Recognition: unknown
No Test Cases, No Problem: Distillation-Driven Code Generation for Scientific Workflows
Pith reviewed 2026-05-08 08:08 UTC · model grok-4.3
The pith
MOSAIC generates accurate scientific code without any test cases by distilling from domain examples and using a context window to keep reasoning consistent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
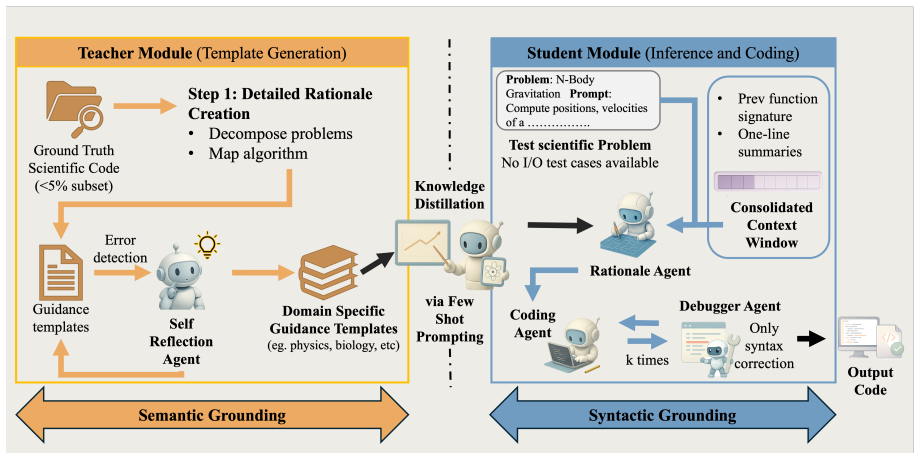
MOSAIC is a training-free multi-agent framework for scientific code generation that substitutes execution feedback and I/O supervision with student-teacher knowledge distillation grounded in domain examples and structured decomposition, plus a Consolidated Context Window that preserves reasoning consistency across agents, yielding higher accuracy, executability, and numerical precision on the SciCode benchmark than prior approaches while using lightweight models.
What carries the argument
The student-teacher knowledge distillation process combined with a Consolidated Context Window that maintains consistent reasoning across agents without any I/O test cases or execution feedback.
If this is right
- Scientific workflows that cannot supply test cases without first solving the underlying problem become candidates for automated code generation.
- Lightweight models can reach usable performance levels on tasks that previously required larger models and iterative testing.
- Errors that arise when subproblems pass information to one another are reduced by keeping a single shared context window.
- Numerical precision in generated scientific code improves without the need to run and check outputs at each step.
Where Pith is reading between the lines
- The same distillation pattern could apply to other technical domains where test cases are expensive or impossible to create in advance.
- Integration with symbolic checkers might add an extra layer of verification on top of the context window.
- Researchers could test whether the approach scales to longer workflow chains or to problems drawn from entirely new scientific fields.
Load-bearing premise
Domain-specific examples together with structured decomposition and the Consolidated Context Window can ground generation and stop hallucinations in chained subproblems without execution feedback or I/O supervision.
What would settle it
A case on the SciCode benchmark where MOSAIC produces non-executable code or numerically incorrect results for a workflow with no available test cases would show the distillation and context window failed to ground the output.
Figures












read the original abstract
Existing multi-agent Large Language Model (LLM) frameworks for code generation typically use execution feedback and improve iteratively using Input/Output (I/O) test cases. However, this does not work for scientific workflows, where I/O test cases do not exist, and generating them requires solving the very problem at hand. To address this, we introduce MOSAIC, a training-free multi-agent framework for scientific code generation without I/O supervision. Instead of execution feedback, MOSAIC employs a student-teacher knowledge distillation framework that grounds generation through domain-specific examples and structured problem decomposition. To further mitigate hallucinations across chained subproblems, we introduce a Consolidated Context Window (CCW) for maintaining consistent reasoning across agents. Experiments on the SciCode benchmark show that MOSAIC improves accuracy, executability, and numerical precision over existing approaches while relying on lightweight models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOSAIC, a training-free multi-agent LLM framework for generating code for scientific workflows lacking I/O test cases. It replaces execution feedback with student-teacher knowledge distillation grounded in domain-specific examples and structured problem decomposition, augmented by a Consolidated Context Window (CCW) to maintain consistent reasoning and reduce hallucinations across chained subproblems. The central claim is that this pipeline yields improvements in accuracy, executability, and numerical precision on the SciCode benchmark while using only lightweight models.
Significance. If the empirical results hold, the approach would address a genuine practical gap in applying LLM code generation to scientific domains, where I/O oracles and test cases are typically unavailable and cannot be generated without solving the target problem. The training-free nature and reliance on lightweight models could make it more accessible than iterative refinement methods.
major comments (3)
- [Abstract] Abstract: The manuscript asserts that 'Experiments on the SciCode benchmark show that MOSAIC improves accuracy, executability, and numerical precision' but provides no quantitative results, baseline comparisons, error bars, or statistical analysis to support this claim.
- [Method and Experiments] Method and Experiments sections: No ablation is reported that isolates the contribution of the Consolidated Context Window from the domain-specific examples or the multi-agent decomposition alone, leaving open the possibility that any observed gains derive from the examples rather than the claimed mechanisms for blocking error propagation in chained subproblems.
- [Method] Method: The student-teacher distillation is described at a high level using external domain examples, but the paper supplies neither a concrete implementation of how distillation occurs without I/O supervision nor any quantitative measure (e.g., hallucination rate or error-propagation rate across subproblem chains) to validate that the CCW successfully grounds generation.
minor comments (1)
- [Abstract and Method] The acronym CCW is introduced without an explicit expansion on first use in the abstract, and the relationship between the student-teacher roles and the multi-agent agents is not diagrammed or tabulated for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the presentation and validation of our work. We address each major comment point by point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'Experiments on the SciCode benchmark show that MOSAIC improves accuracy, executability, and numerical precision' but provides no quantitative results, baseline comparisons, error bars, or statistical analysis to support this claim.
Authors: We agree that the abstract would benefit from greater specificity. Although the Experiments section contains the full quantitative results, baseline comparisons, and analysis, the abstract summarizes these at a high level without numbers. In the revised manuscript we will update the abstract to include key quantitative improvements (e.g., accuracy, executability, and numerical-precision gains relative to baselines) so that the central claim is supported by concrete evidence from the outset. revision: yes
-
Referee: [Method and Experiments] Method and Experiments sections: No ablation is reported that isolates the contribution of the Consolidated Context Window from the domain-specific examples or the multi-agent decomposition alone, leaving open the possibility that any observed gains derive from the examples rather than the claimed mechanisms for blocking error propagation in chained subproblems.
Authors: This is a fair criticism. The current manuscript evaluates the integrated MOSAIC pipeline but does not present an ablation that isolates the Consolidated Context Window while holding domain-specific examples and decomposition fixed. We will add such an ablation study to the Experiments section, reporting performance with and without the CCW to demonstrate its specific contribution to reducing error propagation across subproblem chains. revision: yes
-
Referee: [Method] Method: The student-teacher distillation is described at a high level using external domain examples, but the paper supplies neither a concrete implementation of how distillation occurs without I/O supervision nor any quantitative measure (e.g., hallucination rate or error-propagation rate across subproblem chains) to validate that the CCW successfully grounds generation.
Authors: We acknowledge that the Method section presents the student-teacher distillation at a conceptual level. We will revise this section to supply a more concrete description of the distillation procedure (including how the teacher model supplies domain-grounded guidance without I/O pairs) and will add quantitative supporting metrics, such as measured hallucination rates and error-propagation rates across subproblem chains, both with and without the CCW. revision: yes
Circularity Check
No circularity: method relies on external examples and new CCW component without self-referential reductions or fitted predictions.
full rationale
The paper describes a training-free multi-agent framework (MOSAIC) using knowledge distillation, domain-specific examples, structured decomposition, and a Consolidated Context Window (CCW) to address the absence of I/O test cases in scientific workflows. No equations, derivations, or parameter-fitting steps are present in the provided text or abstract. The central claims rest on empirical results from the SciCode benchmark rather than any prediction that reduces by construction to the inputs (e.g., no fitted parameters renamed as predictions, no self-citation chains justifying uniqueness, and no ansatz smuggled via prior work). The approach is self-contained against external benchmarks and domain examples, with no load-bearing self-referential elements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain-specific examples and structured decomposition can ground LLM generation without I/O test cases or execution feedback
invented entities (1)
-
Consolidated Context Window (CCW)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Program synthesis with large language models.CoRR, abs/2108.07732. S. Banerjee, A. Agarwal, and S. Singla
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2409.05746
Llms will always hallucinate, and we need to live with this. arXiv preprint arXiv:2409.05746. L. Ben Allal, R. Li, D. Kocetkov, C. Mou, C. Akiki, C. M. Ferrandis, N. Muennighoff, M. Mishra, A. Gu, M. Dey, and 1 others
- [3]
-
[4]
Graph of thoughts: Solving elaborate problems with large language mod- els
Graph of thoughts: Solv- ing elaborate problems with large language models. arXiv preprint arXiv:2308.09687. M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, and 1 others
-
[5]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt
work page internal anchor Pith review arXiv
-
[6]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531. D. Huang, J. M. Zhang, M. Luck, Q. Bu, Y . Qing, and H. Cui
work page internal anchor Pith review arXiv
-
[7]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Agentcoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv preprint arXiv:2312.13010. M. A. Islam, M. E. Ali, and M. R. Parvez
work page internal anchor Pith review arXiv
- [8]
-
[9]
Codesim: Multi-agent code generation and problem solving through simulation-driven planning and de- bugging.arXiv preprint arXiv:2502.05664. C. Jimenez and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Starcoder: May the source be with you!arXiv preprint arXiv:2305.06161. T. Mallick, O. Yildiz, D. Lenz, and T. Peterka
work page internal anchor Pith review arXiv
- [11]
-
[12]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Code- gen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom
work page internal anchor Pith review arXiv
-
[13]
Scicode: A re- search coding benchmark curated by scientists.arXiv preprint arXiv:2407.13168. H. Wang, T. Fu, Y . Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. Van Katwyk, A. Deac, A. Anandkumar, K. J. Bergen, C. P. Gomes, S. Ho, P. Kohli, J. Lasenby, J. Leskovec, T.-Y . Liu, A. K. Manrai, and 11 others. 2023a. Scientific discovery in the age of ar...
-
[14]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Chain- of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837. Q. Wu and 1 others. 2023a. Autogen: Enabling next- gen llm applications via multi-agent conversation. arXiv preprint arXiv:2308.08155. Y . Wu and 1 others. 2023b. Mathchat: Converse to tackle challeng...
work page internal anchor Pith review arXiv
- [15]
-
[16]
(b)MOSAIC(ours): correctly computes the Kronecker product for all input combinations
(a)SciCode baseline (Tian et al., 2024): fails to handle the case wheredimis int andargsis a list. (b)MOSAIC(ours): correctly computes the Kronecker product for all input combinations. Figure 7: Side-by-side comparison of the SciCode baseline and MOSAIC outputs for theketfunction. Input prompt Main problem:Consider sending a bipartite maximally entangled ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.