Recognition: unknown
Neural Network Optimization Reimagined: Decoupled Techniques for Scratch and Fine-Tuning
Pith reviewed 2026-05-10 03:21 UTC · model grok-4.3
The pith
DualOpt decouples optimization techniques for training neural networks from scratch versus fine-tuning pre-trained ones to improve convergence, generalization, and reduce knowledge forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DualOpt is introduced as a decoupled optimizer where training from scratch uses real-time layer-wise weight decay to boost convergence and generalization by matching weight update characteristics and architecture, while fine-tuning incorporates a rollback term in each update step to maintain consistency between upstream and downstream weight distributions, mitigating knowledge forgetting, with the decay extended to adjust rollback levels dynamically across layers for different tasks.
What carries the argument
The integration of a rollback term into the weight update rule for fine-tuning combined with real-time layer-wise weight decay that adapts to network layers and tasks.
Load-bearing premise
The premise that a rollback term added to updates will reliably preserve the pre-trained weight distribution and lessen forgetting while layer-wise weight decay will improve optimization without introducing instability or negative effects.
What would settle it
An ablation study removing the rollback term from DualOpt and measuring if fine-tuning performance drops on tasks sensitive to forgetting, such as when upstream task accuracy after fine-tuning is tracked; lack of drop would challenge the term's value.
Figures

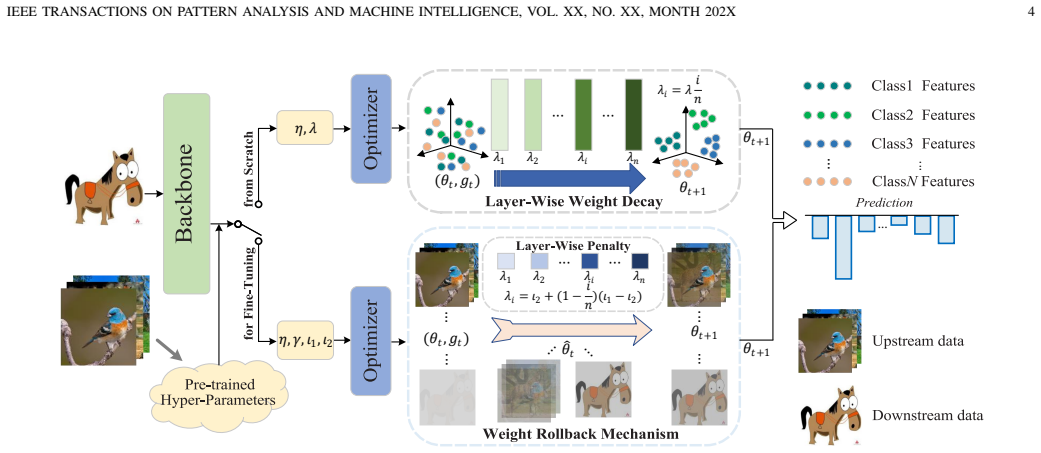
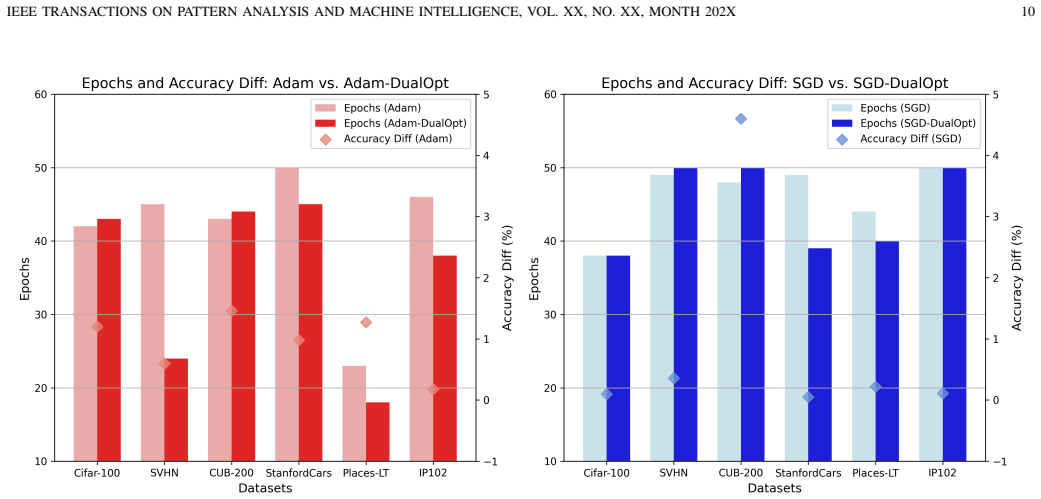
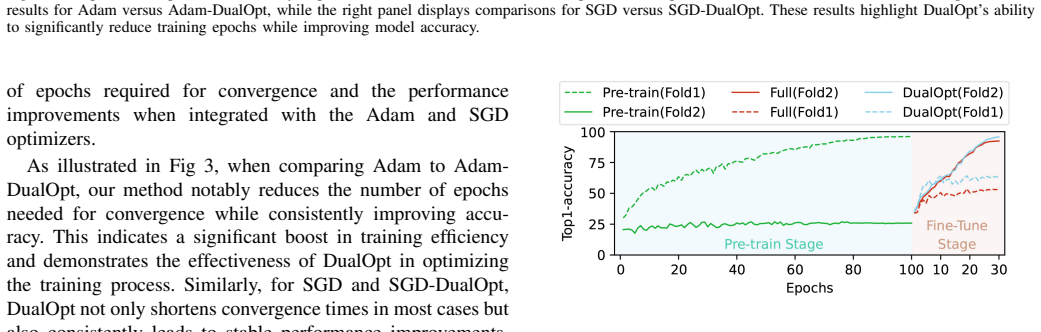
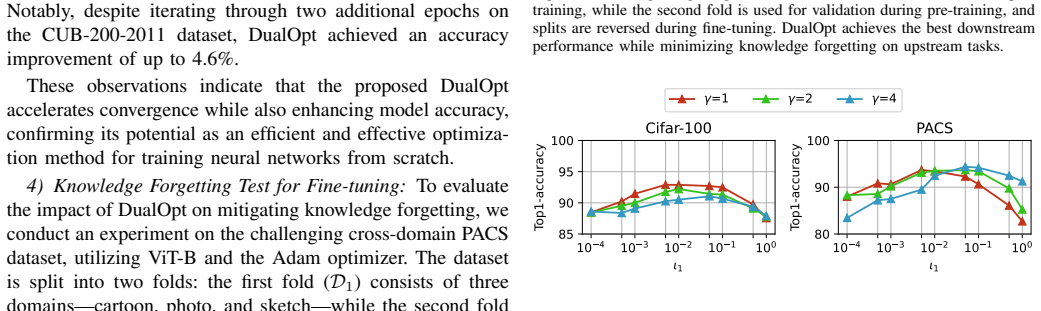

read the original abstract
With the accumulation of resources in the era of big data and the rise of pre-trained models in deep learning, optimizing neural networks for various tasks often involves different strategies for fine-tuning pre-trained models versus training from scratch. However, existing optimizers primarily focus on reducing the loss function by updating model parameters, without fully addressing the unique demands of these two major paradigms. In this paper, we propose DualOpt, a novel approach that decouples optimization techniques specifically tailored for these distinct training scenarios. For training from scratch, we introduce real-time layer-wise weight decay, designed to enhance both convergence and generalization by aligning with the characteristics of weight updates and network architecture. For more importantly fine-tuning, we integrate weight rollback with the optimizer, incorporating a rollback term into each weight update step. This ensures consistency in the weight distribution between upstream and downstream models, effectively mitigating knowledge forgetting and improving fine-tuning performance. Additionally, we extend the layer-wise weight decay to dynamically adjust the rollback levels across layers, adapting to the varying demands of different downstream tasks. Extensive experiments across diverse tasks, including image classification, object detection, semantic segmentation, and instance segmentation, demonstrate the broad applicability and state-of-the-art performance of DualOpt. Code is available at https://github.com/qklee-lz/OLOR-AAAI-2024.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DualOpt, a decoupled optimizer for neural networks. For training from scratch it introduces real-time layer-wise weight decay aligned with update characteristics and architecture. For fine-tuning it adds a rollback term to each weight update (with dynamic layer-wise scaling) to enforce consistency between upstream and downstream weight distributions, thereby mitigating catastrophic forgetting. The authors report extensive experiments on image classification, object detection, semantic segmentation and instance segmentation that demonstrate state-of-the-art performance, with code released.
Significance. If the rollback mechanism can be shown to reliably bound distributional shift beyond standard regularization, the approach would supply a lightweight, architecture-agnostic tool for fine-tuning that could be adopted across computer-vision pipelines. The availability of code and the breadth of evaluated tasks are positive indicators of practical utility.
major comments (3)
- [§3.2] §3.2 (fine-tuning formulation): the central claim that the rollback term 'ensures consistency in the weight distribution' and mitigates forgetting is unsupported. No equation, moment-matching argument, or stability analysis is supplied showing why the chosen form (or its layer-wise dynamic scaling) bounds higher-order statistics under task shift rather than acting as an arbitrary regularizer.
- [§4] §4 (experiments): the abstract asserts 'state-of-the-art performance' and 'broad applicability' yet the provided text supplies neither quantitative tables, ablation studies on the rollback coefficient, nor error bars/comparisons against strong baselines such as L2-SP or EWC. Without these, the empirical support for the decoupling benefit cannot be evaluated.
- [§3.1] §3.1 (scratch training): the real-time layer-wise weight decay is described only at a high level; no derivation or convergence analysis is given that distinguishes it from conventional per-layer decay schedules already present in AdamW or SGD with momentum.
minor comments (2)
- Notation for the rollback term and its dynamic scaling factor is introduced without a clear algorithmic listing or pseudocode, making reproduction difficult despite the GitHub link.
- The abstract and introduction repeatedly use 'decouples optimization techniques' without defining what is being decoupled (optimizer state, hyper-parameters, or update rules).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. The revisions will add the requested theoretical derivations, expanded experimental tables with ablations and baselines, and clearer distinctions from prior methods, thereby strengthening the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (fine-tuning formulation): the central claim that the rollback term 'ensures consistency in the weight distribution' and mitigates forgetting is unsupported. No equation, moment-matching argument, or stability analysis is supplied showing why the chosen form (or its layer-wise dynamic scaling) bounds higher-order statistics under task shift rather than acting as an arbitrary regularizer.
Authors: We agree that a formal justification is required. In the revised manuscript we will augment §3.2 with: (i) an explicit update equation for the rollback term, (ii) a first-order moment-matching derivation showing that the term minimizes the expected squared difference between upstream and downstream layer-wise means and variances, and (iii) a Lyapunov-style stability argument demonstrating that the layer-wise dynamic scaling bounds the second-moment shift under task distribution change. These additions will clarify that the mechanism is not an arbitrary regularizer but a targeted distributional consistency constraint. revision: yes
-
Referee: [§4] §4 (experiments): the abstract asserts 'state-of-the-art performance' and 'broad applicability' yet the provided text supplies neither quantitative tables, ablation studies on the rollback coefficient, nor error bars/comparisons against strong baselines such as L2-SP or EWC. Without these, the empirical support for the decoupling benefit cannot be evaluated.
Authors: The manuscript already contains quantitative results across four vision tasks, but we acknowledge the need for more explicit presentation. The revised §4 will include: full performance tables with metrics and direct comparisons to L2-SP, EWC, and other strong baselines; ablation plots varying the rollback coefficient with mean±std error bars over five random seeds; and a dedicated subsection quantifying the benefit of the decoupled formulation versus joint optimization. These additions will make the empirical claims fully evaluable. revision: yes
-
Referee: [§3.1] §3.1 (scratch training): the real-time layer-wise weight decay is described only at a high level; no derivation or convergence analysis is given that distinguishes it from conventional per-layer decay schedules already present in AdamW or SGD with momentum.
Authors: We will expand §3.1 with a derivation that highlights the real-time, update-dependent nature of the decay. Specifically, we will show that the decay coefficient at each step is computed from the instantaneous gradient magnitude and layer depth, leading to a modified convergence bound (via a time-varying Lyapunov function) that is tighter than the static per-layer schedules in AdamW or momentum SGD. This analysis will be added together with a short proof sketch. revision: yes
Circularity Check
No significant circularity: no derivations or equations present
full rationale
The paper introduces DualOpt by describing two heuristic techniques (real-time layer-wise weight decay for scratch training; a rollback term plus dynamic layer-wise adjustment for fine-tuning) and validates them via experiments on standard tasks. No equations, proofs, moment-matching arguments, or derivation chains appear in the provided text. Claims about distributional consistency or forgetting mitigation are stated as design motivations without analytical reduction to inputs. This is the common case of an empirical method paper whose central content is independent of any self-referential math.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Embracing large natural data: Enhancing medical image analysis via cross-domain fine-tuning,
Q. Li, X. Huang, B. Fang, H. Chen, S. Ding, and X. Liu, “Embracing large natural data: Enhancing medical image analysis via cross-domain fine-tuning,”IEEE Journal of Biomedical and Health Informatics, 2023
2023
-
[2]
One step learning, one step review,
X. Huang, Q. Li, X. Li, and X. Gao, “One step learning, one step review,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 11, 2024, pp. 12 644–12 652
2024
-
[3]
LAION-5B: An open large-scale dataset for training next generation image-text models
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5B: An open large-scale dataset for training next generation image-text models,”ArXiv Preprint arXiv:2210.08402, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
ImageNet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “ImageNet large scale visual recognition challenge,”International Journal of Computer Vision, vol. 115, pp. 211–252, 2015
2015
-
[5]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, “Laion-400M: Open dataset of clip-filtered 400 million image-text pairs,”ArXiv Preprint arXiv:2111.02114, 2021
work page internal anchor Pith review arXiv 2021
-
[6]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 8748–8763
2021
-
[7]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009
2022
-
[8]
BEiT: BERT Pre-Training of Image Transformers
H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,”ArXiv Preprint arXiv:2106.08254, 2021
work page internal anchor Pith review arXiv 2021
-
[9]
Factors of influence for transfer learning across diverse appearance domains and task types,
T. Mensink, J. Uijlings, A. Kuznetsova, M. Gygli, and V . Ferrari, “Factors of influence for transfer learning across diverse appearance domains and task types,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 9298–9314, 2022
2022
-
[10]
Building an open-vocabulary video clip model with better architectures, optimization and data,
Z. Wu, Z. Weng, W. Peng, X. Yang, A. Li, L. S. Davis, and Y .-G. Jiang, “Building an open-vocabulary video clip model with better architectures, optimization and data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 4747–4762, 2024
2024
-
[11]
Data-efficient masked video modeling for self-supervised action recognition,
Q. Li, X. Huang, Z. Wan, L. Hu, S. Wu, J. Zhang, S. Shan, and Z. Wang, “Data-efficient masked video modeling for self-supervised action recognition,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 2723–2733
2023
-
[12]
Advancing micro-action recognition with multi-auxiliary heads and hybrid loss optimization,
Q. Li, X. Huang, H. Chen, F. He, Q. Chen, and Z. Wang, “Advancing micro-action recognition with multi-auxiliary heads and hybrid loss optimization,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024
2024
-
[13]
Rhythm- former: Extracting patterned rppg signals based on periodic sparse attention,
B. Zou, Z. Guo, J. Chen, J. Zhuo, W. Huang, and H. Ma, “Rhythm- former: Extracting patterned rppg signals based on periodic sparse attention,”Pattern Recognition, vol. 164, p. 111511, 2025
2025
-
[14]
Recognizing object by components with human prior knowledge enhances adversarial robust- ness of deep neural networks,
X. Li, Z. Wang, B. Zhang, F. Sun, and X. Hu, “Recognizing object by components with human prior knowledge enhances adversarial robust- ness of deep neural networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 7, pp. 8861–8873, 2023
2023
-
[15]
Medical image segmentation review: The success of u-net,
R. Azad, E. K. Aghdam, A. Rauland, Y . Jia, A. H. Avval, A. Bozorgpour, S. Karimijafarbigloo, J. P. Cohen, E. Adeli, and D. Merhof, “Medical image segmentation review: The success of u-net,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[16]
Positive-negative momen- tum: Manipulating stochastic gradient noise to improve generalization,
Z. Xie, L. Yuan, Z. Zhu, and M. Sugiyama, “Positive-negative momen- tum: Manipulating stochastic gradient noise to improve generalization,” inProc. International Conference on Machine Learning, 2021, pp. 11 448–11 458
2021
-
[17]
Rotational equilibrium: How weight decay balances learning across neural networks, 2024
A. Kosson, B. Messmer, and M. Jaggi, “Rotational equilibrium: How weight decay balances learning across neural networks,” 2024. [Online]. Available: https://arxiv.org/abs/2305.17212
-
[18]
Comparing biases for minimal network construction with back-propagation,
S. Hanson and L. Pratt, “Comparing biases for minimal network construction with back-propagation,” vol. 1, 1988
1988
-
[19]
Improving robustness with adaptive weight decay,
M. A. Ghiasi, A. Shafahi, and R. Ardekani, “Improving robustness with adaptive weight decay,”Proc. Neural Information Processing System, vol. 36, 2024
2024
-
[20]
A continual learning survey: Defying forgetting in classification tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 3366–3385, 2021. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XX, NO. XX,...
2021
-
[21]
Improving generalization performance by switching from Adam to SGD,
N. S. Keskar and R. Socher, “Improving generalization performance by switching from adam to sgd,”ArXiv Preprint arXiv:1712.07628, 2017
-
[22]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
T. Ergen, H. I. Gulluk, J. Lacotte, and M. Pilanci, “Globally optimal training of neural networks with threshold activation functions,” 2023. [Online]. Available: https://arxiv.org/abs/2303.03382
-
[24]
Equi-normalization of neural networks,
P. Stock, B. Graham, R. Gribonval, and H. J ´egou, “Equi-normalization of neural networks,” 2019. [Online]. Available: https://arxiv.org/abs/ 1902.10416
-
[25]
Learning repre- sentations by back-propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning repre- sentations by back-propagating errors,”nature, vol. 323, no. 6088, pp. 533–536, 1986
1986
-
[26]
Adaptive subgradient methods for online learning and stochastic optimization
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization.”Journal of Machine Learning Research, vol. 12, no. 7, 2011
2011
-
[27]
A simple weight decay can improve general- ization,
A. Krogh and J. Hertz, “A simple weight decay can improve general- ization,”Advances in Neural Information Processing Systems, vol. 4, 1991
1991
-
[28]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision. Springer, 2020, pp. 213– 229
2020
-
[29]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” ArXiv Preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Weight prediction boosts the convergence of adamw,
L. Guan, “Weight prediction boosts the convergence of adamw,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2023, pp. 329–340
2023
-
[31]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010
2017
-
[32]
Expe- rience replay for continual learning,
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne, “Expe- rience replay for continual learning,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[33]
Generative feature replay for class- incremental learning,
X. Liu, C. Wu, M. Menta, L. Herranz, B. Raducanu, A. D. Bagdanov, S. Jui, and J. v. de Weijer, “Generative feature replay for class- incremental learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 226– 227
2020
-
[34]
Practical recommendations for replay-based continual learning methods,
G. Merlin, V . Lomonaco, A. Cossu, A. Carta, and D. Bacciu, “Practical recommendations for replay-based continual learning methods,” inIn- ternational Conference on Image Analysis and Processing. Springer, 2022, pp. 548–559
2022
-
[35]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,”Pro- ceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[36]
Explicit inductive bias for transfer learning with convolutional networks,
L. Xuhong, Y . Grandvalet, and F. Davoine, “Explicit inductive bias for transfer learning with convolutional networks,” inInternational Conference on Machine Learning. PMLR, 2018, pp. 2825–2834
2018
-
[37]
Visual prompt tuning,
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 709–727
2022
-
[38]
Visual prompt tuning for generative transfer learning,
K. Sohn, H. Chang, J. Lezama, L. Polania, H. Zhang, Y . Hao, I. Essa, and L. Jiang, “Visual prompt tuning for generative transfer learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 840–19 851
2023
-
[39]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[40]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng, “Reading digits in natural images with unsupervised feature learning,” 2011
2011
-
[41]
The caltech-ucsd birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” 2011
2011
-
[42]
3D object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3D object representations for fine-grained categorization,” inProceedings of the IEEE Interna- tional Conference on Computer Vision Workshops, 2013, pp. 554–561
2013
-
[43]
Learning deep features for scene recognition using places database,
B. Zhou, A. Lapedriza, J. Xiao, A. Torralba, and A. Oliva, “Learning deep features for scene recognition using places database,”Advances in Neural Information Processing Systems, vol. 27, 2014
2014
-
[44]
The sun attribute database: Be- yond categories for deeper scene understanding,
G. Patterson, C. Xu, H. Su, and J. Hays, “The sun attribute database: Be- yond categories for deeper scene understanding,”International Journal of Computer Vision, vol. 108, pp. 59–81, 2014
2014
-
[45]
Deep hashing network for unsupervised domain adaptation,
H. Venkateswara, J. Eusebio, S. Chakraborty, and S. Panchanathan, “Deep hashing network for unsupervised domain adaptation,” inPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5018–5027
2017
-
[46]
Deeper, broader and artier domain generalization,
D. Li, Y . Yang, Y .-Z. Song, and T. M. Hospedales, “Deeper, broader and artier domain generalization,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5542–5550
2017
-
[47]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755
2014
-
[48]
Semantic understanding of scenes through the ade20k dataset,
B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba, “Semantic understanding of scenes through the ade20k dataset,”International Journal of Computer Vision, vol. 127, pp. 302– 321, 2019
2019
-
[49]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[50]
Language Models are Few-Shot Learners
T. B. Brown, “Language models are few-shot learners,”arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review arXiv 2005
-
[51]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[52]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikovet al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,”International journal of computer vision, vol. 128, no. 7, pp. 1956–1981, 2020
1956
- [53]
-
[54]
and Salakhutdinov, Ruslan and Urtasun, Raquel and Torralba, Antonio and Fidler, Sanja , year =
Y . Zhu, “Aligning books and movies: Towards story-like visual ex- planations by watching movies and reading books,”arXiv preprint arXiv:1506.06724, 2015
-
[55]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[57]
Rhythmmamba: Fast, lightweight, and accurate remote physiological measurement,
B. Zou, Z. Guo, X. Hu, and H. Ma, “Rhythmmamba: Fast, lightweight, and accurate remote physiological measurement,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 11 077–11 085
2025
-
[58]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review arXiv 2021
-
[59]
Incremental classifier learning with generative adversarial networks,
Y . Wu, Y . Chen, L. Wang, Y . Ye, Z. Liu, Y . Guo, Z. Zhang, and Y . Fu, “Incremental classifier learning with generative adversarial networks,” arXiv preprint arXiv:1802.00853, 2018
-
[60]
Y . Hsu, “Re-evaluating continual learning scenarios: A categorization and case for strong baselines,”arXiv preprint arXiv:1810.12488, 2018
-
[61]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inInternational conference on machine learning. PMLR, 2017, pp. 3987–3995
2017
-
[62]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935– 2947, 2017
2017
-
[63]
Encoder based lifelong learning,
A. Rannen, R. Aljundi, M. B. Blaschko, and T. Tuytelaars, “Encoder based lifelong learning,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1320–1328
2017
-
[64]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 2790–2799
2019
-
[65]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[66]
AdapterFusion: Non-Destructive Task Composition for Transfer Learning , journal =
J. Pfeiffer, A. Kamath, A. R ¨uckl´e, K. Cho, and I. Gurevych, “Adapter- fusion: Non-destructive task composition for transfer learning,”arXiv preprint arXiv:2005.00247, 2020
-
[67]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”The Annals of Mathematical Statistics, pp. 400–407, 1951. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XX, NO. XX, MONTH 202X 14
1951
-
[68]
On the importance of initialization and momentum in deep learning,
I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” inInternational Conference on Machine Learning. PMLR, 2013, pp. 1139–1147
2013
-
[69]
On the variance of the adaptive learning rate and beyond
L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han, “On the variance of the adaptive learning rate and beyond,”arXiv preprint arXiv:1908.03265, 2019
-
[70]
Adaptive gradient methods with dynamic bound of learning rate,
L. Luo, Y . Xiong, Y . Liu, and X. Sun, “Adaptive gradient methods with dynamic bound of learning rate,”arXiv preprint arXiv:1902.09843, 2019
-
[71]
Rethinking weight decay for robust fine-tuning of foundation models,
J. Tian, C. Huang, and Z. Kira, “Rethinking weight decay for robust fine-tuning of foundation models,”Advances in Neural Information Processing Systems, vol. 37, pp. 22 418–22 440, 2024
2024
-
[72]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117–2125
2017
-
[73]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[74]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1–9
2015
-
[75]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 976–11 986
2022
-
[76]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”ArXiv Preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[77]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition. Ieee, 2009, pp. 248–255
2009
-
[78]
Split-brain autoencoders: Unsu- pervised learning by cross-channel prediction,
R. Zhang, P. Isola, and A. A. Efros, “Split-brain autoencoders: Unsu- pervised learning by cross-channel prediction,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1058–1067. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. XX, NO. XX, MONTH 202X 15 Xin Ning(Senior Member, IEEE) received the...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.