Recognition: unknown
CNN-ViT Fusion with Adaptive Attention Gate for Brain Tumor MRI Classification: A Hybrid Deep Learning Model
Pith reviewed 2026-05-08 08:43 UTC · model grok-4.3
The pith
A CNN-ViT hybrid with an adaptive attention gate dynamically merges local and global features to classify brain tumors in MRI images at 97.6 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
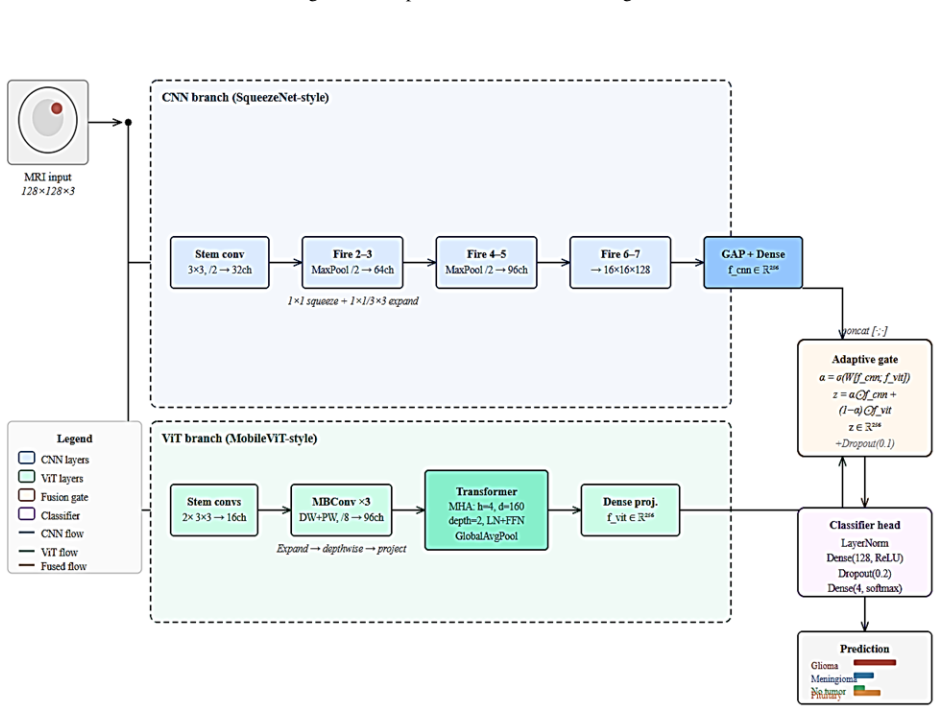
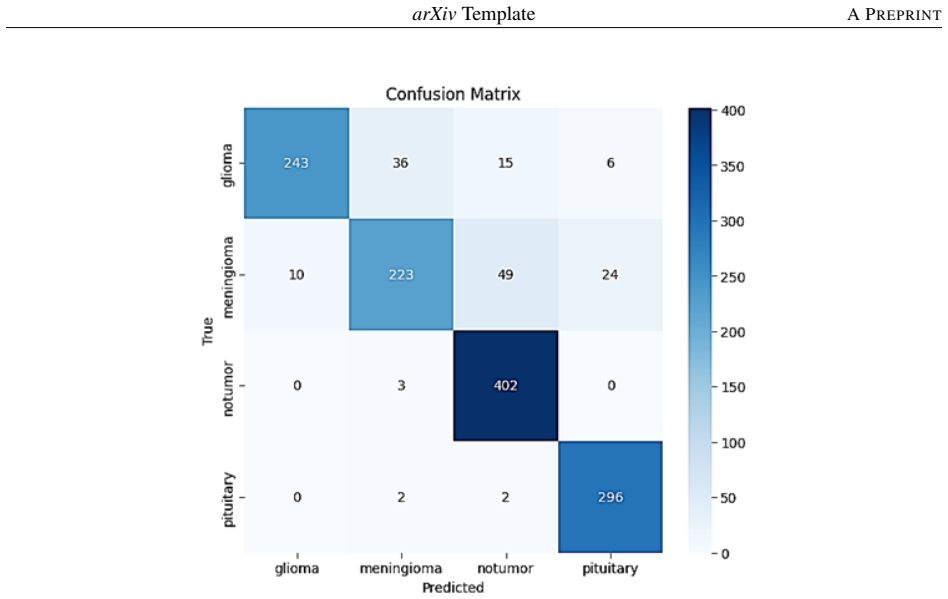
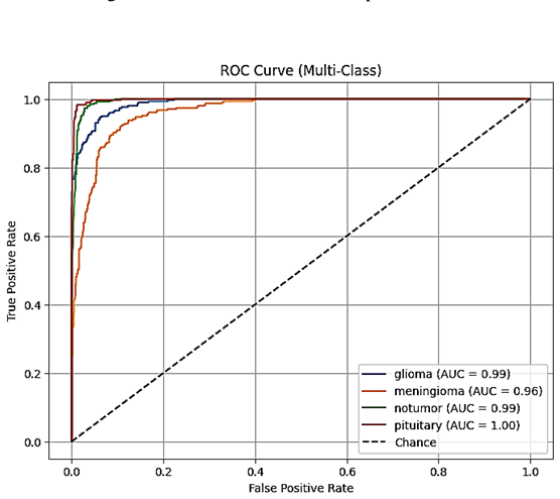
The authors establish that an Adaptive Attention Gate mechanism, which computes dynamic per-sample and per-feature weights, effectively merges the local spatial features from a SqueezeNet-style CNN with the global dependency features from a MobileViT-style transformer. This fusion yields a test accuracy of 97.60%, precision of 97.30%, recall of 97.50%, F1-score of 97.40%, and macro-average AUC of 0.9946 on the Brain Tumor MRI Dataset from Kaggle, surpassing single-branch baselines and existing fusion techniques.
What carries the argument
The Adaptive Attention Gate, a learned module that produces per-sample per-feature weighting factors to control how much each branch contributes to the final representation.
Load-bearing premise
The adaptive attention gate produces stable and generalizable weights that do not overfit to the specific training images in the Kaggle dataset.
What would settle it
Evaluating the model on an independent brain tumor MRI dataset collected from different hospitals or scanners and observing whether the accuracy remains above 95% or if the attention weights show little variation between samples would test the claim.
Figures


read the original abstract
Early detection and classifying brain tumors using Magnetic Resonance Imaging (MRI) images is highly important but difficult to extract in medical images. Convolutional Neural Networks (CNNs) are good at capturing both local texture and spatial information whereas Vision Transformers (ViTs) are good at capturing long-range global dependencies. We propose a new hybrid architecture that combines a SqueezeNet-style CNN branch with a MobileViT-style global transformer branch, through an Adaptive Attention Gate mechanism, in this paper. The gate learns dynamically per-sample, per-feature weights to weight the contribution of each branch, allowing context-sensitive merging of local and global representations. The proposed model has a test accuracy of 97.60, a precision of 97.30, a recall of 97.50, an F1-score of 97.40, and a macro-average area under the curve (AUC) of 0.9946 with a trained and evaluated on the Brain Tumor MRI Dataset (Kaggle). These scores are higher than single CNN and ViT baselines, and current competitive fusion methods, showing that dynamic feature weighting is an effective way to classify medical images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid deep learning architecture fusing a SqueezeNet-style CNN branch (for local textures and spatial info) with a MobileViT-style Vision Transformer branch (for global dependencies) via a novel Adaptive Attention Gate. The gate dynamically learns per-sample, per-feature weights for context-sensitive merging of representations. The model is trained and evaluated on the Kaggle Brain Tumor MRI Dataset, reporting 97.60% test accuracy, 97.30% precision, 97.50% recall, 97.40% F1-score, and 0.9946 macro-average AUC, outperforming standalone CNN/ViT baselines and other fusion methods.
Significance. If the results hold under stronger validation, the work would demonstrate that adaptive, sample-specific fusion of local and global features can improve performance in medical image classification tasks where both fine-grained details and long-range context matter. The high AUC suggests good discriminative capability, and the approach could extend to other hybrid architectures in computer vision for healthcare.
major comments (2)
- [Experimental evaluation / Results] The central claim that the Adaptive Attention Gate enables effective dynamic feature weighting rests on the reported performance gains, but the evaluation (likely in the Experiments or Results section) uses only a single train/test split of the Kaggle dataset with no k-fold cross-validation, no external validation set, and no statistical significance testing. This setup is load-bearing for claims of generalization, as the 97.60% accuracy and 0.9946 AUC could arise from memorization of split-specific artifacts rather than stable per-sample weights, especially given known MRI scanner variability and class imbalance.
- [Methods / Results] No analysis, statistics, or visualizations of the learned attention weights are provided to verify that they are indeed dynamic, vary meaningfully across samples/features, and contribute to the fusion beyond what static baselines achieve. Without this (e.g., weight distribution plots or ablation removing the gate), the mechanism's role in the performance numbers remains unconfirmed.
minor comments (2)
- [Abstract / Methods] The abstract and methods should include explicit references to the exact equations defining the Adaptive Attention Gate (e.g., how per-sample weights are computed from CNN and ViT features) to improve traceability.
- [Experimental setup] Training details such as optimizer, learning rate schedule, batch size, data augmentation, and exact split ratios are not summarized in the abstract; ensure these are clearly stated in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of validation and interpretability. We have addressed both major comments by planning targeted revisions to strengthen the experimental rigor and provide direct evidence for the Adaptive Attention Gate's role. Our responses below are point-by-point.
read point-by-point responses
-
Referee: [Experimental evaluation / Results] The central claim that the Adaptive Attention Gate enables effective dynamic feature weighting rests on the reported performance gains, but the evaluation (likely in the Experiments or Results section) uses only a single train/test split of the Kaggle dataset with no k-fold cross-validation, no external validation set, and no statistical significance testing. This setup is load-bearing for claims of generalization, as the 97.60% accuracy and 0.9946 AUC could arise from memorization of split-specific artifacts rather than stable per-sample weights, especially given known MRI scanner variability and class imbalance.
Authors: We agree that reliance on a single train/test split limits the robustness of generalization claims, particularly in medical imaging where scanner variability and class imbalance are relevant concerns. In the revised manuscript, we will replace the single-split evaluation with 5-fold cross-validation, reporting mean performance and standard deviations across folds. We will also add paired statistical significance tests (e.g., McNemar's test or t-tests on AUC) comparing our model to baselines. While the Kaggle dataset is the established public benchmark for this task and no additional external multi-center dataset was available at the time of submission, we will explicitly discuss this as a limitation and note that the high AUC and consistent outperformance over baselines provide supporting evidence. These changes will better substantiate that the per-sample weights learned by the gate contribute to stable performance rather than split-specific artifacts. revision: yes
-
Referee: [Methods / Results] No analysis, statistics, or visualizations of the learned attention weights are provided to verify that they are indeed dynamic, vary meaningfully across samples/features, and contribute to the fusion beyond what static baselines achieve. Without this (e.g., weight distribution plots or ablation removing the gate), the mechanism's role in the performance numbers remains unconfirmed.
Authors: We concur that direct analysis of the attention weights is necessary to confirm the gate's dynamic behavior and its contribution beyond static fusion. In the revised manuscript, we will add a dedicated subsection with visualizations, including histograms of attention weight distributions across the test set, per-sample weight variation plots for representative examples from each class, and statistics (mean, variance, range) of the learned weights. We will also include an ablation study that replaces the Adaptive Attention Gate with static averaging of the CNN and ViT features, allowing direct comparison of performance. These additions will provide concrete evidence that the weights vary meaningfully and drive the observed gains. revision: yes
Circularity Check
No circularity: empirical test metrics are independent of model inputs
full rationale
The paper describes a hybrid CNN-ViT architecture with an Adaptive Attention Gate that learns per-sample weights during training, then reports standard classification metrics (accuracy 97.60%, AUC 0.9946) measured on a held-out test split of the Kaggle dataset. No derivation chain, equations, or first-principles claims are presented that reduce by construction to the training data or fitted parameters; the performance numbers are direct empirical outputs on unseen samples. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The evaluation is therefore self-contained and falsifiable against external data or alternative splits.
Axiom & Free-Parameter Ledger
free parameters (1)
- attention gate parameters
axioms (1)
- domain assumption CNNs capture local texture while ViTs capture global dependencies
invented entities (1)
-
Adaptive Attention Gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Primary brain tumours in adults,
M. J. Van den Bent et al., “Primary brain tumours in adults,”The Lancet, vol. 402, no. 10412, pp. 1564–1579, 2023
2023
-
[2]
Pediatric brain tumors in the molecular era: updates for the radiologist,
J. AlRayahi, O. Alwalid, W. Mubarak, A. U. R. Maaz, and W. Mifsud, “Pediatric brain tumors in the molecular era: updates for the radiologist,” inSeminars in Roentgenology, 2023, vol. 58, no. 1, pp. 47–66
2023
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020. 8 arXivTemplateA PREPRINT
work page internal anchor Pith review arXiv 2010
-
[4]
S. Mehta and M. Rastegari, “Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer,” arXiv preprint arXiv:2110.02178, 2021
-
[5]
Explainable Disease Classification: Exploring Grad-CAM Analysis of CNNs and ViTs,
A. Alqutayfi et al., “Explainable Disease Classification: Exploring Grad-CAM Analysis of CNNs and ViTs,” Journal of Advances in Information Technology, vol. 16, no. 2, pp. 264–273, 2025
2025
-
[6]
Mzoughi, I
H. Mzoughi, I. Njeh, M. BenSlima, N. Farhat, and C. Mhiri, “Vision transformers (ViT) and deep convolutional neural network (D-CNN)-based models for MRI brain primary tumors images multi-classification supported by explainable artificial intelligence (XAI),”The Visual Computer, vol. 41, no. 4, pp. 2123–2142, 2025
2025
-
[7]
Scalable Hybrid Deep Learning-Based Architecture for Glaucomatous and Healthy Eye Classification in Retinal Fundus Images,
M. Faris, S. Khalid, S. I. Husnain, M. Jamil, H. Yasmeen, and M. Arif, “Scalable Hybrid Deep Learning-Based Architecture for Glaucomatous and Healthy Eye Classification in Retinal Fundus Images,”VFAST Transactions on Software Engineering, vol. 13, no. 4, pp. 01–12, 2025
2025
-
[8]
An Ensemble Deep Learning Framework for Automated Multi Class Skin Lesion Classification Using ConvNeXt-Tiny, EfficientNetV2-S, and MobileNetV3,
M. Faris, F. Khalid, M. Shahid, Z. U. Haque, S. I. Husnain, and M. F. Ali, “An Ensemble Deep Learning Framework for Automated Multi Class Skin Lesion Classification Using ConvNeXt-Tiny, EfficientNetV2-S, and MobileNetV3,”VFAST Transactions on Software Engineering, vol. 14, no. 1, pp. 60–72, 2026
2026
-
[9]
Evaluation of Machine Learning–Based Methods to Detect Bipolar Disorder in Individuals With Mental Health Conditions,
S. I. Hasnain, H. Israr, M. Faris, R. Kamal, and H. S. Y . Tirmiz, “Evaluation of Machine Learning–Based Methods to Detect Bipolar Disorder in Individuals With Mental Health Conditions,”VFAST Transactions on Software Engineering, vol. 13, no. 3, pp. 129–139, 2025
2025
-
[10]
Brain tumor classification using deep neural network and transfer learning,
S. Kumar, S. Choudhary, A. Jain, K. Singh, A. Ahmadian, and M. Y . Bajuri, “Brain tumor classification using deep neural network and transfer learning,”Brain Topography, vol. 36, no. 3, pp. 305–318, 2023
2023
-
[11]
EfficientNet-based deep learning approach for early detection of brain tumors,
N. Verma and V . K. Bohat, “EfficientNet-based deep learning approach for early detection of brain tumors,” Quality & Quantity, pp. 1–21, 2025
2025
-
[12]
F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size,”arXiv preprint arXiv:1602.07360, 2016
-
[13]
Minivit: Compressing vision transformers with weight multiplexing,
J. Zhang et al., “Minivit: Compressing vision transformers with weight multiplexing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12145–12154
2022
-
[14]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
J. Chen et al., “Transunet: Transformers make strong encoders for medical image segmentation,”arXiv preprint arXiv:2102.04306, 2021
work page internal anchor Pith review arXiv 2021
-
[15]
Medical transformer: Gated axial-attention for medical image segmentation,
J. M. J. Valanarasu, P. Oza, I. Hacihaliloglu, and V . M. Patel, “Medical transformer: Gated axial-attention for medical image segmentation,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention, 2021, pp. 36–46
2021
-
[16]
Separable self-attention for mobile vision transformers
S. Mehta and M. Rastegari, “Separable self-attention for mobile vision transformers,”arXiv preprint arXiv:2206.02680, 2022
-
[17]
Image fusion via vision-language model.arXiv preprint arXiv:2402.02235,
Z. Zhao et al., “Image fusion via vision-language model,”arXiv preprint arXiv:2402.02235, 2024
-
[18]
From CNNs to Transformers: A Review of Evolving Deep Learning Architectures for Brain Tumor Classification,
M. Aamir, Z. Rahman, N. Choudhry, J. A. Bhutto, W. A. Abro, and Z. Zhu, “From CNNs to Transformers: A Review of Evolving Deep Learning Architectures for Brain Tumor Classification,”IEEE Access, 2025
2025
-
[19]
Brain tumor detection empowered with ensemble deep learning approaches from MRI scan images,
R. N. Asif et al., “Brain tumor detection empowered with ensemble deep learning approaches from MRI scan images,”Scientific Reports, vol. 15, no. 1, p. 15002, 2025
2025
-
[20]
Multimodal representation learning and fusion,
Q. Jin et al., “Multimodal representation learning and fusion,”arXiv preprint arXiv:2506.20494, 2025
-
[21]
Temporal and Cross-modal Attention for Audio-Visual Zero-Shot Learning,
O.-B. Mercea, T. Hummel, A. S. Koepke, and Z. Akata, “Temporal and Cross-modal Attention for Audio-Visual Zero-Shot Learning,” inComputer Vision – ECCV 2022, 2022, pp. 488–505
2022
-
[22]
Brain Tumor MRI Dataset,
M. Nickparvar, “Brain Tumor MRI Dataset,” Kaggle, 2026. [Online]. Available:https://www.kaggle.com/ datasets/masoudnickparvar/brain-tumor-mri-dataset 9
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.