFormer exploits this structure through a heterogeneous attention framework that applies dense global attention on compressed low-frequency content, structured block-sparse attention on mid frequencies, and sliding-window local attention on high frequencies. A spectral routing network allocates heads across bands using layer statistics and the current denoising timestep. Cross-band summary tokens provide residual exchange. The resulting system is paired with a fused GPU execution plan and is shown in simulation
What carries the argument
Frequency-aware heterogeneous attention framework that partitions tokens into spectral bands and routes them to distinct operators (dense, block-sparse, local) under the control of a timestep-aware routing network plus cross-band summary tokens.
If this is right
- Longer video sequences become feasible because attention FLOPs and KV memory traffic scale more favorably than dense quadratic attention.
- Compute can be reallocated automatically as denoising progresses, prioritizing global structure early and local detail later.
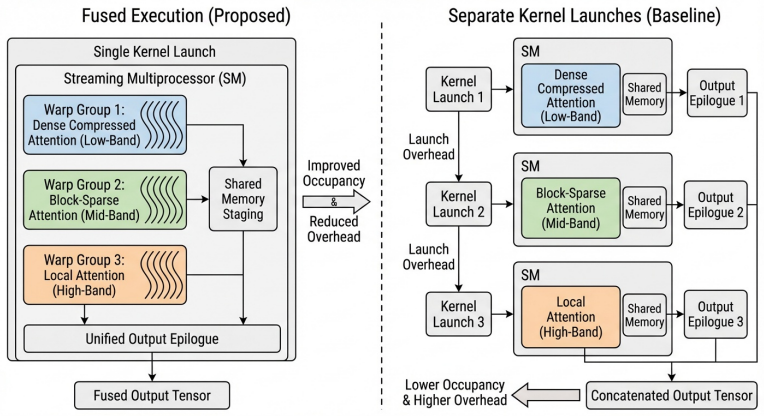
- A single fused GPU schedule for the three branches reduces kernel launches and memory traffic relative to separate kernels.
- The same spectral decomposition supplies both an orthonormal view of the approximation and a consistent complexity model.
- The approach supports hardware-friendly patterns that remain practical on current GPUs up to at least one million tokens.
Where Pith is reading between the lines
- The same band-splitting idea could be tested in other iterative generative settings such as audio waveform models or 3D scene synthesis where frequency structure is also present.
- If the routing network proves stable, it might be combined with existing sparse-attention libraries to obtain real speedups beyond the reported simulations.
- Energy use per generated frame should drop noticeably for very long videos, which would matter for large-scale training runs.
- The method leaves open whether the routing decisions themselves could be learned jointly with the diffusion weights rather than using hand-designed statistics.
Load-bearing premise
Video features remain sufficiently organized by frequency across denoising timesteps so the heterogeneous operators and routing network preserve generative quality without post-hoc retraining.
What would settle it
Run FreqFormer on 1M-token video sequences and measure perceptual quality or FID against a dense-attention baseline; clear degradation at later denoising steps would show the spectral-structure assumption does not hold.
Figures







read the original abstract
Long-sequence video diffusion transformers hit a quadratic self-attention cost that dominates runtime and memory for very long token sequences. Most efficient attention methods use one approximation everywhere, yet video features are spectrally structured: low frequencies carry global layout and coarse motion; high frequencies carry texture and fine detail. We present FreqFormer, a frequency-aware heterogeneous attention framework. Token features are split into spectral bands with different operators: dense global attention on compressed low-frequency content, structured block-sparse attention on mid frequencies, and sliding-window local attention on high frequencies. A lightweight spectral routing network allocates heads across bands using layer statistics and the diffusion timestep, shifting compute toward global structure early in denoising and detail later. Cross-band summary tokens provide cheap residual exchange. FreqFormer is paired with a fused GPU execution plan that co-schedules dense, sparse, and local branches to cut kernel launches and memory traffic. We give a consistent complexity model, an orthonormal-decomposition view of approximation, and simulation-based systems numbers (throughput, arithmetic intensity, memory traffic, duration scaling). In simulations from 64K to 1M tokens, FreqFormer substantially reduces estimated attention FLOPs and KV-related memory traffic versus dense attention while keeping a hardware-friendly pattern, supporting spectrally structured heterogeneous attention as a practical direction for long-video diffusion transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FreqFormer, a frequency-aware heterogeneous attention framework for long-sequence video diffusion transformers. Token features are split into spectral bands processed by different operators (dense global attention on low-frequency content, block-sparse attention on mid frequencies, sliding-window local attention on high frequencies), with a lightweight spectral routing network that allocates heads using layer statistics and diffusion timestep. Cross-band summary tokens enable residual exchange, and the method is paired with a fused GPU execution plan. The authors provide a consistent complexity model, an orthonormal-decomposition view of the approximation, and simulation-based results showing reduced attention FLOPs and KV memory traffic versus dense attention for sequences from 64K to 1M tokens.
Significance. If the spectral structure of video features holds across denoising timesteps and the routing preserves generative quality, FreqFormer could meaningfully advance scalable long-video diffusion by replacing uniform approximations with band-specific operators that align with natural frequency content while maintaining hardware-friendly patterns. The provided complexity model and simulation numbers offer a clear, consistent basis for the efficiency claims.
major comments (2)
- [Abstract] Abstract and simulation results: No end-to-end training results, FID/FVD scores, perceptual metrics, or ablations comparing generated video quality against dense attention are reported. This is load-bearing for the central claim, as the efficiency gains are conditional on the untested assumption that the heterogeneous operators plus timestep-aware routing preserve quality without degradation.
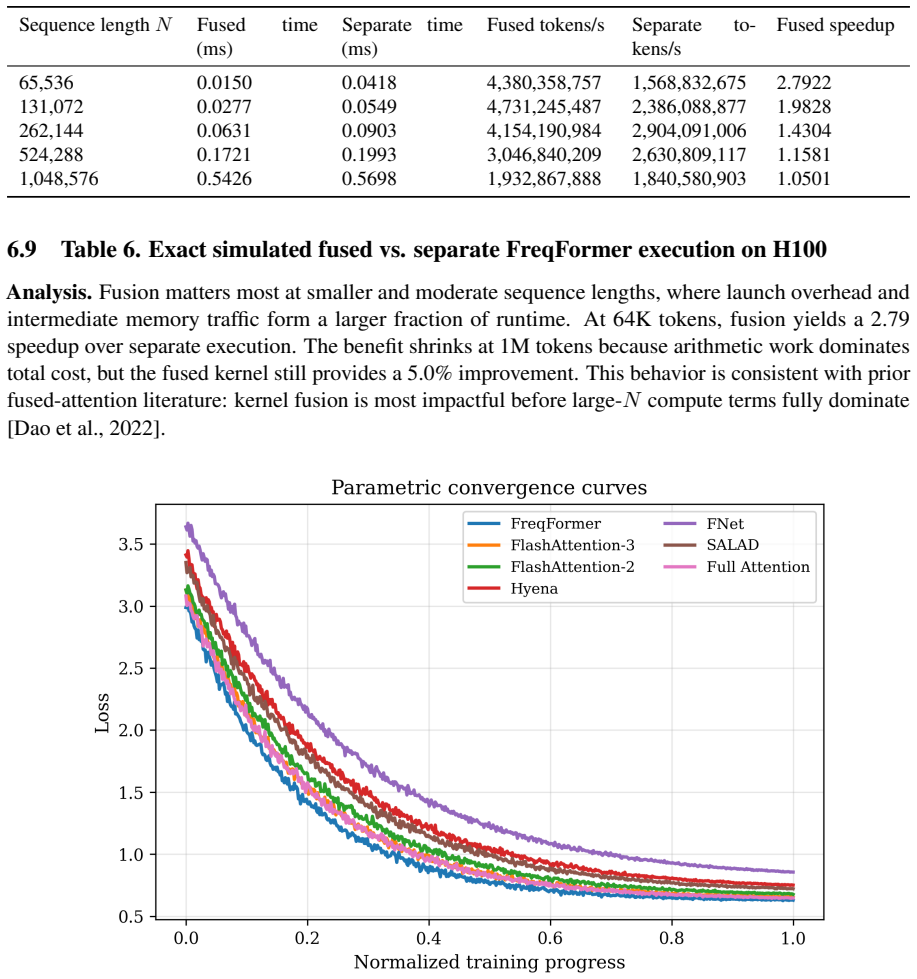
- [Complexity model] Complexity model and simulations: The reported FLOP and memory-traffic reductions for 64K–1M tokens rest entirely on estimated complexity modeling and simulations rather than measured hardware performance or an implemented model; no table or figure provides per-band breakdown, routing overhead, or actual throughput numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the major comments point by point below, clarifying the simulation-focused scope of the work while outlining revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract and simulation results: No end-to-end training results, FID/FVD scores, perceptual metrics, or ablations comparing generated video quality against dense attention are reported. This is load-bearing for the central claim, as the efficiency gains are conditional on the untested assumption that the heterogeneous operators plus timestep-aware routing preserve quality without degradation.
Authors: We acknowledge that the manuscript does not report end-to-end training results, FID/FVD scores, or perceptual metrics. The work is a simulation-based study of the frequency-aware heterogeneous attention mechanism, supported by an analytical complexity model and an orthonormal-decomposition analysis of the approximation error. The assumption of quality preservation follows from the alignment of band-specific operators with video spectral structure and the use of cross-band summary tokens. We will revise the abstract and add a limitations section to explicitly state this scope and note the requirement for future full-model validation. revision: partial
-
Referee: [Complexity model] Complexity model and simulations: The reported FLOP and memory-traffic reductions for 64K–1M tokens rest entirely on estimated complexity modeling and simulations rather than measured hardware performance or an implemented model; no table or figure provides per-band breakdown, routing overhead, or actual throughput numbers.
Authors: The efficiency numbers are derived from the consistent analytical complexity model and simulations described in the manuscript. We will add a table providing per-band FLOP and memory-traffic breakdowns, explicit calculations of the spectral routing overhead, and additional figures reporting arithmetic intensity and estimated throughput from the simulation framework. As the study does not include a full GPU kernel implementation, hardware measurements are not available. revision: yes
- End-to-end generative quality evaluation including FID/FVD scores and direct ablations against dense attention, which would require training a complete video diffusion model beyond the current simulation study scope.
- Measured hardware performance, throughput, and kernel execution times from a deployed implementation, as all results rely on analytical modeling and simulations.
Circularity Check
No circularity: complexity model and simulations derived directly from operator definitions
full rationale
The paper's central results consist of a complexity model and simulation estimates for FLOP/memory reductions that are computed from the explicit definitions of the heterogeneous operators (dense low-frequency attention, block-sparse mid-frequency, sliding-window high-frequency) plus the routing network and cross-band tokens. These quantities follow arithmetically from the proposed architecture without any fitted parameters being renamed as predictions, without self-citations serving as load-bearing justifications for uniqueness or ansatz choices, and without any derivation step that reduces to its own inputs by construction. The orthonormal-decomposition view is presented as an interpretive lens on the same operator set rather than an independent claim. The analysis is therefore self-contained against the paper's own stated components.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video token features are spectrally structured such that low frequencies carry global layout and high frequencies carry texture.
Reference graph
Works this paper leans on
-
[1]
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lucic, M., and Schmid, C. (2021). ViViT: A Video Vision Transformer.Proceedings of the IEEE/CVF International Conference on Computer Vision
2021
-
[2]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. (2020). Longformer: The Long-Document Transformer.arXiv preprint arXiv:2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Bertasius, G., Wang, H., and Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding?Proceedings of the International Conference on Machine Learning
2021
-
[4]
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, O., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., Jampani, V ., and Rombach, R. (2023). Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets.arXiv preprint arXiv:2311.15127
work page internal anchor Pith review arXiv 2023
- [5]
-
[6]
and Mallat, S
Bruna, J. and Mallat, S. (2013). Invariant scattering convolution networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 18721886
2013
-
[7]
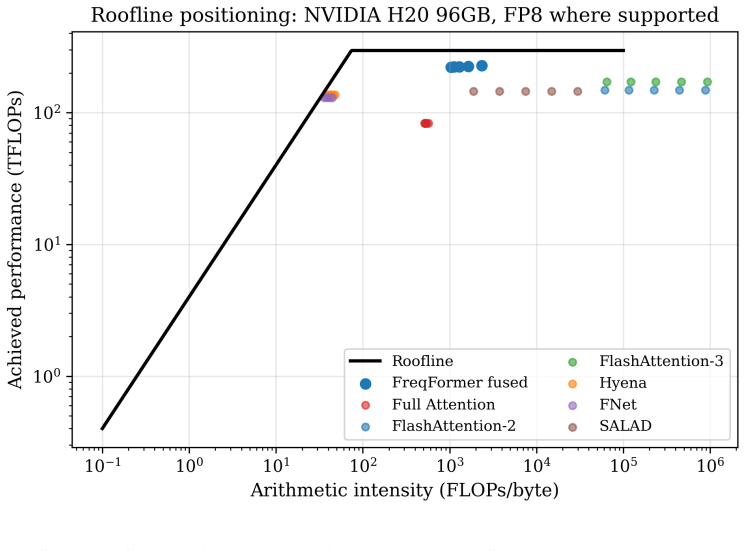
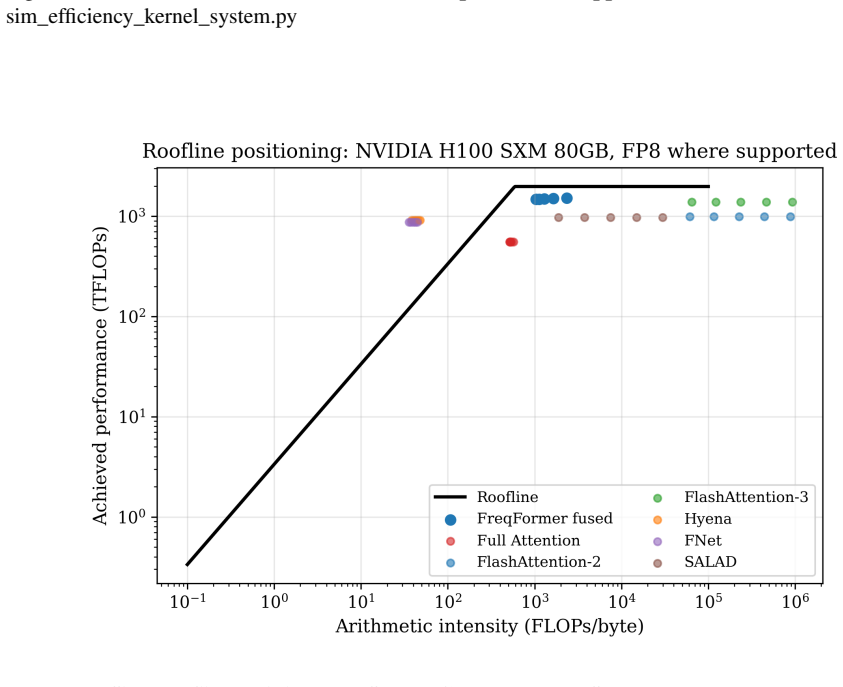
Child, R., Gray, S., Radford, A., and Sutskever, I. (2019). Generating Long Sequences with Sparse Trans- formers.arXiv preprint arXiv:1904.10509. 19 Figure 8:Sim Throughput Nvidia H20 96Gb. Simulation result from sim_efficiency_kernel_system.py Figure 9:Sim Throughput Nvidia H100 Sxm 80Gb. Simulation result from sim_efficiency_kernel_system.py 20 Figure 1...
work page internal anchor Pith review arXiv 2019
-
[8]
Q., Mohiuddin, A., Kaiser, ., Belanger, D., Colwell, L., and Weller, A
Choromanski, K., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J. Q., Mohiuddin, A., Kaiser, ., Belanger, D., Colwell, L., and Weller, A. (2021). Rethinking Attention with Performers.International Conference on Learning Representations
2021
- [9]
-
[10]
Y ., Ermon, S., Rudra, A., and Re, C
Dao, T., Fu, D. Y ., Ermon, S., Rudra, A., and Re, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.Advances in Neural Information Processing Systems
2022
-
[11]
Fan, H., Xiong, B., Mangalam, K., Li, Y ., Yan, Z., Malik, J., and Feichtenhofer, C. (2021). Multiscale Vision Transformers.Proceedings of the IEEE/CVF International Conference on Computer Vision
2021
-
[12]
Feichtenhofer, C., Fan, H., Li, Y ., and He, K. (2022). Masked Autoencoders As Spatiotemporal Learners. Advances in Neural Information Processing Systems
2022
-
[13]
Gu, A., Goel, K., and Re, C. (2022). Efficiently Modeling Long Sequences with Structured State Spaces. International Conference on Learning Representations
2022
-
[14]
J., Jung, M., Kim, J., Oh, Y
Ham, T. J., Jung, M., Kim, J., Oh, Y . H., Park, Y ., Song, Y ., Park, J.-H., Lee, S., Park, K., and Kwon, S. (2024). FlatAttention: Fast and Accurate Attention via Flat Dataflow on GPUs.Proceedings of the ACM/IEEE International Symposium on Computer Architecture
2024
-
[15]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium.Advances in Neural Information Processing Systems
2017
-
[16]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising Diffusion Probabilistic Models.Advances in Neural Information Processing Systems
2020
-
[17]
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Fleet, D., Norouzi, M., and Salimans, T. (2022). Imagen Video: High Definition Video Generation with Diffusion Models.arXiv preprint arXiv:2210.02303
work page internal anchor Pith review arXiv 2022
-
[18]
Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention.Proceedings of the International Conference on Machine Learning
2020
-
[19]
Karras, T., Aittala, M., Aila, T., and Laine, S. (2022). Elucidating the Design Space of Diffusion-Based Generative Models.Advances in Neural Information Processing Systems
2022
-
[20]
Kwon, W., Kim, J., Choi, S., and Lee, J. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention.Proceedings of the ACM SIGOPS Symposium on Operating Systems Principles
2023
-
[21]
Lee-Thorp, J., Ainslie, J., Eckstein, I., and Ontanon, S. (2022). FNet: Mixing Tokens with Fourier Transforms. Proceedings of the North American Chapter of the Association for Computational Linguistics
2022
-
[22]
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandkumar, A. (2021). Fourier Neural Operator for Parametric Partial Differential Equations.International Conference on Learning Representations
2021
-
[23]
Liu, Z., Lin, Y ., Cao, Y ., Hu, H., Wei, Y ., Zhang, Z., Lin, S., and Guo, B. (2021). Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.Proceedings of the IEEE/CVF International Conference on Computer Vision
2021
-
[24]
Mallat, S. (1989). A theory for multiresolution signal decomposition: The wavelet representation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 11(7), 674693
1989
-
[25]
Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V ., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., and Zaharia, M. (2021). Efficient Large- Scale Language Model Training on GPU Clusters Using Megatron-LM.Proceedings of Machine Learning and Systems
2021
-
[26]
A., and Kong, L
Peng, H., Pappas, N., Yogatama, D., Schwarz, J., Smith, N. A., and Kong, L. (2021). Random Feature Attention.International Conference on Learning Representations. 23
2021
-
[27]
and Xie, S
Peebles, W. and Xie, S. (2023). Scalable Diffusion Models with Transformers.Proceedings of the IEEE/CVF International Conference on Computer Vision
2023
-
[28]
Y ., Dao, T., Baccus, S., Bengio, Y ., Ermon, S., and Re, C
Poli, M., Massaroli, S., Nguyen, E., Fu, D. Y ., Dao, T., Baccus, S., Bengio, Y ., Ermon, S., and Re, C. (2023). Hyena Hierarchy: Towards Larger Convolutional Language Models.Proceedings of the International Conference on Machine Learning
2023
-
[29]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision.Proceedings of the International Conference on Machine Learning
2021
-
[30]
Simoncelli, E. P. and Olshausen, B. A. (2001). Natural Image Statistics and Neural Representation.Annual Review of Neuroscience, 24, 11931216
2001
-
[31]
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., Parikh, D., Gupta, S., and Taigman, Y . (2023). Make-A-Video: Text-to-Video Generation without Text-Video Data. International Conference on Learning Representations
2023
-
[32]
Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., Yung, J., Steiner, A., Keysers, D., Uszkoreit, J., Lucic, M., and Dosovitskiy, A. (2021). MLP-Mixer: An all-MLP Architecture for Vision. Advances in Neural Information Processing Systems
2021
-
[33]
Tong, Z., Song, Y ., Wang, J., and Wang, L. (2022). VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training.Advances in Neural Information Processing Systems
2022
-
[34]
and Oliva, A
Torralba, A. and Oliva, A. (2003). Statistics of natural image categories.Network: Computation in Neural Systems, 14(3), 391412
2003
-
[35]
Unterthiner, T., Nessler, B., Heigold, G., van den Oord, A., and Hochreiter, S. (2018). Towards Accurate Generative Models of Video: A New Metric and Challenges.arXiv preprint arXiv:1812.01717
work page internal anchor Pith review arXiv 2018
-
[36]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. (2017). Attention Is All You Need.Advances in Neural Information Processing Systems
2017
- [37]
-
[38]
Wang, X., Girshick, R., Gupta, A., and He, K. (2018). Non-local Neural Networks.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2018
-
[39]
Xiong, Y ., Zeng, Z., Chakraborty, R., Tan, M., Fung, G., Li, Y ., and Singh, V . (2021). Nystromformer: A Nystrom-Based Algorithm for Approximating Self-Attention.Proceedings of the AAAI Conference on Artificial Intelligence
2021
-
[40]
A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., and Ahmed, A
Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., and Ahmed, A. (2020). Big Bird: Transformers for Longer Sequences.Advances in Neural Information Processing Systems
2020
-
[41]
Zheng, C., Zhang, H., and Xu, J. (2024). Survey of Efficient Attention for Long-Context Transformers.ACM Computing Surveys
2024
-
[42]
Zhou, D., Kang, B., Jin, X., Yang, L., Lian, X., Jiang, Z., Hou, Q., and Feng, J. (2022). DeepViT: Towards Deeper Vision Transformer.Proceedings of the AAAI Conference on Artificial Intelligence
2022
-
[43]
Zhu, Y ., Kiros, R., Zemel, R., Salakhutdinov, R., Urtasun, R., Torralba, A., and Fidler, S. (2015). Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. Proceedings of the IEEE International Conference on Computer Vision. 24
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.