Recognition: unknown
Probing Visual Planning in Image Editing Models
Pith reviewed 2026-05-09 21:36 UTC · model grok-4.3
The pith
Reformulating visual planning as single-step image editing lets models generalize from small abstract puzzles to larger and new ones, though they still lag human efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The editing-as-reasoning paradigm reformulates visual planning tasks into single-step image transformations. When tested on the AMAZE dataset featuring maze navigation and queen placement puzzles, leading image editing models struggle in zero-shot settings. However, finetuning on basic scale puzzles leads to strong generalization to larger in-domain scales and out-of-domain scales and geometries. The best performing model still fails to match the zero-shot efficiency of human solvers, indicating a gap in neural visual reasoning.
What carries the argument
The editing-as-reasoning paradigm that recasts visual planning as a single image edit operation, evaluated on the AMAZE dataset of mazes and queen problems using pixel-wise fidelity and logical validity metrics.
If this is right
- Finetuning on basic scales produces generalization to larger in-domain scales.
- The same finetuning extends to out-of-domain scales and geometries.
- Automatic evaluation becomes feasible through pixel-wise fidelity and logical validity on abstract puzzles.
- A persistent efficiency gap remains between the best neural model and human zero-shot solvers.
Where Pith is reading between the lines
- Training image models on transformation tasks may be sufficient to induce planning behavior without separate reasoning modules.
- Abstract puzzle suites could serve as diagnostic benchmarks for planning deficits across other vision architectures.
- Closing the remaining speed gap would likely require architectural changes that reduce the cost of each editing step.
Load-bearing premise
Abstract puzzles such as Maze and Queen problems, together with pixel-wise and logical validity metrics, sufficiently isolate and measure intrinsic visual planning separate from visual recognition.
What would settle it
A model trained only on small-scale mazes that then fails to produce valid solutions on larger mazes or new geometries in the same test set would falsify the generalization result; conversely, any model achieving human-level zero-shot solving speed on the full AMAZE suite would falsify the efficiency gap claim.
Figures




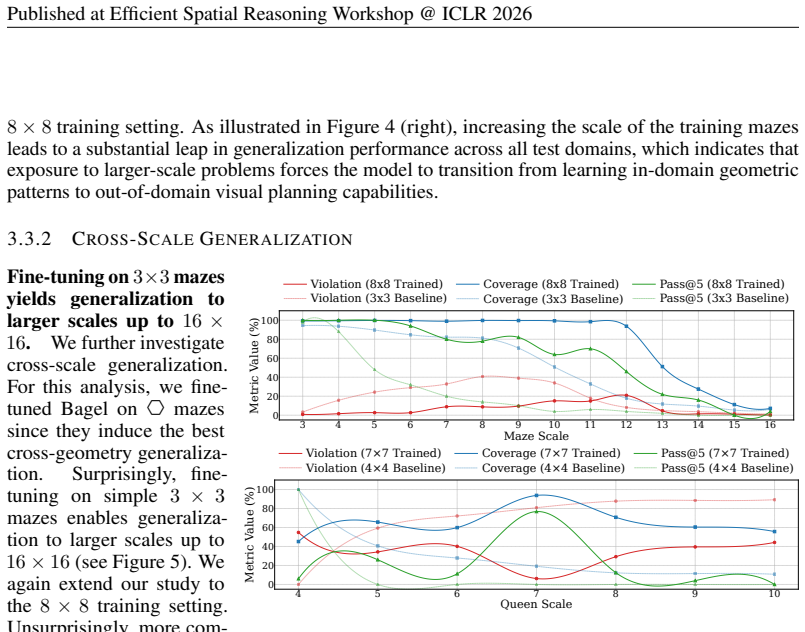



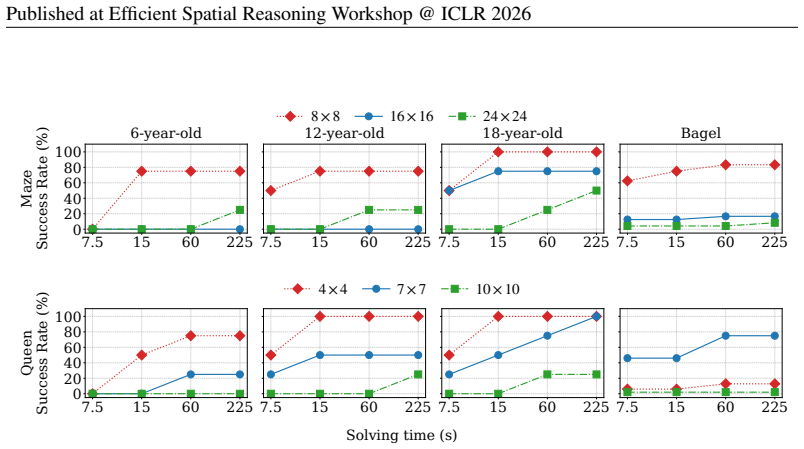




read the original abstract
Visual planning represents a crucial facet of human intelligence, especially in tasks that require complex spatial reasoning and navigation. Yet, in machine learning, this inherently visual problem is often tackled through a verbal-centric lens. While recent research demonstrates the promise of fully visual approaches, they suffer from significant computational inefficiency due to the step-by-step planning-by-generation paradigm. In this work, we present EAR, an editing-as-reasoning paradigm that reformulates visual planning as a single-step image transformation. To isolate intrinsic reasoning from visual recognition, we employ abstract puzzles as probing tasks and introduce AMAZE, a procedurally generated dataset that features the classical Maze and Queen problems, covering distinct, complementary forms of visual planning. The abstract nature of AMAZE also facilitates automatic evaluation of autoregressive and diffusion-based models in terms of both pixel-wise fidelity and logical validity. We assess leading proprietary and open-source editing models. The results show that they all struggle in the zero-shot setting, finetuning on basic scales enables remarkable generalization to larger in-domain scales and out-of-domain scales and geometries. However, our best model that runs on high-end hardware fails to match the zero-shot efficiency of human solvers, highlighting a persistent gap in neural visual reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the EAR (editing-as-reasoning) paradigm that reformulates visual planning tasks as single-step image editing rather than iterative generation. It presents the AMAZE dataset of procedurally generated Maze and Queen puzzles to probe image editing models, using pixel-wise fidelity and logical validity metrics for automatic evaluation. The central claims are that leading proprietary and open-source editing models fail in zero-shot settings, that fine-tuning on basic scales yields strong generalization to larger in-domain scales and out-of-domain geometries, and that even the best model on high-end hardware cannot match the zero-shot efficiency of human solvers.
Significance. If the empirical results hold and the tasks genuinely isolate planning, the work would usefully document limitations of current editing models on visual reasoning and demonstrate the value of the editing-as-reasoning reformulation. The automatic evaluation protocol for abstract puzzles is a constructive contribution. However, the significance is tempered by the absence of evidence that the chosen metrics and puzzles require constructing or searching solution paths rather than permitting low-level shortcuts.
major comments (2)
- [Abstract] Abstract: the claim that AMAZE 'facilitates automatic evaluation' and isolates 'intrinsic reasoning from visual recognition' is load-bearing for the zero-shot failure, generalization, and human-gap conclusions, yet no validation is supplied that logical validity cannot be satisfied by color-based heuristics, direct pattern completion, or dataset regularities that bypass path construction or search.
- [Abstract] The efficiency comparison (best model on high-end hardware vs. human zero-shot solvers) is central to the final claim of a 'persistent gap in neural visual reasoning,' but the manuscript provides no quantitative details on how human solving time or step count is measured, how model inference latency is recorded, or controls for hardware normalization.
minor comments (1)
- [Abstract] The acronym EAR is expanded only once in the abstract; subsequent uses should either repeat the expansion or define it explicitly in the introduction for clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments point by point below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AMAZE 'facilitates automatic evaluation' and isolates 'intrinsic reasoning from visual recognition' is load-bearing for the zero-shot failure, generalization, and human-gap conclusions, yet no validation is supplied that logical validity cannot be satisfied by color-based heuristics, direct pattern completion, or dataset regularities that bypass path construction or search.
Authors: We agree that explicit checks against low-level shortcuts would strengthen the isolation claim. The procedural generation of AMAZE varies maze sizes, queen counts, and board geometries precisely to reduce dataset regularities, and logical validity is defined to require complete, attack-free solutions (for queens) or connected paths from start to goal (for mazes). Zero-shot model failures even on the smallest instances suggest that simple color or pattern heuristics are not being exploited. Nevertheless, to address the concern directly, the revision will add an ablation subsection that evaluates heuristic baselines (color-matching, template completion) and reports their logical-validity rates on held-out scales and geometries, confirming that these shortcuts do not suffice. revision: yes
-
Referee: [Abstract] The efficiency comparison (best model on high-end hardware vs. human zero-shot solvers) is central to the final claim of a 'persistent gap in neural visual reasoning,' but the manuscript provides no quantitative details on how human solving time or step count is measured, how model inference latency is recorded, or controls for hardware normalization.
Authors: We acknowledge that the current description of the efficiency comparison lacks the necessary methodological detail for reproducibility and fair interpretation. In the revised manuscript we will expand the human-study and runtime sections to specify: (i) the exact protocol used to record human solving time and step count (including instructions given to participants and any time limits), (ii) the hardware and software stack on which model inference latency was measured, and (iii) any normalization steps applied to place human and model times on a comparable footing. These additions will allow readers to assess the reported gap with full context. revision: yes
Circularity Check
No circularity: empirical results on new dataset and tasks
full rationale
The paper introduces EAR paradigm and AMAZE dataset with Maze/Queen puzzles, then reports empirical zero-shot and finetuning results on editing models using pixel-wise fidelity and logical validity metrics. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. Claims rest on direct model evaluations rather than any derivation that reduces to its own inputs by construction. The assumption that these tasks isolate planning is a methodological choice open to external scrutiny but does not create circularity in the reported findings.
Axiom & Free-Parameter Ledger
invented entities (2)
-
EAR
no independent evidence
-
AMAZE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reinforcing
Wu, Junfei and Guan, Jian and Feng, Kaituo and Liu, Qiang and Wu, Shu and Wang, Liang and Wu, Wei and Tan, Tieniu , booktitle =. Reinforcing
-
[2]
Visual Instruction Tuning , volume =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , volume =
-
[3]
GitHub repository , howpublished =
Rob Dawson , title =. GitHub repository , howpublished =. 2021 , publisher =
2021
-
[4]
Vision research , volume=
Development of human visual function , author=. Vision research , volume=. 2011 , publisher=
2011
-
[5]
Wiley Interdisciplinary Reviews: Cognitive Science , volume=
Development of visual perception , author=. Wiley Interdisciplinary Reviews: Cognitive Science , volume=. 2010 , publisher=
2010
-
[6]
The Twelfth International Conference on Learning Representations , year=
Zero-Shot Robotic Manipulation with Pre-Trained Image-Editing Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
2025 , eprint=
VFScale: Intrinsic Reasoning through Verifier-Free Test-time Scalable Diffusion Model , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Qwen-Image Technical Report , author=. 2025 , eprint=
2025
-
[9]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =
Wu, Chengyue and Chen, Xiaokang and Wu, Zhiyu and Ma, Yiyang and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong and Luo, Ping , title =. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =. 2025 , pages =
2025
-
[10]
U-Net: convolutional networks for biomedical image segmentation , booktitle =
Olaf Ronneberger and Philipp Fischer and Thomas Brox , editor =. U-Net: Convolutional Networks for Biomedical Image Segmentation , booktitle =. 2015 , url =. doi:10.1007/978-3-319-24574-4\_28 , timestamp =
-
[11]
Advances in Neural Information Processing Systems , editor=
Flamingo: a Visual Language Model for Few-Shot Learning , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Xu, Guowei and Jin, Peng and Wu, Ziang and Li, Hao and Song, Yibing and Sun, Lichao and Yuan, Li , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[13]
Improve Vision Language Model Chain-of-thought Reasoning
Zhang, Ruohong and Zhang, Bowen and Li, Yanghao and Zhang, Haotian and Sun, Zhiqing and Gan, Zhe and Yang, Yinfei and Pang, Ruoming and Yang, Yiming. Improve Vision Language Model Chain-of-thought Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.82
-
[14]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[15]
M ath C oder- VL : Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning
Wang, Ke and Pan, Junting and Wei, Linda and Zhou, Aojun and Shi, Weikang and Lu, Zimu and Xiao, Han and Yang, Yunqiao and Ren, Houxing and Zhan, Mingjie and Li, Hongsheng. M ath C oder- VL : Bridging Vision and Code for Enhanced Multimodal Mathematical Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2...
-
[16]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[18]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[19]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Li, Yun and Zhang, Yiming and Lin, Tao and Liu, Xiangrui and Cai, Wenxiao and Liu, Zheng and Zhao, Bo , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Wang, Wenqi and Tan, Reuben and Zhu, Pengyue and Yang, Jianwei and Yang, Zhengyuan and Wang, Lijuan and Kolobov, Andrey and Gao, Jianfeng and Gong, Boqing , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
2025
-
[23]
Nuscenes-spatialqa: A spatial understanding and reasoning benchmark for vision-language models in autonomous driving , author=. arXiv preprint arXiv:2504.03164 , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Peebles, William and Xie, Saining , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[25]
2023 , eprint=
InstructPix2Pix: Learning to Follow Image Editing Instructions , author=. 2023 , eprint=
2023
-
[26]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[27]
The Eleventh International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[28]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team , doi =. arXiv preprint arXiv:2405.09818 , title =
work page internal anchor Pith review arXiv
-
[29]
Emu3: Next-Token Prediction is All You Need
Emu3: Next-Token Prediction is All You Need , author=. arXiv preprint arXiv:2409.18869 , year=
work page internal anchor Pith review arXiv
-
[30]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[31]
arXiv e-prints , pages=
Seeing clearly, answering incorrectly: A multimodal robustness benchmark for evaluating mllms on leading questions , author=. arXiv e-prints , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , title =...
2024
-
[33]
2025 , eprint=
Humanity's Last Exam , author=. 2025 , eprint=
2025
-
[34]
2025 , url=
Chaoyou Fu and Peixian Chen and Yunhang Shen and Yulei Qin and Mengdan Zhang and Xu Lin and Jinrui Yang and Xiawu Zheng and Ke Li and Xing Sun and Yunsheng Wu and Rongrong Ji and Caifeng Shan and Ran He , booktitle=. 2025 , url=
2025
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Bohao and Ge, Yuying and Ge, Yixiao and Wang, Guangzhi and Wang, Rui and Zhang, Ruimao and Shan, Ying , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[36]
LVLM-EHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models , year=
Xu, Peng and Shao, Wenqi and Zhang, Kaipeng and Gao, Peng and Liu, Shuo and Lei, Meng and Meng, Fanqing and Huang, Siyuan and Qiao, Yu and Luo, Ping , journal=. LVLM-EHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models , year=
-
[37]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[38]
SpatialBot: Precise Spatial Understanding with Vision Language Models , year=
Cai, Wenxiao and Ponomarenko, Iaroslav and Yuan, Jianhao and Li, Xiaoqi and Yang, Wankou and Dong, Hao and Zhao, Bo , booktitle=. SpatialBot: Precise Spatial Understanding with Vision Language Models , year=
-
[39]
2023 , editor =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =. 2023 , editor =
2023
-
[40]
GPT-4V(ision) System Card , year =
-
[41]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review arXiv
-
[42]
Transactions on Machine Learning Research , issn=
Multimodal Chain-of-Thought Reasoning in Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[43]
Lawrence and Parikh, Devi , title =
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C. Lawrence and Parikh, Devi , title =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
-
[44]
2024 , url=
Dongping Chen and Ruoxi Chen and Shilin Zhang and Yaochen Wang and Yinuo Liu and Huichi Zhou and Qihui Zhang and Yao Wan and Pan Zhou and Lichao Sun , booktitle=. 2024 , url=
2024
-
[45]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Goyal, Yash and Khot, Tejas and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[46]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Tong, Shengbang and Liu, Zhuang and Zhai, Yuexiang and Ma, Yi and LeCun, Yann and Xie, Saining , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[47]
2024 , eprint=
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. 2024 , eprint=
2024
-
[48]
Science China Information Sciences , volume=
Woodpecker: Hallucination correction for multimodal large language models , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[49]
2024 , eprint=
VSP: Assessing the dual challenges of perception and reasoning in spatial planning tasks for VLMs , author=. 2024 , eprint=
2024
-
[50]
Why Is Spatial Reasoning Hard for
Chen, Shiqi and Zhu, Tongyao and Zhou, Ruochen and Zhang, Jinghan and Gao, Siyang and Niebles, Juan Carlos and Geva, Mor and He, Junxian and Wu, Jiajun and Li, Manling , booktitle =. Why Is Spatial Reasoning Hard for. 2025 , editor =
2025
-
[51]
Workshop on Foundation Models Meet Embodied Agents at CVPR 2025 , year=
Visual Planning: Let's Think Only with Images , author=. Workshop on Foundation Models Meet Embodied Agents at CVPR 2025 , year=
2025
-
[52]
2025 , eprint=
How Far are VLMs from Visual Spatial Intelligence? A Benchmark-Driven Perspective , author=. 2025 , eprint=
2025
-
[53]
Sensors , VOLUME =
Watanabe, Yuto and Togo, Ren and Maeda, Keisuke and Ogawa, Takahiro and Haseyama, Miki , TITLE =. Sensors , VOLUME =. 2023 , NUMBER =
2023
-
[54]
2025 , eprint=
AlphaMaze: Enhancing Large Language Models' Spatial Intelligence via GRPO , author=. 2025 , eprint=
2025
-
[55]
Preserve or Modify? Context-Aware Evaluation for Balancing Preservation and Modification in Text-Guided Image Editing , year=
Kim, Yoonjeon and Ryu, Soohyun and Jung, Yeonsung and Lee, Hyunkoo and Kim, Joowon and Yang, June Yong and Hwang, Jaeryong and Yang, Eunho , booktitle=. Preserve or Modify? Context-Aware Evaluation for Balancing Preservation and Modification in Text-Guided Image Editing , year=
-
[56]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[57]
The First Workshop on Multimodal Knowledge and Language Modeling , year=
Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Spatial Reasoning , author=. The First Workshop on Multimodal Knowledge and Language Modeling , year=
-
[58]
doi: 10.18653/v1/2023.emnlp-main.568
Kamath, Amita and Hessel, Jack and Chang, Kai-Wei. What ' s ``up'' with vision-language models? Investigating their struggle with spatial reasoning. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.568
-
[59]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[60]
2023 , eprint=
Structured World Representations in Maze-Solving Transformers , author=. 2023 , eprint=
2023
-
[61]
2025 , eprint=
Visual Planning: Let's Think Only with Images , author=. 2025 , eprint=
2025
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brain and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[63]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Imagine While Reasoning in Space: Multimodal Visualization-of-Thought , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[64]
2025 , eprint=
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL , author=. 2025 , eprint=
2025
-
[65]
Proceedings of the AAAI conference on artificial intelligence , volume=
An empirical study of gpt-3 for few-shot knowledge-based vqa , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[66]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu and Shengming Yin and Weizhen Qi and Xiaodong Wang and Zecheng Tang and Nan Duan , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.04671 , eprinttype =. 2303.04671 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2303.04671 2023
-
[67]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Gupta, Tanmay and Kembhavi, Aniruddha , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[68]
Tang, Yihong and Qu, Ao and Wang, Zhaokai and Zhuang, Dingyi and Wu, Zhaofeng and Ma, Wei and Wang, Shenhao and Zheng, Yunhan and Zhao, Zhan and Zhao, Jinhua. Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Spatial Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:...
-
[69]
2023 , eprint=
A Configurable Library for Generating and Manipulating Maze Datasets , author=. 2023 , eprint=
2023
-
[70]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling , author=. arXiv preprint arXiv:2501.17811 , year=
work page internal anchor Pith review arXiv
-
[71]
2025 , eprint=
Video models are zero-shot learners and reasoners , author=. 2025 , eprint=
2025
-
[72]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , url =
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , url =
-
[73]
and Shechtman, Eli and Wang, Oliver , title =
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[74]
Emerging Properties in Unified Multimodal Pretraining
Emerging Properties in Unified Multimodal Pretraining , author =. arXiv preprint arXiv:2505.14683 , year =
work page internal anchor Pith review arXiv
-
[75]
Gemini 3 Pro Image (Nano Banana Pro) , howpublished =
Google DeepMind , year =. Gemini 3 Pro Image (Nano Banana Pro) , howpublished =
-
[76]
2025 , eprint=
Seedream 4.0: Toward Next-generation Multimodal Image Generation , author=. 2025 , eprint=
2025
-
[77]
2025 , eprint=
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. 2025 , eprint=
2025
-
[78]
Unified Reward Model for Multimodal Understanding and Generation
Unified reward model for multimodal understanding and generation , author=. arXiv preprint arXiv:2503.05236 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.