Recognition: unknown
EX-FIQA: Leveraging Intermediate Early eXit Representations from Vision Transformers for Face Image Quality Assessment
Pith reviewed 2026-05-10 02:58 UTC · model grok-4.3
The pith
Fusing quality scores from multiple depths of a vision transformer outperforms using only the final layer for face image quality assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
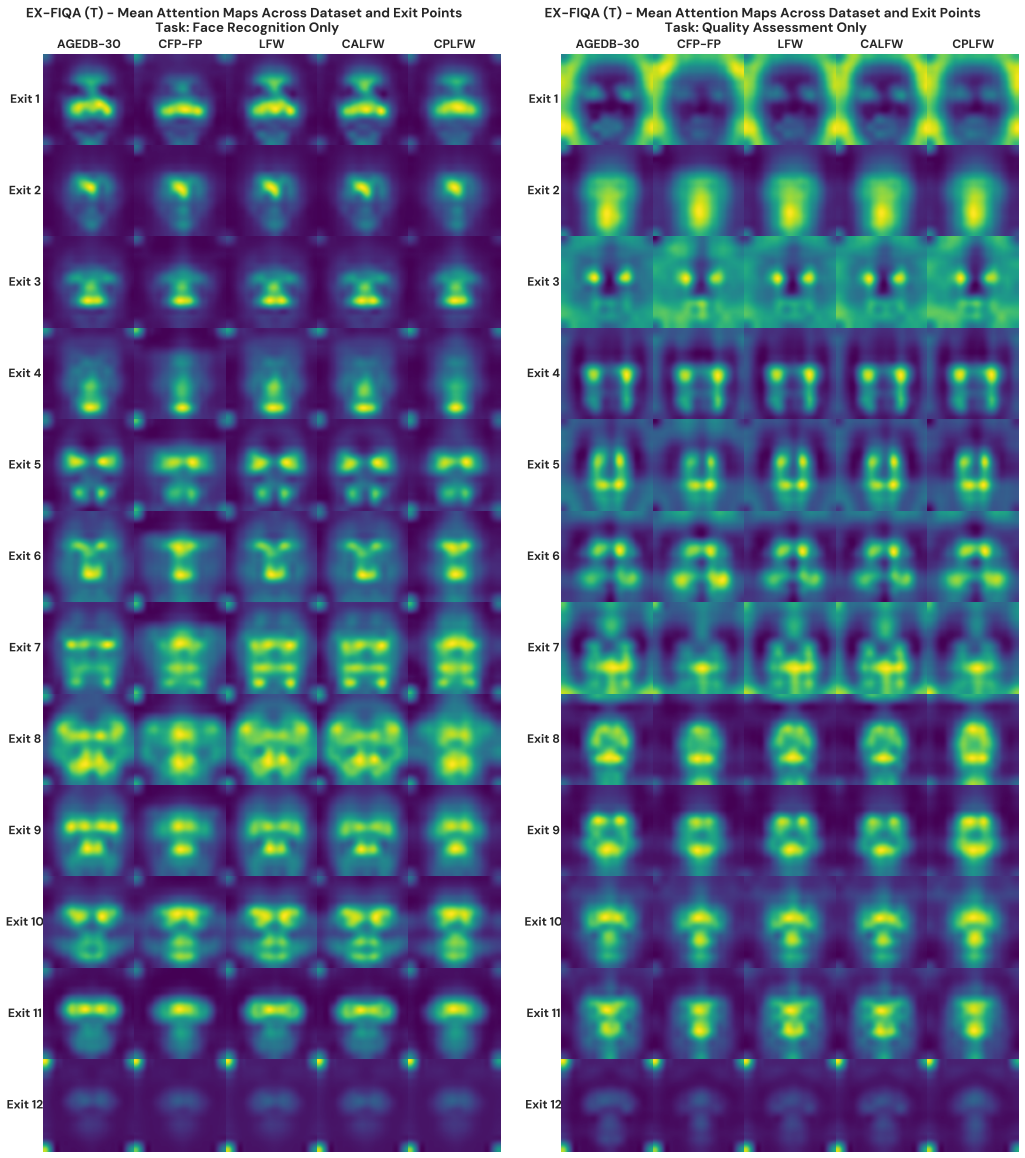
By examining every transformer block in ViT-FIQA models, the work establishes that intermediate representations contain distinct and complementary quality-relevant signals. A depth-weighted averaging fusion that combines predictions from multiple blocks, assigning higher importance to deeper layers, delivers the strongest assessment performance across datasets and face recognition backbones. Early-exit analysis further shows that competitive results can be reached with far fewer layers, confirming that hierarchical feature learning in transformers can be leveraged directly for quality assessment without extra training.
What carries the argument
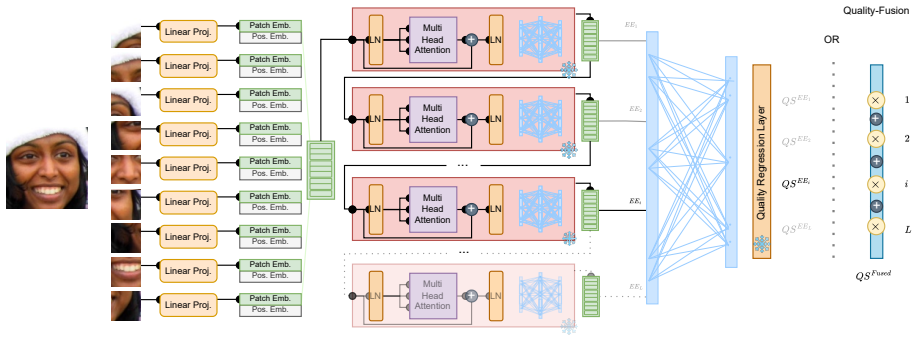
Depth-weighted averaging of quality scores from all twelve transformer blocks, combined with early-exit options.
If this is right
- Quality assessment accuracy rises when predictions from several layers are combined rather than taken from the final block alone.
- Early exits from intermediate blocks enable substantial compute savings while preserving competitive quality scores.
- No architectural modifications or additional training are required to realize the gains from multi-depth fusion.
- The hierarchical structure of vision transformers can be exploited for face analysis tasks by treating intermediate representations as informative rather than discarding them.
Where Pith is reading between the lines
- The same multi-depth fusion idea could be tested on other vision tasks where quality or uncertainty varies by layer depth.
- In mobile or edge biometric deployments, learned or adaptive fusion weights might further improve the performance-efficiency curve beyond the fixed depth-weighted scheme.
- Attention map differences across layers suggest that quality defects such as blur or occlusion may be more detectable at specific depths, opening a route to defect-specific diagnostics.
Load-bearing premise
Different depths of the transformer capture distinct and complementary information that is relevant to face image quality.
What would settle it
A direct test on any of the eight benchmarks where the fused multi-depth score fails to exceed the single best single-block score would disprove the central performance claim.
Figures











read the original abstract
Face Image Quality Assessment is crucial for reliable face recognition systems, yet existing Vision Transformer-based approaches rely exclusively on final-layer representations, ignoring quality-relevant information captured at intermediate network depths. This paper presents the first comprehensive investigation of how intermediate representations within ViTs contribute to face quality assessment through early exit mechanisms and score fusion strategies. We systematically analyze all twelve transformer blocks of ViT-FIQA architectures, demonstrating that different depths capture distinct and complementary quality-relevant information, as evidenced by varying attention patterns and performance characteristics across network layers. We propose a score fusion framework that combines quality predictions from multiple transformer blocks without architectural modifications or additional training. Our early exit analysis reveals optimal performance-efficiency trade-offs, enabling significant computational savings while maintaining competitive performance. Through extensive evaluation across eight benchmark datasets using four FR models, we demonstrate that our fusion strategy improves upon single-exit approaches. Our proposed quality fusion approach employs depth-weighted averaging that assigns progressively higher importance to deeper transformer blocks, achieving the best quality assessment performance by effectively leveraging the hierarchical nature of feature learning in ViTs. Our work challenges the conventional wisdom that only deep features matter for face analysis, revealing that intermediate representations contain valuable information for quality assessment. The proposed framework offers practical benefits for real-world biometric systems by enabling adaptive computation based on resource constraints while maintaining competitive quality assessment capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EX-FIQA, the first systematic study of intermediate-layer early exits in Vision Transformers for face image quality assessment (FIQA). It examines all twelve transformer blocks of ViT-FIQA models, reports that different depths yield distinct attention patterns and quality-prediction performance, and introduces a training-free score-fusion framework that combines per-block predictions. The central technical contribution is a depth-weighted averaging scheme that assigns progressively higher weights to deeper blocks; the authors claim this exploits the hierarchical nature of ViT feature learning and yields the best FIQA results across eight benchmark datasets and four face-recognition backbones while also enabling early-exit efficiency trade-offs.
Significance. If the reported gains are robust, the work would usefully challenge the default practice of using only final-layer ViT embeddings for FIQA and would supply a practical, zero-training-cost method for trading accuracy against compute in biometric pipelines. The emphasis on complementary information across depths and the provision of early-exit analysis are potentially valuable for resource-constrained deployments.
major comments (2)
- [Experiments / fusion results] Experiments / fusion results: The manuscript asserts that depth-weighted averaging (progressively higher weights for deeper blocks) achieves the best performance by leveraging hierarchical feature learning. However, no ablation is presented that directly compares this scheme against uniform averaging of the twelve block scores, against max-pooling, or against a simple learned linear combination. Without such controls, it is impossible to determine whether the observed improvement stems from the specific increasing-depth weighting or merely from fusing multiple layers; this directly affects the load-bearing claim in the abstract and §4.
- [§4.2] §4.2 / early-exit analysis: The paper states that different depths capture complementary quality-relevant information, supported by “varying attention patterns and performance characteristics.” The quantitative evidence for complementarity (e.g., pairwise correlation of per-block quality scores or incremental gain when adding each layer) is not reported; only aggregate fusion numbers are given. This weakens the justification for the fusion framework itself.
minor comments (2)
- [Method] The exact functional form of the depth-weighted averaging (the sequence of weights w_d for d = 1…12) should be stated explicitly, preferably as an equation, rather than described only qualitatively as “progressively higher importance.”
- [Figures / Tables] Table captions and axis labels in the performance plots should indicate the precise fusion variant (depth-weighted vs. other) and the number of blocks used for each early-exit point.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [Experiments / fusion results] Experiments / fusion results: The manuscript asserts that depth-weighted averaging (progressively higher weights for deeper blocks) achieves the best performance by leveraging hierarchical feature learning. However, no ablation is presented that directly compares this scheme against uniform averaging of the twelve block scores, against max-pooling, or against a simple learned linear combination. Without such controls, it is impossible to determine whether the observed improvement stems from the specific increasing-depth weighting or merely from fusing multiple layers; this directly affects the load-bearing claim in the abstract and §4.
Authors: We agree that the absence of these specific controls limits the strength of the claim that the depth-weighted scheme is superior due to its exploitation of hierarchy rather than fusion in general. While the current manuscript shows that the proposed weighting outperforms single-block baselines and is motivated by observed performance trends across depths, we did not report direct comparisons to uniform averaging, max-pooling, or a learned linear combination. In the revised version we will add these ablations on the same eight datasets and four backbones, reporting the full set of results to isolate the contribution of the increasing-depth weighting. revision: yes
-
Referee: [§4.2] §4.2 / early-exit analysis: The paper states that different depths capture complementary quality-relevant information, supported by “varying attention patterns and performance characteristics.” The quantitative evidence for complementarity (e.g., pairwise correlation of per-block quality scores or incremental gain when adding each layer) is not reported; only aggregate fusion numbers are given. This weakens the justification for the fusion framework itself.
Authors: The manuscript supports the complementarity claim via layer-specific attention visualizations and distinct per-block performance numbers, which indicate that intermediate representations are not redundant. However, we did not provide explicit quantitative measures such as pairwise score correlations or incremental gains from cumulative fusion. We will add these analyses to §4.2 in the revision, including correlation matrices across the twelve blocks and step-wise fusion ablations, to give stronger empirical grounding for the fusion framework. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmark evaluations.
full rationale
The paper's core contribution is an empirical analysis of intermediate ViT blocks for face image quality assessment, followed by a proposed score fusion strategy using depth-weighted averaging. No mathematical derivation chain is presented that reduces a claimed result to its own inputs by construction. The depth-weighted scheme is described as a fixed heuristic that assigns higher weights to deeper blocks, with performance gains asserted via evaluation on eight datasets rather than by fitting parameters to the target metric and relabeling them as predictions. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are referenced in the abstract or described claims. The work is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Atzori, F
A. Atzori, F. Boutros, and N. Damer. Vit-fiqa: Assessing face image quality using vision transformers. In2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2025
2025
- [2]
-
[3]
Babnik, P
Z. Babnik, P. Peer, and V . Struc. Faceqan: Face image quality assessment through adversarial noise exploration. In2022 26th International Conference on Pattern Recognition (ICPR), pages 748– 754, 2022
2022
-
[4]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. Diffiqa: Face image quality assessment using denoising diffusion probabilistic models. In2023 IEEE International Joint Conference on Biometrics (IJCB), pages 1– 10, 2023
2023
-
[5]
Babnik, P
ˇZ. Babnik, P. Peer, and V . ˇStruc. eDifFIQA: Towards Efficient Face Image Quality Assessment based on Denoising Diffusion Probabilistic Models.IEEE Transactions on Biometrics, Behavior, and Identity Science (TBIOM), 2024
2024
-
[6]
Bakhtiarnia, Q
A. Bakhtiarnia, Q. Zhang, and A. Iosifidis. Multi-exit vision trans- former for dynamic inference. InBMVC, page 81. BMV A Press, 2021
2021
-
[7]
Bakhtiarnia, Q
A. Bakhtiarnia, Q. Zhang, and A. Iosifidis. Single-layer vision transformers for more accurate early exits with less overhead.Neural Networks, 153:461–473, 2022
2022
-
[8]
Best-Rowden and A
L. Best-Rowden and A. K. Jain. Learning face image quality from human assessments.IEEE Trans. Inf. Forensics Secur., 13(12):3064– 3077, 2018
2018
-
[9]
Bosse, D
S. Bosse, D. Maniry, K. M ¨uller, T. Wiegand, and W. Samek. Deep neural networks for no-reference and full-reference image quality assessment.IEEE Trans. Image Process., 27(1):206–219, 2018
2018
-
[10]
Boutros, N
F. Boutros, N. Damer, F. Kirchbuchner, and A. Kuijper. Elasticface: Elastic margin loss for deep face recognition. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, pages 1577–1586. IEEE, 2022
2022
-
[11]
Boutros, M
F. Boutros, M. Fang, M. Klemt, B. Fu, and N. Damer. CR-FIQA: face image quality assessment by learning sample relative classifiability. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 5836–
2023
-
[12]
Carion, F
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. In A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, editors,Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part I, volume 12346 ofLecture Notes in Computer Science, pages 213–229. ...
2020
-
[13]
J. Chen, Y . Deng, G. Bai, and G. Su. Face image quality assessment based on learning to rank.IEEE Signal Process. Lett., 22(1):90–94, 2015
2015
-
[14]
Chettaoui, N
T. Chettaoui, N. Damer, and F. Boutros. Froundation: Are foundation models ready for face recognition?Image Vis. Comput., 156:105453, 2025
2025
-
[15]
Z. Dai, B. Cai, Y . Lin, and J. Chen. UP-DETR: unsupervised pre- training for object detection with transformers. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 1601–1610. Computer Vision Foundation / IEEE, 2021
2021
-
[16]
J. Dan, Y . Liu, H. Xie, J. Deng, H. Xie, X. Xie, and B. Sun. Transface: Calibrating transformer training for face recognition from a data- centric perspective. InICCV, pages 20585–20596, 2023
2023
-
[17]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 4690–4699. Computer Vision Foundation / IEEE, 2019
2019
-
[18]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview....
2021
-
[19]
Eidinger, R
E. Eidinger, R. Enbar, and T. Hassner. Age and gender estimation of unfiltered faces.IEEE Trans. Inf. Forensics Secur., 9(12):2170–2179, 2014
2014
-
[20]
Best practice technical guidelines for automated border control (abc) systems, 2015
Frontex. Best practice technical guidelines for automated border control (abc) systems, 2015
2015
-
[21]
B. Fu, C. Chen, O. Henniger, and N. Damer. A deep insight into measuring face image utility with general and face-specific image quality metrics. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022, pages 1121–1130. IEEE, 2022
2022
-
[22]
Grother, M
P. Grother, M. N. A. Hom, and K. Hanaoka. Ongoing face recognition vendor test (frvt) part 5: Face image quality assessment (4th draft). InNational Institute of Standards and Technology. Tech. Rep., Sep. 2021
2021
-
[23]
Grother and E
P. Grother and E. Tabassi. Performance of biometric quality measures. IEEE Trans. on Pattern Analysis and Machine Intelligence, 29(4):531– 543, Apr. 2007
2007
-
[24]
Y . Han, G. Huang, S. Song, L. Yang, H. Wang, and Y . Wang. Dynamic neural networks: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 44(11):7436–7456, 2022
2022
-
[25]
Biometric quality: Re- view and application to face recognition with face- qnet
J. Hernandez-Ortega, J. Galbally, J. Fi ´errez, and L. Beslay. Biometric quality: Review and application to face recognition with faceqnet. CoRR, abs/2006.03298, 2020
-
[26]
Hernandez-Ortega, J
J. Hernandez-Ortega, J. Galbally, J. Fi ´errez, R. Haraksim, and L. Beslay. Faceqnet: Quality assessment for face recognition based on deep learning. In2019 International Conference on Biometrics, ICB 2019, Crete, Greece, June 4-7, 2019, pages 1–8. IEEE, 2019
2019
-
[27]
G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. La- beled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007
2007
-
[28]
Huang, Y
Y . Huang, Y . Wang, Y . Tai, X. Liu, P. Shen, S. Li, J. Li, and F. Huang. Curricularface: Adaptive curriculum learning loss for deep face recognition. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 5900–5909. Computer Vision Foundation / IEEE, 2020
2020
-
[29]
D. A. Hudson and L. Zitnick. Generative adversarial transformers. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceedings of Machine Learning Research, pages 4487–4499. PMLR, 2021
2021
-
[30]
ISO/IEC 19795-1:2021 Information technology — Biometric performance testing and reporting — Part 1: Principles and framework
ISO/IEC JTC1 SC37 Biometrics. ISO/IEC 19795-1:2021 Information technology — Biometric performance testing and reporting — Part 1: Principles and framework. International Organization for Standardiza- tion, 2021
2021
-
[31]
M. Kim, Y . Su, F. Liu, A. Jain, and X. Liu. Keypoint relative position encoding for face recognition. InCVPR, pages 244–255. IEEE, 2024
2024
-
[32]
Knoche, S
M. Knoche, S. H ¨ormann, and G. Rigoll. Cross-quality LFW: A database for analyzing cross- resolution image face recognition in unconstrained environments. In16th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2021, Jodhpur, India, December 15-18, 2021, pages 1–5. IEEE, 2021
2021
-
[33]
J. N. Kolf, N. Damer, and F. Boutros. Grafiqs: Face image quality assessment using gradient magnitudes. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1490–1499, 2024
2024
-
[34]
Lecun, L
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[35]
C. Li, Y . Qiang, R. I. Sultan, H. Bagher-Ebadian, P. Khanduri, I. J. Chetty, and D. Zhu. Focalunetr: A focal transformer for boundary- aware prostate segmentation using CT images. In H. Greenspan, A. Madabhushi, P. Mousavi, S. E. Salcudean, J. Duncan, T. F. Syeda- Mahmood, and R. H. Taylor, editors,Medical Image Computing and Computer Assisted Interventi...
2023
-
[36]
X. Liu, J. van de Weijer, and A. D. Bagdanov. Rankiqa: Learning from rankings for no-reference image quality assessment. InIEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 1040–1049. IEEE Computer Society, 2017
2017
-
[37]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10- 17, 2021, pages 9992–10002. IEEE, 2021
2021
-
[38]
Matsubara, M
Y . Matsubara, M. Levorato, and F. Restuccia. Split computing and early exiting for deep learning applications: Survey and research challenges.ACM Comput. Surv., 55(5):90:1–90:30, 2023
2023
-
[39]
B. Maze, J. C. Adams, J. A. Duncan, N. D. Kalka, T. Miller, C. Otto, A. K. Jain, W. T. Niggel, J. Anderson, J. Cheney, and 9 P. Grother. IARPA janus benchmark - C: face dataset and protocol. In 2018 International Conference on Biometrics, ICB 2018, Gold Coast, Australia, February 20-23, 2018, pages 158–165. IEEE, 2018
2018
-
[40]
Q. Meng, S. Zhao, Z. Huang, and F. Zhou. Magface: A universal representation for face recognition and quality assessment. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 14225–14234. Computer Vision Foundation / IEEE, 2021
2021
-
[41]
Mittal, A
A. Mittal, A. K. Moorthy, and A. C. Bovik. No-reference image quality assessment in the spatial domain.IEEE Trans. Image Process., 21(12):4695–4708, 2012
2012
-
[42]
Mittal, R
A. Mittal, R. Soundararajan, and A. C. Bovik. Making a ”completely blind” image quality analyzer.IEEE Signal Process. Lett., 20(3):209– 212, 2013
2013
-
[43]
Moschoglou, A
S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. Agedb: The first manually collected, in-the-wild age database. In2017 IEEE CVPRW, CVPR Workshops 2017, Honolulu, HI, USA, July 21-26, 2017, pages 1997–2005. IEEE Computer Society, 2017
2017
-
[44]
Nixon, P
S. Nixon, P. Ruiu, M. Cadoni, A. Lagorio, and M. Tistarelli. Exploiting face recognizability with early exit vision transformers. In2023 International Conference of the Biometrics Special Interest Group (BIOSIG), pages 1–7, 2023
2023
-
[45]
F. Ou, X. Chen, R. Zhang, Y . Huang, S. Li, J. Li, Y . Li, L. Cao, and Y . Wang. SDD-FIQA: unsupervised face image quality assessment with similarity distribution distance. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 7670–7679. Computer Vision Foundation / IEEE, 2021
2021
-
[46]
F.-Z. Ou, C. Li, S. Wang, and S. Kwong. Clib-fiqa: Face image quality assessment with confidence calibration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1694–1704, 2024
2024
-
[47]
F.-Z. Ou, C. Li, S. Wang, and S. Kwong. Mr-fiqa: Face image quality assessment with multi-reference representations from synthetic data generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12915–12925, October 2025
2025
-
[48]
Ozgur, E
G. Ozgur, E. Caldeira, T. Chettaoui, J. N. Kolf, M. Huber, N. Damer, and F. Boutros. Vitnt-fiqa: Training-free face image quality assessment with vision transformers. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, pages 1203–1213, March 2026
2026
-
[49]
Phuong and C
M. Phuong and C. Lampert. Distillation-based training for multi- exit architectures. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 1355–1364. IEEE, 2019
2019
-
[50]
L. Qin, M. Wang, C. Deng, K. Wang, X. Chen, J. Hu, and W. Deng. Swinface: A multi-task transformer for face recognition, expression recognition, age estimation and attribute estimation.IEEE Trans. Circuits Syst. Video Technol., 34(4):2223–2234, 2024
2024
-
[51]
Raghu, T
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy. Do vision transformers see like convolutional neural networks? In M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Decembe...
2021
-
[52]
Schlett, C
T. Schlett, C. Rathgeb, O. Henniger, J. Galbally, J. Fi ´errez, and C. Busch. Face image quality assessment: A literature survey.ACM Comput. Surv., 54(10s):210:1–210:49, 2022
2022
-
[53]
Schlett, C
T. Schlett, C. Rathgeb, J. E. Tapia, and C. Busch. Considerations on the evaluation of biometric quality assessment algorithms.IEEE Trans. Biom. Behav. Identity Sci., 6(1):54–67, 2024
2024
-
[54]
Sengupta, J
S. Sengupta, J. Chen, C. D. Castillo, V . M. Patel, R. Chellappa, and D. W. Jacobs. Frontal to profile face verification in the wild. In2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, March 7-10, 2016, pages 1–9. IEEE Computer Society, 2016
2016
-
[55]
Shi and A
Y . Shi and A. K. Jain. Probabilistic face embeddings. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 6901–
2019
-
[56]
Strudel, R
R. Strudel, R. Garcia, I. Laptev, and C. Schmid. Segmenter: Trans- former for semantic segmentation. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 7242–7252. IEEE, 2021
2021
-
[57]
Teerapittayanon, B
S. Teerapittayanon, B. McDanel, and H. T. Kung. Branchynet: Fast inference via early exiting from deep neural networks. In23rd International Conference on Pattern Recognition, ICPR 2016, Canc´un, Mexico, December 4-8, 2016, pages 2464–2469. IEEE, 2016
2016
-
[58]
Terh ¨orst, J
P. Terh ¨orst, J. N. Kolf, N. Damer, F. Kirchbuchner, and A. Kuijper. SER-FIQ: unsupervised estimation of face image quality based on stochastic embedding robustness. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 5650–5659. Computer Vision Foundation / IEEE, 2020
2020
-
[59]
Touvron, M
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou. Training data-efficient image transformers & distillation through attention. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceedings of Machine Learning Research, page...
2021
-
[60]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2...
2017
-
[61]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.CoRR, abs/1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[62]
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 5265–5274. IEEE Computer Society, 2018
2018
-
[63]
J. Xin, R. Tang, Y . Yu, and J. Lin. Berxit: Early exiting for BERT with better fine-tuning and extension to regression. In P. Merlo, J. Tiedemann, and R. Tsarfaty, editors,Proceedings of the 16th Con- ference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pages 91–104. Associ...
2021
-
[64]
G. Xu, J. Hao, L. Shen, H. Hu, Y . Luo, H. Lin, and J. Shen. Lgvit: Dynamic early exiting for accelerating vision transformer. In A. El- Saddik, T. Mei, R. Cucchiara, M. Bertini, D. P. T. Vallejo, P. K. Atrey, and M. S. Hossain, editors,Proceedings of the 31st ACM International Conference on Multimedia, MM 2023, Ottawa, ON, Canada, 29 October 2023- 3 Nove...
2023
-
[65]
Zheng and W
T. Zheng and W. Deng. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications, February 2018
2018
-
[66]
Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments
T. Zheng, W. Deng, and J. Hu. Cross-age LFW: A database for studying cross-age face recognition in unconstrained environments. CoRR, abs/1708.08197, 2017. 10 APPENDIX This supplementary material provides comprehensive ex- perimental results and detailed analysis of theEX-FIQA method for face image quality assessment. The supple- mentary material is struct...
work page Pith review arXiv 2017
-
[67]
[43] [54] [27] [66] [65] [32] [39] 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 1e−3 1e−4 ArcFace[17] IQA BRISQUE[41] 0.0565 0.1285 0.0400 0.0585 0.0343 0.0433 0.0043 0.0049 0.0755 0.0813 0.2558 0.3037 0.6680 0.7122 0.0381 0.0656 RankIQA[36] 0.0400 0.0933 0.0372 0.0523 0.0301 0.0384 0.0039 0.0045 0.0846 0.0915 0.2437 0.2969 0.6584...
-
[68]
The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines
FR models. The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines. 21 0.00 0.2 0.4 0.6 XQLFW ArcFace ElasticFace MagFace CurricularFace 0.00 0.02 0.04 0.06Adience 0.00 0.02 0.04AgeDB-30 0.00 0.05 0.1 CALFW 0.00 0.02 0.04CFP-FP 0.00 0.1 0.2 CPLFW 0.00 0.00 0.00 0.01 LFW 0 0.4 0.8 0.00 0.01 0.02 0.03IJB-C 0 0.4 0.8 0 0.4 0.8 0 0.4 0....
-
[69]
The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines
FR models. The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines. 22 0.00 0.2 0.5 0.8 XQLFW ArcFace ElasticFace MagFace CurricularFace 0.00 0.05 0.1 0.2 Adience 0.00 0.02 0.04 0.06AgeDB-30 0.00 0.05 0.1 CALFW 0.00 0.02 0.04 0.06CFP-FP 0.00 0.1 0.2 0.3 CPLFW 0.00 0.00 0.00 0.01 LFW 0 0.4 0.8 0.00 0.02 0.04IJB-C 0 0.4 0.8 0 0.4 0.8 ...
-
[70]
The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines
FR models. The best exits,EX-FIQAand proposed fusionEX-FIQA-FWare marked with solid lines. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.