Recognition: unknown
Don't Make the LLM Read the Graph: Make the Graph Think
Pith reviewed 2026-05-08 11:36 UTC · model grok-4.3
The pith
Belief graphs improve LLM cooperation only when they gate actions rather than appear in prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Integration architecture determines whether belief graphs provide value: as prompt context, graphs are decorative for strong models and beneficial only for weak models on second-order theory of mind; when graphs gate action selection through ranked shortlists, they become structurally essential even for strong models.
What carries the argument
Belief graphs used either as passive prompt context or as active gates that produce ranked shortlists to constrain LLM action selection in the Hanabi game.
If this is right
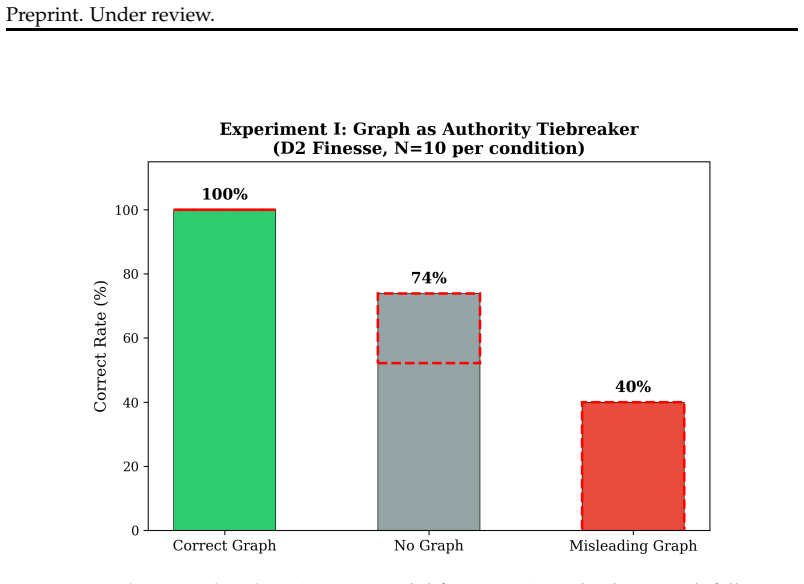
- Strong models reach 100 percent accuracy on second-order theory of mind when graphs rank and limit their actions, versus 20 percent without graphs.
- Some model families override correct graph-based recommendations up to 90 percent of the time while others show near-zero override rates.
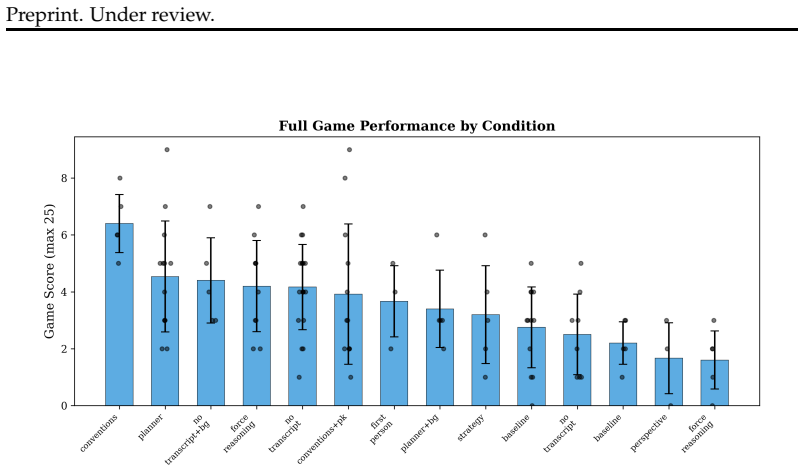
- Inter-agent conventions built from full belief graphs improve full-game scores by 128 percent over baseline single-agent interventions.
- Shallow graphs deliver the highest cost-benefit ratio while deeper graphs reduce performance at larger player counts.
Where Pith is reading between the lines
- Agent designs should embed graphs directly into decision pipelines rather than rely on context windows for multi-agent tasks.
- Model-family differences in response to graph advice suggest that integration methods may need tailoring to specific LLMs.
- The same active-gating pattern could be tested in non-game domains such as collaborative planning or real-time coordination.
Load-bearing premise
That performance differences observed in the Hanabi game accurately reflect general improvements in cooperative multi-agent reasoning and theory-of-mind capabilities that would transfer to other domains.
What would settle it
A controlled experiment in a second cooperative multi-agent task, such as a negotiation or planning scenario, in which graph-gated action selection produces no measurable improvement over baseline prompting.
Figures






read the original abstract
We investigate whether explicit belief graphs improve LLM performance in cooperative multi-agent reasoning. Through 3,000+ controlled trials across four LLM families in the cooperative card game Hanabi, we establish four findings. First, integration architecture determines whether belief graphs provide value: as prompt context, graphs are decorative for strong models and beneficial only for weak models on 2nd-order Theory of Mind (80% vs 10%, p<0.0001, OR=36.0); when graphs gate action selection through ranked shortlists, they become structurally essential even for strong models (100% vs 20% on 2nd-order ToM, p<0.001). Second, we identify "Planner Defiance," a model-family-specific failure where LLMs override correct planner recommendations at partial competence (90% override, replicated N=20); Gemini models show near-zero defiance while Llama 70B shows 90%, and models distinguish factual context (deferred to) from advisory recommendations (overridden). Third, full-game evidence confirms inter-agent conventions (+128% over baseline, p=0.003) outperform all single-agent interventions, and individual belief-graph components must be combined to produce gains. Fourth, preliminary scaling analysis (N=10/cell, exploratory) suggests graph depth has diminishing returns: shallow graphs provide the best cost-benefit ratio, while deeper ToM graphs appear harmful at larger player counts (-1.5 pts at 5-player, p=0.029).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical study of explicit belief graphs in LLM-based cooperative multi-agent reasoning, using 3000+ controlled trials in the Hanabi card game across four LLM families. It claims that integration architecture is decisive: graphs supplied only as prompt context are largely decorative for strong models and help only weak models on 2nd-order Theory of Mind tasks (80% vs 10%, p<0.0001, OR=36), whereas graphs that gate action selection via ranked shortlists make the graphs structurally essential even for strong models (100% vs 20%, p<0.001). Additional findings include model-specific 'Planner Defiance' (LLMs overriding correct planner advice at ~90% rate for some families), the superiority of inter-agent conventions over single-agent interventions, and preliminary evidence that shallow graphs are preferable to deeper ToM graphs at scale.
Significance. If the central architecture claim survives controls for action-space reduction, the work would usefully demonstrate that the value of structured belief representations in LLM agents depends on how they are wired into decision-making rather than on their mere presence in context. The large trial count, reported effect sizes, and identification of planner defiance (with family-specific patterns) are concrete strengths. The results, if robust, would inform practical design choices for multi-agent LLM systems and highlight the limits of context-only augmentation.
major comments (2)
- [Gating architecture results] The gating experiments (abstract and associated results) compare a graph-gated condition that restricts the LLM to a ranked shortlist against a no-graph baseline that permits the full action space. This design confounds the presence of graph-derived ToM information with the mechanical benefit of action-space reduction; without a matched-size non-graph shortlist control or an explicit ablation of ranking quality, the claim that graphs become 'structurally essential' cannot be isolated from simpler filtering effects. This directly undermines the load-bearing contrast between the two integration architectures.
- [Methods and results on ranked shortlists] The 2nd-order ToM performance numbers (100% vs 20% under gating) are reported with p<0.001, yet the manuscript provides no explicit description of how shortlist size was chosen, whether it was held constant across conditions, or how the ranking was generated independently of the graph. These details are required to evaluate whether the reported OR and accuracy gains are attributable to graph content rather than reduced decision complexity.
minor comments (2)
- [Experimental setup] The abstract and results mention 'four LLM families' and 'N=10/cell exploratory scaling' but do not list the exact models, temperature settings, or prompt templates used; these should be supplied in a methods appendix or table for reproducibility.
- [Results] The paper reports statistical tests and effect sizes but does not include a CONSORT-style flow diagram or explicit exclusion criteria for trials; adding this would strengthen the claim of 3000+ controlled trials.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting potential confounds in the gating experiments and the need for greater methodological transparency. We address each major comment below, agreeing that additional controls and details will strengthen the isolation of effects. We commit to revisions that preserve the empirical findings while addressing the concerns directly.
read point-by-point responses
-
Referee: [Gating architecture results] The gating experiments (abstract and associated results) compare a graph-gated condition that restricts the LLM to a ranked shortlist against a no-graph baseline that permits the full action space. This design confounds the presence of graph-derived ToM information with the mechanical benefit of action-space reduction; without a matched-size non-graph shortlist control or an explicit ablation of ranking quality, the claim that graphs become 'structurally essential' cannot be isolated from simpler filtering effects. This directly undermines the load-bearing contrast between the two integration architectures.
Authors: We agree that the design confounds graph-derived information with action-space reduction, as the gated condition uses a shortlist while the baseline uses the full space. This limits the strength of the 'structurally essential' claim for gating. In revision, we will add a matched-size non-graph shortlist control (e.g., random selection or heuristic ranking of equivalent length) to ablate the contribution of graph content versus mere filtering. We will also report an ablation varying ranking quality. These additions will allow clearer isolation while retaining the existing contrast between context-only and gated architectures. revision: yes
-
Referee: [Methods and results on ranked shortlists] The 2nd-order ToM performance numbers (100% vs 20% under gating) are reported with p<0.001, yet the manuscript provides no explicit description of how shortlist size was chosen, whether it was held constant across conditions, or how the ranking was generated independently of the graph. These details are required to evaluate whether the reported OR and accuracy gains are attributable to graph content rather than reduced decision complexity.
Authors: We will expand the Methods section to explicitly describe shortlist size selection (determined via pilot runs to ensure coverage without excessive restriction), confirm it was fixed at the same value across all models, conditions, and trials, and detail the ranking procedure (action scores derived from belief graph probabilities combined with ToM inferences, generated independently per trial from the current graph state). These clarifications will demonstrate that gains stem from graph content rather than generic complexity reduction. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or self-referential reductions
full rationale
This paper reports results from 3000+ controlled experimental trials in Hanabi across LLM families, using performance metrics, p-values, odds ratios, and condition comparisons. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described findings. All claims rest on observed data differences rather than reducing by construction to inputs or prior self-work. The study is self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hanabi performance differences with belief graphs reflect genuine improvements in 2nd-order theory of mind and cooperative reasoning
Reference graph
Works this paper leans on
-
[1]
The Hanabi Challenge: A New Frontier for AI Research
doi: 10.1016/j.artint.2019.103216. URLhttps://arxiv.org/abs/1902.00506. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[2]
Training Verifiers to Solve Math Word Problems
URLhttps://arxiv.org/abs/2110.14168. Michal Kosinski. Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(29),
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2302.02083 , year=
doi: 10.1073/pnas.2405460121. URL https://arxiv.org/abs/2302.02083. Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations,
-
[4]
URL https://arxiv.org/abs/ 2305.20050. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173,
work page internal anchor Pith review arXiv
-
[5]
Available: https://doi.org/10.1162/tacl a 00449
doi: 10.1162/tacl a 00638. URLhttps://arxiv.org/abs/2307.03172. Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, volume 36,
work page internal anchor Pith review doi:10.1162/tacl
-
[6]
Toolformer: Language Models Can Teach Themselves to Use Tools
URLhttps://arxiv.org/abs/2302.04761. Natalie Shapira, Mosh Levy, Seyed Hossein Alavi, Xuhui Zhou, Yejin Choi, Yoav Goldberg, Maarten Sap, and Vered Shwartz. Clever Hans or neural theory of mind? Stress testing social reasoning in large language models.arXiv preprint arXiv:2305.14763,
work page internal anchor Pith review arXiv
- [7]
-
[8]
Green card is immediately playable
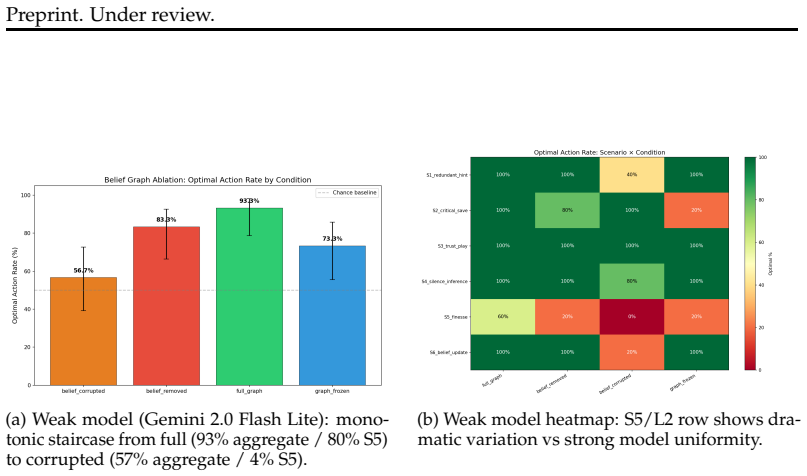
doi: 10.1037/0033-295X.101.1.34. A Case Studies: Illustrative Decision Traces Case 1: Strong Model Ignores Corrupted Graph Gemini 2.5 Flash + corrupted graph on S5/L2 Corrupted graph: “Green card is immediately playable.” Model:“The belief graph indicates green is playable. However, board state shows green at rank 1; my card appears to be G3. Alice’s hint...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.