Recognition: unknown
SGP-SAM: Self-Gated Prompting for Transferring 3D Segment Anything Models to Lesion Segmentation
Pith reviewed 2026-05-10 06:43 UTC · model grok-4.3
The pith
Self-gated prompting conditionally activates multi-scale fusion to improve 3D SAM transfer to lesion segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGP-SAM shows that a lightweight multi-channel gating unit can predict when intermediate features need multi-scale spatial enhancement and activate the corresponding fusion block only then, while a Zoom Loss combining Dice with voxel-balanced focal weighting improves learning of small lesions, producing higher segmentation accuracy than standard fine-tuning of SAM-Med3D on liver and brain tumor volumes.
What carries the argument
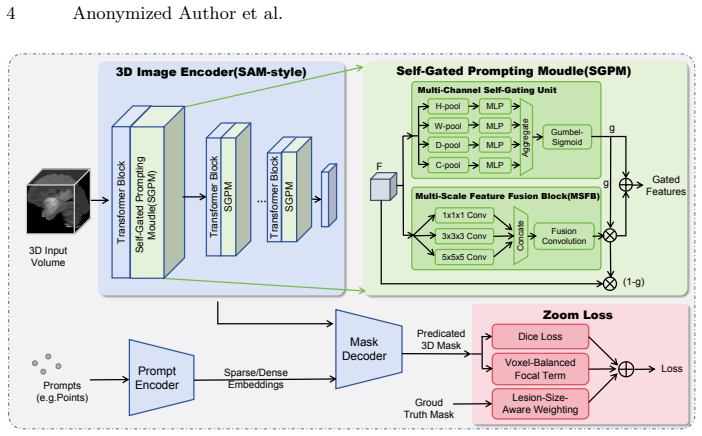
Self-Gated Prompting Module (SGPM): a gating unit that predicts the need for multi-scale fusion and conditionally activates the Multi-Scale Feature Fusion Block.
If this is right
- On the MSD Liver Tumor dataset, mDice rises 7.3 percent above the fine-tuning baseline.
- Consistent accuracy gains appear on the MSD Brain Tumor enhancing-tumor task.
- Conditional activation limits extra computation to cases where the gate detects insufficient spatial context.
- The Zoom Loss up-weights supervision on lesion voxels to mitigate extreme foreground-background imbalance.
Where Pith is reading between the lines
- The same gating logic could be tested on other 3D volumetric tasks such as organ or vessel segmentation where selective feature enrichment is useful.
- If gate decisions correlate strongly with lesion size or shape statistics, the module could provide a simple form of interpretability.
- Replacing the fixed Zoom Loss coefficients with learned parameters might further adapt the method to different imbalance ratios.
Load-bearing premise
The lightweight gating unit will correctly decide when multi-scale fusion is required for small irregular lesions without instability or missed cases, and the reported gains come mainly from the new modules rather than from hyperparameter differences.
What would settle it
A replication experiment that fine-tunes the identical SAM-Med3D baseline with the same optimizer, learning rate schedule, and data augmentations and obtains comparable mDice scores on the MSD Liver Tumor test set would falsify the specific contribution of the SGPM and Zoom Loss.
Figures


read the original abstract
Large segmentation foundation models such as the Segment Anything Model (SAM) have reshaped promptable segmentation in natural images, and recent efforts have extended these models to medical images and volumetric settings. However, directly transferring a 3D SAM-style model to lesion segmentation remains challenging due to (i) weak spatial representational capacity for small, irregular targets in intermediate features, and (ii) extreme foreground-background imbalance in 3D volumes.We propose SGP-SAM, a self-gated prompting framework for efficient and effective transfer to 3D lesion segmentation. Our key component, the Self-Gated Prompting Module (SGPM), performs conditional multi-scale spatial enhancement: a lightweight multi-channel gating unit predicts whether the current features require additional multi-scale fusion, and only then activates a Multi-Scale Feature Fusion Block to enrich spatial context. To further address small-lesion learning, we design a Zoom Loss that up-weights lesion-focused supervision by combining Dice and a voxel-balanced focal term.Experiments on MSD Liver Tumor and MSD Brain Tumor (enhancing tumor) show consistent gains over strong transfer baselines based on SAM-Med3D. On MSD Liver Tumor, SGP-SAM improves mDice by 7.3% over fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
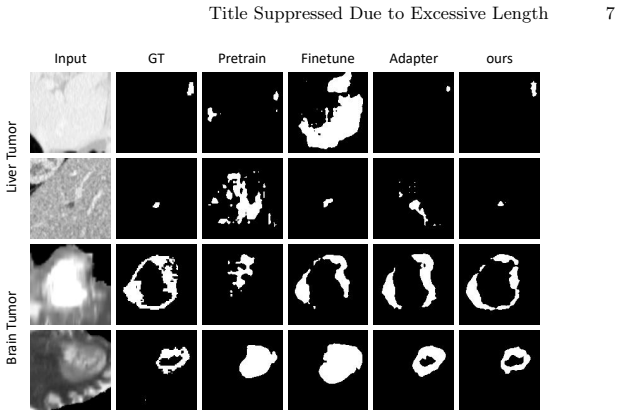
Summary. The paper proposes SGP-SAM, a self-gated prompting framework to adapt 3D SAM-style models (e.g., SAM-Med3D) for lesion segmentation in volumetric medical images. The core contributions are the Self-Gated Prompting Module (SGPM), which uses a lightweight gating unit to conditionally activate a Multi-Scale Feature Fusion Block for spatial enhancement, and a Zoom Loss that combines Dice with a voxel-balanced focal term to address small-lesion imbalance. Experiments on the MSD Liver Tumor and MSD Brain Tumor (enhancing tumor) datasets report consistent improvements over fine-tuning baselines, including a 7.3% mDice gain on Liver Tumor.
Significance. If the performance gains can be robustly attributed to the proposed modules rather than training differences, the work would offer a practical, efficient route for transferring promptable 3D foundation models to challenging medical segmentation tasks involving small, irregular lesions. The conditional gating mechanism and re-weighted loss directly target two stated limitations of direct transfer (weak intermediate spatial features and class imbalance).
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The central claim of a 7.3% mDice improvement on MSD Liver Tumor (and consistent gains on Brain Tumor) is presented without any ablation studies, variant comparisons (e.g., fine-tuning + Zoom Loss only, or SGPM with standard Dice), or statements confirming that the SAM-Med3D fine-tuning baseline used identical optimizer, learning-rate schedule, data augmentation, prompt sampling, or epoch count. This leaves open the possibility that the delta arises from uncontrolled protocol differences rather than the gating logic or small-lesion re-weighting.
- [Method] Method section: The lightweight multi-channel gating unit is described as predicting when multi-scale fusion is needed, yet no architecture details, input features, activation function, or training objective for the gate itself are provided. Without these, it is impossible to assess whether the unit reliably activates for small irregular lesions or introduces instability, which is load-bearing for the conditional-enhancement claim.
minor comments (2)
- [Abstract] Abstract: The statement of 'consistent gains' on MSD Brain Tumor would be strengthened by reporting the exact mDice (or other metric) delta rather than leaving it qualitative.
- [Experiments] The paper would benefit from a table summarizing all hyper-parameters and training settings for both the proposed method and all baselines to enable reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments highlight important gaps in experimental validation and methodological transparency that we agree must be addressed to strengthen the paper. We will revise the manuscript accordingly and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central claim of a 7.3% mDice improvement on MSD Liver Tumor (and consistent gains on Brain Tumor) is presented without any ablation studies, variant comparisons (e.g., fine-tuning + Zoom Loss only, or SGPM with standard Dice), or statements confirming that the SAM-Med3D fine-tuning baseline used identical optimizer, learning-rate schedule, data augmentation, prompt sampling, or epoch count. This leaves open the possibility that the delta arises from uncontrolled protocol differences rather than the gating logic or small-lesion re-weighting.
Authors: We agree that the submitted manuscript lacks explicit ablation studies and protocol confirmation, which weakens the attribution of gains to the proposed modules. In the revised version we will add a dedicated ablation subsection in Experiments that reports four controlled variants on both MSD datasets: (i) SAM-Med3D fine-tuning baseline, (ii) baseline + Zoom Loss only, (iii) SGPM with standard Dice loss, and (iv) full SGP-SAM. We will also insert a clear statement in Section 4.1 confirming that the baseline and all variants used identical settings: AdamW optimizer (weight decay 1e-4), cosine-annealing learning-rate schedule (initial 1e-4), the same data-augmentation pipeline, center-point prompt sampling, and 100-epoch training with early stopping. These additions will allow readers to verify that the 7.3% mDice improvement stems from the gating logic and re-weighted loss rather than training-protocol differences. revision: yes
-
Referee: [Method] Method section: The lightweight multi-channel gating unit is described as predicting when multi-scale fusion is needed, yet no architecture details, input features, activation function, or training objective for the gate itself are provided. Without these, it is impossible to assess whether the unit reliably activates for small irregular lesions or introduces instability, which is load-bearing for the conditional-enhancement claim.
Authors: We concur that the current description of the gating unit is insufficiently detailed. In the revised Method section we will expand the SGPM description to specify: the gating unit receives as input the spatially pooled intermediate feature maps (global average pooling over H×W×D) from the SAM-Med3D encoder layers; it consists of a two-layer MLP (hidden dimension 64) with ReLU activations followed by a sigmoid to output per-channel gate values in [0,1]; the gate is trained end-to-end jointly with the rest of the network under the Zoom Loss (no auxiliary objective). We will also add a short analysis of gate activation histograms stratified by lesion size to demonstrate that the gate activates more frequently for small, irregular targets. These clarifications will enable assessment of reliability and potential instability. revision: yes
Circularity Check
No circularity; empirical architecture proposal validated on external benchmarks
full rationale
The paper introduces an architectural extension (Self-Gated Prompting Module with conditional multi-scale fusion and Zoom Loss) to SAM-Med3D for 3D lesion segmentation. All performance claims rest on direct experimental comparison against baselines on the public MSD Liver Tumor and MSD Brain Tumor datasets. No equations, uniqueness theorems, or fitted parameters are presented that reduce the reported mDice gains to quantities defined solely by the paper's own inputs or self-citations. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (2)
- gating unit parameters
- Zoom Loss balancing coefficient
axioms (2)
- domain assumption Intermediate features from 3D SAM backbones have insufficient spatial context for small irregular lesions
- domain assumption Standard fine-tuning of SAM-Med3D is a strong but insufficient baseline for lesion tasks
invented entities (1)
-
Self-Gated Prompting Module (SGPM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything.arXiv:2304.02643, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Segment anything in medical images.Nature Communications, 15(1):654, 2024
JunMa,YutingHe,FeifeiLi,LinHan,ChenyuYou,others,andBoWang. Segment anything in medical images.Nature Communications, 15(1):654, 2024
2024
-
[4]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
Jun Ma, Zongxin Yang, Sumin Kim, Bihui Chen, Mohammed Baharoon, Adibvafa Fallahpour, Reza Asakereh, Hongwei Lyu, and Bo Wang. Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
-
[5]
Medical sam 2: Segment medical images as video via segment anything model 2,
Jiayuan Zhu, Abdullah Hamdi, Yunli Qi, Yueming Jin, and Junde Wu. Medical sam 2: Segment medical images as video via segment anything model 2.arXiv preprint arXiv:2408.00874, 2024
-
[6]
A review of the segment anything model (sam) for medical image analysis: Accomplishments and perspectives.Computerized Medical Imaging and Graphics, 119:102473, 2025
Mudassar Ali, Tong Wu, Haoji Hu, Qiong Luo, Dong Xu, Weizeng Zheng, Neng Jin, Chen Yang, and Jincao Yao. A review of the segment anything model (sam) for medical image analysis: Accomplishments and perspectives.Computerized Medical Imaging and Graphics, 119:102473, 2025
2025
-
[7]
S-sam: Svd-based fine-tuning of segment anything model for medical image segmentation
JayNParanjape,ShameemaSikder,SSwaroopVedula,andVishalMPatel. S-sam: Svd-based fine-tuning of segment anything model for medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 720–730. Springer, 2024
2024
-
[8]
Cares-unet: Content-aware residual unet for lesion segmentationof covid-19 fromchestct images.Medicalphysics,48(11):7127– 7140, 2021
Xinhua Xu, Yuhang Wen, Lu Zhao, Yi Zhang, Youjun Zhao, Zixuan Tang, Ziduo Yang, and Calvin Yu-Chian Chen. Cares-unet: Content-aware residual unet for lesion segmentationof covid-19 fromchestct images.Medicalphysics,48(11):7127– 7140, 2021
2021
-
[9]
Progressive deep snake for instance boundary extraction in medical images.Expert Systems with Applications, 249:123590, 2024
Zixuan Tang, Bin Chen, An Zeng, Mengyuan Liu, and Shen Zhao. Progressive deep snake for instance boundary extraction in medical images.Expert Systems with Applications, 249:123590, 2024
2024
-
[10]
Sam-med3d: a vision foundation model for general-purpose segmentation on volumetric medical images
Haoyu Wang, Sizheng Guo, Jin Ye, Zhongying Deng, Junlong Cheng, Tianbin Li, Jianpin Chen, Yanzhou Su, Ziyan Huang, Yiqing Shen, et al. Sam-med3d: a vision foundation model for general-purpose segmentation on volumetric medical images. IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[11]
Learnable prompting sam-induced knowledge distillation for semi- supervised medical image segmentation.IEEE Transactions on Medical Imaging, 44(5):2295–2306, 2025
Kaiwen Huang, Tao Zhou, Huazhu Fu, Yizhe Zhang, Yi Zhou, Chen Gong, and Dong Liang. Learnable prompting sam-induced knowledge distillation for semi- supervised medical image segmentation.IEEE Transactions on Medical Imaging, 44(5):2295–2306, 2025
2025
-
[12]
Med-sa: Parameter-efficient tuning of segment anything model for medical image analysis.Medical Image Analysis, 102:103547, 2025
Junyi Wu, Rui Fu, Heng Fang, et al. Med-sa: Parameter-efficient tuning of segment anything model for medical image analysis.Medical Image Analysis, 102:103547, 2025
2025
-
[13]
3dsam-adapter: Holistic adaptation of sam from 2d to 3d for promptable tumor segmentation.Medical Image Analysis, 98:103324, 2024
Shizhan Gong, Yuan Zhong, Wenao Ma, Jinpeng Li, Zhao Wang, Jingyang Zhang, Pheng-Ann Heng, and Qi Dou. 3dsam-adapter: Holistic adaptation of sam from 2d to 3d for promptable tumor segmentation.Medical Image Analysis, 98:103324, 2024
2024
-
[14]
Tianrun Chen, Lanyun Zhu, Chaotao Ding, Runlong Cao, Shangzhan Zhang, Yan Wang, Zejian Li, Lingyun Sun, Papa Mao, and Ying Zang. Sam fails to seg- ment anything?–sam-adapter: Adapting sam in underperformed scenes: Camou- flage, shadow, and more.arXiv:2304.09148, 2023. 10 Anonymized Author et al
-
[15]
Medical sam adapter: Adapting segment anything model for medical image segmentation.Medical image analysis, 102:103547, 2025
Junde Wu, Ziyue Wang, Mingxuan Hong, Wei Ji, Huazhu Fu, Yanwu Xu, Min Xu, and Yueming Jin. Medical sam adapter: Adapting segment anything model for medical image segmentation.Medical image analysis, 102:103547, 2025
2025
-
[16]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv:1611.01144, 2016
work page internal anchor Pith review arXiv 2016
-
[17]
Parameter- efficienttransferlearningfornlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin DeLaroussilhe,AndreaGesmundo,MonaAttariyan,andSylvainGelly. Parameter- efficienttransferlearningfornlp. In InternationalConferenceonMachineLearning, pages 2790–2799. PMLR, 2019
2019
-
[18]
Stitch- ing, fine-tuning, and re-training: A sam-enabled framework for semi-supervised 3d medical image segmentation.IEEETransactionsonMedicalImaging, 44(10):3909– 3923, 2025
Shumeng Li, Lei Qi, Qian Yu, Jing Huo, Yinghuan Shi, and Yang Gao. Stitch- ing, fine-tuning, and re-training: A sam-enabled framework for semi-supervised 3d medical image segmentation.IEEETransactionsonMedicalImaging, 44(10):3909– 3923, 2025
2025
-
[19]
V-net: Fully convolu- tional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolu- tional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV), pages 565–571. Ieee, 2016
2016
-
[20]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings oftheIEEEinternationalconference on computer vision, pages 2980–2988, 2017
2017
-
[21]
Sam-med3d: Towards general-purpose segmentation models for volumetric medical images, 2023
Haoyu Wang, Sizheng Guo, Jin Ye, Zhongying Deng, et al. Sam-med3d: Towards general-purpose segmentation models for volumetric medical images, 2023
2023
-
[22]
Segvol: Universal and interactive volu- metric medical image segmentation
Yuxiang Du, Jin Ye, Zhongying Deng, et al. Segvol: Universal and interactive volu- metric medical image segmentation. InAdvancesin Neural Information Processing Systems (NeurIPS), 2024
2024
-
[23]
Vista3d: A unified segmentation foun- dation model for 3d medical imaging
Yufan He, Pengfei Guo, Yucheng Tang, Andriy Myronenko, Vishwesh Nath, Ziyue Xu, Dong Yang, Can Zhao, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, Daguang Xu, and Wenqi Li. Vista3d: A unified segmentation foun- dation model for 3d medical imaging. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), p...
2025
-
[24]
arXiv preprint arXiv:2201.01266 , year=
Ali Hatamizadeh, Vishwesh Nath, Yucheng Tang, Dong Yang, Holger Roth, and Daguang Xu. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images.arXiv:2201.01266, 2022
-
[25]
AmberLSimpson,MichelaAntonelli,SpyridonBakas,MichelBilello,KeyvanFara- hani, Bram Van Ginneken, Annette Kopp-Schneider, Bennett A Landman, Geert Litjens, Bjoern Menze, et al. A large annotated medical image dataset for the development and evaluation of segmentation algorithms.arXiv:1902.09063, 2019
work page Pith review arXiv 1902
-
[26]
The liver tumor segmentation benchmark (lits).Medical Image Analysis, 84:102680, 2023
Patrick Bilic, Patrick Christ, Hongwei Bran Li, Eugene Vorontsov, Avi Ben-Cohen, Georgios Kaissis, Adi Szeskin, Colin Jacobs, Gabriel Efrain Humpire Mamani, Gabriel Chartrand, et al. The liver tumor segmentation benchmark (lits).Medical Image Analysis, 84:102680, 2023
2023
-
[27]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier- Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2):203–211, 2021
2021
-
[28]
The multimodal brain tumor image segmentation benchmark (brats)
Bjoern H Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Key- van Farahani, Justin Kirby, Yuliya Burren, Nicole Porz, Johannes Slotboom, Roland Wiest, et al. The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging, 34(10):1993–2024, 2014
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.