Recognition: unknown
Structure Guided Retrieval-Augmented Generation for Factual Queries
Pith reviewed 2026-05-10 01:47 UTC · model grok-4.3
The pith
Modeling retrieval as subgraph matching lets RAG systems ensure large language models meet every condition in factual queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
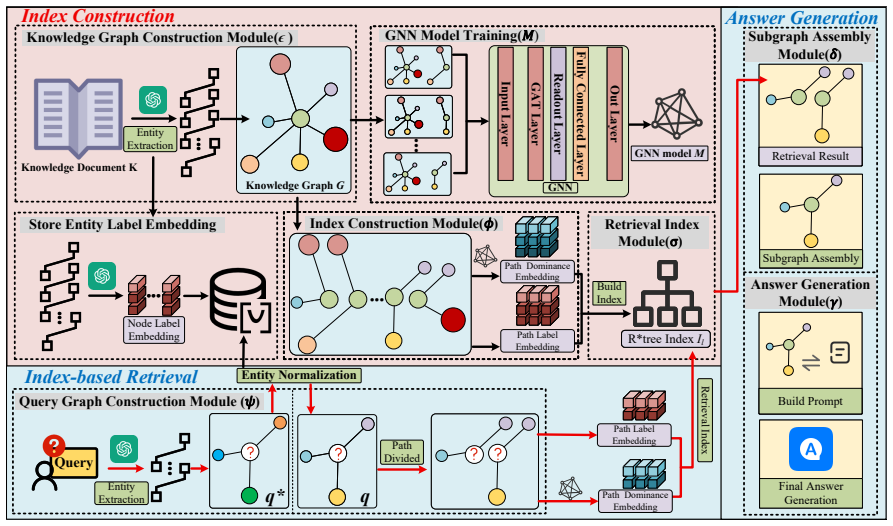
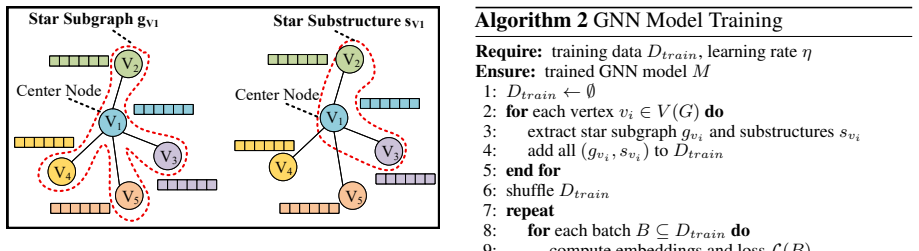
The paper claims that by modeling the retrieval process as an embedding-based subgraph matching task and using the retrieved topological structures to guide the LLM, SG-RAG produces answers that meet all specified conditions in factual queries. This is supported by the construction of the ERQA dataset containing 120000 QA pairs with complex conditions across 20 domains and by experimental results showing consistent large improvements over baselines while keeping computational overhead reasonable.
What carries the argument
Embedding-based subgraph matching on retrieved topological structures, which identifies and supplies the exact structural patterns needed to enforce every condition during LLM generation.
If this is right
- Factual queries containing several interlocking conditions receive more complete answers from LLMs.
- The Exact Retrieval Problem supplies a concrete evaluation target for measuring whether retrieved information satisfies all query requirements.
- Performance lifts of 20 to 50 points across metrics are achieved without unreasonable increases in compute.
- RAG pipelines can shift from purely semantic retrieval toward structure-aware methods for higher precision on factual tasks.
- The released ERQA dataset becomes a public benchmark for testing exact condition adherence in question answering.
Where Pith is reading between the lines
- The same structure-guided approach could be tested on multi-hop factual questions where conditions span several linked facts.
- Replacing embedding similarity with stricter graph isomorphism checks might further reduce residual errors on edge-case queries.
- Domains such as legal or medical reasoning, which demand precise satisfaction of multiple constraints, stand to benefit most from this retrieval style.
- Future systems might combine SG-RAG with existing RAG enhancements to compound the accuracy gains.
Load-bearing premise
Embedding-based subgraph matching will reliably identify and enforce every complex condition in a factual query without semantic noise or missed edge cases.
What would settle it
A test query with multiple explicit conditions for which the knowledge base contains the correct subgraph, yet the embedding match returns an incorrect but similar subgraph that causes the generated answer to violate at least one condition.
Figures






read the original abstract
Retrieval-Augmented Generation (RAG) has been proposed to mitigate hallucinations in large language models (LLMs), where generated outputs may be factually incorrect. However, existing RAG approaches predominantly rely on vector similarity for retrieval, which is prone to semantic noise and fails to ensure that generated responses fully satisfy the complex conditions specified by factual queries, often leading to incorrect answers. To address this challenge, we introduce a novel research problem, named Exact Retrieval Problem (ERP). To the best of our knowledge, this is the first problem formulation that explicitly incorporates structural information into RAG for factual questions to satisfy all query conditions. For this novel problem, we propose Structure Guided Retrieval-Augmented Generation (SG-RAG), which models the retrieval process as an embedding-based subgraph matching task, and uses the retrieved topological structures to guide the LLM to generate answers that meet all specified query conditions. To facilitate evaluation of ERP, we construct and publicly release Exact Retrieval Question Answering (ERQA), a large-scale dataset comprising 120000 fact-oriented QA pairs, each involving complex conditions, spanning 20 diverse domains. The experimental results demonstrate that SG-RAG significantly outperforms strong baselines on ERQA, delivering absolute improvements from 20.68 to 50.88 points across all evaluation metrics, while maintaining reasonable computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Exact Retrieval Problem (ERP) to address limitations of vector-similarity RAG on factual queries with multiple complex conditions. It proposes Structure Guided Retrieval-Augmented Generation (SG-RAG), which formulates retrieval as embedding-based subgraph matching over topological structures and uses the matched subgraphs to guide LLM generation so that all query conditions are satisfied. The authors release the ERQA dataset (120000 QA pairs across 20 domains) and report that SG-RAG yields absolute gains of 20.68–50.88 points over strong baselines on ERQA while keeping computational overhead reasonable.
Significance. If the central claims are substantiated, the work would be a meaningful advance in RAG by explicitly incorporating structural constraints to reduce hallucinations on multi-condition factual questions. The public release of ERQA is a clear positive contribution that could support future benchmarking. The magnitude of the reported gains, if reproducible and statistically supported, would be noteworthy for the IR and NLP communities.
major comments (2)
- [Method (SG-RAG)] Method section (SG-RAG formulation): the claim that embedding-based subgraph matching retrieves structures satisfying every condition in a factual query is load-bearing for the ERP solution but is not accompanied by a formal argument or empirical verification that the chosen embeddings enforce exact condition satisfaction rather than approximate semantic similarity. Standard embedding similarity can still admit near-miss subgraphs that violate one or more conditions, which directly undermines the assertion that SG-RAG solves the Exact Retrieval Problem.
- [Experiments] Experimental results (ERQA evaluation): the absolute improvements of 20.68–50.88 points are presented without accompanying statistical significance tests, variance across runs, or error analysis that isolates whether gains arise from better condition enforcement versus other factors. This information is required to establish that the observed gains demonstrate solution of ERP rather than dataset-specific artifacts.
minor comments (1)
- [Abstract] The abstract states that SG-RAG maintains 'reasonable computational overhead' but the manuscript does not provide concrete latency or memory figures relative to the baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: Method section (SG-RAG formulation): the claim that embedding-based subgraph matching retrieves structures satisfying every condition in a factual query is load-bearing for the ERP solution but is not accompanied by a formal argument or empirical verification that the chosen embeddings enforce exact condition satisfaction rather than approximate semantic similarity. Standard embedding similarity can still admit near-miss subgraphs that violate one or more conditions, which directly undermines the assertion that SG-RAG solves the Exact Retrieval Problem.
Authors: We acknowledge the referee's concern regarding the lack of a formal argument or empirical verification for exact condition satisfaction in the embedding-based subgraph matching. The SG-RAG approach relies on extracting topological structures from queries and matching them using embeddings to guide retrieval. However, to strengthen this, we will revise the method section to include a more detailed explanation of how the subgraph matching ensures condition satisfaction, along with empirical examples from the ERQA dataset showing exact matches. We believe this will address the potential for near-miss subgraphs by demonstrating the effectiveness in practice. revision: yes
-
Referee: Experimental results (ERQA evaluation): the absolute improvements of 20.68–50.88 points are presented without accompanying statistical significance tests, variance across runs, or error analysis that isolates whether gains arise from better condition enforcement versus other factors. This information is required to establish that the observed gains demonstrate solution of ERP rather than dataset-specific artifacts.
Authors: We agree that additional statistical analysis and error analysis would enhance the credibility of the results. In the revised version, we will add statistical significance tests (such as t-tests) with p-values, report standard deviations across multiple runs if applicable, and include an error analysis section that examines cases where conditions are or are not satisfied to attribute the gains to the structural guidance. This will help demonstrate that the improvements are due to solving the ERP. revision: yes
Circularity Check
No significant circularity; new problem, method, and dataset yield independent empirical claims
full rationale
The paper introduces the Exact Retrieval Problem (ERP) as a novel formulation, proposes SG-RAG by modeling retrieval as embedding-based subgraph matching on topological structures to guide LLM answers, constructs the ERQA dataset of 120000 QA pairs across 20 domains, and reports absolute gains of 20.68–50.88 points over baselines. No equations, parameters, or results reduce by construction to self-referential inputs or fitted quantities renamed as predictions. Self-citations, if present, are not load-bearing for the central claims, which rest on explicit experimental evaluation against external baselines on the newly released dataset. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[6]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[7]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[8]
Med-HALT: medical domain hallucination test for large language models. arXiv , author=. arXiv preprint arXiv:2307.15343 , year=
-
[9]
arXiv preprint arXiv:2306.11520 , year=
Hallucination is the last thing you need , author=. arXiv preprint arXiv:2306.11520 , year=
-
[10]
arXiv preprint arXiv:2406.04175 , year=
Confabulation: The surprising value of large language model hallucinations , author=. arXiv preprint arXiv:2406.04175 , year=
-
[11]
arXiv preprint arXiv:2311.15548 , year=
Deficiency of large language models in finance: An empirical examination of hallucination , author=. arXiv preprint arXiv:2311.15548 , year=
-
[12]
The teachers are confused as well
" The teachers are confused as well": A Multiple-Stakeholder Ethics Discussion on Large Language Models in Computing Education , author=. arXiv preprint arXiv:2401.12453 , year=
-
[13]
arXiv preprint arXiv:2401.08358 , year=
Hallucination detection and hallucination mitigation: An investigation , author=. arXiv preprint arXiv:2401.08358 , year=
-
[14]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[15]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review arXiv
-
[16]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Lightrag: Simple and fast retrieval-augmented generation , author=. arXiv preprint arXiv:2410.05779 , year=
work page internal anchor Pith review arXiv
-
[17]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Precise zero-shot dense retrieval without relevance labels , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Memorag: Moving towards next-gen rag via memory-inspired knowledge discovery, 2024
Memorag: Moving towards next-gen rag via memory-inspired knowledge discovery , author=. arXiv preprint arXiv:2409.05591 , volume=
-
[19]
Rq-rag: Learning to refine queries for retrieval augmented generation
Rq-rag: Learning to refine queries for retrieval augmented generation , author=. arXiv preprint arXiv:2404.00610 , year=
-
[20]
arXiv preprint arXiv:2502.12442 , year=
Hoprag: Multi-hop reasoning for logic-aware retrieval-augmented generation , author=. arXiv preprint arXiv:2502.12442 , year=
-
[21]
arXiv preprint arXiv:2505.16237 , year=
Align-GRAG: Reasoning-Guided Dual Alignment for Graph Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2505.16237 , year=
-
[22]
Proceedings of the ACM on Web Conference 2025 , pages=
G-refer: Graph retrieval-augmented large language model for explainable recommendation , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[23]
Proceedings of the ACM on Web Conference 2025 , pages=
Medrag: Enhancing retrieval-augmented generation with knowledge graph-elicited reasoning for healthcare copilot , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[24]
Advances in Neural Information Processing Systems , volume=
Hipporag: Neurobiologically inspired long-term memory for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Harnessing large language models for knowledge graph question answering via adaptive multi-aspect retrieval-augmentation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
arXiv preprint arXiv:1802.03760 , year=
Distributed evaluation of subgraph queries using worstcase optimal lowmemory dataflows , author=. arXiv preprint arXiv:1802.03760 , year=
-
[27]
Journal of the ACM (JACM) , volume=
Worst-case optimal join algorithms , author=. Journal of the ACM (JACM) , volume=. 2018 , publisher=
2018
-
[28]
Proceedings of the VLDB Endowment , volume=
Distributed subgraph matching on timely dataflow , author=. Proceedings of the VLDB Endowment , volume=. 2019 , publisher=
2019
-
[29]
ACM Transactions on Database Systems (TODS) , volume=
Emptyheaded: A relational engine for graph processing , author=. ACM Transactions on Database Systems (TODS) , volume=. 2017 , publisher=
2017
-
[30]
arXiv preprint arXiv:1903.02076 , year=
Optimizing subgraph queries by combining binary and worst-case optimal joins , author=. arXiv preprint arXiv:1903.02076 , year=
-
[31]
Proceedings of the VLDB Endowment , volume=
Rapidmatch: A holistic approach to subgraph query processing , author=. Proceedings of the VLDB Endowment , volume=. 2020 , publisher=
2020
-
[32]
Proceedings of the VLDB Endowment , volume=
Scalable distributed subgraph enumeration , author=. Proceedings of the VLDB Endowment , volume=. 2016 , publisher=
2016
-
[33]
Proceedings of the VLDB Endowment , volume=
Scalable subgraph enumeration in MapReduce , author=. Proceedings of the VLDB Endowment , volume=. 2015 , publisher=
2015
-
[34]
Proceedings of the 2016 International Conference on Management of Data , pages=
Efficient subgraph matching by postponing cartesian products , author=. Proceedings of the 2016 International Conference on Management of Data , pages=
2016
-
[35]
arXiv preprint arXiv:1205.6691 , year=
Efficient subgraph matching on billion node graphs , author=. arXiv preprint arXiv:1205.6691 , year=
-
[36]
BMC bioinformatics , volume=
A subgraph isomorphism algorithm and its application to biochemical data , author=. BMC bioinformatics , volume=. 2013 , publisher=
2013
-
[37]
Proceedings of the 2019 International Conference on Management of Data , pages=
Ceci: Compact embedding cluster index for scalable subgraph matching , author=. Proceedings of the 2019 International Conference on Management of Data , pages=
2019
-
[38]
Proceedings of the VLDB Endowment , volume=
Taming verification hardness: an efficient algorithm for testing subgraph isomorphism , author=. Proceedings of the VLDB Endowment , volume=. 2008 , publisher=
2008
-
[39]
Proceedings of the 2008 ACM SIGMOD international conference on Management of data , pages=
Graphs-at-a-time: query language and access methods for graph databases , author=. Proceedings of the 2008 ACM SIGMOD international conference on Management of data , pages=
2008
-
[40]
IEEE transactions on pattern analysis and machine intelligence , volume=
Challenging the time complexity of exact subgraph isomorphism for huge and dense graphs with VF3 , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[41]
International Workshop on Graph-Based Representations in Pattern Recognition , pages=
VF2 Plus: An improved version of VF2 for biological graphs , author=. International Workshop on Graph-Based Representations in Pattern Recognition , pages=. 2015 , organization=
2015
-
[42]
Proceedings of the VLDB Endowment , volume=
Efficient exact subgraph matching via gnn-based path dominance embedding , author=. Proceedings of the VLDB Endowment , volume=. 2024 , publisher=
2024
-
[43]
The VLDB Journal , volume=
FERRARI: an efficient framework for visual exploratory subgraph search in graph databases , author=. The VLDB Journal , volume=. 2020 , publisher=
2020
-
[44]
The VLDB Journal , volume=
PANDA: toward partial topology-based search on large networks in a single machine , author=. The VLDB Journal , volume=. 2017 , publisher=
2017
-
[45]
The faiss library , author=. arXiv preprint arXiv:2401.08281 , year=
work page internal anchor Pith review arXiv
-
[46]
Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
Approximate nearest neighbor search under neural similarity metric for large-scale recommendation , author=. Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
-
[47]
Proceedings of the 1990 ACM SIGMOD international conference on Management of data , pages=
The R*-tree: An efficient and robust access method for points and rectangles , author=. Proceedings of the 1990 ACM SIGMOD international conference on Management of data , pages=
1990
-
[48]
Proceedings of the ACM on Web Conference 2025 , pages=
How much Medical Knowledge do LLMs have? An Evaluation of Medical Knowledge Coverage for LLMs , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[49]
arXiv preprint arXiv:2505.01655 , year=
Understanding the Mechanisms Behind Structural Influences on Link Prediction: A Case Study on FB15k-237 , author=. arXiv preprint arXiv:2505.01655 , year=
-
[50]
The Twelfth International Conference on Learning Representations , year=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. The Twelfth International Conference on Learning Representations , year=
-
[51]
International conference on applied engineering and natural sciences , volume=
Creating large language model applications utilizing langchain: A primer on developing llm apps fast , author=. International conference on applied engineering and natural sciences , volume=
-
[52]
, author=
Design of On-Premises Version of RAG with AI Agent for Framework Selection Together with Dify and DSL as Well as Ollama for LLM. , author=. International Journal of Advanced Computer Science & Applications , volume=
-
[53]
Pattern Analysis and applications , volume=
A survey of graph edit distance , author=. Pattern Analysis and applications , volume=. 2010 , publisher=
2010
-
[54]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[55]
Han, Wook-Shin and Lee, Jinsoo and Lee, Jeong-Hoon , title =. 2013 , isbn =. doi:10.1145/2463676.2465300 , booktitle =
-
[56]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[57]
2025 , eprint=
Simple Is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation , author=. 2025 , eprint=
2025
-
[59]
2025 , eprint=
LinearRAG: Linear Graph Retrieval Augmented Generation on Large-scale Corpora , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement , author=. 2025 , eprint=
2025
-
[61]
Liang, Lei and Bo, Zhongpu and Gui, Zhengke and Zhu, Zhongshu and Zhong, Ling and Zhao, Peilong and Sun, Mengshu and Zhang, Zhiqiang and Zhou, Jun and Chen, Wenguang and Zhang, Wen and Chen, Huajun , title =. 2025 , isbn =. doi:10.1145/3701716.3715240 , booktitle =
-
[62]
Pattern Analysis & Applications , year=
A survey of graph edit distance , author=. Pattern Analysis & Applications , year=
-
[63]
Xie, Miao and Bhowmick, Sourav S and Su, Hao and Cong, Gao and Han, Wook-Shin , title =. 2018 , issue_date =. doi:10.14778/3229863.3236236 , journal =
-
[64]
and Choi, Byron and Xiao, Xiaokui and Zhou, Shuigeng , booktitle=
Wang, Chaohui and Xie, Miao and Bhowmick, Sourav S. and Choi, Byron and Xiao, Xiaokui and Zhou, Shuigeng , booktitle=. An Indexing Framework for Efficient Visual Exploratory Subgraph Search in Graph Databases , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.