Recognition: unknown
A Systematic Survey of Security Threats and Defenses in LLM-Based AI Agents: A Layered Attack Surface Framework
Pith reviewed 2026-05-08 07:49 UTC · model grok-4.3
The pith
A seven-layer taxonomy shows that LLM agents have large regions of the attack surface with no defenses or benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
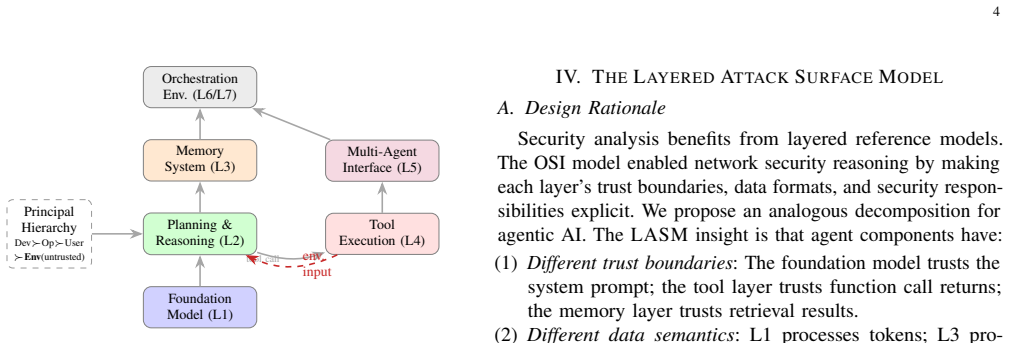
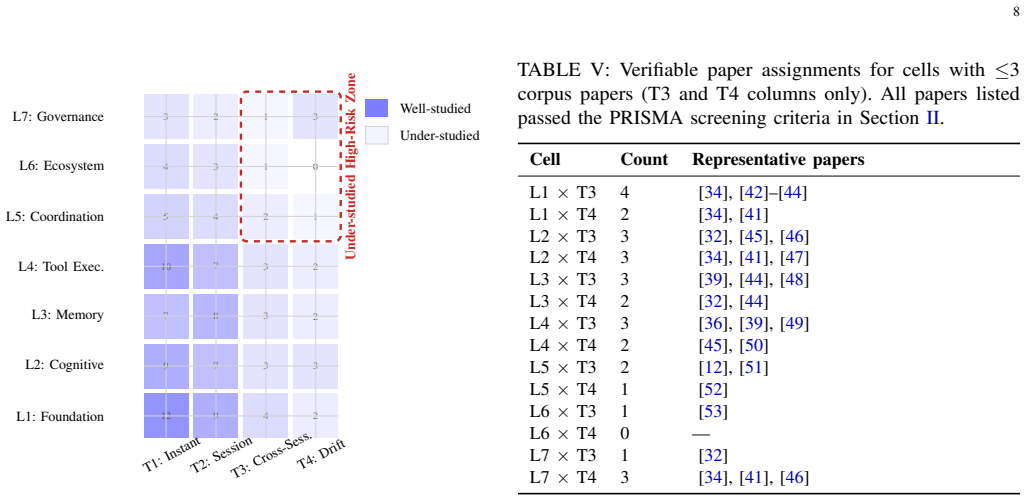
The authors introduce the Layered Attack Surface Model (LASM), a structural taxonomy that decomposes the agentic stack into seven layers—Foundation, Cognitive, Memory, Tool Execution, Multi-Agent Coordination, Ecosystem, and Governance—augmented by a four-class temporality axis of instantaneous, session-persistent, cross-session cumulative, and sub-session-stack threats. Applying the 7x4 framework to 116 papers from 2021-2026 produces a map that locates under-explored upper layers, especially for long-horizon and stack-propagating threats, multiple attack regions that have no corresponding defenses, and benchmarks that provide no coverage for cross-session or sub-session-stack failure modes.
What carries the argument
The Layered Attack Surface Model (LASM), a 7x4 grid that places each threat at the intersection of an architectural layer and a temporal scope to expose uncovered regions and missing defenses.
If this is right
- Security work must expand into the upper layers of the agentic stack for long-horizon and stack-propagating threats.
- New benchmarks are required that test cross-session and sub-session-stack failure modes.
- Defense development is needed for the multiple documented attack regions that currently have none.
- A dependency DAG separates near-term engineering gaps from fundamental research challenges.
- Cross-layer defense recipes become feasible once threats are located within the grid.
Where Pith is reading between the lines
- Practitioners could apply the released Agent Bill of Materials schema to audit deployed agents for missing upper-layer protections.
- The framework implies that standards and regulations for autonomous agents will need explicit requirements for persistent state and coordination risks.
- Future work could test whether the same 7x4 structure applies to hybrid human-AI teams or non-LLM agent architectures.
- Repeated application of the model over time would show whether the coverage gaps narrow or widen as the field advances.
Load-bearing premise
The 116 selected papers form a representative sample of the literature and the seven-layer decomposition plus four-class temporality axis supplies a complete, non-overlapping partition of the agentic attack surface.
What would settle it
A follow-up survey that locates substantial existing work on upper-layer long-horizon defenses or an experiment that demonstrates threats routinely crossing the proposed layer boundaries in ways the taxonomy cannot classify.
Figures

read the original abstract
Agentic AI systems introduce a security surface that is qualitatively different from that of stateless LLMs. They persist memory, invoke external tools, coordinate with peer agents, and operate across sessions, allowing attacks to emerge not only at the prompt interface but also through architectural state, delegated authority, and long-horizon interactions. Existing security taxonomies, however, primarily organize threats by attack type, such as prompt injection or jailbreaking, and therefore obscure where in the agentic stack a threat arises and over what timescale it manifests. We propose the Layered Attack Surface Model (\lasm), a structural taxonomy for agentic AI security. \lasm decomposes the agentic stack into seven layers -- Foundation, Cognitive, Memory, Tool Execution, Multi-Agent Coordination, Ecosystem, and Governance -- and augments them with a four-class temporality axis covering instantaneous, session-persistent, cross-session cumulative, and sub-session-stack threats. We use this 7$\times$4 framework to analyze 116 papers from 2021--2026. The resulting map reveals that the upper layers of the agentic stack remain sharply under-explored, especially for long-horizon and stack-propagating threats; multiple documented attack regions have no corresponding defenses; and current benchmarks provide no coverage for cross-session or sub-session-stack failure modes. We further derive a cross-layer defense taxonomy, defense recipes for canonical attack classes, and a dependency DAG that separates near-term engineering gaps from fundamental research challenges. We release the per-paper coding, robustness scripts, and a reference Agent Bill of Materials schema to support reproducible analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Layered Attack Surface Model (LASM), a 7-layer structural taxonomy (Foundation, Cognitive, Memory, Tool Execution, Multi-Agent Coordination, Ecosystem, Governance) augmented by a 4-class temporality axis (instantaneous, session-persistent, cross-session cumulative, sub-session-stack). It applies this 7×4 framework to map 116 papers (2021–2026) on LLM-based agent security threats and defenses, identifying sharp under-exploration of upper layers for long-horizon and propagating threats, defense gaps, and benchmark limitations. It also derives a cross-layer defense taxonomy, defense recipes, a dependency DAG, and releases per-paper coding, scripts, and an Agent Bill of Materials schema.
Significance. If the survey methodology proves robust, LASM offers a useful structural lens for agentic AI security that moves beyond attack-type taxonomies, with the released artifacts enabling reproducible gap analysis and future work. The identification of defense voids in multi-agent and governance layers for persistent threats could guide prioritized research if the underlying distribution is representative.
major comments (2)
- [Survey Design / Methods] §3 (or equivalent Survey Design section): No search strings, databases, inclusion/exclusion criteria, or inter-rater reliability statistics are provided for the selection and 7×4 classification of the 116 papers. This is load-bearing for the central gap claims, because the reported under-exploration of upper layers (especially long-horizon threats) could arise from keyword bias toward lower-layer attacks such as prompt injection rather than reflecting the true literature distribution.
- [Results / Gap Analysis] Results section (gap analysis): The headline finding that upper layers remain sharply under-explored for long-horizon threats is stated without a quantitative table or counts per layer-temporality cell, preventing assessment of whether the observed distribution is statistically meaningful or merely descriptive.
minor comments (2)
- [Introduction / Framework] The LASM acronym and layer names are introduced clearly in the abstract but would benefit from an early figure or table that explicitly shows the 7×4 grid with one canonical example per cell.
- [Contributions / Artifacts] The released coding artifacts are a strength, but the manuscript should include a brief description of the robustness scripts (e.g., what sensitivity checks they perform) in the main text rather than only in the repository.
Simulated Author's Rebuttal
Thank you for the constructive and detailed referee report. We appreciate the emphasis on methodological transparency and quantitative rigor, as these directly support the validity of our gap analysis. We address each major comment below and commit to revisions that strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Survey Design / Methods] §3 (or equivalent Survey Design section): No search strings, databases, inclusion/exclusion criteria, or inter-rater reliability statistics are provided for the selection and 7×4 classification of the 116 papers. This is load-bearing for the central gap claims, because the reported under-exploration of upper layers (especially long-horizon threats) could arise from keyword bias toward lower-layer attacks such as prompt injection rather than reflecting the true literature distribution.
Authors: We acknowledge that the current manuscript does not provide explicit details on the literature search protocol, databases, inclusion/exclusion criteria, or inter-rater reliability in the Survey Design section. This is a genuine omission that could reasonably lead to concerns about selection bias, particularly whether lower-layer attacks (e.g., prompt injection) were over-sampled due to keyword choices. In the revised version, we will add a dedicated subsection to §3 that fully documents the systematic review methodology. This will include: the databases searched (arXiv, Google Scholar, IEEE Xplore, ACM Digital Library, and selected security venues); the precise search strings and Boolean combinations used (covering terms for LLM agents, threats, defenses, and each architectural layer); the date range and inclusion criteria (peer-reviewed or preprint papers from 2021–2026 focused on security threats or defenses in LLM-based agents); exclusion criteria (non-agentic systems, non-security papers, duplicates); and the classification procedure with inter-rater reliability statistics (e.g., independent coding of a 20% sample by two authors, reporting Cohen’s kappa). We will also explicitly discuss steps taken to ensure broad coverage across layers and temporality classes, thereby addressing potential keyword bias. These additions will make the gap claims reproducible and defensible. revision: yes
-
Referee: [Results / Gap Analysis] Results section (gap analysis): The headline finding that upper layers remain sharply under-explored for long-horizon threats is stated without a quantitative table or counts per layer-temporality cell, preventing assessment of whether the observed distribution is statistically meaningful or merely descriptive.
Authors: We agree that the absence of a quantitative breakdown limits readers’ ability to evaluate the strength of the under-exploration claim. While the manuscript maps all 116 papers to the 7×4 framework and describes the resulting distribution, it does not present cell-by-cell counts or supporting statistics. In the revised manuscript, we will insert a new table (and accompanying heatmap figure) in the Results section that reports the exact number of papers assigned to each layer-temporality cell, with separate columns for threat papers and defense papers. We will also add summary statistics (e.g., percentages per layer and per temporality class) and a short discussion of whether the observed skew toward lower layers and instantaneous threats is statistically notable. This will transform the gap analysis from purely descriptive to quantitatively grounded while preserving the original interpretation. revision: yes
Circularity Check
No circularity: taxonomy application is a direct mapping, not a reduction to inputs
full rationale
The paper proposes the LASM 7-layer plus 4-temporality taxonomy and applies it to classify 116 papers, producing a gap map as output. No equations, fitted parameters, predictions, or self-citations are invoked to derive the distribution or under-exploration claims; the map is the direct result of the manual assignment process described. The representativeness of the sample and reproducibility of coding are methodological assumptions external to any derivation chain, not internal reductions by construction. This matches the default expectation for a non-circular survey paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Agentic AI systems can be decomposed into the seven layers Foundation, Cognitive, Memory, Tool Execution, Multi-Agent Coordination, Ecosystem, and Governance.
- domain assumption Security threats in agentic systems can be usefully classified along the four temporal scales instantaneous, session-persistent, cross-session cumulative, and sub-session-stack.
invented entities (1)
-
Layered Attack Surface Model (LASM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: Language Models Can Teach Themselves to Use Tools,”arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[2]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “ToolLLM: Facilitating large language models to master 16000+ real-world APIs,” inInternational Conference on Learning Representations (ICLR), 2024, arXiv:2307.16789
work page internal anchor Pith review arXiv 2024
-
[3]
Gorilla: Large Language Model Connected with Massive APIs
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive APIs,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024, arXiv:2305.15334
work page internal anchor Pith review arXiv 2024
-
[4]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang, “HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face,” in Advances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2303.17580
work page internal anchor Pith review arXiv 2023
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing Reasoning and Acting in Language Models,”arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An Open-Ended Embodied Agent with Large Language Models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
AutoGPT: An Autonomous GPT-4 Experiment,
S. Gravitas, “AutoGPT: An Autonomous GPT-4 Experiment,”GitHub Repository, 2023, https://github.com/Significant-Gravitas/AutoGPT
2023
-
[8]
A Survey on Large Language Model Based Autonomous Agents,
L. Wang, C. Ma, X. Fenget al., “A Survey on Large Language Model Based Autonomous Agents,”Frontiers of Computer Science, vol. 18, 2024
2024
-
[9]
The Rise and Potential of Large Language Model Based Agents: A Survey
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhouet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Emergent Abilities of Large Language Models
J. Wei, Y . Tay, R. Bommasaniet al., “Emergent abilities of large language models,”Transactions on Machine Learning Research, 2022, arXiv:2206.07682
work page internal anchor Pith review arXiv 2022
-
[11]
WebGPT: Browser-assisted question-answering with human feedback
R. Nakano, J. Hiltonet al., “WebGPT: Browser-assisted question- answering with human feedback,”arXiv preprint arXiv:2112.09332, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
10 Jonathan Hayase, Weihao Kong, Raghav Somani, and Sewoong Oh
Z. Niu, H. Liang, F. Zhang, and X. Li, “Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast,”arXiv preprint arXiv:2402.08567, 2024
-
[13]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
X. Houet al., “Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions,”ACM Transactions on Software Engineering and Methodology, 2025, arXiv:2503.23278
work page internal anchor Pith review arXiv 2025
-
[14]
AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways,
Z. Wanget al., “AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways,”ACM Computing Surveys, vol. 57, no. 7, pp. 182:1–182:38, 2025
2025
-
[15]
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
A. Chhabra, S. Datta, S. K. Nahin, and P. Mohapatra, “Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges,”arXiv preprint arXiv:2510.23883, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Security of LLM-based Agents Regarding Attacks, Defenses, and Applications: A Comprehensive Survey,
Y . Tang, Y . Liu, J. Lan, Z. Yan, and E. Gelenbe, “Security of LLM-based Agents Regarding Attacks, Defenses, and Applications: A Comprehensive Survey,”Information Fusion, vol. 127, 2026
2026
-
[17]
PRISMA 2020 Explanation and Elaboration: Updated Guidance and Exemplars for Reporting Systematic Reviews,
M. J. Page, J. E. McKenzie, P. M. Bossuyt, I. Boutron, T. C. Hoffmann, C. D. Mulrowet al., “PRISMA 2020 Explanation and Elaboration: Updated Guidance and Exemplars for Reporting Systematic Reviews,” BMJ, vol. 372, p. n160, 2021
2020
-
[19]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems (NeurIPS), 2017, arXiv:1706.03762
work page internal anchor Pith review arXiv 2017
-
[20]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019, pp. 4171–4186, arXiv:1810.04805
work page internal anchor Pith review arXiv 2019
-
[21]
Language Models are Few-Shot Learners
T. B. Brown, B. Mannet al., “Language models are few-shot learners,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, arXiv:2005.14165
work page internal anchor Pith review arXiv 2020
-
[22]
OpenAI, “GPT-4 Technical Report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Claude’s Model Card,
Anthropic, “Claude’s Model Card,” 2023, https://www-files.anthropic. com/production/images/model-card-claude-2.pdf
2023
-
[24]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavrilet al., “LLaMA: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[25]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martinet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Advances in Neural Information Processing Systems (NeurIPS), 2017, arXiv:1706.03741
-
[27]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin et al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, arXiv:2203.02155
work page internal anchor Pith review arXiv 2022
-
[28]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” inNeurIPS, 2022
2022
-
[29]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnonet al., “Constitutional AI: Harmlessness from AI Feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[30]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudsonet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review arXiv 2021
-
[31]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, neurIPS 2022
2022
-
[32]
C. Lam, J. Li, L. Zhang, and K. Zhao, “Governing Evolving Memory in LLM Agents: Risks, Mechanisms, and the Stability and Safety Governed Memory (SSGM) Framework,”arXiv preprint arXiv:2603.11768, 2025
-
[33]
Claude’s Model Specification,
Anthropic, “Claude’s Model Specification,” https://anthropic.com/model- spec, 2024
2024
-
[34]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
E. Hubingeret al., “Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training,”arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review arXiv 2024
-
[35]
Malicious MCP Server on npm: postmark- mcp Harvests Emails via BCC Injection,
Snyk Security Research, “Malicious MCP Server on npm: postmark- mcp Harvests Emails via BCC Injection,” Snyk Security Blog, 2025, published September 2025; package postmark-mcp v1.0.16; first docu- mented malicious MCP server in the wild, exfiltrating email content via BCC injection. URL: snyk.io/blog
2025
-
[36]
N. Maloyanet al., “Prompt Injection Attacks on Agentic Coding Assistants: A Systematic Analysis of Vulnerabilities in Skills, Tools, 21 and Protocol Ecosystems,”International Journal of Open Information Technologies, 2025, arXiv:2601.17548
-
[37]
OWASP Top 10 for Large Language Model Applications 2025,
OWASP Foundation, “OWASP Top 10 for Large Language Model Applications 2025,” https://owasp.org/www-project-top-10-for-large- language-model-applications/, 2024
2025
-
[38]
MITRE ATLAS: Adversarial Threat Landscape for Artificial Intelligence Systems, v4.5,
MITRE Corporation, “MITRE ATLAS: Adversarial Threat Landscape for Artificial Intelligence Systems, v4.5,” https://atlas.mitre.org, 2024
2024
-
[39]
Poisonedrag: Knowledge poisoning attacks to retrieval-augmented generation of large language models
W. Zou, R. Geng, B. Wang, and J. Jia, “PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models,”arXiv preprint arXiv:2402.07867, 2024
-
[40]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and Transferable Adversarial Attacks on Aligned Language Models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
E. Hubinger, C. van Merwijk, V . Mikulik, J. Steen, and S. Garrabrant, “Risks from Learned Optimization in Advanced Machine Learning Systems,”arXiv preprint arXiv:1906.01820, 2019
-
[42]
Shadow alignment: The ease of subverting safely-aligned language models
X. Yang, X. Wang, Q. Zhang, L. Petzold, W. Y . Wang, X. Zhao, and D. Lin, “Shadow alignment: The ease of subverting safely-aligned language models,”arXiv preprint arXiv:2310.02949, 2023
-
[43]
Poisoning language models during instruction tuning,
A. Wan, E. Wallace, S. Shen, and D. Klein, “Poisoning language models during instruction tuning,” inProceedings of the 40th International Conference on Machine Learning (ICML), 2023, arXiv:2305.00944
-
[44]
A Survey on the Security of Long-Term Memory in LLM Agents: Toward Mnemonic Sovereignty
Z. Lin, C. Li, and K. Chen, “A Survey on the Security of Long- Term Memory in LLM Agents: Toward Mnemonic Sovereignty,”arXiv preprint arXiv:2604.16548, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
A. Pan, K. Bhatia, and J. Steinhardt, “The Effects of Reward Misspeci- fication: Mapping and Mitigating Misaligned Models,” inInternational Conference on Learning Representations (ICLR), 2022, iCLR 2022; arXiv:2201.03544
-
[46]
Interpreting Agentic Systems: Beyond Model Explana- tions to System-Level Accountability,
J. Zhu, D. Gandhi, H. Joshi, A. R. Mianroodi, S. A. Kocak, and D. Ra- machandran, “Interpreting Agentic Systems: Beyond Model Explana- tions to System-Level Accountability,”arXiv preprint arXiv:2601.17168, 2025
-
[47]
Demonstrating specification gaming in reasoning models,
A. Bondarenkoet al., “Demonstrating specification gaming in reasoning models,”arXiv preprint arXiv:2502.13295, 2025
-
[48]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “AgentPoison: Red- teaming LLM agents via poisoning memory or knowledge bases,” in Advances in Neural Information Processing Systems (NeurIPS), 2024, arXiv:2407.12784
-
[49]
HijackRAG: Hijacking attacks against retrieval-augmented large language models,
Y . Zhang, Q. Deng, T. Zhao, Z. Li, X. Su, Z. Zhu, H. Zhang, and C. Zhuge, “HijackRAG: Hijacking attacks against retrieval-augmented large language models,”arXiv preprint arXiv:2410.22832, 2024
-
[50]
Defining and characterizing reward hacking.arXiv preprint arXiv:2209.13085, 2022
J. Skalse, N. H. R. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward hacking,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, arXiv:2209.13085
-
[51]
Colosseum: Auditing collusion in cooperative multi-agent systems, 2026
M. Nakamura, A. Kumar, S. Das, S. Abdelnabi, S. Mahmud, F. Fioretto, S. Zilberstein, and E. Bagdasarian, “Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems,”arXiv preprint arXiv:2602.15198, 2025
-
[52]
arXiv preprint arXiv:2507.14928 , year=
Y . Jo, M. Jeong, J. Im, and J. Kang, “Byzantine-robust decentralized coordination of LLM agents,”arXiv preprint arXiv:2507.14928, 2025
-
[53]
Large language model supply chain: A research agenda,
J. Weng, Y . Yao, H. Chen, Y . Xie, Z. Li, P. Hu, and D. Gu, “Large language model supply chain: A research agenda,”arXiv preprint arXiv:2404.12736, 2024
-
[54]
J. Yi, J. Ye, Z. Chen, R. Xiong, M. Xu, J. Li, L. Ma, T. Gui, Q. Zhang, and X. Huang, “Jailbreak and guard aligned language models with only few in-context demonstrations,”arXiv preprint arXiv:2310.06387, 2023
-
[55]
Jailbroken: How Does LLM Safety Training Fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How Does LLM Safety Training Fail?” inAdvances in Neural Information Processing Systems (NeurIPS), 2023, neurIPS 2023
2023
-
[56]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. J. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” inInternational Conference on Learning Representations (ICLR), 2014, arXiv:1312.6199
work page internal anchor Pith review arXiv 2014
-
[57]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review arXiv 2014
-
[58]
Available: https://arxiv.org/pdf/1712.03141.pdf 19 N
B. Biggio and F. Roli, “Wild patterns: Ten years after the rise of adversarial machine learning,”Pattern Recognition, vol. 84, pp. 317– 331, 2018, arXiv:1712.03141
-
[59]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “AutoDAN: Generating stealthy jailbreak prompts on aligned large language models,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2310.04451
work page internal anchor Pith review arXiv 2024
-
[60]
Jailbreaking Black Box Large Language Models in Twenty Queries
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” in International Conference on Learning Representations (ICLR), 2024, arXiv:2310.08419
work page internal anchor Pith review arXiv 2024
-
[61]
Many-Shot Jailbreaking,
C. Anil, E. Durmus, M. Sharma, J. Benton, E. Perez, R. Grosse, D. Duvenaudet al., “Many-Shot Jailbreaking,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024, anthropic Technical Report; also presented at NeurIPS 2024
2024
-
[62]
Dissecting Adversarial Robustness of Multimodal LM Agents,
C. Wuet al., “Dissecting Adversarial Robustness of Multimodal LM Agents,” inICLR 2025, 2025, arXiv:2406.12814
-
[63]
Stealing machine learning models via prediction APIs,
F. Tramèr, F. Zhang, A. Juels, M. K. Reiter, and T. Ristenpart, “Stealing machine learning models via prediction APIs,” in25th USENIX Security Symposium (USENIX Security), 2016, arXiv:1609.02943
-
[64]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” inIEEE Symposium on Security and Privacy (S&P), 2017
2017
-
[65]
N. Carlini, D. Paleka, K. Dvijotham, T. Steinke, J. Hayase, A. F. Cooper, K. Lee, M. Jagielski, M. Nasr, A. Conmyet al., “Stealing part of a production language model,” inInternational Conference on Machine Learning (ICML), 2024, arXiv:2403.06634
-
[66]
Extracting training data from large language models
N. Carlini, F. Tramèr, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, Ú. Erlingsson, A. Oprea, and C. Raffel, “Extracting training data from large language models,” in30th USENIX Security Symposium, 2021, pp. 2633–2650, arXiv:2012.07805
-
[67]
Quantifying Memorization Across Neural Language Models
N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tramèr, and C. Zhang, “Quantifying memorization across neural language models,” inIn- ternational Conference on Learning Representations (ICLR), 2023, arXiv:2202.07646
work page internal anchor Pith review arXiv 2023
-
[68]
Feder Cooper, Daphne Ippolito, Christopher A
M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tramèr, and K. Lee, “Scalable extraction of training data from (production) language models,”arXiv preprint arXiv:2311.17035, 2023
-
[69]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789,
W. Shi, A. Ajith, M. Xia, Y . Huang, D. Liu, T. Blevins, D. Chen, and L. Zettlemoyer, “Detecting pretraining data from large language models,” inInternational Conference on Learning Representations (ICLR), 2024, arXiv:2310.16789
-
[70]
Model inversion attacks that exploit confidence information and basic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model inversion attacks that exploit confidence information and basic countermeasures,” in Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS), 2015
2015
-
[71]
Ignore Previous Prompt: Attack Techniques For Language Models,
F. Perez and I. Ribeiro, “Ignore Previous Prompt: Attack Techniques For Language Models,” inEMNLP 2022 Workshop on Trustworthy NLP, 2022
2022
-
[72]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct Preference Optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023, arXiv:2305.18290
work page internal anchor Pith review arXiv 2023
-
[73]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” in International Conference on Learning Representations (ICLR), 2018, arXiv:1706.06083
work page internal anchor Pith review arXiv 2018
-
[74]
and Rosenfeld, Elan and Kolter, J
J. M. Cohen, E. Rosenfeld, and J. Z. Kolter, “Certified adversarial robustness via randomized smoothing,” inInternational Conference on Machine Learning (ICML), 2019, arXiv:1902.02918
-
[75]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa, “Llama Guard: LLM-based input-output safeguard for human-AI conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review arXiv 2023
-
[76]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks, “HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal,”arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[77]
PromptBench : Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
K. Zhu, J. Wang, J. Zhou, Z. Wang, H. Chen, Y . Wang, L. Yang, W. Ye, N. Z. Gong, Y . Zhang, and X. Xie, “PromptBench: Towards evaluating the robustness of large language models on adversarial prompts,”arXiv preprint arXiv:2306.04528, 2023
-
[78]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y . Bai, S. Kadavath, B. Mann, E. Perez, N. Schiefer, K. Ndousse, A. Jones, S. Bowman et al., “Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned,”arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review arXiv 2022
-
[79]
Red Teaming Language Models with Language Models
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with language models,” inProceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing (EMNLP), 2022, arXiv:2202.03286
work page Pith review arXiv 2022
-
[80]
A watermark for large language models.arXiv preprint arXiv:2301.10226, 2023a
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” inInternational Conference on Machine Learning (ICML), 2023, arXiv:2301.10226
-
[81]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” 22 inProceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.