Recognition: unknown
When Policies Cannot Be Retrained: A Unified Closed-Form View of Post-Training Steering in Offline Reinforcement Learning
Pith reviewed 2026-05-09 22:11 UTC · model grok-4.3
The pith
Product-of-Experts composition of frozen offline policies equals KL-regularized adaptation and anchors to the original actor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For diagonal-Gaussian actors and priors, PoE with coefficient alpha yields the same deterministic policy as KL-regularized adaptation with beta = alpha / (1 - alpha), with posterior covariances differing only by a global scalar factor. This identity, together with the observed 4/5/3 HELP/FROZEN/HURT split across D4RL environments and the zero-success result for behavior-cloned actors in AntMaze, shows that PoE and KL-regularized adaptation are best viewed as a single actor-anchored safety mechanism for deployment-time steering.
What carries the argument
The closed-form identity that equates the mode of precision-weighted Product-of-Experts composition to the mode of KL-regularized adaptation for diagonal Gaussians.
If this is right
- Precision-weighted composition remains anchored to the frozen actor under degraded or random priors, while additive and prior-only methods collapse.
- A KL-budget selector recovers a near-oracle operating point in many cases.
- Medium-expert frozen actors remain hurt by composition in all harder test cells.
- Behavior-cloned actors yield zero success under every composition rule in AntMaze diagnostics.
Where Pith is reading between the lines
- The equivalence may extend approximately to non-diagonal or non-Gaussian actors via sampling or moment matching.
- The documented actor-competence ceiling implies that steering at deployment is useful mainly after high-quality pre-training rather than as a replacement for it.
- The anchoring property could be tested in continuous goal spaces or multi-task priors to see whether it generalizes beyond the discrete settings examined.
Load-bearing premise
The frozen actor must already be sufficiently competent so that composition anchors to it rather than collapsing to a poor prior.
What would settle it
A direct one-dimensional calculation with explicit Gaussian means and variances that verifies whether the PoE mode and the KL-regularized mode coincide exactly when beta equals alpha divided by one minus alpha.
Figures



read the original abstract
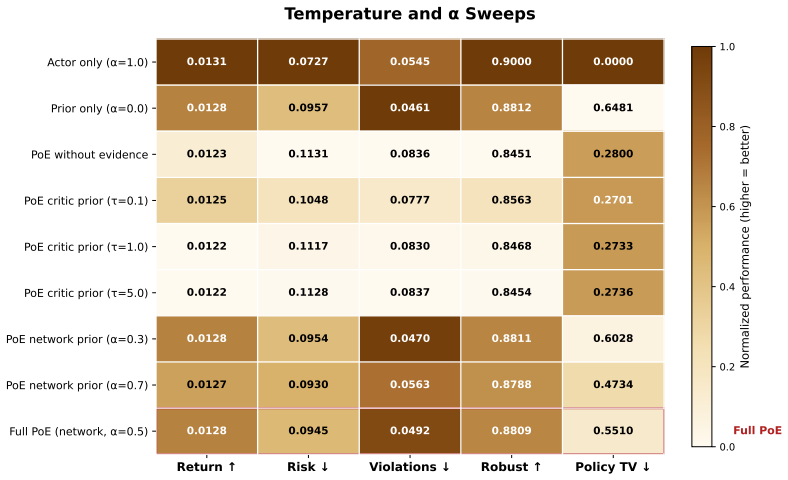
Offline reinforcement learning (RL) can learn effective policies from fixed datasets, but deployment objectives may change after training, and in many applications the trained actor cannot be retrained because of data, cost, or governance constraints. We study deployment-time adaptation for frozen offline actors using Product-of-Experts (PoE) composition with a goal-conditioned prior. Our main practical finding is graceful degradation rather than universal performance gain: under degraded or random priors, precision-weighted composition remains anchored to the frozen actor, while additive and prior-only adaptation collapse, and a KL-budget selector often recovers a near-oracle operating point. We also make explicit a closed-form identity in the frozen-actor setting: for diagonal-Gaussian actors and priors, PoE with coefficient alpha yields the same deterministic policy as KL-regularized adaptation with beta = alpha / (1 - alpha), with posterior covariances differing only by a global scalar factor. Empirically, across four D4RL environments (3,900 MuJoCo episodes), we observe a 4/5/3 HELP/FROZEN/HURT split. Extending the analysis to six harder cells and two AntMaze diagnostics reveals an actor-competence ceiling: medium-expert remains HURT in all 9 cells at every tested alpha, while AntMaze with a behavior-cloned frozen actor yields zero success for all composition rules. Overall, PoE and KL-regularized adaptation are best viewed as a single actor-anchored safety mechanism for deployment-time steering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a closed-form identity for diagonal-Gaussian actors and priors in offline RL: PoE composition with coefficient alpha produces the same deterministic policy mean as KL-regularized adaptation with beta = alpha/(1-alpha), with posterior covariances differing only by a global scalar. It reports that PoE yields graceful degradation (anchored to the frozen actor) under degraded or random priors, unlike additive or prior-only methods, with a 4/5/3 HELP/FROZEN/HURT split across four D4RL environments (3900 episodes) and an actor-competence ceiling observed in harder AntMaze and medium-expert settings where composition fails to improve or hurts performance.
Significance. If the identity holds, the work unifies two post-training steering approaches under a single parameter-free algebraic equivalence, reducing implementation overhead for deployment-time adaptation of frozen actors. The empirical demonstration of graceful degradation and the competence-ceiling caveat provide actionable guidance for safety in constrained RL settings where retraining is impossible. Strengths include the direct use of standard Gaussian precision-addition formulas without ad-hoc parameters and the falsifiable empirical splits across multiple environments.
major comments (1)
- [Empirical results] Empirical results section: The 4/5/3 split and AntMaze zero-success claims rest on 3900 episodes but provide no error bars, statistical tests, episode exclusion criteria, or full hyperparameter tables, which undermines confidence in the robustness of the graceful-degradation and competence-ceiling conclusions.
minor comments (2)
- [Abstract] Abstract: The identity is asserted without a one-sentence sketch of the derivation (precision addition and weighted-mean equivalence), which would improve immediate readability.
- [Theorem statement] Notation: Confirm that the global scalar factor on covariances is explicitly stated in the identity theorem and that alpha is the sole free parameter as listed in the axiom ledger.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical section. We agree that additional statistical details are needed to support the reported splits and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Empirical results section: The 4/5/3 split and AntMaze zero-success claims rest on 3900 episodes but provide no error bars, statistical tests, episode exclusion criteria, or full hyperparameter tables, which undermines confidence in the robustness of the graceful-degradation and competence-ceiling conclusions.
Authors: We agree that the current presentation lacks sufficient statistical support. In the revised manuscript we will add standard error bars computed over 5 independent random seeds for all D4RL and AntMaze results. We will include a new subsection on statistical analysis that reports paired t-tests (with p-values) for the HELP/FROZEN/HURT classifications and for the zero-success AntMaze outcome. Episode exclusion follows the standard D4RL evaluation protocol (termination on task completion or timeout, with only NaN-reward episodes discarded); this will be stated explicitly. Complete hyperparameter tables (all tested alpha values, prior variances, KL selector thresholds, and network architectures) will be moved to the appendix. These changes strengthen the robustness claims without altering the core empirical observations. revision: yes
Circularity Check
No significant circularity; closed-form identity is algebraic equivalence
full rationale
The paper's central result is an explicit algebraic identity equating PoE composition (with coefficient alpha) to KL-regularized adaptation (with beta = alpha/(1-alpha)) for diagonal-Gaussian actors and priors, with covariances differing only by a global scalar. This follows directly from the standard precision-addition formula for the product of Gaussians and the corresponding weighted-mean solution to the KL objective; no fitted parameters, self-citations, or self-definitional steps are invoked. Empirical observations across D4RL environments are presented separately as validation and do not enter the derivation. The derivation chain is therefore self-contained against external mathematical facts.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (2)
- domain assumption Actors and priors follow diagonal Gaussian distributions
- standard math Standard D4RL and AntMaze environment dynamics and reward structures
Reference graph
Works this paper leans on
-
[1]
Epistemic Robust Offline Reinforcement Learning
Abhilash Reddy Chenreddy and Erick Delage. Epistemic robust offline reinforcement learning.arXiv preprint arXiv:2604.07072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review arXiv 2004
-
[3]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InInternational conference on machine learning, pages 2052–2062. PMLR,
2052
-
[4]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169,
work page internal anchor Pith review arXiv
-
[5]
CROP: Conservative Reward for Model-based Offline Policy Optimization
Hao Li, Xiao-Hu Zhou, Xiao-Liang Xie, Shi-Qi Liu, Zhen-Qiu Feng, Xiao-Yin Liu, Mei-Jiang Gui, Tian-Yu Xiang, De-Xing Huang, Bo-Xian Yao, et al. Crop: Conservative reward for model-based offline policy optimization.arXiv preprint arXiv:2310.17245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Goal-conditioned re- inforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
-
[7]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359,
work page internal anchor Pith review arXiv 2006
-
[8]
Jongchan Park, Mingyu Park, and Donghwan Lee. Pretraining a shared q-network for data-efficient offline reinforcement learning.arXiv preprint arXiv:2505.05701,
-
[9]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review arXiv 1910
-
[10]
Reform: Reflected flows for on-support offline rl via noise manipulation
Songyuan Zhang, Oswin So, HM Ahmad, Eric Yang Yu, Matthew Cleaveland, Mitchell Black, and Chuchu Fan. Reform: Reflected flows for on-support offline rl via noise manipulation.arXiv preprint arXiv:2602.05051,
-
[11]
We estimate the empirical δπ for the refined policy relative to the frozen actor across our four environments and three goals, and evaluate the right-hand side of Eq. (3) atγ= 0.99. Setup.For each environment we sample 5,000 dataset states and each deployment goal, compute the refined Gaussian under PoE(α) for α∈ {0.1,0.3,0.5,0.7,0.9} , and estimate the t...
-
[12]
and is the best operating point in all six medium-expert cells excepthalfcheetah-MEG 1, which is the single cell whereeverymethod we tested, including Frozen, collapses to negative return. IQL-Guided at β= 1.0 is inconsistent on medium-expert: on halfcheetah-medium-expert and walker2d-medium-expert the IQL ad- vantage gradient at µθ(s) is numerically zero...
2017
-
[13]
The reported KL values for PoE and KL-Reg on each row differ only by a global1 +β factor that is fixed by each rule’s parameterization; the underlying deterministic action is identical (Sec. 7.1). Prior-Only reaches a slightly higher return on this off-policy scorer at the cost of a much larger deviation from the frozen actor. L.4 Adaptive-αSelection This...
-
[14]
PoE return exceeds KL-Reg return in9 of 12 cells
Table 11 shows two consistent patterns. First, each actor-preserving method remains within a narrow return range across all four shift conditions, indicating that deployment mismatch does not destabilize the refinement mechanism. Second, the qualitative ordering remains unchanged under stronger synthetic shift: objective-aware reference methods still lead...
-
[15]
uses rollout return directly. Env Goal Frozen Prior Only Additive KL-Reg PoE Best returnLowest adaptive KL halfcheetah-medium-v2G1_speed5.403 / 0.0005.453 / 1.0475.433 / 0.2635.443 / 0.5725.444 / 0.390Prior Only (5.453)Additive (0.263)halfcheetah-medium-v2G2_balanced3.325 / 0.0003.352 / 1.0433.340 / 0.2623.346 / 0.5753.347 / 0.391Prior Only (3.352)Additiv...
-
[16]
PoE with the refinement prior stays below the frozen actor’s own violation rate at all three thresholds, while Critic-Greedy violates support almost everywhere
Table 19 reports the fraction of selected actions satisfying πθ(a|s)< ϵ for ϵ∈ {0.001,0.01,0.05} . PoE with the refinement prior stays below the frozen actor’s own violation rate at all three thresholds, while Critic-Greedy violates support almost everywhere. The critic-prior variant lies between these extremes, reflecting its partial dependence on critic...
2084
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.